GlusterFS存储
GlusterFS存储
GlusterFS最早由Gluster公司开发,其目标是开发出一个能为客户提供全局命名空间、分布式前端、高达百PB级别扩展性的开源分布式文件系统,相比其他分布式文件系统,Gluster具有高扩展性、高可用性、高性能、可横向扩展等特点,并且其没有元数据服务器的设计,让整个服务没有单点故障的隐患。正式由于GlusterFS拥有众多优点的特点,红帽公司于2011年收购Gluster公司,并将GlusterFS作为其大数据解决方案的一部分
GlusterFS主要应用在集群系统中,其软件结构设计良好,易于扩展和配置,通过各个模块的灵活搭配可以得到针对性的解决方案,可解决以下问题:网络存储、联合存储(融合多个节点上的存储空间)、冗余备份、大文件的负载均衡(分块),但也因为缺乏一些关键特性,可靠性也未经过长时间考验,还不适合应用于需要提供24小时不间断服务的产品环境,目前适用于大量数据的离线应用
认识“分布式文件系统”
分布式文件系统(Distributed File System)是指文件系统管理的物理存储资源并不直接与本地节点相连(即非直连存储),而是通过计算机网络由多个节点计算机构成。分布式文件系统的设计基于C/S(Client/Server)模式。流行的模式是当用户需要存储数据时,服务器指引其将数据分散地存储到多个存储节点上,以提供更快的速度,更大的容量、更高的冗余性。下文将先拿三种分布式文件系统举例讲解,使读者更好的理解分布式文件系统
MooseFS
MooseFS主要有管理服务器(master),元rizhi服务器(Mate logger),数据存储服务器(ChunkServers)构成,管理服务器主要作用是管理数据存储服务器,文件读写控制,空间管理及节点间的数据拷贝等;元日志服务器主要用来备份管理服务器的变化日志,以便管理服务器出问题时能恢复工作;数据存储服务器主要工作是听从管理服务器调度,提供存储空间,接受或传输客户数据等,MooseFS的读过程如下图:
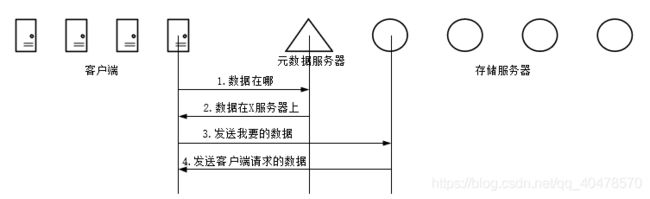
如上图所示,客户端在读取数据的过程中,首先向Master询问数据存放在哪些数据存储服务器上,然后再向数据存储服务器请求并获得数据,其写过程与读过程恰好相反,过程如下图:
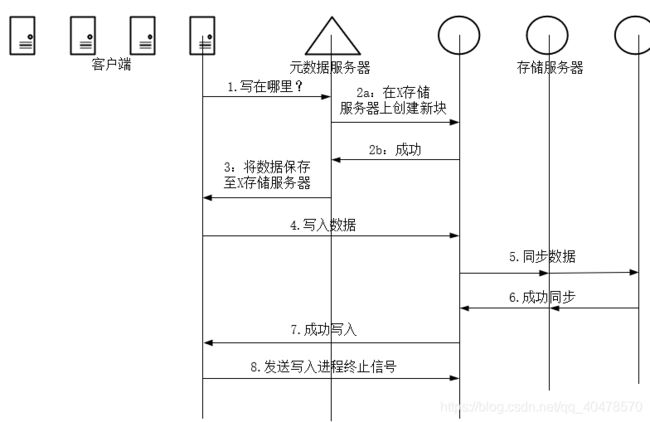
写数据时,客户机向master发出请求,master查询剩余空间后将存储位置返回给客户机,由客户机将数据分散地存放到数据存储服务器上,最后想master发送写入结束信号
MooseFS结构简单,非常适合初学者理解分布式文件系统地工作过程,但也存在较大问题,MooseFS具有单点故障隐患,一旦master无法工作,整个分布式文件系统都将停止工作
Lustre
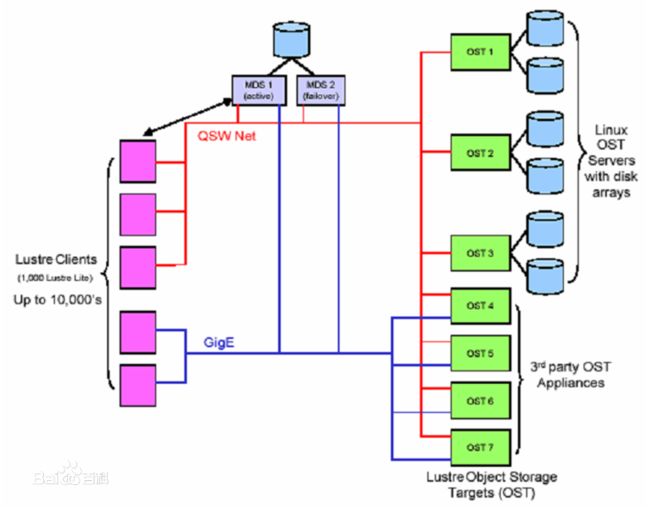
Lustre是HP,Intel,Cluster File System公司联合美国能源开发部联合开发的Linux集群并行文件系统,是一个基于对象存储的文件系统,开源的并行文件系统,Lustre由元数据服务器(Metadata Servers,MDSs)、对象存储服务器(Object Storage Servers,OOSs)和管理服务器(Managerment Servers,MGSs)组成,与MooseFS类似,当客户端读取数据时,主要的操作集中在MDSs和OSSs间;写入数据时就需要MGSs、MDSs及OSSs共同参与操作
Lustre主要面对的是海量级的数据存储,支持多达1000个节点、PB级的数据存储、100Gbit/s以上传输速度。在气象、石油等领域应用十分广泛,是目前比较成熟的解决方案之一
GlusterFS
本文以GlusterFS为标题,所以将详细对GlusterFS进行讲解,GlusterFS与其他分布式文件系统相比,在扩展性、高性能、维护性等方面都具有独特优势
一、无元数据设计
元数据是用来描述一个文件或给定区块在分布式文件系统中所在的位置,简而言之就是某个文件或某个区块存储的位置。传统分布式文件系统大都会设置元数据服务器或功能相近的管理服务器,主要作用就是用来管理文件与数据区块之间的存储关系,相较其他分布式文件系统而言,GlusterFS并没有集中或分布式的元数据概念,取而代之的是弹性Hash算法。集群中的任何服务器、客户端都可利用HASH算法、路径、及文件名进行计算、就可以对数据进行定位,并执行读写访问操作
