leetcode【数据结构简介】《队列&栈》卡片 - 小结
Authur Whywait 做一块努力吸收知识的海绵
想看博主的所有leetcode卡片学习笔记?传送门点这儿
队列和栈 - 小结
- 总结
- 队列和BFS
- 栈和DFS
- 习题练习
- 1. 用栈实现队列
- 方法点睛
- 每部分以及具体操作
- 执行结果
- 2. 用队列实现栈
- 方法点睛
- 每部分以及具体操作
- 执行结果
- 3. 字符串解码
- 声明
- 具体步骤
- 代码实现
- 执行结果
- 4. 图像渲染
- 分析
- 特例
- 代码实现
- 执行结果
- 5. 01矩阵
- 分析Ⅰ
- 操作种类
- 代码实现Ⅰ - BFS
- 结果Ⅰ
- 分析Ⅱ
- 优化点睛
- 代码实现Ⅱ - BFS优化
- 执行结果
- 6. 钥匙和房间
- 分析
- 具体实现
- 代码实现
- 执行结果
总结
经过之前的学习(想了解前面具体都说了啥的可以点击下面 传送门),我们了解两种数据结构以及利用两种数据结构特性的算法。下面将作简略总结。
队列和BFS
队列是一种 FIFO 式的数据结构:第一个元素将被首先处理。
队列的两个重要操作:入队和出队。(我们可以使用带有两个指针的动态数组来实现队列。)
BFS算法:广度优先搜索算法,利用了队列的特性。
下面是对应章节链接
leetcode【数据结构简介】《队列&栈》卡片 - 队列:先入先出的数据结构
leetcode【数据结构简介】《队列&栈》卡片 - 队列和广度优先搜索
栈和DFS
栈是一种 LIFO 式的数据结构:最后一个元素将被首先处理。
栈的两个重要操作:push 和 pop。栈的实现非常简单,使用动态数组就足以实现栈。
当满足 LIFO 原则时,我们使用栈。深度优先搜索(DFS)是栈的一个重要应用。
下面是对应的章节链接
leetcode【数据结构简介】《队列&栈》卡片 - 栈:后入先出的数据结构
leetcode【数据结构简介】《队列&栈》卡片 - 栈和深度优先搜索
习题练习
1. 用栈实现队列
使用栈实现队列的下列操作:
- push(x) – 将一个元素放入队列的尾部。
- pop() – 从队列首部移除元素。
- peek() – 返回队列首部的元素。
- empty() – 返回队列是否为空。
方法点睛
使用俩栈,一主一辅。
每部分以及具体操作
先定义我们的队列
#define SIZE 10000
typedef struct myqueue{
int stack1[SIZE], stack2[SIZE];
int top1, top2;
} MyQueue;
Part 1:初始化队列
- malloc分配空间;
- 初始化两个栈顶指针;
- 关于两个栈的说明:栈1为主栈,栈2为辅助栈。
/** Initialize your data structure here. */
MyQueue* myQueueCreate() {
MyQueue * obj = (MyQueue *)malloc(sizeof(MyQueue));
obj->top1 = 0, obj->top2 = 0;
return obj;
}
Part 2:入列
- 栈1中的元素依次出栈入栈到栈2,直到主栈栈1为空;
- 入列元素入主栈栈1;
- 栈2中的元素依次出栈入栈到栈1,直到栈2为空。
/** Push element x to the back of queue. */
void myQueuePush(MyQueue* obj, int x) {
while(obj->top1) obj->stack2[obj->top2++] = obj->stack1[--obj->top1];
obj->stack1[obj->top1++] = x;
while(obj->top2) obj->stack1[obj->top1++] = obj->stack2[--obj->top2];
}
Part 3: 出列
- 栈1栈顶元素出栈。
/** Removes the element from in front of queue and returns that element. */
int myQueuePop(MyQueue* obj) {
return obj->stack1[--obj->top1];
}
Part 4: 获取队首元素
- 获取栈1栈顶元素。
/** Get the front element. */
int myQueuePeek(MyQueue* obj) {
return obj->stack1[(obj->top1)-1];
}
Part 5: 判断队列是否为空
- 等价于判断栈1是否为空。
/** Returns whether the queue is empty. */
