Java Safepoint 与Stop The World
。原文首发于知乎https://www.zhihu.com/question/57722838
1 SafePoint
1.1 什么是SafePoint
Safepoint是java代码中一个线程可能暂停执行的一个位置,SafePoint保存了其他位置没有的一些运行信息。在这个位置上保存了线程上下文的任何信息,包括对象或者非对象的内部指针。在接收到JVM的进入Stop The World 的信息,在safepoint上,用户线程会被挂起。如果JNI代码想要访问在安全点上的用户线程,那么JNI所在线程也会阻塞直到用户线程离开安全点。因为在安全点上jvm线程信息被很好的描述,所以特别适合做一些全局性的操作,例如代码反优化,线程快照等等。http://peg.hengtiansoft.com/article/jvm-zhong-de-safepoint/
1.2 Safepoint是如何工作的?
在HotSpot虚拟机中,safepoint 协议是主动协作的 。每一个用户线程在安全点 上都会检测一个标志位,来决定自己是否暂停执行。
对于JIT编译后的代码,JIT会在代码特定的位置(通常来说,在方法的返回处和counted loop的结束处)上插入安全点代码。对于解释执行的代码,JVM会设置一个2字节的dispatch tables,解释器执行的时候会经常去检查这个dispatch tables,当有safepoint请求的时候,就会让线程去进行safepoint检查。
1.3 Safepoint的相关总结
翻译自: http://chriskirk.blogspot.com/2013/09/what-is-java-safepoint.html
- 一个线程可以在SafePoint上,也可以不在SafePoint上。一个线程在SafePoint时,它的状态可以安全地其他JVM线程所操作和观测;不在SafePoint时,就不能。
- 在SafePoint上不代表被阻塞(比如:JNI方法就可以在SafePoint上运行),但是被阻塞一定发生在SafePoint上。
- 当JVM决定达到一个全局的SafePoint(也叫做Stop the
World),JVM里面所有的线程都要在SafePoint上并且不能离开,直到JVM让线程允许为止。这对要求所有线程都要被良好的描述的操作(比如CG,代码反优化等等)非常有好处。 - 一些JVM可以持有一些私有的线程到SafePoint上而不需要全局的SafePoint,比如Zing.
- 当你写一些非安全的代码的时候,你必须假设SafePoint有可能发生在任何两个字节码之间。
- 非安全代码的调用并不要求必须有安全点,但是他们可以包含一个或者多个安全点。
- 所有类型的JVM有一些效率非常高的技巧和去快速的穿过SafePoint,线程并不需要真正地进入SafePoint除非虚拟机指示线程这么做。
- 所有的JNI方法都在SafePoint上执行。在安全点,JNI代码都不能改变和观测发起调用JNI代码线程的java机器状态。任何通过JNI
API改变和观测调用线程的状态必须在调用线程离开安全点之后,以及再次进入SafePoint之前的时间内发生。
想了解SafePoint源码的同学,请参照这里:http://hg.openjdk.java.net/jdk7u/jdk7u/hotspot/file/tip/src/share/vm/runtime/safepoint.cpp
2 Stop The World
2.1 什么是Stop the World
Stop the World 是JVM等待所有的用户线程进入safepoint并且阻塞,做一些全局性操作的行为。进入STW的原因不仅仅是因为GC,还有其他原因:
- Garbage collection pauses
- Code deoptimization
- Flushing code cache
- Class redefinition (e.g. hot swap or instrumentation)
- Biased lock revocation
- Various debug operation (e.g. deadlock check or stacktrace dump)
更加详细的参考(很长的一个列表)
http://hg.openjdk.java.net/jdk7/jdk7/hotspot/file/9b0ca45cd756/src/share/vm/runtime/vm_operations.hpp
2.2 Stop The World的四个阶段
根据-XX:+PrintSafepointStatistics –XX:PrintSafepointStatisticsCount=1 参数虚拟机打印的日志文件可以看出,safepoint的执行一共可以分为四个阶段:
- Spin阶段。因为jvm在决定进入全局safepoint的时候,有的线程在安全点上,而有的线程不在安全点上,这个阶段是等待未在安全点上的用户线程进入安全点。
- Block阶段。即使进入safepoint,用户线程这时候仍然是running状态,保证用户不在继续执行,需要将用户线程阻塞。http://blog.csdn.net/iter_zc/article/details/41892567
这篇bog详细说明了如何将用户线程阻塞。 - Cleanup。这个阶段是JVM做的一些内部的清理工作。
- VM Operation. JVM执行的一些全局性工作,例如GC,代码反优化。
只要分析这个四个阶段,就能知道什么原因导致的STW时间过长。
3 STW相关参数
3.1 -XX:+PrintGCApplicationStoppedTime
这个参数用于记录程序运行期间所有情况引发的STW,打开以后,GC日志文件会文件会出现类似于如下内容:
2017-03-31T20:34:54.790+0000: 306738.054: Total time for which application threads were stopped: 0.0434914 seconds, Stopping threads took: 0.0023843 seconds
2017-03-31T20:34:54.790+0000: 306738.054: Application time: 0.0003778 seconds