这种设计带来的好处是极大地提高了扩展性,同时也提高了系统的性能和可靠性;另一显著的特点是如果给定确定的文件名,查找文件位置会非常快。但如果需要列出文件或目录,性能会大幅下降,因为列出文件或目录时,需要查询所在的节点并对所在的节点中的信息进行聚合。此时有元数据服务的分布式文件系统的查询效率反而会高许多
二、服务器间的部署
在之前的版本中,服务器间的关系是对等的,也就是说每个节点服务器都掌握了集群的配置信息。这样做的好处是每个节点都拥有节点的配置信息,高度自治,所有信息都可以在本地查询,每个节点的信息更新都会向其他节点通告,保证节点间信息的一致性。但如果集群规模较大,节点众多时,信息同步的效率就会下降,节点间信息的非一致性概率就会大大提高,因此Glust而FS未来的版本有向集中式管理变化的趋势
GlusterFS支持多种集群模式,组成诸如磁盘阵列状的结构,让用户在数据可靠性、冗余程度等方面自行取舍
三、客户端访问
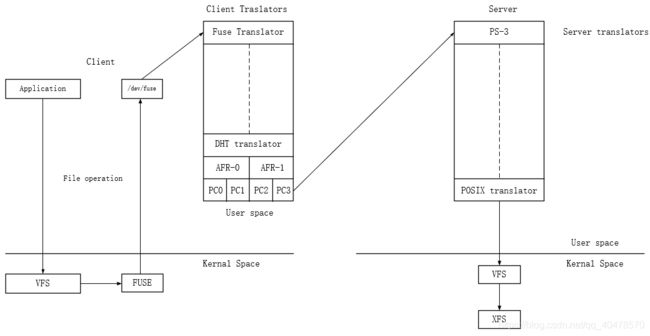
当客户端访问GlusterFS存储时,过程如上图,首先程序会通过挂载点的形式读取数据,对于用户和程序而言,集群文件系统是透明的,用户和程序根本感知 文件系统是本地还是在远端服务器上,读写操作将会交给VFS来处理,VFS会将请求交给FUSE内核模块,而FUSE又会通过设备/dev/fuse将数据交给GlusterFS Client。最后经过GlusterFS Client计算,并最终通过网络将请求或数据发送到GlusterFS Server上
四、可管理性
GlusterFS在提供了一套与Web GUI的基础上,还提供了一套基于分布式体系协同合作的命令行工具,二者相结合就可以完成GlusterFS的管理工作。由于整套系统都是基于Linux系统,在懂得Linux管理知识的基础上,再加上2~3小时的学习就可以完成GlusterFS的日常管理工作,这对一套分布式文件系统而言,GlusterFS的管理工作无疑是非常简单的
GlusterFS集群的模式
GlusterFS集群的模式是指数据在集群中的存放结构,类似与磁盘阵列中的级别,GlusterFS支持多种集群模式
一、分布式GlusterFS卷
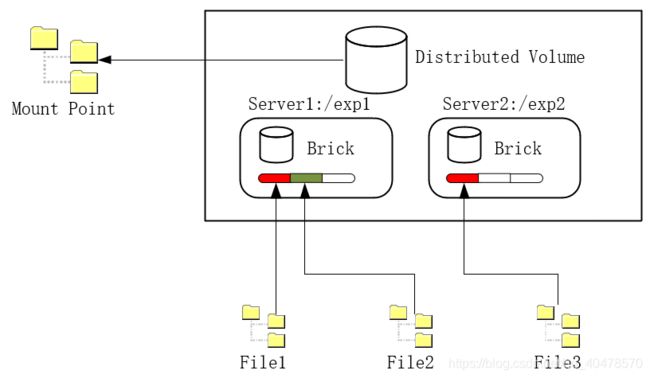
分布式Gluster卷(Distributd Glusterfs Volume)是一种比较常见的松散式结构,结构相对简单,存放文件时并没有特别的规则,只是将文件存放到分布卷的所有服务器上。创建分布式卷时,如果没有特别的指定,将默认使用分布式GlusterFS卷。这种卷的好处是非常便于扩展,且组成卷的服务器容量可以不必相同,缺点是没有任何冗余功能,任何一个节点的失效都会造成数据丢失,分布式GlusterFS卷需要在底层硬件上做数据冗余,如磁盘陈列RAID等
二、复制GlusterFS卷
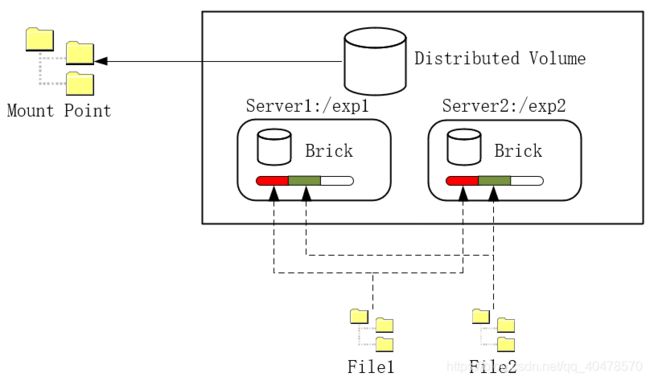
复制GlusterFS卷(Raplicated GlusterFS Volume)同RAID1类似,组成所有卷的服务器中存放的内容完全一致(结构如上图),复制GlusterFS卷的原理是将文件复制到所有组成分布式卷的服务器上,在创建分布式卷是需要制定复制的副本数量,通常是2或者3,但副本数量一定要小于或等于组成卷的服务器数量,由于复制GlusterFS卷会在不同的服务器上保存数据的副本,当其中一台服务器失效后,可以从另一台服务器读取数据,因此复制GlusterFS卷提高了数据可靠性的同时,还提供了数据冗余功能
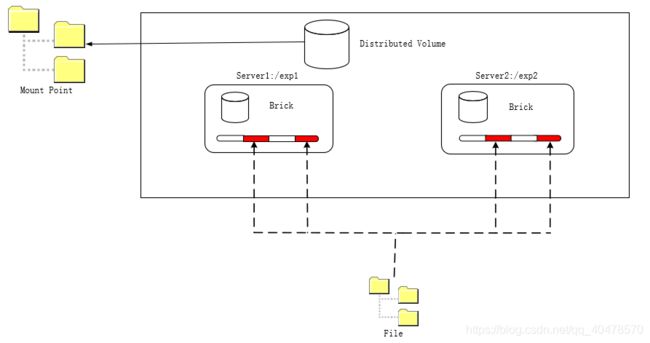
三、分布式复制GlusterFS卷
分布式复制GlusterFS卷(Distributed Replicated Glusterfs Volume)结合了分布式和复制GlusterFS卷的特点,结构看似与RAID10相似,但实质不同,RAID10实质是条带化,但分布式复制GlusterFS卷则没有,这种卷实际上是针对数据冗余和可靠性要求都非常高的环境而开发的
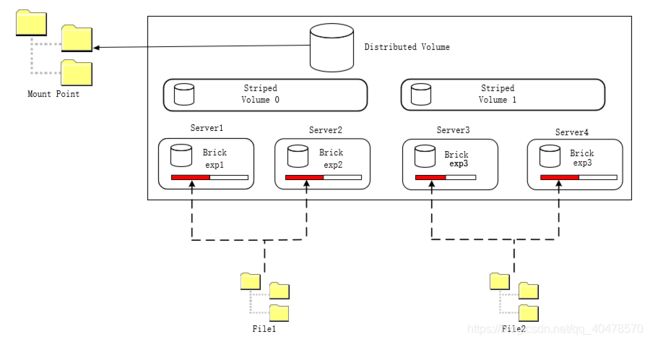
四、条带化GlusterFS卷
条带化GlusterFS (Striped Glusterfs Volume)卷是专门针对大文件,多客户而设置的,当GlusterFS被用来存储一些较大的文件时,如果仅保存在某个服务器上,当客户端较多时,性能就会急剧下降,此时使用条带化的GlusterFSB就可以解决这个问题,条带化Gluster允许将体型较大的文件分拆并存放到多台服务器上,当客户端进行访问时就能分散压力,效果如同负载均衡,条带化GlusterFS的缺点是不能提供数据冗余功能
