Hutool Java常用工具类汇总
简介
Hutool是一个小而全的Java工具类库,通过静态方法封装,降低相关API的学习成本,提高工作效率,使Java拥有函数式语言般的优雅,让Java语言也可以“甜甜的”。
Hutool中的工具方法来自于每个用户的精雕细琢,它涵盖了Java开发底层代码中的方方面面,它既是大型项目开发中解决小问题的利器,也是小型项目中的效率担当;
Hutool是项目中“util”包友好的替代,它节省了开发人员对项目中公用类和公用工具方法的封装时间,使开发专注于业务,同时可以最大限度的避免封装不完善带来的bug。
包含组件
一个Java基础工具类,对文件、流、加密解密、转码、正则、线程、XML等JDK方法进行封装,组成各种Util工具类,同时提供以下组件:
| 模块 | 介绍 |
|---|---|
| hutool-aop | JDK动态代理封装,提供非IOC下的切面支持 |
| hutool-bloomFilter | 布隆过滤,提供一些Hash算法的布隆过滤 |
| hutool-cache | 简单缓存实现 |
| hutool-core | 核心,包括Bean操作、日期、各种Util等 |
| hutool-cron | 定时任务模块,提供类Crontab表达式的定时任务 |
| hutool-crypto | 加密解密模块,提供对称、非对称和摘要算法封装 |
| hutool-db | JDBC封装后的数据操作,基于ActiveRecord思想 |
| hutool-dfa | 基于DFA模型的多关键字查找 |
| hutool-extra | 扩展模块,对第三方封装(模板引擎、邮件、Servlet、二维码、Emoji、FTP、分词等) |
| hutool-http | 基于HttpUrlConnection的Http客户端封装 |
| hutool-log | 自动识别日志实现的日志门面 |
| hutool-script | 脚本执行封装,例如Javascript |
| hutool-setting | 功能更强大的Setting配置文件和Properties封装 |
| hutool-system | 系统参数调用封装(JVM信息等) |
| hutool-json | JSON实现 |
| hutool-captcha | 图片验证码实现 |
| hutool-poi | 针对POI中Excel和Word的封装 |
| hutool-socket | 基于Java的NIO和AIO的Socket封装 |
可以根据需求对每个模块单独引入,也可以通过引入hutool-all方式引入所有模块。
安装
Maven
在项目的pom.xml的dependencies中加入以下内容:
<dependency>
<groupId>cn.hutoolgroupId>
<artifactId>hutool-allartifactId>
<version>5.3.9version>
dependency>
Gradle
compile 'cn.hutool:hutool-all:5.3.9'
核心(Hutool-core)
类型转换
转换为字符串:
int a = 1;
//aStr为"1"
String aStr = Convert.toStr(a);
long[] b = {1,2,3,4,5};
//bStr为:"[1, 2, 3, 4, 5]"
String bStr = Convert.toStr(b);
转换为指定类型数组:
String[] b = { "1", "2", "3", "4" };
//结果为Integer数组
Integer[] intArray = Convert.toIntArray(b);
long[] c = {1,2,3,4,5};
//结果为Integer数组
Integer[] intArray2 = Convert.toIntArray(c);
转换为日期对象:
String a = "2017-05-06";
Date value = Convert.toDate(a);
转换为集合
Object[] a = {"a", "你", "好", "", 1};
List<?> list = Convert.convert(List.class, a);
//从4.1.11开始可以这么用
List<?> list = Convert.toList(a);
Object[] a = { "a", "你", "好", "", 1 };
List<String> list = Convert.convert(new TypeReference<List<String>>() {}, a);
金额大小写转换
double a = 67556.32;
//结果为:"陆万柒仟伍佰伍拾陆元叁角贰分"
String digitUppercase = Convert.digitToChinese(a);
日期时间
Date、long、Calendar之间的相互转换
//当前时间
Date date = DateUtil.date();
//当前时间
Date date2 = DateUtil.date(Calendar.getInstance());
//当前时间
Date date3 = DateUtil.date(System.currentTimeMillis());
//当前时间字符串,格式:yyyy-MM-dd HH:mm:ss
String now = DateUtil.now();
//当前日期字符串,格式:yyyy-MM-dd
String today= DateUtil.today();
字符串转日期
DateUtil.parse方法会自动识别一些常用格式,包括:
yyyy-MM-dd HH:mm:ss
yyyy-MM-dd
HH:mm:ss
yyyy-MM-dd HH:mm
yyyy-MM-dd HH:mm:ss.SSS
String dateStr = "2017-03-01";
Date date = DateUtil.parse(dateStr);
String dateStr = "2017-03-01";
Date date = DateUtil.parse(dateStr, "yyyy-MM-dd");
格式化日期输出
String dateStr = "2017-03-01";
Date date = DateUtil.parse(dateStr);
//结果 2017/03/01
String format = DateUtil.format(date, "yyyy/MM/dd");
//常用格式的格式化,结果:2017-03-01
String formatDate = DateUtil.formatDate(date);
//结果:2017-03-01 00:00:00
String formatDateTime = DateUtil.formatDateTime(date);
//结果:00:00:00
String formatTime = DateUtil.formatTime(date);
获取Date对象的某个部分
Date date = DateUtil.date();
//获得年的部分
DateUtil.year(date);
//获得月份,从0开始计数
DateUtil.month(date);
//获得月份枚举
DateUtil.monthEnum(date);
//.....
开始和结束时间
String dateStr = "2017-03-01 22:33:23";
Date date = DateUtil.parse(dateStr);
//一天的开始,结果:2017-03-01 00:00:00
Date beginOfDay = DateUtil.beginOfDay(date);
//一天的结束,结果:2017-03-01 23:59:59
Date endOfDay = DateUtil.endOfDay(date);
日期时间偏移
String dateStr = "2017-03-01 22:33:23";
Date date = DateUtil.parse(dateStr);
//结果:2017-03-03 22:33:23
Date newDate = DateUtil.offset(date, DateField.DAY_OF_MONTH, 2);
//常用偏移,结果:2017-03-04 22:33:23
DateTime newDate2 = DateUtil.offsetDay(date, 3);
//常用偏移,结果:2017-03-01 19:33:23
DateTime newDate3 = DateUtil.offsetHour(date, -3);
//昨天
DateUtil.yesterday()
//明天
DateUtil.tomorrow()
//上周
DateUtil.lastWeek()
//下周
DateUtil.nextWeek()
//上个月
DateUtil.lastMonth()
//下个月
DateUtil.nextMonth()
日期时间差
String dateStr1 = "2017-03-01 22:33:23";
Date date1 = DateUtil.parse(dateStr1);
String dateStr2 = "2017-04-01 23:33:23";
Date date2 = DateUtil.parse(dateStr2);
//相差一个月,31天
long betweenDay = DateUtil.between(date1, date2, DateUnit.DAY);
//Level.MINUTE表示精确到分
String formatBetween = DateUtil.formatBetween(between, Level.MINUTE);
//输出:31天1小时
Console.log(formatBetween);
计时器
TimeInterval timer = DateUtil.timer();
//---------------------------------
//-------这是执行过程
//---------------------------------
timer.interval();//花费毫秒数
timer.intervalRestart();//返回花费时间,并重置开始时间
timer.intervalMinute();//花费分钟数
其他
//年龄
DateUtil.ageOfNow("1990-01-30");
//是否闰年
DateUtil.isLeapYear(2017);
IO流相关
由来
IO的操作包括读和写,应用场景包括网络操作和文件操作。IO操作在Java中是一个较为复杂的过程,我们在面对不同的场景时,要选择不同的InputStream和OutputStream实现来完成这些操作。而如果想读写字节流,还需要Reader和Writer的各种实现类。这些繁杂的实现类,一方面给我我们提供了更多的灵活性,另一方面也增加了复杂性。封装 io包的封装主要针对流、文件的读写封装,主要以工具类为主,提供常用功能的封装,这包括:
IoUtil 流操作工具类 FileUtil 文件读写和操作的工具类。 FileTypeUtil 文件类型判断工具类
WatchMonitor 目录、文件监听,封装了JDK1.7中的WatchService
ClassPathResource针对ClassPath中资源的访问封装 FileReader 封装文件读取 FileWriter
封装文件写入 流扩展 除了针对JDK的读写封装外,还针对特定环境和文件扩展了流实现。包括:
BOMInputStream针对含有BOM头的流读取 FastByteArrayOutputStream
基于快速缓冲FastByteBuffer的OutputStream,随着数据的增长自动扩充缓冲区(from blade)
FastByteBuffer 快速缓冲,将数据存放在缓冲集中,取代以往的单一数组(from blade)
IO工具类-IoUtil
拷贝
BufferedInputStream in = FileUtil.getInputStream("d:/test.txt");
BufferedOutputStream out = FileUtil.getOutputStream("d:/test2.txt");
long copySize = IoUtil.copy(in, out, IoUtil.DEFAULT_BUFFER_SIZE);
读取流中的内容
读取流中的内容总结下来,可以分为read方法和readXXX方法。
read方法有诸多的重载方法,根据参数不同,可以读取不同对象中的内容,这包括: InputStream Reader FileChannel
这三个重载大部分返回String字符串,为字符流读取提供极大便利。readXXX方法主要针对返回值做一些处理,例如:
readBytes 返回byte数组(读取图片等) readHex 读取16进制字符串 readObj 读取序列化对象(反序列化)
readLines 按行读取 toStream方法则是将某些对象转换为流对象,便于在某些情况下操作:String 转换为ByteArrayInputStream File 转换为FileInputStream
写入到流
IoUtil.write方法有两个重载方法,一个直接调用OutputStream.write方法,另一个用于将对象转换为字符串(调用toString方法),然后写入到流中。
IoUtil.writeObjects 用于将可序列化对象序列化后写入到流中。
write方法并没有提供writeXXX,需要自己转换为String或byte[]。关闭
对于IO操作来说,使用频率最高(也是最容易被遗忘)的就是close操作,好在Java规范使用了优雅的Closeable接口,这样我们只需简单封装调用此接口的方法即可。关闭操作会面临两个问题:
被关闭对象为空 对象关闭失败(或对象已关闭) IoUtil.close方法很好的解决了这两个问题。
在JDK1.7中,提供了AutoCloseable接口,在IoUtil中同样提供相应的重载方法,在使用中并不能感觉到有哪些不同。
文件工具类-FileUtil
简介
在IO操作中,文件的操作相对来说是比较复杂的,但也是使用频率最高的部分,我们几乎所有的项目中几乎都躺着一个叫做FileUtil或者FileUtils的工具类,我想Hutool应该将这个工具类纳入其中,解决用来解决大部分的文件操作问题。总体来说,FileUtil类包含以下几类操作工具:
文件操作:包括文件目录的新建、删除、复制、移动、改名等 文件判断:判断文件或目录是否非空,是否为目录,是否为文件等等。
绝对路径:针对ClassPath中的文件转换为绝对路径文件。 文件名:主文件名,扩展名的获取
读操作:包括类似IoUtil中的getReader、readXXX操作 写操作:包括getWriter和writeXXX操作
在FileUtil中,我努力将方法名与Linux相一致,例如创建文件的方法并不是createFile,而是touch,这种统一对于熟悉Linux的人来说,大大提高了上手速度。当然,如果你不熟悉Linux,那FileUtil工具类的使用则是在帮助你学习Linux命令。这些类Linux命令的方法包括:ls 列出目录和文件 touch 创建文件,如果父目录不存在也自动创建 mkdir 创建目录,会递归创建每层目录 del
删除文件或目录(递归删除,不判断是否为空),这个方法相当于Linux的delete命令 copy 拷贝文件或目录
这些方法提供了人性化的操作,例如touch方法,在创建文件的情况下会自动创建上层目录(我想对于使用者来说这也是大部分情况下的需求),同样mkdir也会创建父目录。需要注意的是,del方法会删除目录而不判断其是否为空,这一方面方便了使用,另一方面也可能造成一些预想不到的后果(比如拼写错路径而删除不应该删除的目录),所以请谨慎使用此方法。
关于FileUtil中更多工具方法,请参阅API文档。
文件类型判断-FileTypeUtil
File file = FileUtil.file("d:/test.jpg");
String type = FileTypeUtil.getType(file);
//输出 jpg则说明确实为jpg文件
Console.log(type);
文件读取-FileReader
FileReader提供了以下方法来快速读取文件内容:
readBytes readString readLines
同时,此类还提供了以下方法用于转换为流或者BufferedReader:getReader getInputStream
//默认UTF-8编码,可以在构造中传入第二个参数做为编码
FileReader fileReader = new FileReader("test.properties");
String result = fileReader.readString();
文件写入-FileWriter
写入文件分为追加模式和覆盖模式两类,追加模式可以用append方法,覆盖模式可以用write方法,同时也提供了一个write方法,第二个参数是可选覆盖模式。
同样,此类提供了:
getOutputStream getWriter getPrintWriter 这些方法用于转换为相应的类提供更加灵活的写入操作。
FileWriter writer = new FileWriter("test.properties");
writer.write("test");
文件追加-FileAppender
由来
顾名思义,FileAppender类表示文件追加器。此对象持有一个一个文件,在内存中积累一定量的数据后统一追加到文件,此类只有在写入文件时打开文件,并在写入结束后关闭之。因此此类不需要关闭。在调用append方法后会缓存于内存,只有超过容量后才会一次性写入文件,因此内存中随时有剩余未写入文件的内容,在最后必须调用flush方法将剩余内容刷入文件。
也就是说,这是一个支持缓存的文件内容追加器。此类主要用于类似于日志写出这类需求所用。
FileAppender appender = new FileAppender(file, 16, true);
appender.append("123");
appender.append("abc");
appender.append("xyz");
appender.flush();
appender.toString();
工具类
字符串工具-StrUtil
- hasBlank、hasEmpty方法
就是给定一些字符串,如果一旦有空的就返回true,常用于判断好多字段是否有空的(例如web表单数据)。
这两个方法的区别是hasEmpty只判断是否为null或者空字符串(""),hasBlank则会把不可见字符也算做空,isEmpty和isBlank同理。
- removePrefix、removeSuffix方法
这两个是去掉字符串的前缀后缀的,例如去个文件名的扩展名啥。
String fileName = StrUtil.removeSuffix(“pretty_girl.jpg”, “.jpg”) //fileName -> pretty_girl
Copy to clipboardErrorCopied
还有忽略大小写的removePrefixIgnoreCase和removeSuffixIgnoreCase都比较实用。
- sub方法
不得不提一下这个方法,有人说String有了subString你还写它干啥,我想说subString方法越界啥的都会报异常,你还得自己判断,难受死了,我把各种情况判断都加进来了,而且index的位置还支持负数哦,-1表示最后一个字符(这个思想来自于Python,如果学过Python的应该会很喜欢的),还有就是如果不小心把第一个位置和第二个位置搞反了,也会自动修正(例如想截取第4个和第2个字符之间的部分也是可以的哦~) 举个栗子
String str = "abcdefgh";
String strSub1 = StrUtil.sub(str, 2, 3); //strSub1 -> c
String strSub2 = StrUtil.sub(str, 2, -3); //strSub2 -> cde
String strSub3 = StrUtil.sub(str, 3, 2); //strSub2 -> c
-
str、bytes方法
好吧,我承认把String.getByte(String charsetName)方法封装在这里了,原生的String.getByte()这个方法太坑了,使用系统编码,经常会有人跳进来导致乱码问题,所以我就加了这两个方法强制指定字符集了,包了个try抛出一个运行时异常,省的我得在我业务代码里处理那个恶心的UnsupportedEncodingException。 -
format方法
我会告诉你这是我最引以为豪的方法吗?灵感来自slf4j,可以使用字符串模板代替字符串拼接,我也自己实现了一个,而且变量的标识符都一样,神马叫无缝兼容~~来,上栗子(吃多了上火吧……)
String template = "{}爱{},就像老鼠爱大米";
String str = StrUtil.format(template, "我", "你"); //str -> 我爱你,就像老鼠爱大米
- 定义的一些常量
为了方便,我定义了一些比较常见的字符串常量在里面,像点、空串、换行符等等,还有HTML中的一些转移字符。
更多方法请参阅API文档。
16进制工具-HexUtil
String str = "我是一个字符串";
String hex = HexUtil.encodeHexStr(str, CharsetUtil.CHARSET_UTF_8);
//hex是:
//e68891e698afe4b880e4b8aae5ad97e7aca6e4b8b2
String decodedStr = HexUtil.decodeHexStr(hex);
//解码后与str相同
Escape工具-EscapeUtil
介绍 转义和反转义工具类Escape / Unescape。escape采用ISO
Latin字符集对指定的字符串进行编码。所有的空格符、标点符号、特殊字符以及其他非ASCII字符都将被转化成%xx格式的字符编码(xx等于该字符在字符集表里面的编码的16进制数字)。此类中的方法对应Javascript中的escape()函数和unescape()函数。
方法
-
EscapeUtil.escape Escape编码(Unicode),该方法不会对 ASCII 字母和数字进行编码,也不会对下面这些 ASCII 标点符号进行编码: * @ - _ + . / 。其他所有的字符都会被转义序列替换。
-
EscapeUtil.unescape Escape解码。
-
EscapeUtil.safeUnescape 安全的unescape文本,当文本不是被escape的时候,返回原文。
Hash算法-HashUtil
方法
这些算法包括:
- additiveHash 加法hash
- rotatingHash 旋转hash
- oneByOneHash 一次一个hash
- bernstein Bernstein’s hash
- universal Universal Hashing
- zobrist Zobrist Hashing
- fnvHash 改进的32位FNV算法1
- intHash Thomas Wang的算法,整数hash
- rsHash RS算法hash
- jsHash JS算法
- pjwHash PJW算法
- elfHash ELF算法
- bkdrHash BKDR算法
- sdbmHash SDBM算法
- djbHash DJB算法
- dekHash DEK算法
- apHash AP算法
- tianlHash TianL Hash算法
- javaDefaultHash JAVA自己带的算法
- mixHash 混合hash算法,输出64位的值
URL工具-URLUtil
方法
获取URL对象
- URLUtil.url 通过一个字符串形式的URL地址创建对象
- URLUtil.getURL 主要获得ClassPath下资源的URL,方便读取Classpath下的配置文件等信息。
其它 - URLUtil.normalize 标准化化URL链接。对于不带http://头的地址做简单补全。
String url = "http://www.hutool.cn//aaa/bbb";
// 结果为:http://www.hutool.cn/aaa/bbb
String normalize = URLUtil.normalize(url);
url = "http://www.hutool.cn//aaa/\\bbb?a=1&b=2";
// 结果为:http://www.hutool.cn/aaa/bbb?a=1&b=2
normalize = URLUtil.normalize(url);
- URLUtil.encode 封装URLEncoder.encode,将需要转换的内容(ASCII码形式之外的内容),用十六进制表示法转换出来,并在之前加上%开头。
String body = "366466 - 副本.jpg";
// 结果为:366466%20-%20%E5%89%AF%E6%9C%AC.jpg
