NLP基础(一):初识自然语言处理和词向量
1.词袋模型(BOW)
词袋模型(Bag of Words, BOW)是一种通过词频将句子转化为向量表示的方法,不考虑句子的顺序,只考虑词表中单词在这个句子中出现的次数。
例句:
Jack lives in Shanghai.
Bob wants to go to Shanghai.
对于这两个句子中出现的单词,使用词袋模型形成词表:
| ['bob', 'go', 'in', 'jack', 'lives', 'shanghai', 'to', 'wants'] |
因此,这两个句子的向量表示为
| s1=[0, 0, 1, 1, 1, 1, 0, 0] s2=[1, 1, 0, 0, 0, 1, 2, 1] |
可使用sklearn中的CountVectorizer()函数实现BOW模型
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
"Jack lives in Shanghai.",
"Bob wants to go to Shanghai."
]
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
print(vectorizer.get_feature_names())
print(X.toarray())
# 输出
['bob', 'go', 'in', 'jack', 'lives', 'shanghai', 'to', 'wants']
[[0 0 1 1 1 1 0 0]
[1 1 0 0 0 1 2 1]]
2.N-gram
假设我们有一个由n个词组成的句子 S = ( w 1 , w 2 , ⋯ , w n ) S=(w_1,w_2,⋯,w_n) S=(w1,w2,⋯,wn),如何衡量它的概率呢?让我们假设,每一个单词 w i w_i wi都要依赖于从第一个单词 w 1 w_1 w1到它之前一个单词 w i − 1 w_{i−1} wi−1的影响:
p ( S ) = p ( w 1 w 2 ⋯ w n ) = p ( w 1 ) p ( w 2 ∣ w 1 ) ⋯ p ( w n ∣ w n − 1 ⋯ w 2 w 1 ) p(S)=p(w_1w_2⋯w_n)=p(w_1)p(w_2∣w_1)⋯p(w_n∣w_n−1⋯w_2w_1) p(S)=p(w1w2⋯wn)=p(w1)p(w2∣w1)⋯p(wn∣wn−1⋯w2w1)