五、分布式条带化GlusterFS卷
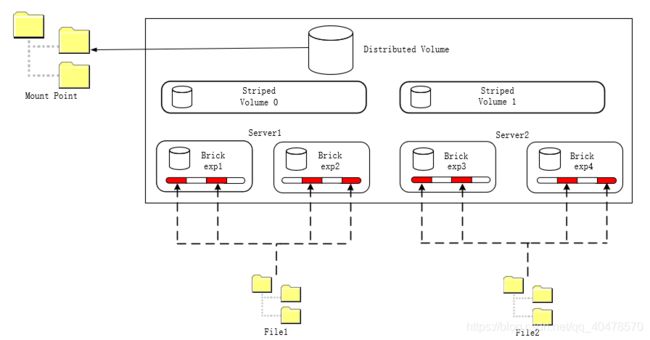
当单个文件的体型十分巨大,客户端数量更多时,条带化GlusterFS已经无法满足需求,此时将分布式与条带化结合起来是一个比较好的选择。需要注意的是,无论是条带化GlusterFS还是分布式条带化GlusterFS,其性能都与服务器数量有关
GlusterFS部署与应用
| FQDN | 硬盘A | 硬盘B |
| server1 | /dev/sda(系统盘) | /dev/sdb(Gluster卷) |
| server2 | /dev/sda(系统盘) | /dev/sdb(Gluster卷) |
| server3 | /dev/sda(系统盘) | /dev/sdb(Gluster卷) |
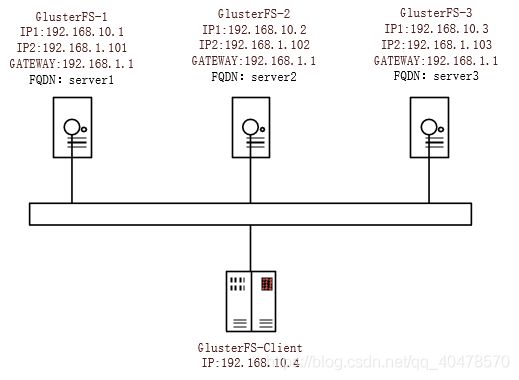
STEP1:设置三台服务器及客户机的/etc/hosts文件
[root@Server1 ~]# cat /etc/hosts
192.168.10.1 server1
192.168.10.2 server2
192.168.10.3 server3
STEP2:三台服务器和客户机下载网易的YUM源并生成本地缓存
# cd /etc/yum.repos.d/
# wget http://mirrors.163.com/.help/CentOS7-Base-163.repo
# yum repolist
STEP3:用YUM源安装centos-release-gluster软件包(三台服务器与客户机)
# yum install -y centos-release-gluster
##这个软件包必须安装,很重要,它包含了后续所需的YUM库文件
# ls /etc/yum.repos.d/
CentOS7-Base-163.repo CentOS-Gluster-6.repo CentOS-Storage-common.repo
##红字的YUM库就是刚刚下载的,后续会用到
STEP4:三台服务器安装GlusterFS
# yum install glusterfs-server -y
STEP5:启动并设置gluster开机自启(三台服务器都要配置)
# systemctl enable glusterd
# systemctl restart glusterd
STEP6:关闭三台服务器的防火墙
# systemctl stop firewalld
STEP7:使用fdisk为/dev/sdb硬盘进行分区(不做详细演示了,因为很简单)(三台服务器都要配置)
[root@server1 yum.repos.d]# fdisk -l /dev/sdb
Disk /dev/sdb: 21.5 GB, 21474836480 bytes, 41943040 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0x8e8f44d0Device Boot Start End Blocks Id System
/dev/sdb1 2048 41943039 20970496 83 Linux
STEP8:使用mkfs.xfs命令对新分区写入文件系统(三台服务器都要配置)
# mkfs.xfs /dev/sdb1
meta-data=/dev/sdb1 isize=512 agcount=4, agsize=1310656 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=5242624, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
STEP9:创建/dev/sdb1文件系统挂载点(三台服务器都要配置)
# mkdir -p /bricks/brick1
STEP10:修改/etc/fstab,添加分区与挂载点参数(三台服务器都要配置)
# vim /etc/fstab
/dev/sdb1 /bricks/brick1 xfs defaults 1 2
STEP11:使用mount命令将文件系统挂载(三台服务器都要配置)