String encode = URLUtil.encode(body);
- URLUtil.decode 封装URLDecoder.decode,将%开头的16进制表示的内容解码。
- URLUtil.getPath 获得path部分 URI -> http://www.aaa.bbb/search?scope=ccc&q=ddd PATH -> /search
- URLUtil.toURI 转URL或URL字符串为URI。
反射工具-ReflectUtil
获取某个类的所有方法
Method[] methods = ReflectUtil.getMethods(ExamInfoDict.class);
获取某个类的指定方法
Method method = ReflectUtil.getMethod(ExamInfoDict.class, "getId");
构造对象
ReflectUtil.newInstance(ExamInfoDict.class);
执行方法
class TestClass {
private int a;
public int getA() {
return a;
}
public void setA(int a) {
this.a = a;
}
}
TestClass testClass = new TestClass();
ReflectUtil.invoke(testClass, "setA", 10);
数字工具-NumberUtil
加减乘除
- NumberUtil.add 针对double类型做加法
- NumberUtil.sub 针对double类型做减法
- NumberUtil.mul 针对double类型做乘法
- NumberUtil.div 针对double类型做除法,并提供重载方法用于规定除不尽的情况下保留小数位数和舍弃方式。
以上四种运算都会将double转为BigDecimal后计算,解决float和double类型无法进行精确计算的问题。这些方法常用于商业计算。
保留小数
保留小数的方法主要有两种:
- NumberUtil.round 方法主要封装BigDecimal中的方法来保留小数,返回double,这个方法更加灵活,可以选择四舍五入或者全部舍弃等模式。
double te1=123456.123456;
double te2=123456.128456;
Console.log(round(te1,4));//结果:123456.1235
Console.log(round(te2,4));//结果:123456.1285
- NumberUtil.roundStr 方法主要封装String.format方法,舍弃方式采用四舍五入。
double te1=123456.123456;
double te2=123456.128456;
Console.log(roundStr(te1,2));//结果:123456.12
Console.log(roundStr(te2,2));//结果:123456.13
decimalFormat
针对 DecimalFormat.format进行简单封装。按照固定格式对double或long类型的数字做格式化操作。
long c=299792458;//光速
String format = NumberUtil.decimalFormat(",###", c);//299,792,458
格式中主要以 # 和 0 两种占位符号来指定数字长度。0 表示如果位数不足则以 0 填充,# 表示只要有可能就把数字拉上这个位置。
- 0 -> 取一位整数
- 0.00 -> 取一位整数和两位小数
- 00.000 -> 取两位整数和三位小数
- #-> 取所有整数部分
- #.##% -> 以百分比方式计数,并取两位小数
- #.#####E0 -> 显示为科学计数法,并取五位小数
- ,### -> 每三位以逗号进行分隔,例如:299,792,458
- 光速大小为每秒,###米 -> 将格式嵌入文本
是否为数字
- NumberUtil.isNumber 是否为数字
- NumberUtil.isInteger 是否为整数
- NumberUtil.isDouble 是否为浮点数
- NumberUtil.isPrimes 是否为质数
随机数
- NumberUtil.generateRandomNumber 生成不重复随机数 根据给定的最小数字和最大数字,以及随机数的个数,产生指定的不重复的数组。
- NumberUtil.generateBySet 生成不重复随机数 根据给定的最小数字和最大数字,以及随机数的个数,产生指定的不重复的数组。
整数列表
NumberUtil.range 方法根据范围和步进,生成一个有序整数列表。 NumberUtil.appendRange 将给定范围内的整数添加到已有集合中
其它
- NumberUtil.factorial 阶乘
- NumberUtil.sqrt 平方根
- NumberUtil.divisor 最大公约数
- NumberUtil.multiple 最小公倍数
- NumberUtil.getBinaryStr 获得数字对应的二进制字符串
- NumberUtil.binaryToInt 二进制转int
- NumberUtil.binaryToLong 二进制转long
- NumberUtil.compare 比较两个值的大小
- NumberUtil.toStr 数字转字符串,自动并去除尾小数点儿后多余的0
数组工具-ArrayUtil
判空
数组的判空类似于字符串的判空,标准是null或者数组长度为0,ArrayUtil中封装了针对原始类型和泛型数组的判空和判非空:
int[] a = {};
int[] b = null;
ArrayUtil.isEmpty(a);
ArrayUtil.isEmpty(b);
int[] a = {1,2};
ArrayUtil.isNotEmpty(a);
新建泛型数组
Array.newInstance并不支持泛型返回值,在此封装此方法使之支持泛型返回值。
String[] newArray = ArrayUtil.newArray(String.class, 3);
调整大小
使用 ArrayUtil.resize方法生成一个新的重新设置大小的数组。
合并数组
ArrayUtil.addAll方法采用可变参数方式,将多个泛型数组合并为一个数组。
克隆
数组本身支持clone方法,因此确定为某种类型数组时调用ArrayUtil.clone(T[]),不确定类型的使用ArrayUtil.clone(T),两种重载方法在实现上有所不同,但是在使用中并不能感知出差别。
- 泛型数组调用原生克隆
Integer[] b = {1,2,3};
Integer[] cloneB = ArrayUtil.clone(b);
Assert.assertArrayEquals(b, cloneB);
- 非泛型数组(原始类型数组)调用第二种重载方法
int[] a = {1,2,3};
int[] clone = ArrayUtil.clone(a);
Assert.assertArrayEquals(a, clone);
有序列表生成
ArrayUtil.range方法有三个重载,这三个重载配合可以实现支持步进的有序数组或者步进为1的有序数组。这种列表生成器在Python中做为语法糖存在。
拆分数组
ArrayUtil.split方法用于拆分一个byte数组,将byte数组平均分成几等份,常用于消息拆分。
过滤
ArrayUtil.filter方法用于编辑已有数组元素,只针对泛型数组操作,原始类型数组并未提供。 方法中Editor接口用于返回每个元素编辑后的值,返回null此元素将被抛弃。
一个大栗子:过滤数组,只保留偶数
Integer[] a = {1,2,3,4,5,6};
Integer[] filter = ArrayUtil.filter(a, new Editor<Integer>(){
@Override
public Integer edit(Integer t) {
return (t % 2 == 0) ? t : null;
}});
Assert.assertArrayEquals(filter, new Integer[]{2,4,6});
zip
ArrayUtil.zip方法传入两个数组,第一个数组为key,第二个数组对应位置为value,此方法在Python中为zip()函数。
String[] keys = {"a", "b", "c"};
Integer[] values = {1,2,3};
Map<String, Integer> map = ArrayUtil.zip(keys, values, true);
//{a=1, b=2, c=3}
是否包含元素
ArrayUtil.contains方法只针对泛型数组,检测指定元素是否在数组中。
包装和拆包
在原始类型元素和包装类型中,Java实现了自动包装和拆包,但是相应的数组无法实现,于是便是用ArrayUtil.wrap和ArrayUtil.unwrap对原始类型数组和包装类型数组进行转换。
判断对象是否为数组
ArrayUtil.isArray方法封装了obj.getClass().isArray()。
转为字符串
-
ArrayUtil.toString 通常原始类型的数组输出为字符串时无法正常显示,于是封装此方法可以完美兼容原始类型数组和包装类型数组的转为字符串操作。
-
ArrayUtil.join 方法使用间隔符将一个数组转为字符串,比如[1,2,3,4]这个数组转为字符串,间隔符使用“-”的话,结果为 1-2-3-4,join方法同样支持泛型数组和原始类型数组。
toArray
ArrayUtil.toArray方法针对ByteBuffer转数组提供便利。
随机工具-RandomUtil
说明
RandomUtil主要针对JDK中Random对象做封装,严格来说,Java产生的随机数都是伪随机数,因此Hutool封装后产生的随机结果也是伪随机结果。不过这种随机结果对于大多数情况已经够用。
使用
- RandomUtil.randomInt 获得指定范围内的随机数
- RandomUtil.randomBytes 随机bytes
- RandomUtil.randomEle 随机获得列表中的元素
- RandomUtil.randomEleSet 随机获得列表中的一定量的不重复元素,返回Set
- RandomUtil.randomString 获得一个随机的字符串(只包含数字和字符)
- RandomUtil.randomNumbers 获得一个只包含数字的字符串
- RandomUtil.randomUUID 随机UUID
- RandomUtil.weightRandom 权重随机生成器,传入带权重的对象,然后根据权重随机获取对象
唯一ID工具-IdUtil
介绍
在分布式环境中,唯一ID生成应用十分广泛,生成方法也多种多样,Hutool针对一些常用生成策略做了简单封装。
唯一ID生成器的工具类,涵盖了:
- UUID
- ObjectId(MongoDB)
- Snowflake(Twitter)
使用
UUID
UUID全称通用唯一识别码(universally unique identifier),JDK通过java.util.UUID提供了 Leach-Salz 变体的封装。在Hutool中,生成一个UUID字符串方法如下:
//生成的UUID是带-的字符串,类似于:a5c8a5e8-df2b-4706-bea4-08d0939410e3
String uuid = IdUtil.randomUUID();
//生成的是不带-的字符串,类似于:b17f24ff026d40949c85a24f4f375d42
String simpleUUID = IdUtil.simpleUUID();
说明 Hutool重写java.util.UUID的逻辑,对应类为cn.hutool.core.lang.UUID,使生成不带-的UUID字符串不再需要做字符替换,性能提升一倍左右。
ObjectId
ObjectId是MongoDB数据库的一种唯一ID生成策略,是UUID version1的变种,详细介绍可见:服务化框架-分布式Unique ID的生成方法一览。
Hutool针对此封装了cn.hutool.core.lang.ObjectId,快捷创建方法为:
//生成类似:5b9e306a4df4f8c54a39fb0c
String id = ObjectId.next();
//方法2:从Hutool-4.1.14开始提供
String id2 = IdUtil.objectId();
Snowflake
分布式系统中,有一些需要使用全局唯一ID的场景,有些时候我们希望能使用一种简单一些的ID,并且希望ID能够按照时间有序生成。Twitter的Snowflake 算法就是这种生成器。
使用方法如下:
//参数1为终端ID
//参数2为数据中心ID
Snowflake snowflake = IdUtil.createSnowflake(1, 1);
long id = snowflake.nextId();
压缩工具-ZipUtil
由来
在Java中,对文件、文件夹打包,压缩是一件比较繁琐的事情,我们常常引入Zip4j进行此类操作。但是很多时候,JDK中的zip包就可满足我们大部分需求。ZipUtil就是针对java.util.zip做工具化封装,使压缩解压操作可以一个方法搞定,并且自动处理文件和目录的问题,不再需要用户判断,压缩后的文件也会自动创建文件,自动创建父目录,大大简化的压缩解压的复杂度。
方法
Zip
- 压缩
ZipUtil.zip 方法提供一系列的重载方法,满足不同需求的压缩需求,这包括:
- 打包到当前目录(可以打包文件,也可以打包文件夹,根据路径自动判断)
//将aaa目录下的所有文件目录打包到d:/aaa.zip
ZipUtil.zip("d:/aaa");
- 指定打包后保存的目的地,自动判断目标是文件还是文件夹
//将aaa目录下的所有文件目录打包到d:/bbb/目录下的aaa.zip文件中
// 此处第二个参数必须为文件,不能为目录
ZipUtil.zip("d:/aaa", "d:/bbb/aaa.zip");
//将aaa目录下的所有文件目录打包到d:/bbb/目录下的ccc.zip文件中
ZipUtil.zip("d:/aaa", "d:/bbb/ccc.zip");
- 可选是否包含被打包的目录。比如我们打包一个照片的目录,打开这个压缩包有可能是带目录的,也有可能是打开压缩包直接看到的是文件。zip方法增加一个boolean参数可选这两种模式,以应对众多需求。
//将aaa目录以及其目录下的所有文件目录打包到d:/bbb/目录下的ccc.zip文件中
ZipUtil.zip("d:/aaa", "d:/bbb/ccc.zip", true);
- 多文件或目录压缩。可以选择多个文件或目录一起打成zip包。
ZipUtil.zip(FileUtil.file("d:/bbb/ccc.zip"), false,
FileUtil.file("d:/test1/file1.txt"),
FileUtil.file("d:/test1/file2.txt"),
FileUtil.file("d:/test2/file1.txt"),
FileUtil.file("d:/test2/file2.txt")
);
- 解压
ZipUtil.unzip 解压。同样提供几个重载,满足不同需求。
//将test.zip解压到e:\\aaa目录下,返回解压到的目录
File unzip = ZipUtil.unzip("E:\\aaa\\test.zip", "e:\\aaa");
Gzip
Gzip是网页传输中广泛使用的压缩方式,Hutool同样提供其工具方法简化其过程。
ZipUtil.gzip 压缩,可压缩字符串,也可压缩文件 ZipUtil.unGzip 解压Gzip文件
Zlib
ZipUtil.zlib 压缩,可压缩字符串,也可压缩文件 ZipUtil.unZlib 解压zlib文件
注意 ZipUtil默认情况下使用系统编码,也就是说:
如果你在命令行下运行,则调用系统编码(一般Windows下为GBK、Linux下为UTF-8)
如果你在IDE(如Eclipse)下运行代码,则读取的是当前项目的编码(详细请查阅IDE设置,我的项目默认都是UTF-8编码,因此解压和压缩都是用这个编码)
正则工具-ReUtil
由来
在文本处理中,正则表达式几乎是全能的,但是Java的正则表达式有时候处理一些事情还是有些繁琐,所以我封装了部分常用功能。就比如说我要匹配一段文本中的某些部分,我们需要这样做:
String content = "ZZZaaabbbccc中文1234";
Pattern pattern = Pattern.compile(regex, Pattern.DOTALL);
Matcher matcher = pattern.matcher(content);
if (matcher.find()) {
String result= matcher.group();
}
其中牵涉到多个对象,想用的时候真心记不住。好吧,既然功能如此常用,我就封装一下:
/**
* 获得匹配的字符串
*
* @param pattern 编译后的正则模式
* @param content 被匹配的内容
* @param groupIndex 匹配正则的分组序号
* @return 匹配后得到的字符串,未匹配返回null
*/
public static String get(Pattern pattern, String content, int groupIndex) {
Matcher matcher = pattern.matcher(content);
if (matcher.find()) {
return matcher.group(groupIndex);
}
return null;
}
/**
* 获得匹配的字符串
*
* @param regex 匹配的正则
* @param content 被匹配的内容
* @param groupIndex 匹配正则的分组序号
* @return 匹配后得到的字符串,未匹配返回null
*/
public static String get(String regex, String content, int groupIndex) {
Pattern pattern = Pattern.compile(regex, Pattern.DOTALL);
return get(pattern, content, groupIndex);
}
使用
ReUtil.extractMulti
抽取多个分组然后把它们拼接起来
String content = "ZZZaaabbbccc中文1234";
String resultExtractMulti = ReUtil.extractMulti("(\\w)aa(\\w)", content, "$1-$2");
Assert.assertEquals("Z-a", resultExtractMulti);
ReUtil.delFirst
删除第一个匹配到的内容
String content = "ZZZaaabbbccc中文1234";
String resultDelFirst = ReUtil.delFirst("(\\w)aa(\\w)", content);
Assert.assertEquals("ZZbbbccc中文1234", resultDelFirst);
ReUtil.findAll
查找所有匹配文本
String content = "ZZZaaabbbccc中文1234";
List<String> resultFindAll = ReUtil.findAll("\\w{2}", content, 0, new ArrayList<String>());
// 结果:["ZZ", "Za", "aa", "bb", "bc", "cc", "12", "34"]
ReUtil.getFirstNumber
找到匹配的第一个数字
Integer resultGetFirstNumber = ReUtil.getFirstNumber(content);
// 结果:1234
ReUtil.isMatch
给定字符串是否匹配给定正则
String content = "ZZZaaabbbccc中文1234";
boolean isMatch = ReUtil.isMatch("\\w+[\u4E00-\u9FFF]+\\d+", content);
Assert.assertTrue(isMatch);
ReUtil.replaceAll
通过正则查找到字符串,然后把匹配到的字符串加入到replacementTemplate中,$1表示分组1的字符串
String content = "ZZZaaabbbccc中文1234";
//此处把1234替换为 ->1234<-
String replaceAll = ReUtil.replaceAll(content, "(\\d+)", "->$1<-");
Assert.assertEquals("ZZZaaabbbccc中文->1234<-", replaceAll);
ReUtil.escape
转义给定字符串,为正则相关的特殊符号转义
String escape = ReUtil.escape("我有个$符号{}");
// 结果:我有个\\$符号\\{\\}
身份证工具-IdcardUtil
由来
在日常开发中,我们对身份证的验证主要是正则方式(位数,数字范围等),但是中国身份证,尤其18位身份证每一位都有严格规定,并且最后一位为校验位。而我们在实际应用中,针对身份证的验证理应严格至此。于是IdcardUtil应运而生。
介绍
IdcardUtil现在支持大陆15位、18位身份证,港澳台10位身份证。
工具中主要的方法包括:
- isValidCard 验证身份证是否合法
- convert15To18 身份证15位转18位
- getBirthByIdCard 获取生日
- getAgeByIdCard 获取年龄
- getYearByIdCard 获取生日年
- getMonthByIdCard 获取生日月
- getDayByIdCard 获取生日天
- getGenderByIdCard 获取性别
- getProvinceByIdCard 获取省份
使用
String ID_18 = "321083197812162119";
String ID_15 = "150102880730303";
//是否有效
boolean valid = IdcardUtil.isValidCard(ID_18);
boolean valid15 = IdcardUtil.isValidCard(ID_15);
//转换
String convert15To18 = IdcardUtil.convert15To18(ID_15);
Assert.assertEquals(convert15To18, "150102198807303035");
//年龄
DateTime date = DateUtil.parse("2017-04-10");
int age = IdcardUtil.getAgeByIdCard(ID_18, date);
Assert.assertEquals(age, 38);
int age2 = IdcardUtil.getAgeByIdCard(ID_15, date);
Assert.assertEquals(age2, 28);
//生日
String birth = IdcardUtil.getBirthByIdCard(ID_18);
Assert.assertEquals(birth, "19781216");
String birth2 = IdcardUtil.getBirthByIdCard(ID_15);
Assert.assertEquals(birth2, "19880730");
//省份
String province = IdcardUtil.getProvinceByIdCard(ID_18);
Assert.assertEquals(province, "江苏");
String province2 = IdcardUtil.getProvinceByIdCard(ID_15);
Assert.assertEquals(province2, "内蒙古");
控制台打印封装-Console
由来
编码中我们常常需要调试输出一些信息,除了打印日志,最长用的要数System.out和System.err
但是面对纷杂的打印需求,System.out.println无法满足,比如:
- 不支持参数,对象打印需要拼接字符串
- 不能直接打印数组,需要手动调用Arrays.toString
使用
String[] a = {"abc", "bcd", "def"};
Console.log(a);//控制台输出:[abc, bcd, def]
Console.log("This is Console log for {}.", "test");
//控制台输出:This is Console log for test.
