Oracle数据库(索引、视图、伪列与伪表)
引用推荐博客、数据库网址
http://www.educity.cn/shujuku/1598602.html(希赛数据库学院)
http://blog.csdn.net/kingzone_2008/article/details/8182792(索引)
http://www.linuxidc.com/Linux/2014-11/109301.htm
http://blog.itpub.net/28929558/viewspace-1161733/
http://www.cr173.com/html/17456_1.html(oracle 数据库索引完整解析)(索引知识点推荐!!!!)
一、伪列与伪表
oracle系统为了实现完整的关系数据库功能,系统专门提供了一组成为伪列(Pseudocolumn)的数据库列,这些列不是在建立对象时由我们完成的,而是在我们建立时由Oracle完成的。Oracle目前有以下伪列:
1.1、伪列
创建表时,没有定义过的列,不在表结构中,为存储在表中,查询后,自动附加的列,查询时,自动生成值,只能查询,不能update、delete、insert。常见的伪列分为以下几种。详细介绍rowid、rownum。
CURRVAL AND NEXTVAL 使用序列号的保留字
LEVEL 查询数据所对应的层级
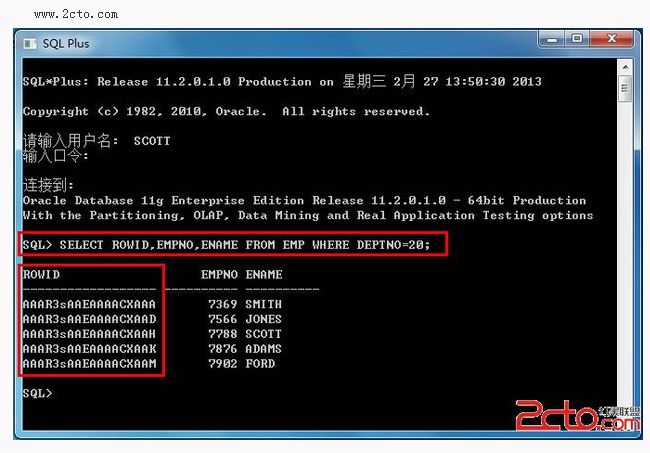
ROWID 记录的唯一标识
ROWNUM 限制查询结果集的数量
rowid概念:伪列一种数据类型,唯一标识一条记录物理位置的一个id,基于64位编码的10个字符的显,未存储在表中,可以从表中查询,但不支持插、更新、删除他们,伪列作用:能以最快的方式访问表中的一行,能显示表的行是如何存储的,作为表的唯一标识,伪列组成:rowid确定了每条记录是在oracle中的哪一个数据对象,数据文件、块、行上。
伪列格式如下:数据对象编码+文件编号+块编号+行编号
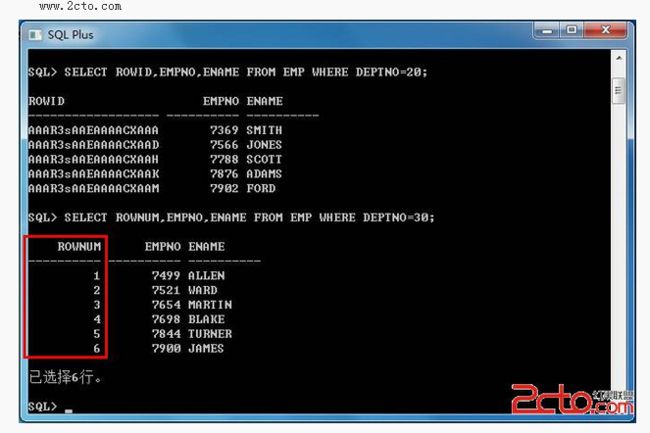
rownum概念:rownum是一个序列,是oracle数据库从数据文件或缓冲区中读取数据的顺序,连续生成,它取得的第一条记录则rownum为1,第二条为2,依次类推。如果用>,>=,=,between…and这些条件,因为从缓冲区或数据文件中的到的第一条记录的rownum为1,则被删除,接着取下条,可是它的rownum还是1,又被删除,依次类推,便没有了数据。所以如果想取到数据,条件必须包含1且连续。
如果想用rowmun > 10 这种条件的语句就要用嵌套语句,把rownum先生成然后对他进行查询。
select * from (select rownum rn,a.* from table a)b where b.rn >10。注:rownum不能加表名前缀!