# mount -a && mount
/dev/sdb1 on /bricks/brick1 type xfs (rw,relatime,seclabel,attr2,inode64,noquota)
STEP12:在Server1将三台服务器添加至“可信池”并查看池状态(只需要在一台执行即可,不是网状结构)
[root@Server1 ~]# gluster peer probe 192.168.10.1
[root@Server1 ~]# gluster peer probe 192.168.10.2
[root@Server1 ~]# gluster peer probe 192.168.10.3
[root@Server1 ~]# gluster peer status
Number of Peers: 2
Hostname: 192.168.10.2
Uuid: c3c9d8ca-1318-4696-b4f5-9ef486401c10
State: Accepted peer request (Connected)Hostname: 192.168.10.3
Uuid: c2f0e33f-8367-4362-9b00-29837eedc7d1
State: Accepted peer request (Connected)
STEP13:三台服务器都创建bl0目录
# mkdir /bricks/brick1/bl0
STEP14:在任何一台服务器都可执行以下操作(创建GlusterFS卷)
# gluster volume create bl0 replica 3 192.168.10.1:/bricks/brick1/bl0 192.168.10.2:/bricks/brick1/bl0 192.168.10.3:/bricks/brick1/bl0
volume create: bl0: success: please start the volume to access data
▲该命令的语法如下图:
gluster volume create volume-name [replica
] :/filepath :/filepath :/filepath
STEP15:启动GlusterFS卷(在任何一台服务器上执行都可以)
# gluster volume start bl0
volume start: bl0: success
STEP16:使用gluster命令查看卷详细信息
[root@server1 ~]# gluster volume info bl0
Volume Name: bl0
Type: Distribute
Volume ID: d32d778d-26c2-43a3-8055-b1afd2c82bbe
Status: Started
Snapshot Count: 0
Number of Bricks: 3
Transport-type: tcp
Bricks:
Brick1: 192.168.10.1:/bricks/brick1/bl0
Brick2: 192.168.10.2:/bricks/brick1/bl0
Brick3: 192.168.10.3:/bricks/brick1/bl0
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
使用Linux客户端进行测试
STEP1:安装centos-release-gluster软件包
[root@Server4 ~]# yum install centos-release-gluster -y
STEP2:安装glusterfs-fuse软件包
[root@Server4 ~]# yum install glusterfs-fuse -y
STEP3:安装glusterfs-fuse
[root@Server4 yum.repos.d]# yum install -y glusterfs-fuse
STEP4:安装glusterfs-server,并且启动Gluster
[root@Server4 yum.repos.d]# yum install glusterfs
STEP5:挂载Gluster卷
[root@Server4 yum.repos.d]# mount -t glusterfs server1:/bl0 /mnt/
STEP6:使用df -h或mount命令查看挂载状态
[root@server4 yum.repos.d]# df -h