Console.error 这个方法基本等同于System.err.println,,但是支持类似于Slf4j的字符串模板语法,同时也会自动将对象(包括数组)转为字符串形式。
字段验证器-Validator
作用
验证给定字符串是否满足指定条件,一般用在表单字段验证里。
此类中全部为静态方法。
使用
判断验证
直接调用Validator.isXXX(String value)既可验证字段,返回是否通过验证。
例如:
boolean isEmail = Validator.isEmail("[email protected]")
如果Validator里的方法无法满足自己的需求,那还可以调用
Validator.isMactchRegex("需要验证字段的正则表达式", "被验证内容")
异常验证
除了手动判断,我们有时需要在判断未满足条件时抛出一个异常,Validator同样提供异常验证机制:
Validator.validateChinese("我是一段zhongwen", "内容中包含非中文");
因为内容中包含非中文字符,因此会抛出ValidateException。
Bean工具-BeanUtil
什么是Bean
把一个拥有对属性进行set和get方法的类,我们就可以称之为JavaBean。实际上JavaBean就是一个Java类,在这个Java类中就默认形成了一种规则——对属性进行设置和获得。而反之将说Java类就是一个JavaBean,这种说法是错误的,因为一个java类中不一定有对属性的设置和获得的方法(也就是不一定有set和get方法)。通常Java中对Bean的定义是包含setXXX和getXXX方法的对象,在Hutool中,采取一种简单的判定Bean的方法:是否存在只有一个参数的setXXX方法。
Bean工具类主要是针对这些setXXX和getXXX方法进行操作,比如将Bean对象转为Map等等。
方法
是否为Bean对象
BeanUtil.isBean方法根据是否存在只有一个参数的setXXX方法或者public类型的字段来判定是否是一个Bean对象。这样的判定方法主要目的是保证至少有一个setXXX方法用于属性注入。
boolean isBean = BeanUtil.isBean(HashMap.class);//false
内省 Introspector
把一类中需要进行设置和获得的属性访问权限设置为private(私有的)让外部的使用者看不见摸不着,而通过public(共有的)set和get方法来对其属性的值来进行设置和获得,而内部的操作具体是怎样的?外界使用的人不用不知道,这就称为内省。
Hutool中对内省的封装包括:
- BeanUtil.getPropertyDescriptors 获得Bean字段描述数组
PropertyDescriptor[] propertyDescriptors = BeanUtil.getPropertyDescriptors(SubPerson.class);
- BeanUtil.getFieldNamePropertyDescriptorMap 获得字段名和字段描述Map
- BeanUtil.getPropertyDescriptor 获得Bean类指定属性描述
Bean属性注入
BeanUtil.fillBean方法是bean注入的核心方法,此方法传入一个ValueProvider接口,通过实现此接口来获得key对应的值。CopyOptions参数则提供一些注入属性的选项。
CopyOptions的配置项包括:
- editable 限制的类或接口,必须为目标对象的实现接口或父类,用于限制拷贝的属性,例如一个类我只想复制其父类的一些属性,就可以将editable设置为父类。
- ignoreNullValue 是否忽略空值,当源对象的值为null时,true: 忽略而不注入此值,false: 注入null
- ignoreProperties 忽略的属性列表,设置一个属性列表,不拷贝这些属性值
- ignoreError 是否忽略字段注入错误
可以通过CopyOptions.create()方法创建一个默认的配置项,通过setXXX方法设置每个配置项。
ValueProvider接口需要实现两个方法:
- value方法是通过key和目标类型来从任何地方获取一个值,并转换为目标类型,如果返回值不和目标类型匹配,将会自动调用Convert.convert方法转换。
- containsKey方法主要是检测是否包含指定的key,如果不包含这个key,其对应的属性将会忽略注入。
首先定义两个bean:
// Lombok注解
@Data
public class Person{
private String name;
private int age;
}
// Lombok注解
@Data
public class SubPerson extends Person {
public static final String SUBNAME = "TEST";
private UUID id;
private String subName;
private Boolean isSlow;
}
然后注入这个bean:
Person person = BeanUtil.fillBean(new Person(), new ValueProvider<String>(){
@Override
public Object value(String key, Class<?> valueType) {
switch (key) {
case "name":
return "张三";
case "age":
return 18;
}
return null;
}
@Override
public boolean containsKey(String key) {
//总是存在key
return true;
}
}, CopyOptions.create());
Assert.assertEquals(person.getName(), "张三");
Assert.assertEquals(person.getAge(), 18);
同时,Hutool还提供了BeanUtil.toBean方法,此处并不是传Bean对象,而是Bean类,Hutool会自动调用默认构造方法创建对象。
基于BeanUtil.fillBean方法Hutool还提供了Map对象键值对注入Bean,其方法有:
- BeanUtil.fillBeanWithMap 使用Map填充bean
HashMap<String, Object> map = CollUtil.newHashMap();
map.put("name", "Joe");
map.put("age", 12);
map.put("openId", "DFDFSDFWERWER");
SubPerson person = BeanUtil.fillBeanWithMap(map, new SubPerson(), false);
- BeanUtil.fillBeanWithMapIgnoreCase 使用Map填充bean,忽略大小写
HashMap<String, Object> map = CollUtil.newHashMap();
map.put("Name", "Joe");
map.put("aGe", 12);
map.put("openId", "DFDFSDFWERWER");
SubPerson person = BeanUtil.fillBeanWithMapIgnoreCase(map, new SubPerson(), false);
同时提供了map转bean的方法,与fillBean不同的是,此处并不是传Bean对象,而是Bean类,Hutool会自动调用默认构造方法创建对象。当然,前提是Bean类有默认构造方法(空构造),这些方法有:
- BeanUtil.mapToBean
HashMap<String, Object> map = CollUtil.newHashMap();
map.put("a_name", "Joe");
map.put("b_age", 12);
// 设置别名,用于对应bean的字段名
HashMap<String, String> mapping = CollUtil.newHashMap();
mapping.put("a_name", "name");
mapping.put("b_age", "age");
Person person = BeanUtil.mapToBean(map, Person.class, CopyOptions.create().setFieldMapping(mapping));
- BeanUtil.mapToBeanIgnoreCase
HashMap<String, Object> map = CollUtil.newHashMap();
map.put("Name", "Joe");
map.put("aGe", 12);
Person person = BeanUtil.mapToBeanIgnoreCase(map, Person.class, false);
Bean转为Map
BeanUtil.beanToMap方法则是将一个Bean对象转为Map对象。
SubPerson person = new SubPerson();
person.setAge(14);
person.setOpenid("11213232");
person.setName("测试A11");
person.setSubName("sub名字");
Map<String, Object> map = BeanUtil.beanToMap(person);
Bean转Bean
Bean之间的转换主要是相同属性的复制,因此方法名为copyProperties,此方法支持Bean和Map之间的字段复制。
BeanUtil.copyProperties方法同样提供一个CopyOptions参数用于自定义属性复制。
SubPerson p1 = new SubPerson();
p1.setSlow(true);
p1.setName("测试");
p1.setSubName("sub测试");
Map<String, Object> map = MapUtil.newHashMap();
BeanUtil.copyProperties(p1, map);
Alias注解
5.x的Hutool中增加了一个自定义注解:Alias,通过此注解可以给Bean的字段设置别名。
首先我们给Bean加上注解:
// Lombok注解
@Getter
@Setter
public static class SubPersonWithAlias {
@Alias("aliasSubName")
private String subName;
private Boolean slow;
SubPersonWithAlias person = new SubPersonWithAlias();
person.setSubName("sub名字");
person.setSlow(true);
// Bean转换为Map时,自动将subName修改为aliasSubName
Map<String, Object> map = BeanUtil.beanToMap(person);
// 返回"sub名字"
map.get("aliasSubName")
同样Alias注解支持注入Bean时的别名:
Map<String, Object> map = MapUtil.newHashMap();
map.put("aliasSubName", "sub名字");
map.put("slow", true);
SubPersonWithAlias subPersonWithAlias = BeanUtil.mapToBean(map, SubPersonWithAlias.class, false);
// 返回"sub名字"
subPersonWithAlias.getSubName();
集合工具-CollUtil
介绍
这个工具主要增加了对数组、集合类的操作。
- join 方法
将集合转换为字符串,这个方法还是挺常用,是StrUtil.split的反方法。这个方法的参数支持各种类型对象的集合,最后连接每个对象时候调用其toString()方法。栗子如下:
String[] col= new String[]{"a","b","c","d","e"};
List<String> colList = CollUtil.newArrayList(col);
String str = CollUtil.join(colList, "#"); //str -> a#b#c#d#e
- sortPageAll、sortPageAll2方法
这个方法其实是一个真正的组合方法,功能是:将给定的多个集合放到一个列表(List)中,根据给定的Comparator对象排序,然后分页取数据。这个方法非常类似于数据库多表查询后排序分页,这个方法存在的意义也是在此。sortPageAll2功能和sortPageAll的使用方式和结果是 一样的,区别是sortPageAll2使用了BoundedPriorityQueue这个类来存储组合后的列表,不知道哪种性能更好一些,所以就都保留了。使用此方法,栗子如下:
//Integer比较器
Comparator<Integer> comparator = new Comparator<Integer>(){
@Override
public int compare(Integer o1, Integer o2) {
return o1.compareTo(o2);
}
};
//新建三个列表,CollUtil.newArrayList方法表示新建ArrayList并填充元素
List<Integer> list1 = CollUtil.newArrayList(1, 2, 3);
List<Integer> list2 = CollUtil.newArrayList(4, 5, 6);
List<Integer> list3 = CollUtil.newArrayList(7, 8, 9);
//参数表示把list1,list2,list3合并并按照从小到大排序后,取0~2个(包括第0个,不包括第2个),结果是[1,2]
@SuppressWarnings("unchecked")
List<Integer> result = CollUtil.sortPageAll(0, 2, comparator, list1, list2, list3);
System.out.println(result); //输出 [1,2]
-
sortEntrySetToList方法
这个方法主要是对Entry -
popPart方法
这个方法传入一个栈对象,然后弹出指定数目的元素对象,弹出是指pop()方法,会从原栈中删掉。
5.newHashMap、newHashSet、newArrayList方法
这些方法是新建相应的数据结构,数据结构元素的类型取决于你变量的类型,例子如下:
HashMap<String, String> map = CollUtil.newHashMap();
HashSet<String> set = CollUtil.newHashSet();
ArrayList<String> list = CollUtil.newArrayList();
-
append方法
在给定数组里末尾加一个元素,其实List.add()也是这么实现的,这个方法存在的意义是只有少量的添加元素时使用,因为内部使用了System.arraycopy,每调用一次就要拷贝数组一次。这个方法也是为了在某些只能使用数组的情况下使用,省去了先要转成List,添加元素,再转成Array。 -
resize方法
重新调整数据的大小,如果调整后的大小比原来小,截断,如果比原来大,则多出的位置空着。(貌似List在扩充的时候会用到类似的方法) -
addAll方法
将多个数据合并成一个数组 -
sub方法
对集合切片,其他类型的集合会转换成List,封装List.subList方法,自动修正越界等问题,完全避免IndexOutOfBoundsException异常。 -
isEmpty、isNotEmpty方法
判断集合是否为空(包括null和没有元素的集合)。 -
zip方法
此方法也是来源于Python的一个语法糖,给定两个集合,然后两个集合中的元素一一对应,成为一个Map。此方法还有一个重载方法,可以传字符,然后给定分分隔符,字符串会被split成列表。栗子:
String[] keys = new String[]{"a", "b", "c"};
Integer[] values = new Integer[]{1, 2, 3};
Map<String, Integer> map = CollUtil.zip(keys,values);
System.out.println(map); // {b=2, c=3, a=1}
String a = "a,b,c";
String b = "1,2,3";
Map<String, String> map2 = CollUtil.zip(a,b, ",");
System.out.println(map2); // {b=2, c=3, a=1}
- filter方法
此方法可以过滤map,排除不需要的key。栗子:
@Test
public void CollUtil_Filter() {
Map<String, Object> m = new HashMap<String, Object>() {{
put("k1", "v1");
put("k2", "v2");
put("k3", "v3");
}};
String[] inc = {"k1", "k3"};//需要的key
List<String> incList = Arrays.asList(inc);
m = CollectionUtil.filter(m, new Editor<Map.Entry<String, Object>>() {
@Override
public Map.Entry<String, Object> edit(Map.Entry<String, Object> stringObjectEntry) {
if (incList.contains(stringObjectEntry.getKey())) {
return stringObjectEntry;
}
return null;
}
});
log.info("{}", m);
}
结果
{k3=v3, k1=v1}
列表工具-ListUtil
- 过滤列表
List<String> a = ListUtil.toLinkedList("1", "2", "3");
// 结果: [edit1, edit2, edit3]
List<String> filter = ListUtil.filter(a, str -> "edit" + str);
- 获取满足指定规则所有的元素的位置
List<String> a = ListUtil.toLinkedList("1", "2", "3", "4", "3", "2", "1");
// [1, 5]
int[] indexArray = ListUtil.indexOfAll(a, "2"::equals);
Iterator工具-IterUtil
方法介绍
- isEmpty 是否为null或者无元素
- isNotEmpty 是否为非null或者至少一个元素
- hasNull 是否有null元素
- isAllNull 是否全部为null元素
- countMap 根据集合返回一个元素计数的Map,所谓元素计数就是假如这个集合中某个元素出现了n -次,那将这个元素做为key,n做为value
- join 使用分隔符将集合转换为字符串
- toMap toMap Entry列表转Map,或者key和value单独列表转Map
- asIterator Enumeration转Iterator
- asIterable Iterator转Iterable
- getFirst 获取列表的第一个元素
- getElementType 获取元素类型
Map工具-MapUtil
方法
- isEmpty、isNotEmpty 判断Map为空和非空方法,空的定义为null或没有值
- newHashMap 快速创建多种类型的HashMap实例
- createMap 创建自定义的Map类型的Map
- of 此方法将一个或多个键值对加入到一个新建的Map中,下面是栗子:
Map<Object, Object> colorMap = MapUtil.of(new String[][] {
{"RED", "#FF0000"},
{"GREEN", "#00FF00"},
{"BLUE", "#0000FF"}
});
- toListMap 行转列,合并相同的键,值合并为列表,将Map列表中相同key的值组成列表做为Map的value,例如传入数据是:
[
{a: 1, b: 1, c: 1}
{a: 2, b: 2}
{a: 3, b: 3}
{a: 4}
]
结果为:
{
a: [1,2,3,4]
b: [1,2,3,]
c: [1]
}
- toMapList 列转行。将Map中值列表分别按照其位置与key组成新的map,例如传入数据:
{
a: [1,2,3,4]
b: [1,2,3,]
c: [1]
}
结果为:
[
{a: 1, b: 1, c: 1}
{a: 2, b: 2}
{a: 3, b: 3}
{a: 4}
]
- join、joinIgnoreNull 将Map按照给定的分隔符转换为字符串
- filter 过滤过程通过传入的Editor实现来返回需要的元素内容,这个Editor实现可以实现以下功能:1、过滤出需要的对象,如果返回null表示这个元素对象抛弃 2、修改元素对象,返回集合中为修改后的对象
- reverse Map的键和值互换
- sort 排序Map
- getAny 获取Map的部分key生成新的Map
- get、getXXX 获取Map中指定类型的值
双向查找Map-BiMap
介绍
我们知道在Guava中提供了一种特使的Map结构,叫做BiMap,它实现了一种双向查找的功能,即根据key查找value和根据value查找key,Hutool也同样提供此对象。
BiMap要求key和value都不能重复(非强制要求),如果key重复了,后加入的键值对会覆盖之前的键值对,如果value重复了,则会按照不确定的顺序覆盖key,这完全取决于map实现。比如HashMap无序(按照hash顺序),则谁覆盖谁和hash算法有关;如果是LinkedHashMap,则有序,是后加入的覆盖先加入的。
使用
BiMap<String, Integer> biMap = new BiMap<>(new HashMap<>());
biMap.put("aaa", 111);
biMap.put("bbb", 222);
// 111
biMap.get("aaa");
// 222
biMap.get("bbb");
// aaa
biMap.getKey(111);
// bbb
biMap.getKey(222);
Base62编码解码-Base62
介绍
Base62编码是由10个数字、26个大写英文字母和26个小写英文字母组成,多用于安全领域和短URL生成。
使用
在这里插入代码片String a = "伦家是一个非常长的字符串66";
// 17vKU8W4JMG8dQF8lk9VNnkdMOeWn4rJMva6F0XsLrrT53iKBnqo
String encode = Base62.encode(a);
// 还原为a
String decodeStr = Base62.decodeStr(encode);
Base64编码解码-Base64
介绍
Base64编码是用64(2的6次方)个ASCII字符来表示256(2的8次方)个ASCII字符,也就是三位二进制数组经过编码后变为四位的ASCII字符显示,长度比原来增加1/3。
使用
String a = "伦家是一个非常长的字符串";
//5Lym5a625piv5LiA5Liq6Z2e5bi46ZW/55qE5a2X56ym5Liy
