当BERT遇上知识图谱
写在前面
上篇博客理了一下一些知识表示学习模型,那今天我们来看目前最流行的BERT模型加上外部知识这个buff后到底会有怎么样的发展。其实这个思路在之前就有出现过比较有意思且高效的工作,像百度的ERNIE和ERNIE2.0 以及清华的ERNIE,这些工作的介绍可以参考站在BERT肩膀上的NLP新秀们(PART I)。
√ KG-BERT from NWU
√ K-BERT from PKU
√ KnowBERT from AI2
1、KG-BERT: BERT for Knowledge Graph Completion(2019)
这篇文章是介绍知识库补全方面的工作,结合预训练模型BERT可以将更丰富的上下文表示结合进模型中,在三元组分类、链接预测以及关系预测等任务中达到了SOTA效果。
具体的做法也非常简单易懂,就是修改了BERT模型的输入使其适用于知识库三元组的形式。
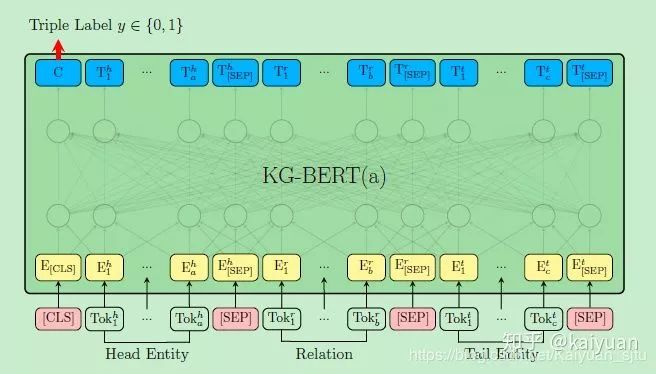
首先是KG-BERT(a),输入为三元组
的形式,当然还有BERT自带的special tokens。举个栗子,对于三元组
,上图中的Head Entity输入可以表示为Steven Paul Jobs was an American business magnate, entrepreneur and investor或者Steve Jobs,而Tail Entity可以表示为Apple Inc. is an American multinational technology company headquartered in Cupertino, California或Apple Inc。也就是说,头尾实体的输入可以是实体描述句子或者实体名本身。
模型训练是首先分别构建positive triple set和negative triple set,然后用BERT的[CLS]标签做一个sigmoid打分以及最后交叉熵损失

上述的KG-BERT(a)需要输入关系,对于关系分类任务不适用,于是作者又提出一种KG-BERT(b),如上图。这里只是把sigmoid的二分类改成了softmax的关系多分类。
有一点想法,既然已经训练了那么多的三元组信息,按理说模型应该是会有学到外部知识的一些信息,也算是一种知识融合,是不是可以把这个模型经过三元组训练后用来做一做其他的NLU任务看看效果?
yao8839836/kg-bertgithub.com

2、K-BERT: Enabling Language Representation with Knowledge Graph(2019)
作者指出通过公开语料训练的BERT模型仅仅是获得了general knowledge,就像是一个普通人,当面对特定领域的情境时(如医疗、金融等),往往表现不如意,即domain discrepancy between pre-training and fine-tuning。而本文提出的K-BERT则像是领域专家,通过将知识库中的结构化信息(三元组)融入到预训练模型中,可以更好地解决领域相关任务。如何将外部知识整合到模型中成了一个关键点,这一步通常存在两个难点:
- Heterogeneous Embedding Space: 即文本的单词embedding和知识库的实体实体embedding通常是通过不同方式获取的,使得他俩的向量空间不一致;
- Knowledge Noise: 即过多的知识融合可能会使原始句子偏离正确的本意,过犹不及。
Okay,理解了大致思想之后我们来分析具体的实现方式。模型的整体框架如下图,主要包括了四个子模块: knowledge layer, embedding layer, seeing layer 和 mask-transformer。对于一个给定的输入
,首先 knowledge layer会从一个KG中注入相关的三元组,将原来的句子转换成一个knowledge-rich的句子树;接着句子树被同时送入embedding layer和seeing layer生成一个token级别的embedding表示和一个可见矩阵(visible matrix);最后通过mask-transformer层编码后用于下游任务的输出。

Knowledge Layer
这一层的输入是原始句子
,输出是融入KG信息后的句子树
通过两步完成:
- K-Query 输入句子中涉及的所有实体都被选中,并查询它们在KG中对应的三元组
;
- K-Inject 将查询到的三元组注入到句子
中,将
中的三元组插入到它们相应的位置,并生成一个句子树 t 。
Embedding Layer
K-BERT的输入和原始BERT的输入形式是一样的,都需要token embedding, position embedding和segment embedding,不同的是,K-BERT的输入是一个句子树,因此问题就变成了句子树到序列化句子的转化,并同时保留结构化信息。