分页1:省内存不省时间
select * from (
select rownum rn,a.* from a
where rownum <= &pageNo * &pageSize
)b where b.rn >= 1 + (&pageNo -1) * &pageSize;分页2:省时间不省内存
select * from (
select rownum rn,a.* from a
)b where b.rn >= 1 + (&pageNo -1) * &pageSize
and b.rn <= &pageNo * &pageSize;排序分页1:省内存不省时间
select * from (
select rownum rn,b.* from (
select * from a order by 类名 排序类型
)b where rownum <= &pageNo * &pageSize
)c where c.rn >= 1 + (&pageNo -1) * &pageSize;排序分页2:省时间不省内存
select * from (
select rownum rn,b.* from (
select * from a order by 类名 排序类型
)b
)c where c.rn >= 1 + (&pageNo -1) * &pageSize
and c.rn <= &pageNo * &pageSize;关于伪列简单演示:
rowid记录每条记录在硬盘上位置的唯一标识 ,进入scott用户,进行下面操作,观察结果:
1.2、伪表
(1)、DUAL 表
该表主要目的是为了保证在使用SELECT语句中的语句的完整性而提供的。
一般用于验证函数。例如:
select sysdate,to_char(sysdate,’yyyy-mm-dd HH24:mm:ss’) from dual
(2)、oracle的几个伪列函数
ORACLE有几个函数专门用来产生伪列的,rownum,rowid,row_number(),rank,dense_rank,lan
1 Connect by 语句
该语句结合伪列rownum或level 可以产生一个结果集.
1. 基本用法:
产生1~~100之间的整数
Select rownum xh from dual connect by rownum<=100;
Select level xh from dual connect by level<=100;
2. 高级用法
2.1.产生所有汉字,汉字内码为:19968~~~40869之间
select t.* from(
select rownum xh,nchr(rownum) hz from dual
connect by rownum<65535
) t
where t.xh between 19968 and 40869
2 rownum按行的顺序自动增加产生
row_number() 给每个组内的不同记录进行排号(分组可不设)
关于伪表简单演示(标识查询结果集中记录序号 ):
二、索引
Oracle数据库中提供的索引类型:B-树索引、位图索引、基于函数的索引、反向值索引、域索引。索引是与表相关、可选,用于加速对表的访问,索引是oracle对象中的一种。关于索引的代码练习放在附录一。
create index 索引名 on 表名(列名,…)→ 生成一个索引表:索引值和rowid
当往原表中插入一条记录时,会将这张表中索引值同时插入索引表,索引表中索引值调整排序,索引由oracle自己维护,无须用户干预,表:创建表后,自动为主键列和唯一列创建索引
创建索引:
create index 索引名 on 表名(列名,...)[tablespace 表空间名];
删除索引:
drop index 索引名;
2.1索引的两面性
一方面加速查询;另外一方面需要维护索引:当往原表中,插入一条记录时,会将这张表中索引列的值,同时插入索引表,索引表要调整数据顺序,索引要占用存储空间。建立索引,系统要占用大约为表的1.2倍的硬盘和内存空间来保存索引;更新数据时,必须同时对索引进行更新,以维持数据和索引的一致性。因此,不恰当的索引反而会降低系统性能,因为在数据插入、修改和删除时需要额外的时间更新索引。例如,如在如下字段建立索引一般是不恰当的:很少或从不引用的字段;逻辑型字段,如男或女(是或否)等。总之,建立索引提高查询效率是以消耗一定的系统资源(额外的存储和增删改操作额外的索引更新时间)为代价的,DBA需要慎重考虑在哪些字段上建立索引,以及建立哪种索引。
什么时候用索引:经常使用某个列作为查询条件,数据量大的时候。
2.2 索引使用原则
在大表上建立索引才有意义;在where子句(where子句中一般将熵值较大的字段放在后面,SQL语句的查询条件是从右向左)或连接条件上经常使用的列上建立索引;索引的层次不宜超过4层。
A.依据表的大小创建索引。一般来说,小表不必建索引,可以通过全表扫描的性能分析来判断建立索引后是否改善了数据库性能。
B.依据表和列的特征创建索引。
在经常进行查询的列上建立索引,可以提高搜索的速度;
在经常进行连接查询的列上建立索引,可以提高搜索速度;
C.限制表中索引的数量。过多或过少的索引都会影响系统的性能
D.要合理安排符合索引总列的顺序,将频繁使用的列放在其他列的前面
2.3索引作用
(1)、支持快速查询