String encode = Base64.encode(a);
// 还原为a
String decodeStr = Base64.decodeStr(encode);
Base32编码解码-Base32
介绍
Base32就是用32(2的5次方)个特定ASCII码来表示256个ASCII码。所以,5个ASCII字符经过base32编码后会变为8个字符(公约数为40),长度增加3/5.不足8n用“=”补足。
使用
String a = "伦家是一个非常长的字符串";
String encode = Base32.encode(a);
Assert.assertEquals("4S6KNZNOW3TJRL7EXCAOJOFK5GOZ5ZNYXDUZLP7HTKCOLLMX46WKNZFYWI", encode);
String decodeStr = Base32.decodeStr(encode);
Assert.assertEquals(a, decodeStr);
CSV文件处理工具-CsvUtil
介绍
逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。
Hutool针对此格式,参考FastCSV项目做了对CSV文件读写的实现(Hutool实现完全独立,不依赖第三方)
CsvUtil是CSV工具类,主要封装了两个方法:
- getReader 用于对CSV文件读取
- getWriter 用于生成CSV文件
这两个方法分别获取CsvReader对象和CsvWriter,从而独立完成CSV文件的读写。
使用
读取CSV文件
读取为CsvRow
CsvReader reader = CsvUtil.getReader();
//从文件中读取CSV数据
CsvData data = reader.read(FileUtil.file("test.csv"));
List<CsvRow> rows = data.getRows();
//遍历行
for (CsvRow csvRow : rows) {
//getRawList返回一个List列表,列表的每一项为CSV中的一个单元格(既逗号分隔部分)
Console.log(csvRow.getRawList());
}
CsvRow对象还记录了一些其他信息,包括原始行号等。
读取为Bean列表
首先测试的CSV:test_bean.csv:
姓名,gender,focus,age
张三,男,无,33
李四,男,好对象,23
王妹妹,女,特别关注,22
定义Bean:
// lombok注解
@Data
private static class TestBean{
// 如果csv中标题与字段不对应,可以使用alias注解设置别名
@Alias("姓名")
private String name;
private String gender;
private String focus;
private Integer age;
}
读取:
final CsvReader reader = CsvUtil.getReader();
//假设csv文件在classpath目录下
final List<TestBean> result = reader.read(
ResourceUtil.getUtf8Reader("test_bean.csv"), TestBean.class);
输出:
CsvReaderTest.TestBean(name=张三, gender=男, focus=无, age=33)
CsvReaderTest.TestBean(name=李四, gender=男, focus=好对象, age=23)
CsvReaderTest.TestBean(name=王妹妹, gender=女, focus=特别关注, age=22)
生成CSV文件
//指定路径和编码
CsvWriter writer = CsvUtil.getWriter("e:/testWrite.csv", CharsetUtil.CHARSET_UTF_8);
//按行写出
writer.write(
new String[] {"a1", "b1", "c1"},
new String[] {"a2", "b2", "c2"},
new String[] {"a3", "b3", "c3"}
);
注意 CSV文件本身为一种简单文本格式,有编码区分。Excel读取CSV文件中含有中文时时必须为GBK编码(Windows平台下),否则会出现乱码。
可复用字符串生成器-StrBuilder
介绍
在JDK提供的StringBuilder中,拼接字符串变得更加高效和灵活,但是生成新的字符串需要重新构建StringBuilder对象,造成性能损耗和内存浪费,因此Hutool提供了可复用的StrBuilder。
使用
StrBuilder和StringBuilder使用方法基本一致,只是多了reset方法可以重新构建一个新的字符串而不必开辟新内存。
StrBuilder builder = StrBuilder.create();
builder.append("aaa").append("你好").append('r');
//结果:aaa你好r
Unicode编码转换工具-UnicodeUtil
介绍
此工具主要针对类似于\u4e2d\u6587这类Unicode字符做一些特殊转换。
使用
- 字符串转Unicode符
//第二个参数true表示跳过ASCII字符(只跳过可见字符)
String s = UnicodeUtil.toUnicode("aaa123中文", true);
//结果aaa123\\u4e2d\\u6587
- Unicode转字符串
String str = "aaa\\U4e2d\\u6587\\u111\\urtyu\\u0026";
String res = UnicodeUtil.toString(str);
//结果aaa中文\\u111\\urtyu&
由于\\u111为非Unicode字符串,因此原样输出。
字符串切割-StrSpliter
由来
在Java的String对象中提供了split方法用于通过某种字符串分隔符来把一个字符串分割为数组。但是有的时候我们对这种操作有不同的要求,默认方法无法满足,这包括:
- 分割限制分割数
- 分割后每个字符串是否需要去掉两端空格
- 是否忽略空白片
- 根据固定长度分割
- 通过正则分隔
因此,StrSpliter应运而生。StrSpliter中全部为静态方法,方便快捷调用。
方法
基础方法
split 切分字符串,众多可选参数,返回结果为List splitToArray 切分字符串,返回结果为数组 splitsplitByRegex 根据正则切分字符串 splitByLength 根据固定长度切分字符串
栗子:
String str1 = "a, ,efedsfs, ddf";
//参数:被切分字符串,分隔符逗号,0表示无限制分片数,去除两边空格,忽略空白项
List<String> split = StrSpliter.split(str1, ',', 0, true, true);
注解工具-AnnotationUtil
介绍
封装了注解获取等方法的工具类。
使用
方法介绍
- 注解获取相关方法:
- getAnnotations 获取指定类、方法、字段、构造等上的注解列表
- getAnnotation 获取指定类型注解
- getAnnotationValue 获取指定注解属性的值
例子:
我们定义一个注解:
// Retention注解决定MyAnnotation注解的生命周期
@Retention(RetentionPolicy.RUNTIME)
// Target注解决定MyAnnotation注解可以加在哪些成分上,如加在类身上,或者属性身上,或者方法身上等成分
@Target({ ElementType.METHOD, ElementType.TYPE })
public @interface AnnotationForTest {
/**
* 注解的默认属性值
*
* @return 属性值
*/
String value();
}
给需要的类加上注解:
@AnnotationForTest("测试")
public static class ClassWithAnnotation{
}
获取注解中的值:
// value为"测试"
Object value = AnnotationUtil.getAnnotationValue(ClassWithAnnotation.class, AnnotationForTest.class);
- 注解属性获取相关方法:
-
getRetentionPolicy 获取注解类的保留时间,可选值 SOURCE(源码时),CLASS(编译时),RUNTIME(运行时),默认为 CLASS
-
getTargetType 获取注解类可以用来修饰哪些程序元素,如 TYPE, METHOD, CONSTRUCTOR, FIELD, PARAMETER 等
-
isDocumented 是否会保存到 Javadoc 文档中
-
isInherited 是否可以被继承,默认为 false
异常工具-ExceptionUtil
介绍
针对异常封装,例如包装为RuntimeException。
方法
- getMessage 获得完整消息,包括异常名
- wrap 包装一个异常为指定类型异常
- wrapRuntime 使用运行时异常包装编译异常
- getCausedBy 获取由指定异常类引起的异常
- isCausedBy 判断是否由指定异常类引起
- stacktraceToString 堆栈转为完整字符串
其它方法见API文档:
https://apidoc.gitee.com/loolly/hutool/cn/hutool/core/exceptions/ExceptionUtil.html
线程工具-ThreadUtil
由来
并发在Java中算是一个比较难理解和容易出问题的部分,而并发的核心在线程。好在从JDK1.5开始Java提供了concurrent包可以很好的帮我们处理大部分并发、异步等问题。
不过,ExecutorService和Executors等众多概念依旧让我们使用这个包变得比较麻烦,如何才能隐藏这些概念?又如何用一个方法解决问题?ThreadUtil便为此而生。
原理
Hutool使用GlobalThreadPool持有一个全局的线程池,默认所有异步方法在这个线程池中执行。
方法:
-
ThreadUtil.execute
直接在公共线程池中执行线程 -
ThreadUtil.newExecutor
获得一个新的线程池 -
ThreadUtil.excAsync
执行异步方法 -
ThreadUtil.newCompletionService
创建CompletionService,调用其submit方法可以异步执行多个任务,最后调用take方法按照完成的顺序获得其结果。若未完成,则会阻塞。 -
ThreadUtil.newCountDownLatch
新建一个CountDownLatch,一个同步辅助类,在完成一组正在其他线程中执行的操作之前,它允许一个或多个线程一直等待。 -
ThreadUtil.sleep
挂起当前线程,是Thread.sleep的封装,通过返回boolean值表示是否被打断,而不是抛出异常。
ThreadUtil.safeSleep方法是一个保证挂起足够时间的方法,当给定一个挂起时间,使用此方法可以保证挂起的时间大于或等于给定时间,解决Thread.sleep挂起时间不足问题,此方法在Hutool-cron的定时器中使用保证定时任务执行的准确性。
- ThreadUtil.getStackTrace
此部分包括两个方法:
- getStackTrace 获得堆栈列表
- getStackTraceElement 获得堆栈项
其它
- createThreadLocal 创建本地线程对象
- interupt 结束线程,调用此方法后,线程将抛出InterruptedException异常
- waitForDie 等待线程结束. 调用 Thread.join() 并忽略 InterruptedException
- getThreads 获取JVM中与当前线程同组的所有线程
- getMainThread 获取进程的主线程
图片工具-ImgUtil
介绍
针对awt中图片处理进行封装,这些封装包括:缩放、裁剪、转为黑白、加水印等操作。
方法介绍
- scale 缩放图片
提供两种重载方法:其中一个是按照长宽缩放,另一种是按照比例缩放。
ImgUtil.scale(
FileUtil.file("d:/face.jpg"),
FileUtil.file("d:/face_result.jpg"),
0.5f//缩放比例
);
- cut 剪裁图片
ImgUtil.cut(
FileUtil.file("d:/face.jpg"),
FileUtil.file("d:/face_result.jpg"),
new Rectangle(200, 200, 100, 100)//裁剪的矩形区域
);
- slice 按照行列剪裁切片(将图片分为20行和20列)
ImgUtil.slice(FileUtil.file("e:/test2.png"), FileUtil.file("e:/dest/"), 10, 10);
- convert 图片类型转换,支持GIF->JPG、GIF->PNG、PNG->JPG、PNG->GIF(X)、BMP->PNG等
ImgUtil.convert(FileUtil.file("e:/test2.png"), FileUtil.file("e:/test2Convert.jpg"));
- gray 彩色转为黑白
ImgUtil.gray(FileUtil.file("d:/logo.png"), FileUtil.file("d:/result.png"));
- pressText 添加文字水印
ImgUtil.pressText(//
FileUtil.file("e:/pic/face.jpg"), //
FileUtil.file("e:/pic/test2_result.png"), //
"版权所有", Color.WHITE, //文字
new Font("黑体", Font.BOLD, 100), //字体
0, //x坐标修正值。 默认在中间,偏移量相对于中间偏移
0, //y坐标修正值。 默认在中间,偏移量相对于中间偏移
0.8f//透明度:alpha 必须是范围 [0.0, 1.0] 之内(包含边界值)的一个浮点数字
);
- pressImage 添加图片水印
ImgUtil.pressImage(
FileUtil.file("d:/picTest/1.jpg"),
FileUtil.file("d:/picTest/dest.jpg"),
ImgUtil.read(FileUtil.file("d:/picTest/1432613.jpg")), //水印图片
0, //x坐标修正值。 默认在中间,偏移量相对于中间偏移
0, //y坐标修正值。 默认在中间,偏移量相对于中间偏移
0.1f
);
- rotate 旋转图片
// 旋转180度
BufferedImage image = ImgUtil.rotate(ImageIO.read(FileUtil.file("e:/pic/366466.jpg")), 180);
ImgUtil.write(image, FileUtil.file("e:/pic/result.png"));
- flip 水平翻转图片
ImgUtil.flip(FileUtil.file("d:/logo.png"), FileUtil.file("d:/result.png"));
图片编辑器-Img
介绍
针对awt中图片处理进行封装,这些封装包括:缩放、裁剪、转为黑白、加水印等操作。
方法介绍
图像切割
// 将face.jpg切割为原型保存为face_radis.png
Img.from(FileUtil.file("e:/pic/face.jpg"))
.cut(0, 0, 200)//
.write(FileUtil.file("e:/pic/face_radis.png"));
图片压缩
图片压缩只支持Jpg文件。
Img.from(FileUtil.file("e:/pic/1111.png"))
.setQuality(0.8)//压缩比率
.write(FileUtil.file("e:/pic/1111_target.jpg"));
网络工具-NetUtil
由来
在日常开发中,网络连接这块儿必不可少。日常用到的一些功能,隐藏掉部分IP地址、绝对相对路径的转换等等。
介绍
NetUtil 工具中主要的方法包括:
- longToIpv4 根据long值获取ip v4地址
- ipv4ToLong 根据ip地址计算出long型的数据
- isUsableLocalPort 检测本地端口可用性
- isValidPort 是否为有效的端口
- isInnerIP 判定是否为内网IP
- localIpv4s 获得本机的IP地址列表
- toAbsoluteUrl 相对URL转换为绝对URL
- hideIpPart 隐藏掉IP地址的最后一部分为 * 代替
- buildInetSocketAddress 构建InetSocketAddress
- getIpByHost 通过域名得到IP
- isInner 指定IP的long是否在指定范围内
使用
String ip= "127.0.0.1";
long iplong = 2130706433L;
//根据long值获取ip v4地址
String ip= NetUtil.longToIpv4(iplong);
//根据ip地址计算出long型的数据
long ip= NetUtil.ipv4ToLong(ip);
//检测本地端口可用性
boolean result= NetUtil.isUsableLocalPort(6379);
//是否为有效的端口
boolean result= NetUtil.isValidPort(6379);
//隐藏掉IP地址
String result =NetUtil.hideIpPart(ip);
配置文件(Hutool-setting)
概述
由来
Setting
众所周知,Java中广泛应用的配置文件Properties存在一个特别大的诟病:不支持中文。每次使用时,如果想存放中文字符,必须借助IDE相关插件才能转为Unicode符号,而这种反人类的符号在命令行下根本没法看(想想部署在服务器上后修改配置文件是一件多么痛苦的事情)
于是,在很多框架中开始渐渐抛弃Properties文件而转向XML配置文件(例如Hibernate和Spring早期版本)。但是XML罗嗦的配置方式实在无法忍受。于是,Setting诞生。
Props
Properties的第二个问题是读取非常不方便,需要我们自己写长长的代码进行load操作:
properties = new Properties();
try {
Class clazz = Demo1.class;
InputStream inputestream = clazz.getResourceAsStream("db.properties");
properties.load( inputestream);
}catch (IOException e) {
//ignore
}
而Props则大大简化为:
Props props = new Props("db.properties");
考虑到Properties使用依旧广泛,因此封装了Props类以应对兼容性。
设置文件-Setting
简介
Setting除了兼容Properties文件格式外,还提供了一些特有功能,这些功能包括:
- 各种编码方式支持
- 变量支持
- 分组支持
首先说编码支持,在Properties中,只支ISO8859-1导致在Properties文件中注释和value没法使用中文,(用日本的那个插件在Eclipse里可以读写,放到服务器上读就费劲了),因此Setting中引入自定义编码,可以很好的支持各种编码的配置文件。
再就是变量支持,在Setting中,支持${key}变量,可以将之前定义的键对应的值做为本条值得一部分,这个特性可以减少大量的配置文件冗余。
最后是分组支持。分组的概念我第一次在Linux的rsync的/etc/rsyncd.conf配置文件中有所了解,发现特别实用,具体大家可以自行百度之。当然,在Windows的ini文件中也有分组的概念,Setting将这一概念引入,从而大大增加配置文件的可读性。
配置文件格式example.setting
# -------------------------------------------------------------
# ----- Setting File with UTF8-----
# ----- 数据库配置文件 -----
# -------------------------------------------------------------
#中括表示一个分组,其下面的所有属性归属于这个分组,在此分组名为demo,也可以没有分组
[demo]
#自定义数据源设置文件,这个文件会针对当前分组生效,用于给当前分组配置单独的数据库连接池参数,没有则使用全局的配置
ds.setting.path = config/other.setting
#数据库驱动名,如果不指定,则会根据url自动判定
driver = com.mysql.jdbc.Driver
#JDBC url,必须
url = jdbc:mysql://fedora.vmware:3306/extractor
#用户名,必须
user = root${demo.driver}
#密码,必须,如果密码为空,请填写 pass =
pass = 123456
配置文件可以放在任意位置,具体Setting类如何寻在在构造方法中提供了多种读取方式,具体稍后介绍。现在说下配置文件的具体格式 Setting配置文件类似于Properties文件,规则如下:
- 注释用#开头表示,只支持单行注释,空行和无法正常被识别的键值对也会被忽略,可作为注释,但是 建议显式指定注释。同时在value之后不允许有注释,会被当作value的一部分。
- 键值对使用key = value 表示,key和value在读取时会trim掉空格,所以不用担心空格。
- 分组为中括号括起来的内容(例如配置文件中的[demo]),中括号以下的行都为此分组的内容,无分组相当于空字符分组,即[]。若某个key是name,分组是group,加上分组后的key相当于group.name。
- 支持变量,默认变量命名为 变 量 名 , 变 量 只 能 识 别 读 入 行 的 变 量 , 例 如 第 6 行 的 变 量 在 第 三 行 无 法 读 取 , 例 如 配 置 文 件 中 的 {变量名},变量只能识别读入行的变量,例如第6行的变量在第三行无法读取,例如配置文件中的 变量名,变量只能识别读入行的变量,例如第6行的变量在第三行无法读取,例如配置文件中的{driver}会被替换为com.mysql.jdbc.Driver,为了性能,Setting创建的时候构造方法会指定是否开启变量替换,默认不开启。
代码
代码具体请见cn.hutool.setting.test.SettingTest
- Setting初始化
//读取classpath下的XXX.setting,不使用变量
Setting setting = new Setting("XXX.setting");
//读取classpath下的config目录下的XXX.setting,不使用变量
setting = new Setting("config/XXX.setting");
//读取绝对路径文件/home/looly/XXX.setting(没有就创建,关于touc请查阅FileUtil)
//第二个参数为自定义的编码,请保持与Setting文件的编码一致
//第三个参数为是否使用变量,如果为true,则配置文件中的每个key都以被之后的条目中的value引用形式为 ${key}