Token embedding
句子树的序列化,作者提出一种简单的重排策略:分支中的token被插入到相应节点之后,而后续的token被向后移动。举个栗子,对于上图中的句子树,则重排后变成了Tim Cook CEO Apple is visiting Beijing capital China is a City now。没错,这的确看上去毫无逻辑,但是还好后面可以通过trick来解决。
Soft-position embedding
通过重排后的句子显然是毫无意义的,这里利用了position embedding来还原回结构信息。还是以上图为例,重排后,CEO和Apple被插入在了Cook和is之间,但是is应该是接在Cook之后一个位置的,那么我们直接把is的position number 设置为3即可。Segment embedding 部分同BERT一样。
Seeing Layer
作者认为Seeing layer的mask matrix是K-BERT有效的关键,主要解决了前面提到的Knowledge Noise问题。栗子中China仅仅修饰的是Beijing,和Apple半毛钱关系没有,因此像这种token之间就不应该有相互影响。为此定义一个可见矩阵,判断句子中的单词之间是否彼此影响
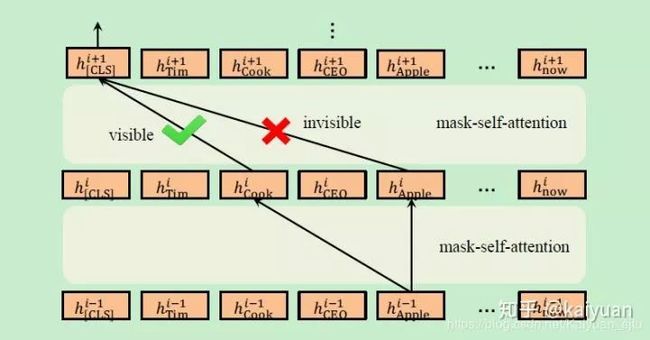
Mask-Transformer
BERT中的Transformer Encoder不能接受上述可见矩阵作为输入,因此需要稍作改进。Mask-Transformer是一层层mask-self-attention的堆叠,
Code Heregithub.com
3、Knowledge-Enriched Transformer for Emotion Detection in Textual Conversations(2019)
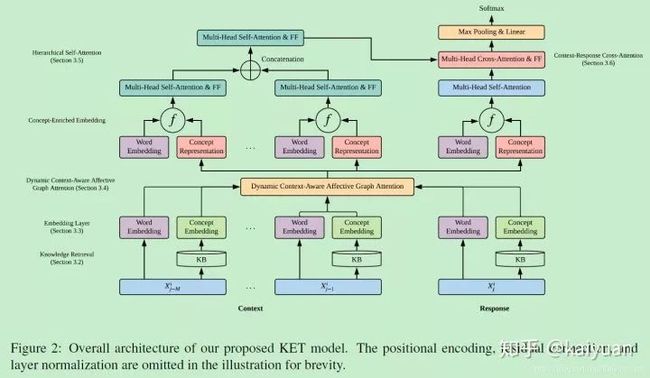
这篇是将外部常识知识用于特定的任务,在对话中的情绪识别问题,提出一种Knowledge- Enriched Transformer (KET) 框架,如下图。关于Transformer、情绪识别等背景知识不做复杂介绍,主要看看是如何将外部知识应用起来的。
任务概览
首先来看一下任务,给定对话数据集,数据格式为
,
表示第
组对话第
句表述,
表示第
组对话第
句表述对应的标签,目标是最大化

Knowledge Retrieval
模型使用了常识知识库ConceptNet和情感词典NEC_VAD作为外部知识来源,对于对话中的每个非停用词token,都会从ConceptNet检索包含其直接邻居的连通知识图 g(t),并且对对于每一个 g(t) ,会移除停用词、词表外词以及置信分数低于1的concept。经过上述操作,最终得到的,对于每一个token,都会有 a list of tuples:
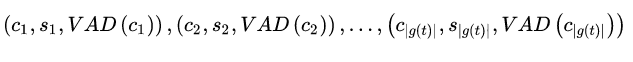
Embedding Layer
就是常见的word embedding 加上 position embedding
Dynamic Context-Aware Affective Graph Attention
这个名字好拗口…动态上下文感知情感图注意力,目的就是计算每个token融入知识后的上下文表示
其中
表示concept embedding,
代表其对应的attention weight
这里面最重要的就是
的计算,在这个模型中假设上下文越相关且情感强度越强的concept越重要,即具有更高的权重。那么如何衡量呢?提出了两个因素:相关性因子和情感因子
- 相关性因子:衡量
和会话上下文之间关系的关联程度。
其中
表示余弦相似度,
表示第
组对话的上下文表示,因为一组对话中可能存在多个句子,所以就表示为所有句子的向量平均
- 情感因子 :衡量
的情感强度
将上述两个因素综合考虑可得到 的表达式
![]()
最后融入知识的上下文表示可以通过一个线性转变得到
Hierarchical Self-Attention
提出了一种层次化自注意力机制,以利用对话的结构表示形式并学习上下文话语的向量表示形式。
- 第一步,对于utterance
,可以表示为:
- 第二步,利用所有对话来学习上下文表示
Context-Response Cross-Attention
最后,通过前面得到的融入外部知识的上下文表示来得出预测标签。
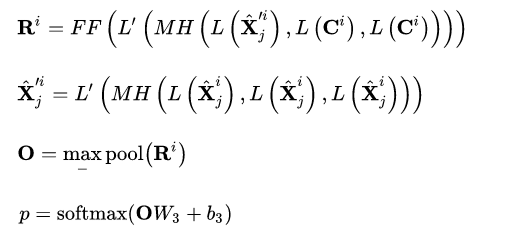
————————————————————————————————————————————————————————————————————————————
看完以后是不是发现大佬们向模型中整合知识的技巧五花八门,但是你再仔细一点会看到大家都有相同一个关键点:**ATTENTION**,哈哈感觉又回到了 attention is all you need。下一篇会也是打算介绍知识融入模型的内容,但重点是会在分析而不是介绍模型~