Python爬取今日头条搜索的照片。使用requests+正则表达式
爬取网页:http://www.toutiao.com/search/?keyword=%E8%A1%97%E6%8B%8D
1,分析爬取页面,找到页面信息
在Chrome按F12打开开发者工具,查找网页内容的请求位置
找了doc中发现内容都是加载,查看JS内容页面内容无关。
在XHR中发现到我们想要的内容,页面内容是通过ajax加载进来的
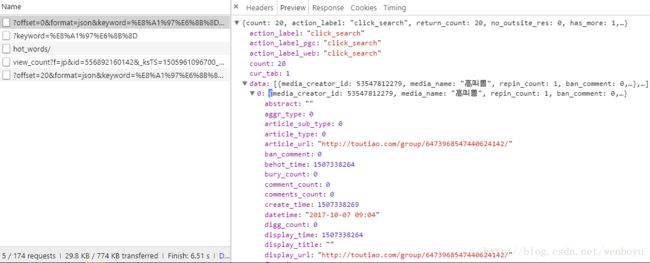
查看Headers,可以得到Request URL和Query String,构造成完整的请求URL

编写请求索引页代码:
def get_index(offset, keyword):
# 网页下拉后,页面重新加载新的内容,offset也增加20,因此offset和翻页有关
# keyword刚好是我们要搜索的内容-街拍
dict = {
'offset': offset,
'format': 'json',
'keyword': keyword,
'autoload': 'true',
'count': '20',
'cur_tab': '1'
}
# urlencode()把字典变成字符ASCII字符串
# 构造索引页url
url = 'http://www.toutiao.com/search_content/?' + urlencode(dict)
print('索引页url' + url)
try:
res = requests.get(url)
if res.status_code == 200:
return res.text
return None
except RequestException:
print('索引页请求失败')
return None2,分析索引页代码,得到详情页内容

在开发者工具里面查看到代码,发现是比较整齐的js代码,用json.loads载入代码,再经过处理就可以得到想要的信息
代码:
def parse_index(html):
# 请求的链接返回的json文件,用json.loads载入变成字典,解析出每个详情页的url
try:
js = json.loads(html)
if js and 'data' in js.keys():
for item in js.get('data'):
if item.get('article_url'):
# 用生成器返回url
yield item.get('article_url')
except JSONDecodeError:
pass3.请求详情页
请求详情页和索引页类似,复制粘贴详情页请求,加上if 内容==None判断跳过URL出错的异常
def get_detail(url):
print('下载:' + url)
if url != None:
try:
res = requests.get(url)
if res.status_code == 200:
return res.text
return None
except RequestException:
print('详情页请求失败')
return None4.得到详情页信息
详情页的图片信息在Doc也就是正常html文件中,但是是通过需要通过js加载后进行解析
标题信息比较简单,用BeautifulSoup.select就可以查找到。
通过对比发现,网页有2种不同的页面,一种静态的下拉页面,一种是左右播放页面,两个页面title标题信息的获取是一致的,但是图片信息不同。
下拉式:

图片url代码在content后面,使用正则表达式解析可以得到
播放页面:

图片url代码在 gallery:里面,使用正则表达式匹配,然后分解后可以去掉一些文字,转换成js字典格式,就可以到url了
最后以字典的形式返回爬取的信息
def parse_detail(html, url):
if html == None:
return None
# 通过BeautifulSoup来查找title
soup = BeautifulSoup(html, 'lxml')
title = soup.select('title')
title = title[0].text if title else''
# 因为有两个不一样的页面,所以有2个不一样的正则分析式
images_pattern1 = re.compile('img src="(.*?);', re.S)
images_pattern2 = re.compile('gallery: {(.*?)},.*?siblingLis', re.S)
res = re.findall(images_pattern1, html)
# 第一种页面,如果能匹配到内容就存储起来
if res != []:
results = [result.rstrip('"') for result in res]
for ima in results: download_image(ima)
return{
'title': title,
'url': url,
'images': results
}
# 第二种页面,使用第二个正则表达式进行匹配,并储存结果
else:
res = re.search(images_pattern2, html)
if res:
data = json.loads(res.group(0).lstrip('gallery: ').rstrip('siblingLis').strip().rstrip(','))
if data and 'sub_images' in data.keys():
sub_images = data.get('sub_images')
images = [item.get('url') for item in sub_images]
for image in images: download_image(image)
return{
'title': title,
'url': url,
'images': images
}5,下载,存储图片
def download_image(url):
print('下载:'+url)
try:
res = requests.get(url)
if res.status_code == 200:
# 直接调用保持图片,传入参数网页的二进制信息
save_iamge(res.content) # res.contenst是二进制信息,因为下载图片需要二进制。
return None
except RequestException:
print('详情页请求失败')
return None
def save_iamge(content):
# 构造保持路径, {0}为当前目录路径,{1}为md5生成值,避免重复下载,{2}为文件格式
file_path = '{0}/images/{1}.{2}'.format(os.getcwd(), md5(content).hexdigest(), 'jpg')
print(file_path)
if not os.path.exists(file_path): # 如果 路径文件不存在 就下载
with open(file_path, 'wb') as f:
f.write(content) # 传入二进制信息
f.close()
6,整合代码添加循环,爬取多页信息
import json
from json import JSONDecodeError
from urllib.parse import urlencode
from hashlib import md5
import re
import os
from requests.exceptions import RequestException
import requests
from bs4 import BeautifulSoup
def get_index(offset, keyword):
# 网页下拉后,页面重新加载新的内容,offset也增加20,因此offset和翻页有关
# keyword刚好是我们要搜索的内容-街拍
dict = {
'offset': offset,
'format': 'json',
'keyword': keyword,
'autoload': 'true',
'count': '20',
'cur_tab': '1'
}
# urlencode()把字典变成字符ASCII字符串
# 构造索引页url
url = 'http://www.toutiao.com/search_content/?' + urlencode(dict)
print('索引页url' + url)
try:
res = requests.get(url)
if res.status_code == 200:
return res.text
return None
except RequestException:
print('索引页请求失败')
return None
def parse_index(html):
# 请求的链接返回的json文件,用json.loads载入变成字典,解析出每个详情页的url
try:
js = json.loads(html)
if js and 'data' in js.keys():
for item in js.get('data'):
if item.get('article_url'):
yield item.get('article_url')
except JSONDecodeError:
pass
def get_detail(url):
print('下载:' + url)
if url != None:
try:
res = requests.get(url)
if res.status_code == 200:
return res.text
return None
except RequestException:
print('详情页请求失败')
return None
def parse_detail(html, url):
if html == None:
return None
# 通过BeautifulSoup来查找title
soup = BeautifulSoup(html, 'lxml')
title = soup.select('title')
title = title[0].text if title else''
# 因为有两个不一样的页面,所以有2个不一样的正则分析式
images_pattern1 = re.compile('img src="(.*?);', re.S)
images_pattern2 = re.compile('gallery: {(.*?)},.*?siblingLis', re.S)
res = re.findall(images_pattern1, html)
# 第一种页面,如果能匹配到内容就存储起来
if res != []:
results = [result.rstrip('"') for result in res]
for ima in results: download_image(ima)
return{
'title': title,
'url': url,
'images': results
}
# 第二种页面,使用第二个正则表达式进行匹配,并储存结果
else:
res = re.search(images_pattern2, html)
if res:
data = json.loads(res.group(0).lstrip('gallery: ').rstrip('siblingLis').strip().rstrip(','))
if data and 'sub_images' in data.keys():
sub_images = data.get('sub_images')
images = [item.get('url') for item in sub_images]
for image in images: download_image(image)
return{
'title': title,
'url': url,
'images': images
}
def download_image(url):
print('下载:'+url)
try:
res = requests.get(url)
if res.status_code == 200:
# 直接调用保持图片,传入参数网页的二进制信息
save_iamge(res.content) # res.contenst是二进制信息,因为下载图片需要二进制。
return None
except RequestException:
print('详情页请求失败')
return None
def save_iamge(content):
# 构造保持路径, {0}为当前目录路径,{1}为md5生成值,避免重复下载,{2}为文件格式
file_path = '{0}/images/{1}.{2}'.format(os.getcwd(), md5(content).hexdigest(), 'jpg')
print(file_path)
if not os.path.exists(file_path): # 如果 路径文件不存在 就下载
with open(file_path, 'wb') as f:
f.write(content) # 传入二进制信息
f.close()
def main(offset):
urls = get_index(offset, '街拍')
for url in parse_index(urls):
res = get_detail(url)
parse_detail(res, url)
# # 测试单个页面:
# url = 'https://temai.snssdk.com/article/feed/index?id=3972873&subscribe=6768458493&source_type=24&content_type=2&create_user_id=6100&classify=2&adid=__AID__'
# res = get_detail(url)
# print(parse_detail(res, url))
if __name__ == '__main__':
# 传入翻页内容,每次offset变化20,因此0-10也每次*20
for i in range(0, 10):
main(i*20)