setting = new Setting(FileUtil.touc("/home/looly/XXX.setting"), CharsetUtil.CHARSET_UTF_8, true);
//读取与SettingDemo.class文件同包下的XXX.setting
setting = new Setting("XXX.setting", SettingDemo.class,CharsetUtil.CHARSET_UTF_8, true);
- Setting读取配置参数
//获取key为name的值
setting.getStr("name");
//获取分组为group下key为name的值
setting.getByGroup("name", "group1");
//当获取的值为空(null或者空白字符时,包括多个空格),返回默认值
setting.getStr("name", "默认值");
//完整的带有key、分组和默认值的获得值得方法
setting.getStr("name", "group1", "默认值");
//如果想获得其它类型的值,可以调用相应的getXXX方法,参数相似
//有时候需要在key对应value不存在的时候(没有这项设置的时候)告知户,故有此方法打印一个debug日志
setting.getWithLog("name");
setting.getByGroupWithLog("name", "group1");
//获取分组下所有配置键值对,组成新的Setting
setting.getSetting("group1")
- 重新加载配置和保存配置
//重新读取配置文件
setting.reload();
//在配置文件变更时自动加载
setting.autoLoad(true);
//当通过代码加入新的键值对的时候,调用store会保存到文件,但是会盖原来的文件,并丢失注释
setting.set("name1", "value");
setting.store("/home/looly/XXX.setting");
//获得所有分组名
setting.getGroups();
//将key-value映射为对象,原理是原理是调用对象对应的setXX方法
UserVO userVo = new UserVo();
setting.toBean(userVo);
//设定变量名的正则表达式。
//Setting的变量替换是通过正则查找替换的,如果Setting中的变量名其他冲突,可以改变变量的定义方式
//整个正则匹配变量名,分组1匹配key的名字
setting.setVarRegex("\\$\\{(.*?)\\}");
Properties扩展-Props
介绍
对于Properties的广泛使用使我也无能为力,有时候遇到Properties文件又想方便的读写也不容易,于是对Properties做了简单的封装,提供了方便的构造方法(与Setting一致),并提供了与Setting一致的getXXX方法来扩展Properties类,Props类继承自Properties,所以可以兼容Properties类。
使用
Props的使用方法和Properties以及Setting一致(同时支持):
Props props = new Props("test.properties");
String user = props.getProperty("user");
String driver = props.getStr("driver");
日志(Hutool-log)
概述
由来
准确的说,Hutool-log只是一个日志的通用门面,功能类似于Slf4j。既然像Slf4j这种门面框架已经非常完善,为何还要自己做一个门面呢?下面我列举实践中遇到的一些问题:
已有门面存在问题
- log对象创建比较复杂
很多时候我们为了在类中加日志不得不写一行,而且还要去手动改XXX这个类名
private static final Logger log = LoggerFactory.getLogger(XXX.class);
- 对于附带Exception参数的方法,并不支持变量。
Slf4j中我最喜欢的形式,这样既省去了麻烦的isInfoEnabled()的判断,还避免了拼接字符串:
log.info("我在XXX 改了 {} 变量", "name");
但是这种情况下就无法使用变量模式:
log.error("错误消息", e);
特点
Logfactory.get方法不再需要(或者不是必须)传入当前类名,会自定解析当前类名
log.xxx方法在传入Exception时同时支持模板语法。
不需要桥接包而自动适配引入的日志框架,在无日志框架下依旧可以完美适配JDK Logging。
引入多个日志框架情况下,可以自定义日志框架输出。
原理
Hutool-log采用动态自动适配模式,它会自动检测引入的日志框架包从而将日志输出到此框架。 比如我们在项目中引入Log4j的包,Hutool-log会自动检测到此包的存在,并将日志输出到log4j。如果没有引入任何日志框架,会将日志输出到JDK Logging中。
因此,Hutool-log并没有统一的配置文件,如果你引入任何一种日志框架,使用此框架的配置文件即可。
Hutool-log对于日志框架的监测顺序是: Slf4j(Logback) > Log4j > Log4j2 > Apache Commons Logging > JDK Logging > Console
当然,如果只是引入Slf4j-API,而没有引入任何实现,Slf4j将被跳过。
使用
常规使用
Hutool-log的使用与一般日志框架并无区别,调用LogFactory.get()即可简单获取Log实现对象。
Log log = LogFactory.get();
log.debug("This is {} log", Level.DEBUG);
log.info("This is {} log", Level.INFO);
log.warn("This is {} log", Level.WARN);
Exception e = new Exception("test Exception");
log.error(e, "This is {} log", Level.ERROR);
自定义日志实现
有的时候,我们需要自定义日志框架输出,这是我们就需要调用LogFactory.setCurrentLogFactory方法来定义全局的日志实现。
// 自动选择日志实现
Log log = LogFactory.get();
log.debug("This is {} log", "default");
Console.log("----------------------------------------------------------------------");
//自定义日志实现为Apache Commons Logging
LogFactory.setCurrentLogFactory(new ApacheCommonsLogFactory());
log.debug("This is {} log", "custom apache commons logging");
Console.log("----------------------------------------------------------------------");
//自定义日志实现为JDK Logging
LogFactory.setCurrentLogFactory(new JdkLogFactory());
log.info("This is {} log", "custom jdk logging");
Console.log("----------------------------------------------------------------------");
//自定义日志实现为Console Logging
LogFactory.setCurrentLogFactory(new ConsoleLogFactory());
log.info("This is {} log", "custom Console");
Console.log("----------------------------------------------------------------------");
日志工厂-LogFactory
介绍
Hutool-log做为一个日志门面,为了兼容各大日志框架,一个用于自动创建日志对象的日志工厂类必不可少。
LogFactory类用于灵活的创建日志对象,通过static方法创建我们需要的日志,主要功能如下:
-
LogFactory.get 自动识别引入的日志框架,从而创建对应日志框架的门面Log对象(此方法创建一次后,下次再次get会根据传入类名缓存Log对象,对于每个类,Log对象都是单例的),同时自动识别当前类,将当前类做为类名传入日志框架。
-
LogFactory.createLog 与get方法作用类似。但是此方法调用后会每次创建一个新的Log对象。
-
LogFactory.setCurrentLogFactory 自定义当前日志门面的日志实现类。当引入多个日志框架时,我们希望自定义所用的日志框架,调用此方法即可。需要注意的是,此方法为全局方法,在获取Log对象前只调用一次即可。
使用
获取当前类对应的Log对象:
//推荐创建不可变静态类成员变量
private static final Log log = LogFactory.get();
如果你想获得自定义name的Log对象(像普通Log日志实现一样),那么可以使用如下方式获取Log:
private static final Log log = LogFactory.get("我是一个自定义日志名");
自定义日志实现
//自定义日志实现为Apache Commons Logging
LogFactory.setCurrentLogFactory(new ApacheCommonsLogFactory());
//自定义日志实现为JDK Logging
LogFactory.setCurrentLogFactory(new JdkLogFactory());
//自定义日志实现为Console Logging
LogFactory.setCurrentLogFactory(new ConsoleLogFactory());
自定义日志工厂(自定义日志门面实现)
LogFactory是一个抽象类,我们可以继承此类,实现createLog方法即可(同时我们可能需要实现Log接口来达到自定义门面的目的),这样我们就可以自定义一个日志门面。最后通过LogFactory.setCurrentLogFactory方法装入这个自定义LogFactory即可实现自定义日志门面。
静态调用日志-StaticLog
由来
很多时候,我们只是想简简单的使用日志,最好一个方法搞定,我也不想创建Log对象,那么StaticLog或许是你需要的。
使用
StaticLog.info("This is static {} log.", "INFO");
同样StaticLog提供了trace、debug、info、warn、error方法,提供变量占位符支持,使项目中日志的使用简单到没朋友。
StaticLog类中同样提供log方法,可能在极致简洁的状况下,提供非常棒的灵活性(打印日志等级由level参数决定)
与LogFactory同名方法
假如你只知道StaticLog,不知道LogFactory怎么办?Hutool非常贴心的提供了get方法,此方法与Logfactory中的get方法一样,同样可以获得Log对象。
缓存(Hutool-cache)
概述
来源
Hutool-cache模块最早受到jodd-cache的启发(如今大部分逻辑依旧与jodd保持一致),此模块提供一种缓存的简单实现方案,在小型项目中对于简单的缓存需求非常好用。
介绍
Hutoo-cache模块提供了几种缓存策略实现:
- FIFOCache
FIFO(first in first out) 先进先出策略。元素不停的加入缓存直到缓存满为止,当缓存满时,清理过期缓存对象,清理后依旧满则删除先入的缓存(链表首部对象)。
优点:简单快速 缺点:不灵活,不能保证最常用的对象总是被保留
-
LFUCache
LFU(least frequently used) 最少使用率策略。根据使用次数来判定对象是否被持续缓存(使用率是通过访问次数计算),当缓存满时清理过期对象,清理后依旧满的情况下清除最少访问(访问计数最小)的对象并将其他对象的访问数减去这个最小访问数,以便新对象进入后可以公平计数。 -
LRUCache
LRU (least recently used)最近最久未使用缓存。根据使用时间来判定对象是否被持续缓存,当对象被访问时放入缓存,当缓存满了,最久未被使用的对象将被移除。此缓存基于LinkedHashMap,因此当被缓存的对象每被访问一次,这个对象的key就到链表头部。这个算法简单并且非常快,他比FIFO有一个显著优势是经常使用的对象不太可能被移除缓存。缺点是当缓存满时,不能被很快的访问。 -
TimedCache
定时缓存,对被缓存的对象定义一个过期时间,当对象超过过期时间会被清理。此缓存没有容量限制,对象只有在过期后才会被移除 -
WeakCache
弱引用缓存。对于一个给定的键,其映射的存在并不阻止垃圾回收器对该键的丢弃,这就使该键成为可终止的,被终止,然后被回收。丢弃某个键时,其条目从映射中有效地移除。该类使用了WeakHashMap做为其实现,缓存的清理依赖于JVM的垃圾回收。 -
FileCach
FileCach是一个独立的缓存,主要是将小文件以byte[]的形式缓存到内容中,减少文件的访问,以解决频繁读取文件引起的性能问题。
主要实现有:
- LFUFileCache
- LRUFileCache
缓存工具-CacheUtil
概述
CacheUtil是缓存创建的快捷工具类。用于快速创建不同的缓存对象。
使用
//新建FIFOCache
Cache<String,String> fifoCache = CacheUtil.newFIFOCache(3);
先入先出-FIFOCache
介绍
FIFO(first in first out) 先进先出策略。元素不停的加入缓存直到缓存满为止,当缓存满时,清理过期缓存对象,清理后依旧满则删除先入的缓存(链表首部对象)。
优点:简单快速 缺点:不灵活,不能保证最常用的对象总是被保留
使用
Cache<String,String> fifoCache = CacheUtil.newFIFOCache(3);
//加入元素,每个元素可以设置其过期时长,DateUnit.SECOND.getMillis()代表每秒对应的毫秒数,在此为3秒
fifoCache.put("key1", "value1", DateUnit.SECOND.getMillis() * 3);
fifoCache.put("key2", "value2", DateUnit.SECOND.getMillis() * 3);
fifoCache.put("key3", "value3", DateUnit.SECOND.getMillis() * 3);
//由于缓存容量只有3,当加入第四个元素的时候,根据FIFO规则,最先放入的对象将被移除
fifoCache.put("key4", "value4", DateUnit.SECOND.getMillis() * 3);
//value1为null
String value1 = fifoCache.get("key1");
最少使用-LFUCache
介绍
LFU(least frequently used) 最少使用率策略。根据使用次数来判定对象是否被持续缓存(使用率是通过访问次数计算),当缓存满时清理过期对象,清理后依旧满的情况下清除最少访问(访问计数最小)的对象并将其他对象的访问数减去这个最小访问数,以便新对象进入后可以公平计数。
使用
Cache<String, String> lfuCache = CacheUtil.newLFUCache(3);
//通过实例化对象创建
//LFUCache lfuCache = new LFUCache(3);
lfuCache.put("key1", "value1", DateUnit.SECOND.getMillis() * 3);
lfuCache.get("key1");//使用次数+1
lfuCache.put("key2", "value2", DateUnit.SECOND.getMillis() * 3);
lfuCache.put("key3", "value3", DateUnit.SECOND.getMillis() * 3);
lfuCache.put("key4", "value4", DateUnit.SECOND.getMillis() * 3);
//由于缓存容量只有3,当加入第四个元素的时候,根据LRU规则,最少使用的将被移除(2,3被移除)
String value2 = lfuCache.get("key2");//null
String value3 = lfuCache.get("key3");//null
最近最久未使用-LRUCache
介绍
LRU (least recently used)最近最久未使用缓存。根据使用时间来判定对象是否被持续缓存,当对象被访问时放入缓存,当缓存满了,最久未被使用的对象将被移除。此缓存基于LinkedHashMap,因此当被缓存的对象每被访问一次,这个对象的key就到链表头部。这个算法简单并且非常快,他比FIFO有一个显著优势是经常使用的对象不太可能被移除缓存。缺点是当缓存满时,不能被很快的访问。
使用
Cache<String, String> lruCache = CacheUtil.newLRUCache(3);
//通过实例化对象创建
//LRUCache lruCache = new LRUCache(3);
lruCache.put("key1", "value1", DateUnit.SECOND.getMillis() * 3);
lruCache.put("key2", "value2", DateUnit.SECOND.getMillis() * 3);
lruCache.put("key3", "value3", DateUnit.SECOND.getMillis() * 3);
lruCache.get("key1");//使用时间推近
lruCache.put("key4", "value4", DateUnit.SECOND.getMillis() * 3);
//由于缓存容量只有3,当加入第四个元素的时候,根据LRU规则,最少使用的将被移除(2被移除)
String value2 = lruCache.get("key");//null
超时-TimedCache
介绍
定时缓存,对被缓存的对象定义一个过期时间,当对象超过过期时间会被清理。此缓存没有容量限制,对象只有在过期后才会被移除。
使用
//创建缓存,默认4毫秒过期
TimedCache<String, String> timedCache = CacheUtil.newTimedCache(4);
//实例化创建
//TimedCache timedCache = new TimedCache(4);
timedCache.put("key1", "value1", 1);//1毫秒过期
timedCache.put("key2", "value2", DateUnit.SECOND.getMillis() * 5);
timedCache.put("key3", "value3");//默认过期(4毫秒)
//启动定时任务,每5毫秒秒检查一次过期
timedCache.schedulePrune(5);
//等待5毫秒
ThreadUtil.sleep(5);
//5毫秒后由于value2设置了5毫秒过期,因此只有value2被保留下来
String value1 = timedCache.get("key1");//null
String value2 = timedCache.get("key2");//value2
//5毫秒后,由于设置了默认过期,key3只被保留4毫秒,因此为null
String value3 = timedCache.get("key3");//null
//取消定时清理
timedCache.cancelPruneSchedule();
如果用户在超时前调用了get(key)方法,会重头计算起始时间。举个例子,用户设置key1的超时时间5s,用户在4s的时候调用了get(“key1”),此时超时时间重新计算,再过4s调用get(“key1”)方法值依旧存在。如果想避开这个机制,请调用get(“key1”, false)方法。
说明 如果启动了定时器,那会定时清理缓存中的过期值,但是如果不起动,那只有在get这个值得时候才检查过期并清理。不起动定时器带来的问题是:有些值如果长时间不访问,会占用缓存的空间。
弱引用-WeakCache
介绍
弱引用缓存。对于一个给定的键,其映射的存在并不阻止垃圾回收器对该键的丢弃,这就使该键成为可终止的,被终止,然后被回收。丢弃某个键时,其条目从映射中有效地移除。该类使用了WeakHashMap做为其实现,缓存的清理依赖于JVM的垃圾回收。
使用
与TimedCache使用方法一致:
WeakCache<String, String> weakCache = CacheUtil.newWeakCache(DateUnit.SECOND.getMillis() * 3);
WeakCache也可以像TimedCache一样设置定时清理时间,同时具备垃圾回收清理。
文件缓存-FileCache
介绍
FileCache主要是将小文件以byte[]的形式缓存到内存中,减少文件的访问,以解决频繁读取文件引起的性能问题。
实现
- LFUFileCache
- LRUFileCache
使用
//参数1:容量,能容纳的byte数
//参数2:最大文件大小,byte数,决定能缓存至少多少文件,大于这个值不被缓存直接读取
//参数3:超时。毫秒
LFUFileCache cache = new LFUFileCache(1000, 500, 2000);
byte[] bytes = cache.getFileBytes("d:/a.jpg");
LRUFileCache的使用与LFUFileCache一致,不再举例。
JSON(Hutool-json)
JSON工具-JSONUtil
介绍
JSONUtil是针对JSONObject和JSONArray的静态快捷方法集合,在之前的章节我们已经介绍了一些工具方法,在本章节我们将做一些补充。
使用
parseXXX和toXXX
这两种方法主要是针对JSON和其它对象之间的转换。
readXXX
这类方法主要是从JSON文件中读取JSON对象的快捷方法。包括:
- readJSON
- readJSONObject
- readJSONArray
其它方法
除了上面中常用的一些方法,JSONUtil还提供了一些JSON辅助方法:
- quote 对所有双引号做转义处理(使用双反斜杠做转义)
- wrap 包装对象,可以将普通任意对象转为JSON对象
- formatJsonStr 格式化JSON字符串,此方法并不严格检查JSON的格式正确与否
JSON对象-JSONObject
介绍
JSONObject代表一个JSON中的键值对象,这个对象以大括号包围,每个键值对使用,隔开,键与值使用:隔开,一个JSONObject类似于这样:
{
"key1":"value1",
"key2":"value2"
}
此处键部分可以省略双引号,值为字符串时不能省略,为数字或波尔值时不加双引号。
使用
创建
JSONObject json1 = JSONUtil.createObj()
.put("a", "value1")
.put("b", "value2")
.put("c", "value3");
JSONUtil.createObj()是快捷新建JSONObject的工具方法,同样我们可以直接new:
JSONObject json1 = new JSONObject();
...