对于存储大量数据的数据库,线性查找效率很低,索引技术使数据库支持次线性时间查找以提高查询性能。索引是所有提高查询性能的数据结构。目前已经有许多数据结构可用于提高查询速度,事实上计算机科学领域的研究有很大一部分工作是对索引数据结构的研究和分析。索引数据结构的研究需要考虑查询性能、索引大小和索引更新性能等方面的折中。许多索引提供对数时间复杂度(O(logn(N)))的查找性能,某些情况下甚至可以获得O(1)时间复杂度。
(2)、实现数据库约束
索引也可以用于实现数据库的约束,如UNIQUE,EXCLUSION,PRIMARY KEY和FOREIGN KEY。UNIQUE索引约束其所引用的列,该列的值唯一。数据库系统通常会默认在PRIMARY KEY(主键)的列上创建索引。
关于索引是怎么样增加查询速度的以及索引是怎么实现的,可以查找相关的知识,在这里只是简单的介绍一些B-Tree。 就不深入介绍了。推荐博格:http://blog.csdn.net/kingzone_2008/article/details/8182792
三、视图
一个虚拟表,视图并不在数据库中存储数据值,数据库中值在数据字典中存储对视图的定义。
视图优点:
1.为用户集中数据,简化用户的数据查询和处理
2.屏蔽数据库的复杂性,用户不必了解数据库的复杂性
3.简化用户权限的管理,只授予用户使用视图的权限
4.便于数据共享,多个用户不必都定义所需的数据
5.可以重新阻止数据,以便关联到其他应用中
语法:
create [or replace] view 视图名 as select … [with check option][with read only]
create or replace 用于创建和修改视图
with check option 用于创建限制数据访问的视图
with read only 用于创建只读视图视图的类别:
1.简单视图 基于单个表并且不包含函数或表达式的视图,在该视图上可以执行DML语句(即可以执行增删改操作)
2.复杂视图 包含函数、表达式或者分组数据的视图,在该视图上执行DML语句时必须要符合特定条件。 注:在定义复杂视图时必须为函数或表达式定义别名。
3.连接视图 基于多个表建立的视图,一般来说不会在该视图上执行insert、update、delete操作。
4.只读视图 只允许进行select操作的视图,在该视图时指定with read only选项。 注:该视图上不能执行insert、update、delete操作。
5.check约束视图 with check option用于在视图上定义check、update操作时,数据必须符合查询结果。
如何查询视图和表的更新权限
select table_name,column_name,updatable,insetable,deletable from user_update_columns;
updatable 表示当前字段是否可以执行修改操作
insertable 表示当前字段是否可以执行添加操作
deletable 表示当前字段是否可以执行删除操作附录一:
Oracle索引(Index)是关系数据库中用于存放表中每一条记录位置的一种对象,主要目的是加快数据的读取速度和数据的完整性检查。索引的建立是一项技术性要求非常高的工作。
一般在数据库设计阶段就要考虑到如何设计和创建索引。
- 创建索引
CREATE [UNIQUE] INDEX [schema.] index
ON [schema.] table (column [ASC | DESC], column [ASC | DESC]...)
[CLUSTER schema.cluster]
[INITRANS n]
[MAXTRANS n]
[PCTFREE n]
[STORAGE storage]
[TABLESPACE tablespace]
[NO SORT]
关键字说明:
UNIQUE: 该参数用来指明所创建的索引为唯一索引。
CLUSTER: 该参数为可选参数,用来指定一个聚簇(Hash cluster 不能创建索引)。
INITRANS, MAXTRANS: 为可选参数,指定初始和最大的事务入口数。
TABLESPACE: 索引的存储表空间。
STORAGE: 存储参数。
PCTFREE: 索引数据块空闲的百分比。
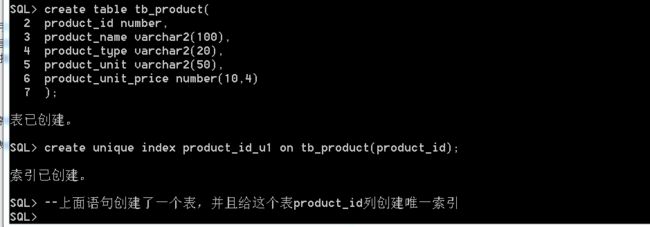
NO SORT: 不排序(存储时就按照升序进行排序,所以这里指出不再排序)。示例:创建一张产品表(tb_product),为该表的product_id列创建索引,以便在使用到该列时提高查询效率。
- 修改索引
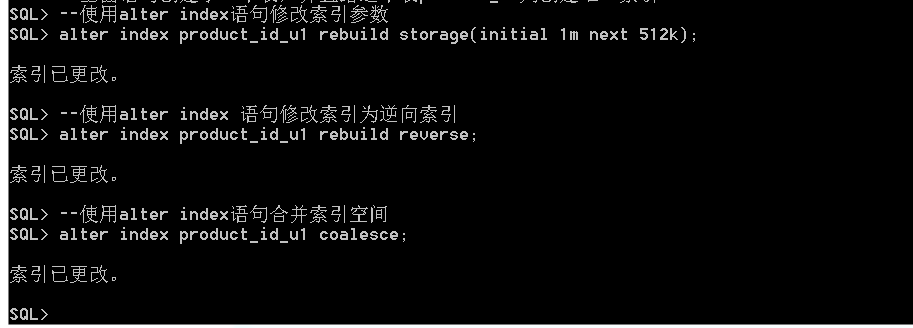
索引的修改主要由数据库管理员完成,修改索引主要涉及到修改索引的存储参数、重建索引、对无用的索引空间进行合并等。
修改索引的语法:
ALTER [UNIQUE] INDEX [user.] index
INITRANS n
MAXTRANS n
REBUILD
[STORAGE ]
关键字说明:
INITRANS n: 表示一个块内同时访问的初始事务的入口数,n为十进制整数。
MAXTRANS n: 表示一个块内同时访问的最大事务入口数,n为十进制整数。
REBUILD: 表示根据原来的索引结构重新建立索引,也就是重新对表进行全表扫描以后创建索引数据。
STORAGE : 表示存储数据。示例:
- 删除索引
可以使用DROP语句删除索引。
DROP INDEX schema.index;