bool myQueueEmpty(MyQueue* obj) {
return !obj->top1;
}
Part 6: 释放队列
void myQueueFree(MyQueue* obj) {
free(obj);
}
点击传送门具体了解如何释放结构体。
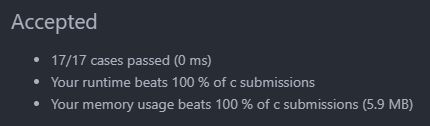
执行结果
2. 用队列实现栈
使用队列实现栈的下列操作:
- push(x) – 元素 x 入栈
- pop() – 移除栈顶元素
- top() – 获取栈顶元素
- empty() – 返回栈是否为空
方法点睛
两个队列,一主一辅。
因为队列为FIFO式的结构,先入先出的性质使其无法让队尾的元素直接出列,所以使用一个队列辅助主队列实现栈的特性。
每部分以及具体操作
具体操作类似上文用栈实现队列,故不再赘述。
#define SIZE 10000
typedef struct {
int queue1[SIZE], queue2[SIZE];
int front1, tail1, front2, tail2;
} MyStack;
Part 1
/** Initialize your data structure here. */
MyStack* myStackCreate() {
MyStack * obj = (MyStack *)malloc(sizeof(MyStack));
obj->front1 = 0; obj->tail1 = 0;
obj->front2 = 0; obj->tail2 = 0;
return obj;
}
Part 2
/** Push element x onto stack. */
void myStackPush(MyStack* obj, int x) {
obj->queue1[obj->tail1++] = x;
}
Part 3
/** Removes the element on top of the stack and returns that element. */
int myStackPop(MyStack* obj) {
while(obj->front1 < (obj->tail1)-1) obj->queue2[obj->tail2++] = obj->queue1[obj->front1++];
int returnNum = obj->queue1[obj->front1];
obj->front1 = 0, obj->tail1 = 0;
while(obj->front2 < obj->tail2) obj->queue1[obj->tail1++] = obj->queue2[obj->front2++];
obj->front2 = 0, obj->tail2 = 0;
return returnNum;
}
一点说明:
下面两行的代码是什么意思呢?
obj->front1 = 0, obj->tail1 = 0;
obj->front2 = 0, obj->tail2 = 0;若没有,会有什么影响呢?
两个数组的front指针就会一直后移,操作次数过多很容易引起数组越界。
Part 4
/** Get the top element. */
int myStackTop(MyStack* obj) {
return obj->queue1[obj->tail1-1];
}
Part 5
/** Returns whether the stack is empty. */
bool myStackEmpty(MyStack* obj) {
return obj->front1 == obj->tail1;
}
Part 6
void myStackFree(MyStack* obj) {
free(obj);
}
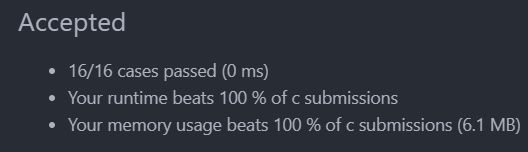
执行结果
3. 字符串解码
给定一个经过编码的字符串,返回它解码后的字符串。
编码规则为: k[encoded_string],表示其中方括号内部的 encoded_string 正好重复 k 次。注意 k 保证为正整数。
你可以认为输入字符串总是有效的;输入字符串中没有额外的空格,且输入的方括号总是符合格式要求的。
此外,可以认为原始数据不包含数字,所有的数字只表示重复的次数 k ,例如不会出现像 3a 或 2[4] 的输入。
示例
s = “3[a]2[bc]”, 返回 “aaabcbc”.
s = “3[a2[c]]”, 返回 “accaccacc”.
s = “2[abc]3[cd]ef”, 返回 “abcabccdcdcdef”.