转换
- JSON字符串解析
String jsonStr = "{\"b\":\"value2\",\"c\":\"value3\",\"a\":\"value1\"}";
//方法一:使用工具类转换
JSONObject jsonObject = JSONUtil.parseObj(jsonStr);
//方法二:new的方式转换
JSONObject jsonObject2 = new JSONObject(jsonStr);
//JSON对象转字符串(一行) jsonObject.toString();
// 也可以美化一下,即显示出带缩进的JSON: jsonObject.toStringPretty();
2. JavaBean解析
首先我们定义一个Bean
```java
// 注解使用Lombok
@Data
public class UserA {
private String name;
private String a;
private Date date;
private List<Seq> sqs;
}
解析为JSON:
UserA userA = new UserA();
userA.setName("nameTest");
userA.setDate(new Date());
userA.setSqs(CollectionUtil.newArrayList(new Seq(null), new Seq("seq2")));
// false表示不跳过空值
JSONObject json = JSONUtil.parseObj(userA, false);
Console.log(json.toStringPretty());
结果:
{
"date": 1585618492295,
"a": null,
"sqs": [
{
"seq": null
},
{
"seq": "seq2"
}
],
"name": "nameTest"
}
可以看到,输出的字段顺序和Bean的字段顺序不一致,如果想保持一致,可以:
// 第二个参数表示保持有序
JSONObject json = JSONUtil.parseObj(userA, false, true);
结果:
{
"name": "nameTest",
"a": null,
"date": 1585618648523,
"sqs": [
{
"seq": null
},
{
"seq": "seq2"
}
]
}
默认的,Hutool将日期输出为时间戳,如果需要自定义日期格式,可以调用:
json.setDateFormat("yyyy-MM-dd HH:mm:ss");
得到结果为:
{
"name": "nameTest",
"a": null,
"date": "2020-03-31 09:41:29",
"sqs": [
{
"seq": null
},
{
"seq": "seq2"
}
]
}
同样,JSONUtil还可以支持以下对象转为JSONObject对象:
- String对象
- Java Bean对象
- Map对象
- XML字符串(使用JSONUtil.parseFromXml方法)
- ResourceBundle(使用JSONUtil.parseFromResourceBundle)
JSONUtil还提供了JSONObject对象转换为其它对象的方法:
- toJsonStr 转换为JSON字符串
- toXmlStr 转换为XML字符串
- toBean 转换为JavaBean
JSON数组-JSONArray
介绍
在JSON中,JSONArray代表一个数组,使用中括号包围,每个元素使用逗号隔开。一个JSONArray类似于这样:
["value1","value2","value3"]
使用
创建
//方法1
JSONArray array = JSONUtil.createArray();
//方法2
JSONArray array = new JSONArray();
array.add("value1");
array.add("value2");
array.add("value3");
//转为JSONArray字符串
array.toString();
转换
String jsonStr = "[\"value1\", \"value2\", \"value3\"]";
JSONArray array = JSONUtil.parseArray(jsonStr);
加密解密(Hutool-crypto)
加密解密工具-SecureUtil
介绍
SecureUtil主要针对常用加密算法构建快捷方式,还有提供一些密钥生成的快捷工具方法。
方法介绍
对称加密
- SecureUtil.aes
- SecureUtil.des
摘要算法
- SecureUtil.md5
- SecureUtil.sha1
- SecureUtil.hmac
- SecureUtil.hmacMd5
- SecureUtil.hmacSha1
非对称加密
- SecureUtil.rsa
- SecureUtil.dsa
UUID
- SecureUtil.simpleUUID 方法提供无“-”的UUID
密钥生成
- SecureUtil.generateKey 针对对称加密生成密钥
- SecureUtil.generateKeyPair 生成密钥对(用于非对称加密)
- SecureUtil.generateSignature 生成签名(用于非对称加密)
其它方法为针对特定加密方法的一些密钥生成和签名相关方法,详细请参阅API文档。
对称加密-SymmetricCrypto
介绍
对称加密(也叫私钥加密)指加密和解密使用相同密钥的加密算法。有时又叫传统密码算法,就是加密密钥能够从解密密钥中推算出来,同时解密密钥也可以从加密密钥中推算出来。而在大多数的对称算法中,加密密钥和解密密钥是相同的,所以也称这种加密算法为秘密密钥算法或单密钥算法。它要求发送方和接收方在安全通信之前,商定一个密钥。对称算法的安全性依赖于密钥,泄漏密钥就意味着任何人都可以对他们发送或接收的消息解密,所以密钥的保密性对通信的安全性至关重要。
对于对称加密,封装了JDK的,具体介绍见:https://docs.oracle.com/javase/7/docs/technotes/guides/security/StandardNames.html#KeyGenerator:
- AES (默认AES/ECB/PKCS5Padding)
- ARCFOUR
- Blowfish
- DES (默认DES/ECB/PKCS5Padding)
- DESede
- RC2
- PBEWithMD5AndDES
- PBEWithSHA1AndDESede
- PBEWithSHA1AndRC2_40
使用
通用使用
以AES算法为例:
String content = "test中文";
//随机生成密钥
byte[] key = SecureUtil.generateKey(SymmetricAlgorithm.AES.getValue()).getEncoded();
//构建
SymmetricCrypto aes = new SymmetricCrypto(SymmetricAlgorithm.AES, key);
//加密
byte[] encrypt = aes.encrypt(content);
//解密
byte[] decrypt = aes.decrypt(encrypt);
//加密为16进制表示
String encryptHex = aes.encryptHex(content);
//解密为字符串
String decryptStr = aes.decryptStr(encryptHex, CharsetUtil.CHARSET_UTF_8);
DESede实现
String content = "test中文";
byte[] key = SecureUtil.generateKey(SymmetricAlgorithm.DESede.getValue()).getEncoded();
SymmetricCrypto des = new SymmetricCrypto(SymmetricAlgorithm.DESede, key);
//加密
byte[] encrypt = des.encrypt(content);
//解密
byte[] decrypt = des.decrypt(encrypt);
//加密为16进制字符串(Hex表示)
String encryptHex = des.encryptHex(content);
//解密为字符串
String decryptStr = des.decryptStr(encryptHex);
AES封装
AES全称高级加密标准(英语:Advanced Encryption Standard,缩写:AES),在密码学中又称Rijndael加密法。
对于Java中AES的默认模式是:AES/ECB/PKCS5Padding,如果使用CryptoJS,请调整为:padding: CryptoJS.pad.Pkcs7
- 快速构建
String content = "test中文";
// 随机生成密钥
byte[] key = SecureUtil.generateKey(SymmetricAlgorithm.AES.getValue()).getEncoded();
// 构建
AES aes = SecureUtil.aes(key);
// 加密
byte[] encrypt = aes.encrypt(content);
// 解密
byte[] decrypt = aes.decrypt(encrypt);
// 加密为16进制表示
String encryptHex = aes.encryptHex(content);
// 解密为字符串
String decryptStr = aes.decryptStr(encryptHex, CharsetUtil.CHARSET_UTF_8);
- 自定义模式和偏移
AES aes = new AES(Mode.CTS, Padding.PKCS5Padding, "0CoJUm6Qyw8W8jud".getBytes(), "0102030405060708".getBytes());
DES封装
DES全称为Data Encryption Standard,即数据加密标准,是一种使用密钥加密的块算法,Java中默认实现为:DES/CBC/PKCS5Padding
DES使用方法与AES一致,构建方法为:
- 快速构建
byte[] key = SecureUtil.generateKey(SymmetricAlgorithm.DES.getValue()).getEncoded();
DES des = SecureUtil.des(key);
- 自定义模式和偏移
DES des = new DES(Mode.CTS, Padding.PKCS5Padding, "0CoJUm6Qyw8W8jud".getBytes(), "01020304".getBytes());
非对称加密-AsymmetricCrypto
介绍
对于非对称加密,最常用的就是RSA和DSA,在Hutool中使用AsymmetricCrypto对象来负责加密解密。
非对称加密有公钥和私钥两个概念,私钥自己拥有,不能给别人,公钥公开。根据应用的不同,我们可以选择使用不同的密钥加密:
-
签名:使用私钥加密,公钥解密。用于让所有公钥所有者验证私钥所有者的身份并且用来防止私钥所有者发布的内容被篡改,但是不用来保证内容不被他人获得。
-
加密:用公钥加密,私钥解密。用于向公钥所有者发布信息,这个信息可能被他人篡改,但是无法被他人获得。
Hutool封装了JDK的,详细见https://docs.oracle.com/javase/7/docs/technotes/guides/security/StandardNames.html#KeyPairGenerator:
- RSA
- DSA
- EC
使用
在非对称加密中,我们可以通过AsymmetricCrypto(AsymmetricAlgorithm algorithm)构造方法,通过传入不同的算法枚举,获得其加密解密器。
当然,为了方便,我们针对最常用的RSA和DSA算法构建了单独的对象:RSA和DSA。
基本使用
我们以RSA为例,介绍使用RSA加密和解密 在构建RSA对象时,可以传入公钥或私钥,当使用无参构造方法时,Hutool将自动生成随机的公钥私钥密钥对:
RSA rsa = new RSA();
//获得私钥
rsa.getPrivateKey()
rsa.getPrivateKeyBase64()
//获得公钥
rsa.getPublicKey()
rsa.getPublicKeyBase64()
//公钥加密,私钥解密
byte[] encrypt = rsa.encrypt(StrUtil.bytes("我是一段测试aaaa", CharsetUtil.CHARSET_UTF_8), KeyType.PublicKey);
byte[] decrypt = rsa.decrypt(encrypt, KeyType.PrivateKey);
//Junit单元测试
//Assert.assertEquals("我是一段测试aaaa", StrUtil.str(decrypt, CharsetUtil.CHARSET_UTF_8));
//私钥加密,公钥解密
byte[] encrypt2 = rsa.encrypt(StrUtil.bytes("我是一段测试aaaa", CharsetUtil.CHARSET_UTF_8), KeyType.PrivateKey);
byte[] decrypt2 = rsa.decrypt(encrypt2, KeyType.PublicKey);
//Junit单元测试
//Assert.assertEquals("我是一段测试aaaa", StrUtil.str(decrypt2, CharsetUtil.CHARSET_UTF_8));
自助生成密钥对
有时候我们想自助生成密钥对可以:
KeyPair pair = SecureUtil.generateKeyPair("RSA");
pair.getPrivate();
pair.getPublic();
签名和验证-Sign
介绍
Hutool针对java.security.Signature做了简化包装,包装类为:Sign,用于生成签名和签名验证。
对于签名算法,Hutool封装了JDK的,具体介绍见:https://docs.oracle.com/javase/7/docs/technotes/guides/security/StandardNames.html#Signature:
使用
byte[] data = "我是一段测试字符串".getBytes();
Sign sign = SecureUtil.sign(SignAlgorithm.MD5withRSA);
//签名
byte[] signed = sign.sign(data);
//验证签名
boolean verify = sign.verify(data, signed);
国密算法工具-SmUtil
介绍
Hutool针对Bouncy Castle做了简化包装,用于实现国密算法中的SM2、SM3、SM4。
国密算法工具封装包括:
非对称加密和签名:SM2
摘要签名算法:SM3
对称加密:SM4
国密算法需要引入Bouncy Castle库的依赖。
使用
引入Bouncy Castle依赖
<dependency>
<groupId>org.bouncycastlegroupId>
<artifactId>bcprov-jdk15onartifactId>
<version>${bouncycastle.version}version>
dependency>
非对称加密SM2
- 使用随机生成的密钥对加密或解密
String text = "我是一段测试aaaa";
SM2 sm2 = SmUtil.sm2();
// 公钥加密,私钥解密
String encryptStr = sm2.encryptBcd(text, KeyType.PublicKey);
String decryptStr = StrUtil.utf8Str(sm2.decryptFromBcd(encryptStr, KeyType.PrivateKey));
- 使用自定义密钥对加密或解密
String text = "我是一段测试aaaa";
KeyPair pair = SecureUtil.generateKeyPair("SM2");
byte[] privateKey = pair.getPrivate().getEncoded();
byte[] publicKey = pair.getPublic().getEncoded();
SM2 sm2 = SmUtil.sm2(privateKey, publicKey);
// 公钥加密,私钥解密
String encryptStr = sm2.encryptBcd(text, KeyType.PublicKey);
String decryptStr = StrUtil.utf8Str(sm2.decryptFromBcd(encryptStr, KeyType.PrivateKey));
摘要加密算法SM3
//结果为:136ce3c86e4ed909b76082055a61586af20b4dab674732ebd4b599eef080c9be
String digestHex = SmUtil.sm3("aaaaa");
对称加密SM4
String content = "test中文";
SymmetricCrypto sm4 = SmUtil.sm4();
String encryptHex = sm4.encryptHex(content);
String decryptStr = sm4.decryptStr(encryptHex, CharsetUtil.CHARSET_UTF_8);
DFA查找(Hutool-dfa)
使用
- 构建关键词树
WordTree tree = new WordTree();
tree.addWord("大");
tree.addWord("大土豆");
tree.addWord("土豆");
tree.addWord("刚出锅");
tree.addWord("出锅");
- 查找关键词
//正文
String text = "我有一颗大土豆,刚出锅的";
情况一:标准匹配,匹配到最短关键词,并跳过已经匹配的关键词
// 匹配到【大】,就不再继续匹配了,因此【大土豆】不匹配
// 匹配到【刚出锅】,就跳过这三个字了,因此【出锅】不匹配(由于刚首先被匹配,因此长的被匹配,最短匹配只针对第一个字相同选最短)
List<String> matchAll = tree.matchAll(text, -1, false, false);
Assert.assertEquals(matchAll.toString(), "[大, 土豆, 刚出锅]");
情况二:匹配到最短关键词,不跳过已经匹配的关键词
// 【大】被匹配,最短匹配原则【大土豆】被跳过,【土豆继续被匹配】
// 【刚出锅】被匹配,由于不跳过已经匹配的词,【出锅】被匹配
matchAll = tree.matchAll(text, -1, true, false);
Assert.assertEquals(matchAll.toString(), "[大, 土豆, 刚出锅, 出锅]");
情况三:匹配到最长关键词,跳过已经匹配的关键词
// 匹配到【大】,由于到最长匹配,因此【大土豆】接着被匹配
// 由于【大土豆】被匹配,【土豆】被跳过,由于【刚出锅】被匹配,【出锅】被跳过
matchAll = tree.matchAll(text, -1, false, true);
Assert.assertEquals(matchAll.toString(), "[大, 大土豆, 刚出锅]");
情况四:匹配到最长关键词,不跳过已经匹配的关键词(最全关键词)
// 匹配到【大】,由于到最长匹配,因此【大土豆】接着被匹配,由于不跳过已经匹配的关键词,土豆继续被匹配
// 【刚出锅】被匹配,由于不跳过已经匹配的词,【出锅】被匹配
matchAll = tree.matchAll(text, -1, true, true);
Assert.assertEquals(matchAll.toString(), "[大, 大土豆, 土豆, 刚出锅, 出锅]");
数据库(Hutool-db)
数据库简单操作-Db
由来
数据库操作不外乎四门功课:增删改查,在Java的世界中,由于JDBC的存在,这项工作变得简单易用,但是也并没有做到使用上的简化。于是出现了JPA(Hibernate)、MyBatis、Jfinal、BeetlSQL等解决框架,或解决多数据库差异问题,或解决SQL维护问题。而Hutool对JDBC的封装,多数为在小型项目中对数据处理的简化,尤其只涉及单表操作时。OK,废话不多,来个Demo感受下。
使用
我们以MySQL为例
- 添加配置文件
Maven项目中在src/main/resources目录下添加db.setting文件(非Maven项目添加到ClassPath中即可):
## db.setting文件
url = jdbc:mysql://localhost:3306/test
user = root
pass = 123456
## 可选配置
# 是否在日志中显示执行的SQL
showSql = true
# 是否格式化显示的SQL
formatSql = false
# 是否显示SQL参数
showParams = true
# 打印SQL的日志等级,默认debug,可以是info、warn、error
sqlLevel = debug
- 引入MySQL JDBC驱动jar
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>${mysql.version}version>
dependency>
- 增删改查
增
Db.use().insert(
Entity.create("user")
.set("name", "unitTestUser")
.set("age", 66)
);
插入数据并返回自增主键:
Db.use().insertForGeneratedKey(
Entity.create("user")
.set("name", "unitTestUser")
.set("age", 66)
);
删
Db.use().del(
Entity.create("user").set("name", "unitTestUser")//where条件
);
改
Db.use().update(
Entity.create().set("age", 88), //修改的数据
Entity.create("user").set("name", "unitTestUser") //where条件
);
查
- 查询全部字段
//user为表名
Db.use().findAll("user");
- 条件查询
Db.use().findAll(Entity.create("user").set("name", "unitTestUser"));
- 模糊查询
Db.use().findLike("user", "name", "Test", LikeType.Contains);
或者:
List<Entity> find = Db.use().find(Entity.create("user").set("name", "like 王%"));
- 分页查询
//Page对象通过传入页码和每页条目数达到分页目的
PageResult<Entity> result = Db.use().page(Entity.create("user").set("age", "> 30"), new Page(10, 20));
- 执行SQL语句
//查询
List<Entity> result = Db.use().query("select * from user where age < ?", 3);
//模糊查询
List<Entity> result = Db.use().query("select * from user where name like ?", "王%");
//新增
Db.use().execute("insert into user values (?, ?, ?)", "张三", 17, 1);
//删除
Db.use().execute("delete from user where name = ?", "张三");
//更新
Db.use().execute("update user set age = ? where name = ?", 3, "张三");
- 事务
Db.use().tx(new TxFunc() {
@Override
public void call(Db db) throws SQLException {
db.insert(Entity.create("user").set("name", "unitTestUser"));
db.update(Entity.create().set("age", 79), Entity.create("user").set("name", "unitTestUser"));
}
});
JDK8中可以用lambda表达式(since:5.x):
Db.use().tx(db -> {