3.神经网络语言模型(NNLM)
NNLM模型包括两部分:
1)一个从词汇表V到实数向量空间的映射C。通过这个映射得到每个单词的向量表示。因此C实际上是一个|V|×m的矩阵(m是单词向量的维数);
2)以单词向量作为自变量的概率方程 g g g:以单词向量序列 C ( w t − n + 1 ) , . . . , C ( w t − 1 ) C(w_{t-n+1}),..., C(w_{t-1}) C(wt−n+1),...,C(wt−1)作为输入,输出序列的后续单词 w t w_t wt的条件概率。方程 g g g的输出也是一个向量,向量的第i维对应单词表中第 i i i个单词的条件概率:
f ( i , w t − 1 , . . . , w t − n + 1 ) = g ( i , C ( w t − 1 ) , . . . , C ( w t − n + 1 ) ) f(i,w_{t-1},...,w_{t-n+1})=g(i,C(w_{t-1}),..., C(w_{t-n+1})) f(i,wt−1,...,wt−n+1)=g(i,C(wt−1),...,C(wt−n+1))

4.Word2vec
特点:有一个很大的词表库;在词表中的每一个词都可以通过向量表征;有一个中心词c,有一个输出词o;用词c和o的相似度来计算他们之间同时出现的概率;调整这个词向量来获得最大的输出概率。
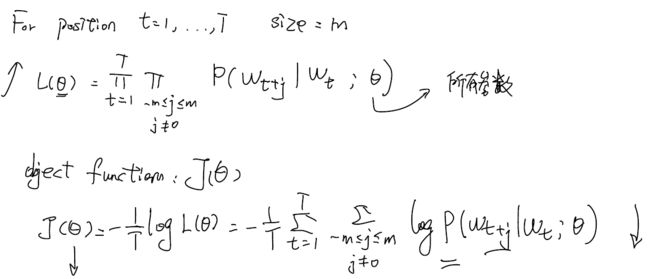
Word2Vec模型中,主要有Skip-Gram和CBOW两种模型,从直观上理解,Skip-Gram是给定input word来预测上下文。而CBOW是给定上下文,来预测input word。
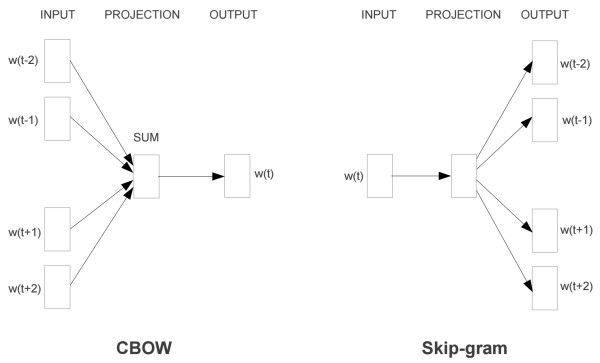
4.1 Skip-gram
Skip-Gram通过中心词预测上下文。设定我们的窗口大小为2(window_size=2),也就是说我们仅选输入词前后各两个词和输入词进行组合。下图中,蓝色代表input word,方框内代表位于窗口内的单词。时间复杂度为 O ( k × V ) O(k \times V) O(k×V)。