声明
这个代码是从题解中学习而来。
其中有几个非常值得学习的小技巧。
cnt = 10 * cnt + *s - '0'-
- 如果从前往后遍历一个字符串,如何将遍历到的字符转换为数字呢?这确实是一种非常巧妙的方法,也属于一点就通的那种。至于在从后往前的情况下遍历一个字符串将其转换为数字,只需要
cnt += ('s' - '0') * pow(10, n);即可,n为此时已经遍历的字符的个数。
- 如果从前往后遍历一个字符串,如何将遍历到的字符转换为数字呢?这确实是一种非常巧妙的方法,也属于一点就通的那种。至于在从后往前的情况下遍历一个字符串将其转换为数字,只需要
isalpha(*s)以及isdigit(*s)-
- 这两个函数我也是第一次遇到,遇到了自然就要把它记到小本本上啦。一个是判断字符是否为英文字符,一个是判断字符是否为数字字符。
- 使用系统栈而非显式栈
-
- 递归和辅助栈法相比较,更加简洁明了。
具体步骤
遍历字符串,分为几种情况:
- 遇到字母,则保存至缓存中;
- 遇到数字,则更新计数值;
- 遇到"[",递归调用,将递归调用返回的结果复制N次到结果中;
- 遇到"]", 保存当前字符串指针所在的位置,并返回结果。
代码实现
#define STR_LEN 5000
char * decodeStringCore(char * s, char ** e){
char * ret = (char *)malloc(sizeof(char) * STR_LEN);
char * buf, *end = NULL;
int cnt = 0, idx = 0;
while(* s != '\0'){
if(isalpha(*s)) ret[idx++] = *s;
else if(isdigit(*s)) cnt = 10 * cnt + *s - '0';
else if(*s == '['){
buf = decodeStringCore(s + 1, &end);
while(cnt){
strcpy(ret + idx, buf);
idx += strlen(buf);
cnt--;
}
s = end;
}
else if(*s == ']'){
*e = s;
ret[idx] = '\0';
return ret;
}
s++;
}
ret[idx] = '\0';
return ret;
}
char * decodeString(char * s){
char * end = NULL;
return decodeStringCore(s, &end);
}
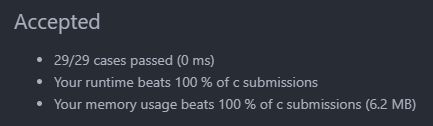
执行结果
4. 图像渲染
有一幅以二维整数数组表示的图画,每一个整数表示该图画的像素值大小,数值在 0 到 65535 之间。
给你一个坐标 (sr, sc) 表示图像渲染开始的像素值(行 ,列)和一个新的颜色值 newColor,让你重新上色这幅图像。
为了完成上色工作,从初始坐标开始,记录初始坐标的上下左右四个方向上像素值与初始坐标相同的相连像素点,接着再记录这四个方向上符合条件的像素点与他们对应四个方向上像素值与初始坐标相同的相连像素点,……,重复该过程。将所有有记录的像素点的颜色值改为新的颜色值。
最后返回经过上色渲染后的图像。
输入:
image = [[1,1,1],[1,1,0],[1,0,1]]
sr = 1, sc = 1, newColor = 2
输出: [[2,2,2],[2,2,0],[2,0,1]]
解析:
在图像的正中间,(坐标(sr,sc)=(1,1)),
在路径上所有符合条件的像素点的颜色都被更改成2。
注意,右下角的像素没有更改为2,
因为它不是在上下左右四个方向上与初始点相连的像素点。
分析
此题做法很明显,使用的方法为BFS广度优先搜索。
特例
- 传入数组为空
- 新的颜色和原来的颜色一样(这一点开始的时候我也没有想到)
代码实现
#define SIZE 10000
typedef struct{
int x, y;
} Node;
int** floodFill(int** image, int imageSize, int* imageColSize, int sr, int sc, int newColor, int* returnSize, int** returnColumnSizes){
* returnSize = 0;
(* returnColumnSizes)[0] = (int *)malloc(sizeof(int));
**returnColumnSizes = 0;
if(!image || !imageSize) return NULL;
* returnSize = imageSize;
for(int i=0; i<imageSize; i++) (* returnColumnSizes)[i] = imageColSize[i];
Node * queue = (Node *)malloc(sizeof(Node) * SIZE);
int front = 0, tail = 0, val = image[sr][sc];
if(val == newColor) return image;
image[sr][sc] = newColor;
queue[tail].x = sr;
queue[tail++].y = sc;
while(front<tail){
if(queue[front].x>0 && image[queue[front].x-1][queue[front].y] == val){
image[queue[front].x-1][queue[front].y] = newColor;
queue[tail].x = queue[front].x - 1;
queue[tail++].y = queue[front].y;
}
if(queue[front].y>0 && image[queue[front].x][queue[front].y-1] == val){
image[queue[front].x][queue[front].y-1] = newColor;
queue[tail].x = queue[front].x;
queue[tail++].y = queue[front].y - 1;
}
if(queue[front].x<imageSize-1 && image[queue[front].x+1][queue[front].y] == val){