db.insert(Entity.create("user").set("name", "unitTestUser2"));
db.update(Entity.create().set("age", 79), Entity.create("user").set("name", "unitTestUser2"));
});
- 支持命名占位符的SQL执行
有时候使用"?"占位符比较繁琐,且在复杂SQL中很容易出错,Hutool支持使用命名占位符来执行SQL。
Map<String, Object> paramMap = MapUtil.builder("name1", (Object)"张三").put("age", 12).put("subName", "小豆豆").build();
Db.use().query("select * from table where id=@id and name = @name1 and nickName = @subName", paramMap);
在Hutool中,占位符支持以下几种形式:
- :name
- ?name
- @name
- IN查询
我们在执行类似于select * from user where id in 1,2,3这类SQL的时候,Hutool封装如下:
List<Entity> results = db.findAll(
Entity.create("user")
.set("id", "in 1,2,3"));
当然你也可以直接:
List<Entity> results = db.findAll(
Entity.create("user")
.set("id", new long[]{1, 2, 3}));
HTTP客户端(Hutool-http)
Http客户端工具类-HttpUtil
概述
HttpUtil是应对简单场景下Http请求的工具类封装,此工具封装了HttpRequest对象常用操作,可以保证在一个方法之内完成Http请求。
此模块基于JDK的HttpUrlConnection封装完成,完整支持https、代理和文件上传。
使用
请求普通页面
针对最为常用的GET和POST请求,HttpUtil封装了两个方法,
- HttpUtil.get
- HttpUtil.post
这两个方法用于请求普通页面,然后返回页面内容的字符串,同时提供一些重载方法用于指定请求参数(指定参数支持File对象,可实现文件上传,当然仅仅针对POST请求)。
GET请求栗子:
// 最简单的HTTP请求,可以自动通过header等信息判断编码,不区分HTTP和HTTPS
String result1= HttpUtil.get("https://www.baidu.com");
// 当无法识别页面编码的时候,可以自定义请求页面的编码
String result2= HttpUtil.get("https://www.baidu.com", CharsetUtil.CHARSET_UTF_8);
//可以单独传入http参数,这样参数会自动做URL编码,拼接在URL中
HashMap<String, Object> paramMap = new HashMap<>();
paramMap.put("city", "北京");
String result3= HttpUtil.get("https://www.baidu.com", paramMap);
POST请求例子:
HashMap<String, Object> paramMap = new HashMap<>();
paramMap.put("city", "北京");
String result= HttpUtil.post("https://www.baidu.com", paramMap);
文件上传
HashMap<String, Object> paramMap = new HashMap<>();
//文件上传只需将参数中的键指定(默认file),值设为文件对象即可,对于使用者来说,文件上传与普通表单提交并无区别
paramMap.put("file", FileUtil.file("D:\\face.jpg"));
String result= HttpUtil.post("https://www.baidu.com", paramMap);
下载文件
因为Hutool-http机制问题,请求页面返回结果是一次性解析为byte[]的,如果请求URL返回结果太大(比如文件下载),那内存会爆掉,因此针对文件下载HttpUtil单独做了封装。文件下载在面对大文件时采用流的方式读写,内存中只是保留一定量的缓存,然后分块写入硬盘,因此大文件情况下不会对内存有压力。
String fileUrl = "http://mirrors.sohu.com/centos/7.3.1611/isos/x86_64/CentOS-7-x86_64-DVD-1611.iso";
//将文件下载后保存在E盘,返回结果为下载文件大小
long size = HttpUtil.downloadFile(fileUrl, FileUtil.file("e:/"));
System.out.println("Download size: " + size);
当然,如果我们想感知下载进度,还可以使用另一个重载方法回调感知下载进度:
//带进度显示的文件下载
HttpUtil.downloadFile(fileUrl, FileUtil.file("e:/"), new StreamProgress(){
@Override
public void start() {
Console.log("开始下载。。。。");
}
@Override
public void progress(long progressSize) {
Console.log("已下载:{}", FileUtil.readableFileSize(progressSize));
}
@Override
public void finish() {
Console.log("下载完成!");
}
});
定时任务(Hutool-cron)
全局定时任务-CronUtil
介绍
CronUtil通过一个全局的定时任务配置文件,实现统一的定时任务调度。
使用
- 配置文件
对于Maven项目,首先在src/main/resources/config下放入cron.setting文件(默认是这个路径的这个文件),然后在文件中放入定时规则,规则如下:
# 我是注释
[com.company.aaa.job]
TestJob.run = */10 * * * *
TestJob2.run = */10 * * * *
中括号表示分组,也表示需要执行的类或对象方法所在包的名字,这种写法有利于区分不同业务的定时任务。
TestJob.run表示需要执行的类名和方法名(通过反射调用,不支持Spring和任何框架的依赖注入),*/10 * * * *表示定时任务表达式,此处表示每10分钟执行一次,以上配置等同于:
com.company.aaa.job.TestJob.run = */10 * * * *
com.company.aaa.job.TestJob2.run = */10 * * * *
- 启动
CronUtil.start();
如果想让执行的作业同定时任务线程同时结束,可以将定时任务设为守护线程,需要注意的是,此模式下会在调用stop时立即结束所有作业线程,请确保你的作业可以被中断:
//使用deamon模式,
CronUtil.start(true);
- 关闭
CronUtil.stop();
更多选项
秒匹配和年匹配
考虑到Quartz表达式的兼容性,且存在对于秒级别精度匹配的需求,Hutool可以通过设置使用秒匹配模式来兼容。
//支持秒级别定时任务
CronUtil.setMatchSecond(true);
动态添加定时任务
当然,如果你想动态的添加定时任务,使用CronUtil.schedule(String schedulingPattern, Runnable task)方法即可(使用此方法加入的定时任务不会被写入到配置文件)。
CronUtil.schedule("*/2 * * * * *", new Task() {
@Override
public void execute() {
Console.log("Task excuted.");
}
});
// 支持秒级别定时任务
CronUtil.setMatchSecond(true);
CronUtil.start();
扩展(Hutool-extra)
邮件工具-MailUtil
概述
在Java中发送邮件主要品依靠javax.mail包,但是由于使用比较繁琐,因此Hutool针对其做了封装。由于依赖第三方包,因此将此工具类归类到extra模块中。
使用
引入依赖
Hutool对所有第三方都是可选依赖,因此在使用MailUtil时需要自行引入第三方依赖。
<dependency>
<groupId>javax.mailgroupId>
<artifactId>mailartifactId>
<version>1.4.7version>
dependency>
邮件服务器配置
在classpath(在标准Maven项目中为src/main/resources)的config目录下新建mail.setting文件,最小配置内容如下,在此配置下,smtp服务器和用户名都将通过from参数识别:
# 发件人(必须正确,否则发送失败)
from = [email protected]
# 密码(注意,某些邮箱需要为SMTP服务单独设置密码,详情查看相关帮助)
pass = q1w2e3
有时候一些非标准邮箱服务器(例如企业邮箱服务器)的smtp地址等信息并不与发件人后缀一致,端口也可能不同,此时Hutool可以提供完整的配置文件:
完整配置
# 邮件服务器的SMTP地址,可选,默认为smtp.<发件人邮箱后缀>
host = smtp.yeah.net
# 邮件服务器的SMTP端口,可选,默认25
port = 25
# 发件人(必须正确,否则发送失败)
from = [email protected]
# 用户名,默认为发件人邮箱前缀
user = hutool
# 密码(注意,某些邮箱需要为SMTP服务单独设置授权码,详情查看相关帮助)
pass = q1w2e3
发送邮件
- 发送普通文本邮件,最后一个参数可选是否添加多个附件:
MailUtil.send("[email protected]", "测试", "邮件来自Hutool测试", false);
- 发送HTML格式的邮件并附带附件,最后一个参数可选是否添加多个附件:
MailUtil.send("[email protected]", "测试", "邮件来自Hutool测试
", true, FileUtil.file("d:/aaa.xml"));
- 群发邮件,可选HTML或普通文本,可选多个附件:
ArrayList<String> tos = CollUtil.newArrayList(
"[email protected]",
"[email protected]",
"[email protected]",
"[email protected]");
MailUtil.send(tos, "测试", "邮件来自Hutool群发测试", false);
发送邮件非常简单,只需一个方法即可搞定其中按照参数顺序说明如下:
- tos: 对方的邮箱地址,可以是单个,也可以是多个(Collection表示)
- subject:标题
- content:邮件正文,可以是文本,也可以是HTML内容
- isHtml: 是否为HTML,如果是,那参数3识别为HTML内容
- files: 可选:附件,可以为多个或没有,将File对象加在最后一个可变参数中即可
其它
- 自定义邮件服务器
除了使用配置文件定义全局账号以外,MailUtil.send方法同时提供重载方法可以传入一个MailAccount对象,这个对象为一个普通Bean,记录了邮件服务器信息。
MailAccount account = new MailAccount();
account.setHost("smtp.yeah.net");
account.setPort("25");
account.setAuth(true);
account.setFrom("[email protected]");
account.setUser("hutool");
account.setPass("q1w2e3");
MailUtil.send(account, CollUtil.newArrayList("[email protected]"), "测试", "邮件来自Hutool测试", false);
- 使用SSL加密方式发送邮件 在使用QQ或Gmail邮箱时,需要强制开启SSL支持,此时我们只需修改配置文件即可:
# 发件人(必须正确,否则发送失败),“小磊”可以任意变更,<>内的地址必须唯一,以下方式也对
# from = [email protected]
from = 小磊>
# 密码(注意,某些邮箱需要为SMTP服务单独设置密码,详情查看相关帮助)
pass = q1w2e3
# 使用SSL安全连接
sslEnable = true
在原先极简配置下只需加入sslEnable即可完成SSL连接,当然,这是最简单的配置,很多参数根据已有参数已设置为默认。
完整的配置文件如下:
# 邮件服务器的SMTP地址
host = smtp.yeah.net
# 邮件服务器的SMTP端口
port = 465
# 发件人(必须正确,否则发送失败)
from = [email protected]
# 用户名(注意:如果使用foxmail邮箱,此处user为qq号)
user = hutool
# 密码(注意,某些邮箱需要为SMTP服务单独设置密码,详情查看相关帮助)
pass = q1w2e3
#使用 STARTTLS安全连接,STARTTLS是对纯文本通信协议的扩展。
starttlsEnable = true
# 使用SSL安全连接
sslEnable = true
# 指定实现javax.net.SocketFactory接口的类的名称,这个类将被用于创建SMTP的套接字
socketFactoryClass = javax.net.ssl.SSLSocketFactory
# 如果设置为true,未能创建一个套接字使用指定的套接字工厂类将导致使用java.net.Socket创建的套接字类, 默认值为true
socketFactoryFallback = true
# 指定的端口连接到在使用指定的套接字工厂。如果没有设置,将使用默认端口456
socketFactoryPort = 465
# SMTP超时时长,单位毫秒,缺省值不超时
timeout = 0
# Socket连接超时值,单位毫秒,缺省值不超时
connectionTimeout = 0
- 针对QQ邮箱和Foxmail邮箱的说明
(1) QQ邮箱中SMTP密码是单独生成的授权码,而非你的QQ密码,至于怎么生成,见腾讯的帮助说明:http://service.mail.qq.com/cgi-bin/help?subtype=1&&id=28&&no=1001256
使用帮助引导生成授权码后,配置如下即可:
pass = 你生成的授权码
(2) Foxmail邮箱本质上也是QQ邮箱的一种别名,你可以在你的QQ邮箱中设置一个foxmail邮箱,不过配置上有所区别。在Hutool中user属性默认提取你邮箱@前面的部分,但是foxmail邮箱是无效的,需要单独配置为与之绑定的qq号码或者[email protected]的XXXX。即:
host = smtp.qq.com
from = [email protected]
user = foxmail邮箱对应的QQ号码或者qq邮箱@前面部分
...
二维码工具-QrCodeUtil
由来
由于大家对二维码的需求较多,对于二维码的生成和解析我认为应该作为简单的工具存在于Hutool中。考虑到自行实现的难度,因此Hutool针对被广泛接受的的zxing库进行封装。而由于涉及第三方包,因此归类到extra模块中。
使用
引入zxing
考虑到Hutool的非强制依赖性,因此zxing需要用户自行引入:
<dependency>
<groupId>com.google.zxinggroupId>
<artifactId>coreartifactId>
<version>3.3.3version>
dependency>
生成二维码
在此我们将Hutool主页的url生成为二维码,微信扫一扫可以看到H5主页哦:
// 生成指定url对应的二维码到文件,宽和高都是300像素
QrCodeUtil.generate("https://hutool.cn/", 300, 300, FileUtil.file("d:/qrcode.jpg"));
效果qrcode.jpg:

自定义参数(since 4.1.2)
- 基本参数设定
通过QrConfig可以自定义二维码的生成参数,例如长、宽、二维码的颜色、背景颜色、边距等参数,使用方法如下:
QrConfig config = new QrConfig(300, 300);
// 设置边距,既二维码和背景之间的边距
config.setMargin(3);
// 设置前景色,既二维码颜色(青色)
config.setForeColor(Color.CYAN.getRGB());
// 设置背景色(灰色)
config.setBackColor(Color.GRAY.getRGB());
// 生成二维码到文件,也可以到流
QrCodeUtil.generate("http://hutool.cn/", config, FileUtil.file("e:/qrcode.jpg"));
效果qrcode.jpg:

2. 附带logo小图标
QrCodeUtil.generate(//
"http://hutool.cn/", //二维码内容
QrConfig.create().setImg("e:/logo_small.jpg"), //附带logo
FileUtil.file("e:/qrcodeWithLogo.jpg")//写出到的文件
);
效果如图:

3. 调整纠错级别
很多时候,二维码无法识别,这时就要调整纠错级别。纠错级别使用zxing的ErrorCorrectionLevel枚举封装,包括:L、M、Q、H几个参数,由低到高。低级别的像素块更大,可以远距离识别,但是遮挡就会造成无法识别。高级别则相反,像素块小,允许遮挡一定范围,但是像素块更密集。
QrConfig config = new QrConfig();
// 高纠错级别
config.setErrorCorrection(ErrorCorrectionLevel.H);
QrCodeUtil.generate("https://hutool.cn/", config, FileUtil.file("e:/qrcodeCustom.jpg"));
识别二维码
// decode -> "http://hutool.cn/"
String decode = QrCodeUtil.decode(FileUtil.file("d:/qrcode.jpg"));
FTP封装-Ftp
介绍
FTP客户端封装,此客户端基于Apache Commons Net。
使用
引入依赖
<dependency>
<groupId>commons-netgroupId>
<artifactId>commons-netartifactId>
<version>3.6version>
dependency>
使用
//匿名登录(无需帐号密码的FTP服务器)
Ftp ftp = new Ftp("172.0.0.1");
//进入远程目录
ftp.cd("/opt/upload");
//上传本地文件
ftp.upload("/opt/upload", FileUtil.file("e:/test.jpg"));
//下载远程文件
ftp.download("/opt/upload", "test.jpg", FileUtil.file("e:/test2.jpg"));
//关闭连接
ftp.close();
Emoji工具-EmojiUtil
由来
考虑到MySQL等数据库中普通的UTF8编码并不支持Emoji(只有utf8mb4支持),因此对于数据中的Emoji字符进行处理(转换、清除)变成一项必要工作。因此Hutool基于emoji-java库提供了Emoji工具实现。
此工具在Hutoo-4.2.1之后版本可用。
使用
加入依赖
<dependency>
<groupId>com.vdurmontgroupId>
<artifactId>emoji-javaartifactId>
<version>4.0.0version>
dependency>
使用
- 转义Emoji字符
String alias = EmojiUtil.toAlias("");//:smile:
- 将转义的别名转为Emoji字符
String emoji = EmojiUtil.toUnicode(":smile:");//
- 将字符串中的Unicode Emoji字符转换为HTML表现形式
String alias = EmojiUtil.toHtml("");//👦
Spring工具-SpringUtil
由来
使用Spring Boot时,通过依赖注入获取bean是非常方便的,但是在工具化的应用场景下,想要动态获取bean就变得非常困难,于是Hutool封装了Spring中Bean获取的工具类——SpringUtil。
使用
注册SpringUtil
- 使用ComponentScan注册类
// 扫描cn.hutool.extra.spring包下所有类并注册之
@ComponentScan(basePackages={"cn.hutool.extra.spring"})
- 使用Import导入
@Import(cn.hutool.extra.spring.SpringUtil.class)
获取指定Bean
- 定义一个Bean
@Data
public static class Demo2{
private long id;
private String name;
@Bean(name="testDemo")
public Demo2 generateDemo() {
Demo2 demo = new Demo2();
demo.setId(12345);
demo.setName("test");
return demo;
}
}
- 获取Bean
final Demo2 testDemo = SpringUtil.getBean("testDemo");
Office文档操作(Hutool-poi)
Excel工具-ExcelUtil
介绍
Excel操作工具封装
使用
- 从文件中读取Excel为ExcelReader
ExcelReader reader = ExcelUtil.getReader(FileUtil.file("test.xlsx"));
- 从流中读取Excel为ExcelReader(比如从ClassPath中读取Excel文件)
ExcelReader reader = ExcelUtil.getReader(ResourceUtil.getStream("aaa.xlsx"));
- 读取指定的sheet
ExcelReader reader;
//通过sheet编号获取
reader = ExcelUtil.getReader(FileUtil.file("test.xlsx"), 0);
//通过sheet名获取
reader = ExcelUtil.getReader(FileUtil.file("test.xlsx"), "sheet1");
- 读取大数据量的Excel
private RowHandler createRowHandler() {
return new RowHandler() {
@Override
public void handle(int sheetIndex, int rowIndex, List<Object> rowlist) {
Console.log("[{}] [{}] {}", sheetIndex, rowIndex, rowlist);
}
};
}
ExcelUtil.readBySax("aaa.xlsx", 0, createRowHandler());
Excel读取-ExcelReader
介绍
读取Excel内容的封装,通过构造ExcelReader对象,指定被读取的Excel文件、流或工作簿,然后调用readXXX方法读取内容为指定格式。
使用
- 读取Excel中所有行和列,都用列表表示
ExcelReader reader = ExcelUtil.getReader("d:/aaa.xlsx");
List<List<Object>> readAll = reader.read();
- 读取为Map列表,默认第一行为标题行,Map中的key为标题,value为标题对应的单元格值。
ExcelReader reader = ExcelUtil.getReader("d:/aaa.xlsx");
List<Map<String,Object>> readAll = reader.readAll();
- 读取为Bean列表,Bean中的字段名为标题,字段值为标题对应的单元格值。
ExcelReader reader = ExcelUtil.getReader("d:/aaa.xlsx");
List<Person> all = reader.readAll(Person.class);