server1:/bl0 20G 268M 20G 2% /mnt
[root@server4 yum.repos.d]# mount
server1:/bl0 on /mnt type fuse.glusterfs
STEP7:在客户端使用下列组合命令,对GlusterFS写入文件测试
# for i in `seq -w 1 100`; do cp -rp /var/log/messages /mnt/copy-test-$i; done
STEP8:查看/mnt目录下创建的文件个数(在客户机上)
# ls -lA /mnt | wc -l
STEP9:查看GlusterFS服务器上的目录(在服务器上)
[root@server1 yum.repos.d]# ls -lA /bricks/brick1/bl0/
-rw-------. 2 root root 318304 Oct 27 00:41 copy-test-001
-rw-------. 2 root root 318304 Oct 27 00:41 copy-test-002
-rw-------. 2 root root 318304 Oct 27 00:41 copy-test-003
-rw-------. 2 root root 318304 Oct 27 00:41 copy-test-004
-rw-------. 2 root root 318304 Oct 27 00:41 copy-test-005
-rw-------. 2 root root 318304 Oct 27 00:41 copy-test-006
-rw-------. 2 root root 318304 Oct 27 00:41 copy-test-007
-rw-------. 2 root root 318304 Oct 27 00:41 copy-test-008
-rw-------. 2 root root 318304 Oct 27 00:41 copy-test-009
-rw-------. 2 root root 318304 Oct 27 00:41 copy-test-010
………………………………………………、
-----------------------------------------------------------------------------------------------------------------------------------------
总结以下配置顺序:
- 修改三台服务器及客户机的网络配置(IP地址,/etc/hosts文件)等
- 先从网易获取CentOS7的yum库文件安装centos-release-gluster软件再通过centos-release-gluster软件获取gluster软件
- 配置新硬盘分区并写入文件系统,创建挂载点并将文件系统挂载(不想修改配置文件可以直接用mount挂载)
- 将三台服务器加入“可信池”
- 在三台服务器的新硬盘挂载点中创建目录用于GlusterFS卷(/bricks/brick1/bl0)
- 使用每台服务器下的/bricks/brick/bl0目录创建Gluster FS卷
- 启动新创建的Gluster FS卷
- 客户端安装glusterfs,glusterfs-fuse两个软件包,使用mount命令连接GlusterFS卷
☆附注1:一定要glusterfs-fuse这个软件包,否则在挂载Gluster卷时会发生如下报错
[root@Server4 yum.repos.d]# mount -t glusterfs server1:/bl0 /mnt
mount: unknown filesystem type 'glusterfs'
-----------------------------------------------------------------------------------------------------------------------------------------
☆附注2:一定要安装glusterfs软件包否则将会出现如下报错
[root@Server4 yum.repos.d]# mount -t glusterfs server1:/bl0 /mnt
Mount failed. Please check the log file for more details.