image[queue[front].x + 1][queue[front].y] = newColor;
queue[tail].x = queue[front].x + 1;
queue[tail++].y = queue[front].y;
}
if(queue[front].y<imageColSize[queue[front].x]-1 && image[queue[front].x][queue[front].y+1] == val){
image[queue[front].x][queue[front].y + 1] = newColor;
queue[tail].x = queue[front].x;
queue[tail++].y = queue[front].y + 1;
}
front++;
}
free(queue); //至于这里的free()没有也没有关系,但是作为一个好习惯的养成者,最好还是加上吧~
return image;
}
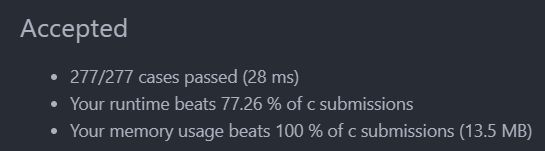
执行结果
5. 01矩阵
给定一个由 0 和 1 组成的矩阵,找出每个元素到最近的 0 的距离。
两个相邻元素间的距离为 1 。
输入:
0 0 0
0 1 0
1 1 1
输出:
0 0 0
0 1 0
1 2 1
分析Ⅰ
读完题目,脑子里跳出来的第一个方法应该都是BFS。
那么我们就来实现它。
操作种类
两个for循环遍历矩阵内所有元素,会遇到如下两种情况
- 遇到0:跳过;
- 遇到1:则将该位置的1替换为其到值为0的节点的步数。
代码实现Ⅰ - BFS
#define SIZE 10000
typedef struct{
int x, y;
} Pos;
int** updateMatrix(int** matrix, int matrixSize, int* matrixColSize, int* returnSize, int** returnColumnSizes){
* returnSize = 0;
if(!matrix || !matrixSize) return NULL;
* returnSize = matrixSize;
for(int i=0; i<matrixSize; i++) (* returnColumnSizes)[i] = matrixColSize[i];
for(int i=0; i<matrixSize; i++){
for(int j=0; j<matrixColSize[i]; j++){
if(!matrix[i][j]) continue;
Pos * queue = (Pos *)malloc(sizeof(Pos) * SIZE);
int front = 0, tail = 0, step = 0;
bool flag = false;
queue[tail].x = i;
queue[tail++].y = j;
while(front < tail){
step++;
int size = tail - front;
for(int k=0; k<size; k++){
if(queue[front].x){
if(!matrix[queue[front].x-1][queue[front].y]){
flag = true;
break;
}
queue[tail].x = queue[front].x-1;
queue[tail++].y = queue[front].y;
}
if(queue[front].y){
if(!matrix[queue[front].x][queue[front].y-1]){
flag = true;
break;
}
queue[tail].x = queue[front].x;
queue[tail++].y = queue[front].y-1;
}
if(queue[front].x < matrixSize - 1){
if(!matrix[queue[front].x+1][queue[front].y]){
flag = true;
break;
}
queue[tail].x = queue[front].x + 1;
queue[tail++].y = queue[front].y;
}
if(queue[front].y < matrixColSize[queue[front].x] - 1){
if(!matrix[queue[front].x][queue[front].y + 1]){
flag = true;
break;
}
queue[tail].x = queue[front].x;
queue[tail++].y = queue[front].y + 1;
}
front++;
}
if(flag) break;
}
matrix[i][j] = step;
}
}
return matrix;
}
结果Ⅰ
超时TLE(惊不惊喜?意不意外?)
分析Ⅱ
这可是BFS算法欸!
怎么牛逼哄哄的算法怎么会超时呢?难道不该这么BFS吗?
细细回想,究其本质,上文中使用的BFS算法算是一种披了一层“BFS”皮的暴力法吧。纵使披上了BFS的外皮,但是暴力法的本质(遍历所有元素),终究会被暴露(TLE)。
那么我们如何优化呢?优化的时候又应该用上什么思想呢?
优化点睛
单源变多源,正向超时逆着来。
单源变多源
我们平时遇到的都是从一个点为源头,然后如蜻蜓点水的效应一般,往外层层扩散(BFS)。多源是什么意思呢?你可以想象很多蜻蜓在点水,水面上为源头的点很多,如此向外一层层扩散开来。
多源BFS是单源BFS的一部分(请细品这句话)
正向超时逆着来
第一种方法做了重复许多重复的事情。举个例子,如果一个1周围全被1包围,我们通过周围的1上面的到达0的最小步长就可以得到中间这个1到达零的最小步长,何必再去往外层层搜索呢?
说是这么说,但是仔细一想却又无从下手。这时候我们就要用到上面提到的单源变多源了。矩阵里面所有的0同时向外搜索,把所有步长为1的1全部找出来赋值为1,然后所有赋值为1的1向外搜索,找到所有步长为2的1··· 如此循环下去直到遍历整个矩阵。这样子一看,队列和BFS是必不可少的了。关于BFS的算法模板,请点击传送门
我们放弃了从1搜索0,而是选择了从0搜索1,这就是所谓"逆"。同时,也从单源变为了多源。
代码实现Ⅱ - BFS优化
/**
* Return an array of arrays of size *returnSize.