流方式读取Excel2003-Excel03SaxReader
介绍
在标准的ExcelReader中,如果数据量较大,读取Excel会非常缓慢,并有可能造成内存溢出。因此针对大数据量的Excel,Hutool封装了event模式的读取方式。
Excel03SaxReader只支持Excel2003格式的Sax读取。
使用
定义行处理器
首先我们实现一下RowHandler接口,这个接口是Sax读取的核心,通过实现handle方法编写我们要对每行数据的操作方式(比如按照行入库,入List或者写出到文件等),在此我们只是在控制台打印。
private RowHandler createRowHandler() {
return new RowHandler() {
@Override
public void handle(int sheetIndex, long rowIndex, List<Object> rowlist) {
Console.log("[{}] [{}] {}", sheetIndex, rowIndex, rowlist);
}
};
}
ExcelUtil快速读取
ExcelUtil.read03BySax("aaa.xls", 1, createRowHandler());
构建对象读取
Excel03SaxReader reader = new Excel03SaxReader(createRowHandler());
reader.read("aaa.xls", 0);
reader方法的第二个参数是sheet的序号,-1表示读取所有sheet,0表示第一个sheet,依此类推。
流方式读取Excel2007-Excel07SaxReader
介绍
在标准的ExcelReader中,如果数据量较大,读取Excel会非常缓慢,并有可能造成内存溢出。因此针对大数据量的Excel,Hutool封装了Sax模式的读取方式。
Excel07SaxReader只支持Excel2007格式的Sax读取。
使用
定义行处理器
首先我们实现一下RowHandler接口,这个接口是Sax读取的核心,通过实现handle方法编写我们要对每行数据的操作方式(比如按照行入库,入List或者写出到文件等),在此我们只是在控制台打印。
private RowHandler createRowHandler() {
return new RowHandler() {
@Override
public void handle(int sheetIndex, long rowIndex, List<Object> rowlist) {
Console.log("[{}] [{}] {}", sheetIndex, rowIndex, rowlist);
}
};
}
ExcelUtil快速读取
ExcelUtil.read07BySax("aaa.xlsx", 0, createRowHandler());
构建对象读取
Excel07SaxReader reader = new Excel07SaxReader(createRowHandler());
reader.read("d:/text.xlsx", 0);
reader方法的第二个参数是sheet的序号,-1表示读取所有sheet,0表示第一个sheet,依此类推。
Excel生成-ExcelWriter
由来
Excel有读取也便有写出,Hutool针对将数据写出到Excel做了封装。
原理
Hutool将Excel写出封装为ExcelWriter,原理为包装了Workbook对象,每次调用merge(合并单元格)或者write(写出数据)方法后只是将数据写入到Workbook,并不写出文件,只有调用flush或者close方法后才会真正写出文件。
由于机制原因,在写出结束后需要关闭ExcelWriter对象,调用close方法即可关闭,此时才会释放Workbook对象资源,否则带有数据的Workbook一直会常驻内存。
使用例子
- 将行列对象写出到Excel
我们先定义一个嵌套的List,List的元素也是一个List,内层的一个List代表一行数据,每行都有4个单元格,最终list对象代表多行数据。
List<String> row1 = CollUtil.newArrayList("aa", "bb", "cc", "dd");
List<String> row2 = CollUtil.newArrayList("aa1", "bb1", "cc1", "dd1");
List<String> row3 = CollUtil.newArrayList("aa2", "bb2", "cc2", "dd2");
List<String> row4 = CollUtil.newArrayList("aa3", "bb3", "cc3", "dd3");
List<String> row5 = CollUtil.newArrayList("aa4", "bb4", "cc4", "dd4");
List<List<String>> rows = CollUtil.newArrayList(row1, row2, row3, row4, row5);
然后我们创建ExcelWriter对象后写出数据:
//通过工具类创建writer
ExcelWriter writer = ExcelUtil.getWriter("d:/writeTest.xlsx");
//通过构造方法创建writer
//ExcelWriter writer = new ExcelWriter("d:/writeTest.xls");
//跳过当前行,既第一行,非必须,在此演示用
writer.passCurrentRow();
//合并单元格后的标题行,使用默认标题样式
writer.merge(row1.size() - 1, "测试标题");
//一次性写出内容,强制输出标题
writer.write(rows, true);
//关闭writer,释放内存
writer.close();

2. 写出Map数据
构造数据:
Map<String, Object> row1 = new LinkedHashMap<>();
row1.put("姓名", "张三");
row1.put("年龄", 23);
row1.put("成绩", 88.32);
row1.put("是否合格", true);
row1.put("考试日期", DateUtil.date());
Map<String, Object> row2 = new LinkedHashMap<>();
row2.put("姓名", "李四");
row2.put("年龄", 33);
row2.put("成绩", 59.50);
row2.put("是否合格", false);
row2.put("考试日期", DateUtil.date());
ArrayList<Map<String, Object>> rows = CollUtil.newArrayList(row1, row2);
写出数据:
// 通过工具类创建writer
ExcelWriter writer = ExcelUtil.getWriter("d:/writeMapTest.xlsx");
// 合并单元格后的标题行,使用默认标题样式
writer.merge(rows.size() - 1, "一班成绩单");
// 一次性写出内容,使用默认样式,强制输出标题
writer.write(rows, true);
// 关闭writer,释放内存
writer.close();

3. 写出Bean数据
定义Bean:
public class TestBean {
private String name;
private int age;
private double score;
private boolean isPass;
private Date examDate;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public double getScore() {
return score;
}
public void setScore(double score) {
this.score = score;
}
public boolean isPass() {
return isPass;
}
public void setPass(boolean isPass) {
this.isPass = isPass;
}
public Date getExamDate() {
return examDate;
}
public void setExamDate(Date examDate) {
this.examDate = examDate;
}
}
构造数据:
TestBean bean1 = new TestBean();
bean1.setName("张三");
bean1.setAge(22);
bean1.setPass(true);
bean1.setScore(66.30);
bean1.setExamDate(DateUtil.date());
TestBean bean2 = new TestBean();
bean2.setName("李四");
bean2.setAge(28);
bean2.setPass(false);
bean2.setScore(38.50);
bean2.setExamDate(DateUtil.date());
List<TestBean> rows = CollUtil.newArrayList(bean1, bean2);
写出数据:
// 通过工具类创建writer
ExcelWriter writer = ExcelUtil.getWriter("d:/writeBeanTest.xlsx");
// 合并单元格后的标题行,使用默认标题样式
writer.merge(4, "一班成绩单");
// 一次性写出内容,使用默认样式,强制输出标题
writer.write(rows, true);
// 关闭writer,释放内存
writer.close();
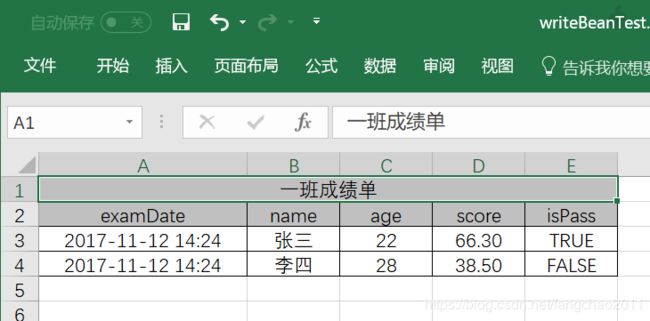
4. 自定义Bean的key别名(排序标题)
在写出Bean的时候,我们可以调用ExcelWriter对象的addHeaderAlias方法自定义Bean中key的别名,这样就可以写出自定义标题了(例如中文)。
写出数据:
// 通过工具类创建writer
ExcelWriter writer = ExcelUtil.getWriter("d:/writeBeanTest.xlsx");
//自定义标题别名
writer.addHeaderAlias("name", "姓名");
writer.addHeaderAlias("age", "年龄");
writer.addHeaderAlias("score", "分数");
writer.addHeaderAlias("isPass", "是否通过");
writer.addHeaderAlias("examDate", "考试时间");
// 合并单元格后的标题行,使用默认标题样式
writer.merge(4, "一班成绩单");
// 一次性写出内容,使用默认样式,强制输出标题
writer.write(rows, true);
// 关闭writer,释放内存
writer.close();

提示(since 4.1.5) 默认情况下Excel中写出Bean字段不能保证顺序,此时可以使用addHeaderAlias方法设置标题别名,Bean的写出顺序就会按照标题别名的加入顺序排序。 如果不需要设置标题但是想要排序字段,请调用writer.addHeaderAlias(“age”, “age”)设置一个相同的别名就可以不更换标题。 未设置标题别名的字段不参与排序,会默认排在前面。
- 写出到流
// 通过工具类创建writer,默认创建xls格式
ExcelWriter writer = ExcelUtil.getWriter();
//创建xlsx格式的
//ExcelWriter writer = ExcelUtil.getWriter(true);
// 一次性写出内容,使用默认样式,强制输出标题
writer.write(rows, true);
//out为OutputStream,需要写出到的目标流
writer.flush(out);
// 关闭writer,释放内存
writer.close();
- 写出到客户端下载(写出到Servlet)
写出xls
// 通过工具类创建writer,默认创建xls格式
ExcelWriter writer = ExcelUtil.getWriter();
// 一次性写出内容,使用默认样式,强制输出标题
writer.write(rows, true);
//out为OutputStream,需要写出到的目标流
//response为HttpServletResponse对象
response.setContentType("application/vnd.ms-excel;charset=utf-8");
//test.xls是弹出下载对话框的文件名,不能为中文,中文请自行编码
response.setHeader("Content-Disposition","attachment;filename=test.xls");
ServletOutputStream out=response.getOutputStream();
writer.flush(out, true);
// 关闭writer,释放内存
writer.close();
//此处记得关闭输出Servlet流
IoUtil.close(out);
写出xlsx
ExcelWriter writer = ExcelUtil.getWriter(true);
writer.write(rows, true);
response.setContentType("application/vnd.openxmlformats-officedocument.spreadsheetml.sheet;charset=utf-8");
response.setHeader("Content-Disposition","attachment;filename=test.xlsx");
writer.flush(out, true);
writer.close();
IoUtil.close(out);
注意 ExcelUtil.getWriter()默认创建xls格式的Excel,因此写出到客户端也需要自定义文件名为XXX.xls,否则会出现文件损坏的提示。 若想生成xlsx格式,请使用ExcelUtil.getWriter(true)创建。
下载提示文件损坏问题解决
有用户反馈按照代码生成的Excel下载后提示文件损坏,无法打开,经过排查,可能是几个问题:
(1)writer和out流没有正确关闭,请在代码末尾的finally块增加关闭。
(2)扩展名不匹配。getWriter默认生成xls,Content-Disposition中也应该是xls,只有getWriter(true)时才可以使用xlsx
(3)Maven项目中Excel保存于ClassPath中(src/main/resources下)宏替换导致被破坏,解决办法是添加filtering(参考:https://blog.csdn.net/qq_42270377/article/details/92771349)
(4)Excel打开提示文件损坏,WPS可以打开。这是Excel的安全性控制导致的,解决办法见:https://blog.csdn.net/zm9898/article/details/99677626
自定义Excel
- 设置单元格背景色
ExcelWriter writer = ...;
// 定义单元格背景色
StyleSet style = writer.getStyleSet();
// 第二个参数表示是否也设置头部单元格背景
style.setBackgroundColor(IndexedColors.RED, false);
- 自定义字体
ExcelWriter writer = ...;
//设置内容字体
Font font = writer.createFont();
font.setBold(true);
font.setColor(Font.COLOR_RED);
font.setItalic(true);
//第二个参数表示是否忽略头部样式
writer.getStyleSet().setFont(font, true);
- 写出多个sheet
//初始化时定义表名
ExcelWriter writer = new ExcelWriter("d:/aaa.xls", "表1");
//切换sheet,此时从第0行开始写
writer.setSheet("表2");
...
writer.setSheet("表3");
...
- 更详细的定义样式
在Excel中,由于样式对象个数有限制,因此Hutool根据样式种类分为4个样式对象,使相同类型的单元格可以共享样式对象。样式按照类别存在于StyleSet中,其中包括:
- 头部样式 headCellStyle
- 普通单元格样式 cellStyle
- 数字单元格样式 cellStyleForNumber
- 日期单元格样式 cellStyleForDate
其中cellStyleForNumber cellStyleForDate用于控制数字和日期的显示方式。
因此我们可以使用以下方式获取CellStyle对象自定义指定种类的样式:
StyleSet style = writer.getStyleSet();
CellStyle cellStyle = style.getHeadCellStyle();
...
Excel大数据生成-BigExcelWriter
介绍
对于大量数据输出,采用ExcelWriter容易引起内存溢出,因此有了BigExcelWriter,使用方法与ExcelWriter完全一致。
使用
List<?> row1 = CollUtil.newArrayList("aa", "bb", "cc", "dd", DateUtil.date(), 3.22676575765);
List<?> row2 = CollUtil.newArrayList("aa1", "bb1", "cc1", "dd1", DateUtil.date(), 250.7676);
List<?> row3 = CollUtil.newArrayList("aa2", "bb2", "cc2", "dd2", DateUtil.date(), 0.111);
List<?> row4 = CollUtil.newArrayList("aa3", "bb3", "cc3", "dd3", DateUtil.date(), 35);
List<?> row5 = CollUtil.newArrayList("aa4", "bb4", "cc4", "dd4", DateUtil.date(), 28.00);
List<List<?>> rows = CollUtil.newArrayList(row1, row2, row3, row4, row5);
BigExcelWriter writer= ExcelUtil.getBigWriter("e:/xxx.xlsx");
// 一次性写出内容,使用默认样式
writer.write(rows);
// 关闭writer,释放内存
writer.close();
Word生成-Word07Writer
由来
Hutool针对Word(主要是docx格式)进行封装,实现简单的Word文件创建。
介绍
Hutool将POI中Word生成封装为Word07Writer, 通过分段写出,实现word生成。
使用例子
Word07Writer writer = new Word07Writer();
// 添加段落(标题)
writer.addText(new Font("方正小标宋简体", Font.PLAIN, 22), "我是第一部分", "我是第二部分");
// 添加段落(正文)
writer.addText(new Font("宋体", Font.PLAIN, 22), "我是正文第一部分", "我是正文第二部分");
// 写出到文件
writer.flush(FileUtil.file("e:/wordWrite.docx"));
// 关闭
writer.close();
系统调用(Hutool-system)
概述
此工具是针对System.getProperty(name)的封装,通过此工具,可以获取如下信息:
Java Virtual Machine Specification信息
SystemUtil.getJvmSpecInfo();
Java Virtual Machine Implementation信息
SystemUtil.getJvmInfo();
Java Specification信息
SystemUtil.getJavaSpecInfo();
Java Implementation信息
SystemUtil.getJavaInfo();
Java运行时信息
SystemUtil.getJavaRuntimeInfo();
系统信息
SystemUtil.getOsInfo();
用户信息
SystemUtil.getUserInfo();
当前主机网络地址信息
SystemUtil.getHostInfo();
运行时信息,包括内存总大小、已用大小、可用大小等
SystemUtil.getRuntimeInfo();
图形验证码(Hutool-captcha)
由来
由于对验证码需求量巨大,且我之前项目中有所积累,因此在Hutool中加入验证码生成和校验功能。
介绍
验证码功能位于cn.hutool.captcha包中,核心接口为ICaptcha,此接口定义了以下方法:
- createCode 创建验证码,实现类需同时生成随机验证码字符串和验证码图片
- getCode 获取验证码的文字内容
- verify 验证验证码是否正确,建议忽略大小写
- write 将验证码写出到目标流中
其中write方法只有一个OutputStream,ICaptcha实现类可以根据这个方法封装写出到文件等方法。
AbstractCaptcha为一个ICaptcha抽象实现类,此类实现了验证码文本生成、非大小写敏感的验证、写出到流和文件等方法,通过继承此抽象类只需实现createImage方法定义图形生成规则即可。
实现类
- LineCaptcha 线段干扰的验证码

贴栗子:
//定义图形验证码的长和宽
LineCaptcha lineCaptcha = CaptchaUtil.createLineCaptcha(200, 100);
//图形验证码写出,可以写出到文件,也可以写出到流
lineCaptcha.write("d:/line.png");
//输出code
Console.log(lineCaptcha.getCode());
//验证图形验证码的有效性,返回boolean值
lineCaptcha.verify("1234");
//重新生成验证码
lineCaptcha.createCode();
lineCaptcha.write("d:/line.png");
//新的验证码
Console.log(lineCaptcha.getCode());
//验证图形验证码的有效性,返回boolean值
lineCaptcha.verify("1234");
- ShearCaptcha 扭曲干扰验证码

贴栗子:
//定义图形验证码的长、宽、验证码字符数、干扰线宽度
ShearCaptcha captcha = CaptchaUtil.createShearCaptcha(200, 100, 4, 4);
//ShearCaptcha captcha = new ShearCaptcha(200, 100, 4, 4);
//图形验证码写出,可以写出到文件,也可以写出到流
captcha.write("d:/shear.png");
//验证图形验证码的有效性,返回boolean值
captcha.verify("1234");
写出到浏览器(Servlet输出)
ICaptcha captcha = ...;
captcha.write(response.getOutputStream());
//Servlet的OutputStream记得自行关闭哦!
自定义验证码
有时候标准的验证码不满足要求,比如我们希望使用纯字母的验证码、纯数字的验证码、加减乘除的验证码,此时我们就要自定义CodeGenerator
// 自定义纯数字的验证码(随机4位数字,可重复)
RandomGenerator randomGenerator = new RandomGenerator("0123456789", 4);
LineCaptcha lineCaptcha = CaptchaUtil.createLineCaptcha(200, 100);
captcha.setGenerator(randomGenerator);
// 重新生成code
captcha.createCode();
ShearCaptcha captcha = CaptchaUtil.createShearCaptcha(200, 45, 4, 4);
// 自定义验证码内容为四则运算方式
captcha.setGenerator(new MathGenerator());
// 重新生成code
captcha.createCode();