-----------------------------------------------------------------------------------------------------------------------------------------
☆附注3:当出现如下报错时,应用该解决方案
[root@Server3 yum.repos.d]# gluster peer status
Number of Peers: 2
Hostname: server1
Uuid: b902df09-5489-45ba-9853-5be5cda68e76
State: Peer in Cluster (Connected)Hostname: server2
Uuid: dd01f530-fe43-4604-90e4-df4d497e6297
State: Peer in Cluster (Disconnected)##如果这里有邻居Disconnected,解决方案如下
STEP1:在/var/lib/glusterd/peers目录下,找到与该UUID相同的文件
[root@Server3 yum.repos.d]# vim /var/lib/glusterd/peers/dd01f530-fe43-4604-90e4-df4d497e6297
uuid=dd01f530-fe43-4604-90e4-df4d497e6297
state=3
hostname1=server2 ##修改为server2
STEP2:重启Gluster服务
[root@Server3 yum.repos.d]# systemctl restart glusterd
STEP3:再次查看Gluster邻居状态
[root@Server3 yum.repos.d]# gluster peer status
Number of Peers: 2
Hostname: server1
Uuid: b902df09-5489-45ba-9853-5be5cda68e76
State: Peer in Cluster (Connected)Hostname: server2
Uuid: dd01f530-fe43-4604-90e4-df4d497e6297
State: Peer in Cluster (Connected)
☆造成这个故障的原因,基本是/etc/hosts文件修改有问题,也就是主机名解析环节,出现了问题
-----------------------------------------------------------------------------------------------------------------------------------------
☆附注4:如果出现以下报错,则有可能是以下错误
[root@Server4 yum.repos.d]# mount -t glusterfs server1:/bl0 /mnt
Mount failed. Please check the log file for more details.
第一:有可能是因为客户机没有安装glusterfs软件
解决方案:在客户机安装glusterfs软件(yum install -y glusterfs)
第二:有可能是因为服务器端没有启动bl0卷
解决方案:gluster volume start bl0
-----------------------------------------------------------------------------------------------------------------------------------------
☆附注5:如果每台服务器上有两块磁盘,那么命令就如下图
# gluster volume create bl0 server1:/bricks/brick1/bl0 server2:/bricks/brick1/bl0 server1:/bricks/brick2/bl0 server2:/bricks/brick2/bl0
▲该命令的语法为:
# gluster volume create volume-name [replica
] <host1>:/filepath1 :/filepath1 :/filepath2 :/filepath2
-----------------------------------------------------------------------------------------------------------------------------------------
☆附注6:Volume卷扩容
STEP1:首先修改四台(原来三台与新加一台)服务器的/etc/hosts文件
[root@server1 ~]# cat /etc/hosts
192.168.10.1 server1
192.168.10.2 server2
192.168.10.3 server3
192.168.10.4 server4
STEP2:Server4要完成于其他三台相同的配置
- 安装glusterfs-server并启动
- 创建文件系统挂载点/bricks/brick1/bl0
- 对硬盘进行分区,对分区写入文件系统,将文件系统挂载至/bricks/brick1/bl0
- 关闭防火墙
STEP3:在Server1上将Server4加入可信池
[root@server1 ~]# gluster peer probe server4
peer probe: success.