* The sizes of the arrays are returned as *returnColumnSizes array.
* Note: Both returned array and *columnSizes array must be malloced, assume caller calls free().
*/
#define SIZE 10000
typedef struct{
int x, y;
} Pos;
int** updateMatrix(int** matrix, int matrixSize, int* matrixColSize, int* returnSize, int** returnColumnSizes){
* returnSize = matrixSize;
if(!matrix || !matrixSize) return NULL;
* returnColumnSizes = matrixColSize;
Pos * queue = (Pos *)malloc(sizeof(Pos) * 10000);
int front = 0, tail = 0, step = 0;
for(int i=0; i<matrixSize; i++){
for(int j=0; j<matrixColSize[i]; j++){
if(matrix[i][j]) matrix[i][j] += SIZE;
else{
queue[tail].x = i;
queue[tail++].y = j;
}
}
}
int directions[4][2] = {{-1, 0}, {1, 0}, {0, -1}, {0, 1}};
while(front < tail){
step++;
int size = tail - front;
for(int i=0; i<size; i++){
for(int j=0; j<4; j++){
int x_temp = queue[front].x + directions[j][0];
int y_temp = queue[front].y + directions[j][1];
if(x_temp < 0 || x_temp >= matrixSize || y_temp < 0 || y_temp >= matrixColSize[x_temp]) continue;
if(matrix[x_temp][y_temp] > step){
matrix[x_temp][y_temp] = step;
queue[tail].x = x_temp;
queue[tail++].y = y_temp;
}
}
front++;
}
}
return matrix;
}
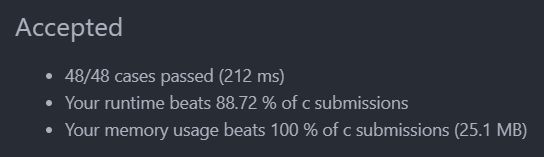
执行结果
6. 钥匙和房间
有 N 个房间,开始时你位于 0 号房间。每个房间有不同的号码:0,1,2,…,N-1,并且房间里可能有一些钥匙能使你进入下一个房间。
在形式上,对于每个房间 i 都有一个钥匙列表 rooms[i],每个钥匙 rooms[i][j] 由 [0,1,…,N-1] 中的一个整数表示,其中 N = rooms.length。 钥匙 rooms[i][j] = v 可以打开编号为 v 的房间。
最初,除 0 号房间外的其余所有房间都被锁住。
你可以自由地在房间之间来回走动。
如果能进入每个房间返回 true,否则返回 false。
输入: [[1],[2],[3],[]]
输出: true
解释:
我们从 0 号房间开始,拿到钥匙 1。
之后我们去 1 号房间,拿到钥匙 2。
然后我们去 2 号房间,拿到钥匙 3。
最后我们去了 3 号房间。
由于我们能够进入每个房间,我们返回 true。
分析
仔细分析问题,我们就可以比较清晰的知道这道题需要使用BFS。
具体实现
使用一个数组来标记每扇门是否进去过:
初始化一个数组,每扇门的编号即为索引,如果当前索引的值为0,说明尚未进去过;如果为1,说明,已经进去过了,所以就不再进去了。
另外就是套用BFS的模板。
这不再是一道中等难度的题目了。
代码实现
bool canVisitAllRooms(int** rooms, int roomsSize, int* roomsColSize){
if(!rooms || !roomsSize) return 1;
int * visited = (int *)calloc(roomsSize, sizeof(int));
int * queue = (int *)malloc(sizeof(int) * (roomsSize+1));
int front = 0, rear = 0;
queue[rear++] = 0;
visited[0] = 1;
while(front < rear){
int size = rear - front;
for(int i=0; i<size; i++){
int cur = queue[front++];
for(int j=0; j<roomsColSize[cur]; j++){
if(visited[rooms[cur][j]]) continue;
queue[rear++] = rooms[cur][j];
visited[rooms[cur][j]] = 1;
}
}
}
for(int i=0; i<roomsSize; i++)
if(!visited[i]) return 0;
return 1;
}
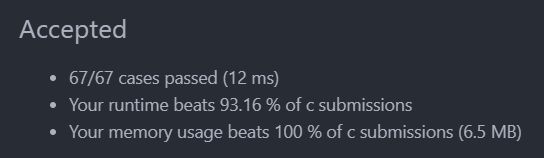
执行结果
都看到这里了,不如点个赞吧~