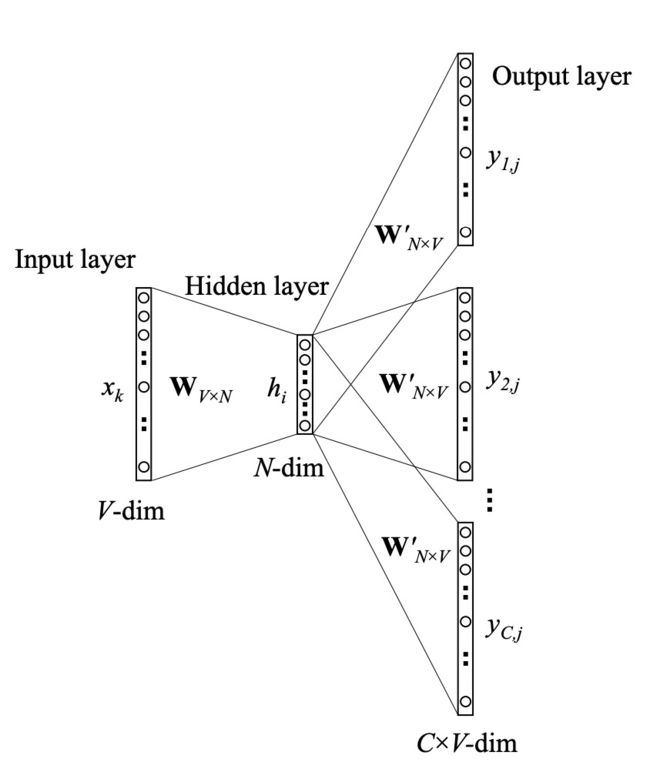
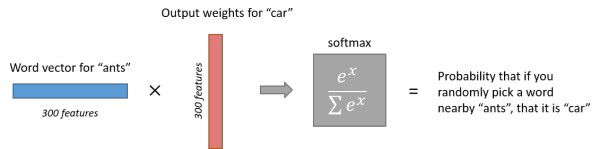
我们将一个输入的单词表示成一个one-hot向量。这个向量有10000个元素(字典中的每个单词都是一位,而形成一个向量),我们将单词出现的位置设置为1,其它位置设置为0。中间隐藏层为10000x300的矩阵,表示这10000个元素的词向量,用于对输入的单词词向量的查找。神经网络的输出是一个单独的向量,依然有10000元素,包含了对于词典中的每个单词,随机选中的单词是那个词典单词的概率。
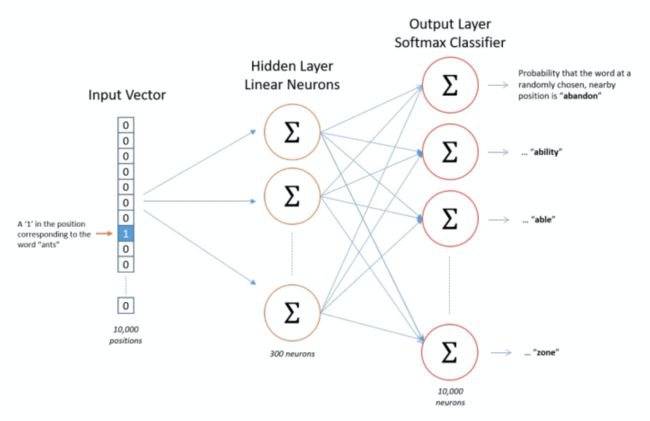
比如说,经过神经网络隐层的计算,ants这个词会从一个1 x 10000的向量变成1 x 300的向量(词向量),再被输入到输出层。输出层是一个softmax回归分类器,其中 x = u T v 。 x=u^Tv。 x=uTv。它的每个结点将会输出一个0-1之间的值(概率),这些所有输出层神经元结点的概率之和为1。
4.2 CBOW
CBOW通过上下文预测输入词,时间复杂度为 O ( V ) O(V) O(V)。CBOW结果受到上下文多个词的词向量影响,跟着周围词一起调整,没有受到针对性训练,但是在数据量小生僻字少的情况下效果更好。而Skip-Gram结果仅受到中心词一个词的词向量影响,在数据量大时效果好。
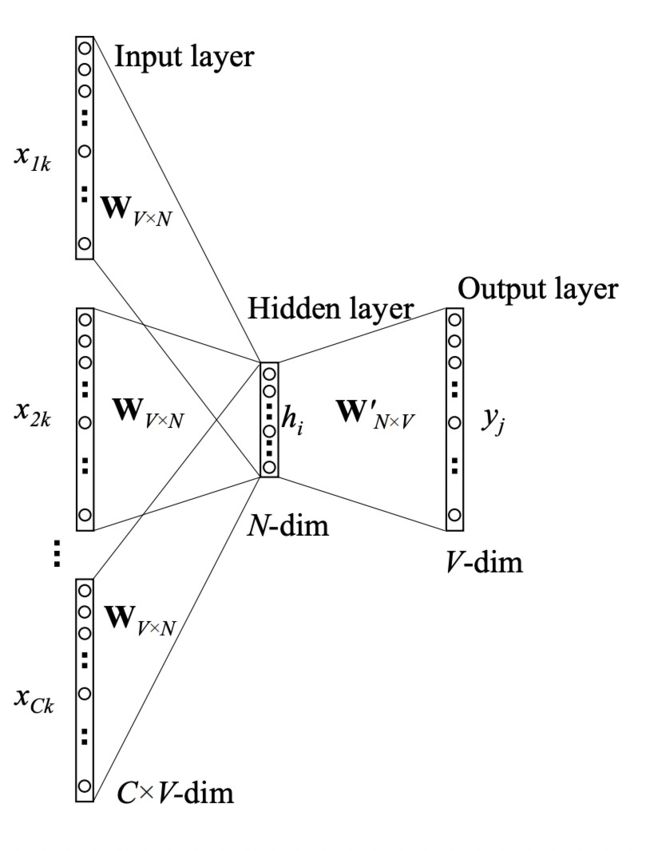
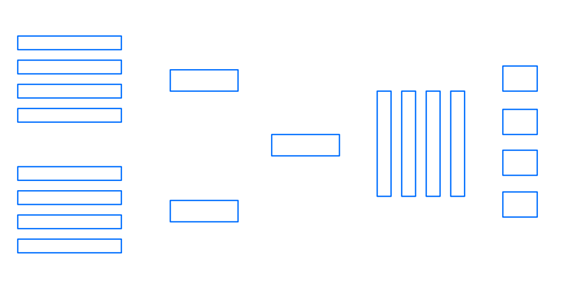
CBOW的隐藏层输出为所有输入计算结果的平均,再用 W N × V ′ W'_{N \times V} WN×V′计算各词出现的概率。
参考资料
[1]GitHub README模板
[2]GitHub Python gitignore文件
[3]Word2Vec Tutorial - The Skip-Gram Model
[4]Efficient Estimation of Word Representations inVector Space
[5]自然语言处理NLP中的N-gram模型
[6]Neural Probabilistic Language Model, word2vec来龙去脉