STEP4:将Server4硬盘添加至Volume卷
[root@server1 ~]# gluster volume add-brick bl0 server4:/bricks/brick1/bl0
volume add-brick: success
STEP5:查看Volume卷状态
[root@server1 ~]# gluster volume info
Volume Name: br0
Type: Distribute
Volume ID: cf1ab742-e0c6-485d-8d38-58c771c5cade
Status: Started
Snapshot Count: 0
Number of Bricks: 4
Transport-type: tcp
Bricks:
Brick1: server1:/bricks/brick1/br0
Brick2: server2:/bricks/brick1/br0
Brick3: server3:/bricks/brick1/br0
Brick4: server4:/bricks/brick1/br0
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
☆附注7:在线收缩,将Server4的/bricks/brick1/br0从Gluster FS卷中移除
STEP1:在Server1执行命令
[root@server1 ~]# gluster volume remove-brick br0 server4:/bricks/brick1/br0 force
Remove-brick force will not migrate files from the removed bricks, so they will no longer be available on the volume
Do you want to continue? (y/n) y
volume remove-brick commit force: success
STEP2:查看Gluster FS卷状态
[root@server1 ~]# gluster volume info br0
Volume Name: br0
Type: Distribute
Volume ID: cf1ab742-e0c6-485d-8d38-58c771c5cade
Status: Started
Snapshot Count: 0
Number of Bricks: 3
Transport-type: tcp
Bricks:
Brick1: server1:/bricks/brick1/br0
Brick2: server2:/bricks/brick1/br0
Brick3: server3:/bricks/brick1/br0
Options Reconfigured:
performance.client-io-threads: on
transport.address-family: inet
nfs.disable: on
▲该命令的语法为:
volume remove-brick
-----------------------------------------------------------------------------------------------------------------------------------------
☆附注8:当远程卷,加入Gluster分布式文件系统后,被移除,再被添加时,将会如下报错:
[root@server1 ~]# gluster volume add-brick br0 server4:/bricks/brick1/br0
volume add-brick: failed: Pre Validation failed on server4. /bricks/brick1/br0 is already part of a volume
▲解决方案:
[root@server1 ~]# gluster volume add-brick br0 server4:/bricks/brick1/br0 force
##在后面加上force就可以添加成功
-----------------------------------------------------------------------------------------------------------------------------------------
☆附注9:在客户端使用命令组合测试时,如果出现如下报错:
[root@localhost br0]# for i in `seq -w 1 100`; do cp -rp /var/log/messages /mnt/br0/copy-test-$i; done
cp: cannot create regular file ‘/mnt/br0/copy-test-001’: Input/output error
cp: cannot create regular file ‘/mnt/br0/copy-test-002’: Input/output error
cp: cannot create regular file ‘/mnt/br0/copy-test-003’: Input/output error
cp: cannot create regular file ‘/mnt/br0/copy-test-005’: Input/output error
▲copy-test-001到copy-test-003与copy-test-005都创建失败,那么4呢?
▲因为Gluster分布式文件系统默认采用的是分布式存储,所以我们就可以直接猜到,集群中有某块存储盘故障了
STEP1:在Server1查看Volume卷的状态
[root@server1 br0]# gluster volume status
Status of volume: br0
Gluster process TCP Port RDMA Port Online Pid
-------------------------------------------------------------------------------------------------------------
Brick server1:/bricks/brick1/br0 N/A N/A N N/A
Brick server2:/bricks/brick1/br0 49152 0 Y 8455
Brick server3:/bricks/brick1/br0 N/A N/A N N/A
Brick server4:/bricks/brick1/br0 49152 0 Y 19190Task Status of Volume br0
-------------------------------------------------------------------------------------------------------------
There are no active volume tasks
STEP2:拿Server1举例子,在/bricks/brick1目录下创建一个新目录
[root@server1 brick1]# mkdir /bricks/brick1/br1
STEP3:使用命令,使刚刚创建的新目录顶替之前挂掉的目录
[root@server1 brick1]# gluster volume replace-brick br0 server1:/bricks/brick1/br0 server1:/bricks/brick1/br1 commit force ##后面一定要跟commit force
volume replace-brick: success: replace-brick commit force operation successful
▲该命令的语法为:
gluster volume replace-brick
{commit force}
STEP4:完成后查看Volume卷状态
[root@server1 brick1]# gluster volume status
Status of volume: br0
Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------
Brick server1:/bricks/brick1/br1 49152 0 Y 19337
Brick server2:/bricks/brick1/br0 49152 0 Y 8975
Self-heal Daemon on localhost N/A N/A Y 19345
Self-heal Daemon on server2 N/A N/A Y 19099
Task Status of Volume br0
------------------------------------------------------------------------------
There are no active volume tasks
STEP5:这样就完成了,但是我中间省略了很多步骤,详情可以阅读官网文档,从《Replacing bricks in Replicate/Distributed Replicate volumes》开始
https://gluster.readthedocs.io/en/latest/Administrator%20Guide/Managing%20Volumes/#rebalancing-volumes
☆附注10:当卸载设备时,若出现如下报错:
[root@server1 br0]# umount /bricks/brick1/
umount: /bricks/brick1: target is busy.
(In some cases useful info about processes that use
the device is found by lsof(8) or fuser(1))
解决方案1:
STEP1:使用fuser命令查看正在使用的进程
[root@server1 br0]# fuser -mv /bricks/brick1
USER PID ACCESS COMMAND
/bricks/brick1: root kernel mount /bricks/brick1
root 19653 ..c.. bash
STEP2:使用fuser命令结束占用的进程
[root@server1 br0]# fuser -kv /bricks/brick1
USER PID ACCESS COMMAND
/bricks/brick1: root kernel mount /bricks/brick1
STEP3:再次使用umount命令卸载即可
解决方案2:使用lsof命令找到占用进程(该命令需要yum安装)
STEP1:使用lsof命令找到占用进程(该命令需要yum安装,下框只是举例子!!)