重点解释一下两个参数:第一个黑体数字306738.054是JVM启动后的秒数,第二个黑字体0.0434914是 JVM发起STW的开始到结束的时间。特别地,如果是GC引发的STW,这条内容会紧挨着出现在GC log的下面,如下:
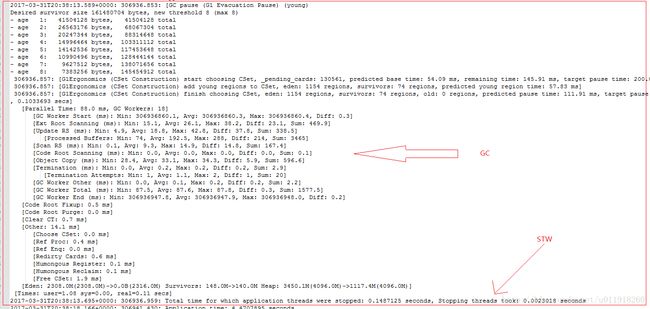
3.2 -XX:+PrintSafepointStatistics -XX:PrintSafepointStatisticsCount=1
这两个参数用于记录STW发生的原因、线程情况、STW各个阶段的停顿时间等。当添加这两个参数后,程序运行期间会打印如下内容(答主的环境会打印到一个blobsvc.out文件):
![]()
如上内容和GC log内容中包含的:Total time for which application threads…一一对应。更加详细的对应关系如下图所示:

参数介绍:
- vmop:引发STW的原因,以及触发时间,本例中是GC。该项常见的输出有:RevokeBias、BulkRevokeBias、Deoptimize、G1IncCollectionPause。数字306936.812是虚拟机启动后运行的秒数。GC log可以根据该项内容定位Total time for which application threads…引发的详细信息。
- total :STW发生时,JVM存在的线程数目。
- initially_running :STW发生时,仍在运行的线程数,这项是Spin阶段的 时间来源
- wait_to_block : STW需要阻塞的线程数目,这项是block阶段的时间来源
- spin,block,cleanup,vmop前面已经做了介绍,sync=spin + block + 其他。
分析blobsvc.out文件,发现好多STW的原因都是RevokeBias或者BulkRevokeBias。

这个是撤销偏向锁操作,虽然每次暂停的 时间很短,但是特别频繁出现。偏向锁相关内容请参考:http://www.cnblogs.com/paddix/p/5405678.html 所以在一些高并发的系统中,禁掉JVM偏向锁优化,可以提升系统的吞吐量。禁用偏向锁的参数为: -XX:-UseBiasedLocking
4 引发长时间STW的Troubleshooting
引发STW时间过长的原因答主能确定的有如下几个:
- Full GC。因为GC的时间算在STW里面。建议优化GC缩短STW时间。
- RevokeBias 通过分析STW日志,发现有时候撤销偏向锁操作也会消耗很长时间。在高并发系统中 建议禁用偏向锁
还有一个引发长时间的STW 原因是因为程序中存在非常长的Count Looop并且循环中没有执行其他函数,或者执行的函数被内联进来。这种程序会导致Spin的时间变的很长,JVM要等待程序运行完循环之才进入STW(通常在方法的返回处和counted loop的结束处插入SafePoint) 导致SWT时间变长.这个问题R大也曾经讨论过:http://hllvm.group.iteye.com/group/topic/38232
@RednaxelaFX
可惜这个猜想答主并不能重现。答主在执行10w次1亿的长循环,Spin时间基本在5毫秒以下,和预想的结果很不一样。希望R大能够指点一下。
答主的测试程序如下:
class LongCount implements Runnable {
public void run() {
long k = 0;
System.out.println("开始执行");
for(int j =0;j<100000;j++)
for(long i = 0;i<100000000L;i++){
k++;
}
System.out.println("执行结束");
System.exit(0);
}
}
public class SafePointTest {
public static void main(String[] args) {
new Thread(new Runnable() {
public void run() {
while(true){
new Object();
}
}
}).start();
new Thread(new LongCount()).start();
}
}JVM参数为:
-XX:+ExplicitGCInvokesConcurrent
-XX:G1HeapRegionSize=2m
-XX:GCLogFileSize=52428800
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=C:\Users\chenc49\Desktop\log\1.txt
-XX:InitialHeapSize=50m
-XX:MaxHeapSize=50m
-XX:InitiatingHeapOccupancyPercent=30
-XX:MaxGCPauseMillis=50
-XX:MaxHeapSize=256m
-XX:MaxTenuringThreshold=8
-XX:NumberOfGCLogFiles=3
-XX:+PrintAdaptiveSizePolicy
-XX:+PrintGC
-XX:+PrintGCApplicationConcurrentTime
-XX:+PrintGCApplicationStoppedTime
-XX:+PrintGCDateStamps
-XX:+PrintGCDetails
-XX:+PrintGCTimeStamps
-XX:+PrintSafepointStatistics
-XX:PrintSafepointStatisticsCount=1
-XX:+PrintTenuringDistribution
-XX:+UnlockExperimentalVMOptions
-XX:+UseCompressedOops
较小堆空间可以保证频繁进入STW进行GC。答主在JDK6和8的运行环境得到的结果都是一样的:Spin的时间非常短。
不知道是不是我测试程序写的有问题,如果能重现长时间的Spin,希望大家能够贴出来。
答主提的问题,基本上已经没办法重现,但是如果再次出现total time for which application threads were stopped 时间很长的情况,这个回答,也算一个参考的思路.
如果有错误不足之处,还请各位批评指出哈