[root@server1 brick1]# lsof /dev
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
glusterfs 19337 root 0r CHR 1,3 0t0 1035 /dev/null
glusterfs 19337 root 1w CHR 1,3 0t0 1035 /dev/null
STEP2:使用kill命令终止该进程
[root@server1 brick1]# kill 19337
-----------------------------------------------------------------------------------------------------------------------------------------
☆附注11:如果服务器重启后,出现了与☆附注3同样的报错时,很有可能是防火墙自启动了
解决方案:
# systemctl stop firewalld ##关闭防火墙
# systemctl disable firewalld ##取消防火墙开机自启动
☆附注12:当你完成了☆附注6的扩容操作后,一定要执行这步操作,否则无法向新卷读写文件
该步骤的名称为“重新均衡卷以修复布局更改(Rebalancing Volume to Fix Layout Changes),有两种模式:
- Fix Layout:重新更改布局,以便可以将文件分发到新添加的存储节点
- Fix Layout and Migrate Data:重新更改布局,同时迁移现有数据来重新均衡卷,同时将存储节点添加至拓扑
Fix Layout模式
STEP1:先将新节点添加至Volume卷并查看卷状态
# gluster volume add-brick br0 server3:/bricks/brick/br0 force
volume add-brick: success
[root@server1 br0]# gluster volume info
Volume Name: br0
Type: Distribute
Volume ID: e6635b97-0f3b-4c00-a1b6-ee3d75ad1d96
Status: Started
Snapshot Count: 0
Number of Bricks: 3
Transport-type: tcp
Bricks:
Brick1: server1:/bricks/brick/br0
Brick2: server2:/bricks/brick/br0
Brick3: server3:/bricks/brick/br0
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
STEP2:在客户端使用长命令测试写入
[root@server4 ~]# for i in `seq -w 1 100`; do cp -rp /var/log/messages /mnt/br0/copy-test-$i; done
STEP3:在Server1,2,3查看/bricks/brick/br0目录下的文件数量
[root@server1 br0]# ls -lA /bricks/brick/br0/ | wc -l
52(多出来的两个文件是.与..下面两个也是)
[root@server2 br0]# ls -lA /bricks/brick/br0/ | wc -l
52
[root@server3 br0]# ls -lA /bricks/brick/br0/ | wc -l
2
STEP4:从上一步可以看到,Server1与Server2被分配到了同样数量的文件,而Server3没有被分发到文件
[root@server1 br0]# gluster volume rebalance br0 fix-layout start
volume rebalance: br0: success: Rebalance on br0 has been started successfully. Use rebalance status command to check status of the rebalance process.
ID: 91eabd92-439c-4e0b-9a1f-52f919ffe933
STEP5:再次在客户端使用长命令测试写入
[root@server4 ~]# for i in `seq -w 1 100`; do cp -rp /var/log/messages /mnt/br0/copy-test-$i; done
STEP6:查看Server1,2,3被分配到的文件数量
[root@server1 br0]# ls -lA /bricks/brick/br0/ | wc -l
40
[root@server2 br0]# ls -lA /bricks/brick/br0/ | wc -l
41
[root@server3 br0]# ls -lA /bricks/brick/br0/ | wc -l
25
Fix Layout and Migrate Data模式
STEP1:客户机挂载GlusterFS后直接使用长命令测试写入
# for i in `seq -w 1 100`; do cp -rp /var/log/messages /mnt/br0/copy-test-$i; done
STEP2:查看Server1,2目录下的文件数量
[root@server1 br0]# ls -lA /bricks/brick/br0/ | wc -l
52
[root@server2 br0]# ls -lA /bricks/brick/br0/ | wc -l
52
STEP3:将Server3添加至信任池
[root@server1 br0]# gluster peer probe server3
peer probe: success.
STEP4:将Server3的/bricks/brick/br0添加至存储池
# gluster volume add-brick br0 server3:/bricks/brick/br0 force
STEP5:使用均衡卷功能,将Server1,2的数据迁移到Server3使其平衡
[root@server1 br0]# gluster volume rebalance br0 start
volume rebalance: br0: success: Rebalance on br0 has been started successfully. Use rebalance status command to check status of the rebalance process.
ID: 834facaf-168b-4c23-bc59-328d878687d0
STEP6:查看Server1,2,3服务器/bricks/brick/br0目录下的文件数量
[root@server1 br0]# ls -lA /bricks/brick/br0/ | wc -l
40
[root@server2 br0]# ls -lA /bricks/brick/br0/ | wc -l
41
[root@server3 br0]# ls -lA /bricks/brick/br0/ | wc -l
25
STEP7:这里可以看到,当Server3加入存储节点后,Server1与Server2将卷下的部分文件,分配给Server3,从而达到存储空间的均衡