分析Ajax请求并抓取今日头条街拍美图(2019.8最新)
分析站点发现,索引页的不同之处在于offset不同,其详情的图片数据放在原始js文档里面的gallery变量里面,这个变量不是隐藏在HTML里,所以不能用beautifulSoup、pyQuery等库来解析,这里使用正则表达式来解析
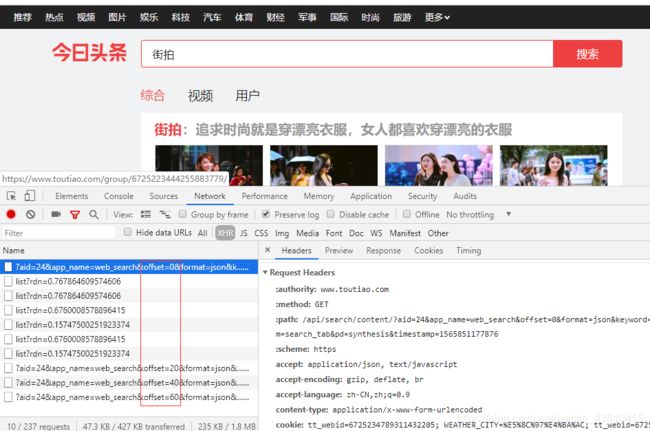
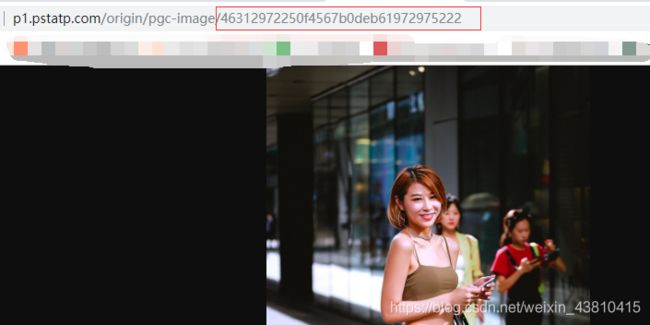
看下面图片可知存放图片的json格式地址并不规范,在代码里面还需要进行格式化才能解析
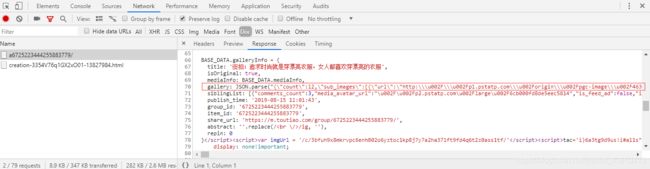
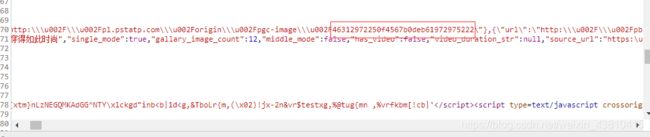
流程框架:
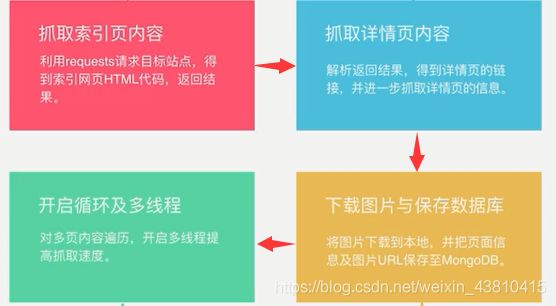
具体代码,有注释:
spider.py:
# -*- coding: utf-8 -*-
"""
Created on Thu Aug 15 14:11:43 2019
@author: Mr.zeng
"""
from hashlib import md5
from urllib.parse import urlencode
from requests.exceptions import RequestException
import requests
import json
import time
from bs4 import BeautifulSoup
import re
import os
import pymongo
from config import MONGO_URL,MONGO_TABLE,MONGO_DB,GROUP_START,GROUP_END,KEYWORD #引入配置文件的变量,用 * 号来代替这一串的变量的话会失败,这个不清楚为什么
from multiprocessing import Pool
from json.decoder import JSONDecodeError
client = pymongo.MongoClient(MONGO_URL,connect=False) #生成mongodb对象
db = client[MONGO_DB] #传入数据库名称
#请求的头部信息,不加入请求头的话返回的data为null
headers = {
'accept': 'application/json, text/javascript',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'content-type': 'application/x-www-form-urlencoded',
'cookie': 'tt_webid=6725234789311432205; WEATHER_CITY=%E5%8C%97%E4%BA%AC; tt_webid=6725234789311432205; csrftoken=ac8e76cd6bfea1dee5654772342d3b32; s_v_web_id=0236c69843aaac23b1ef7720c4d8ecf1',
'referer': 'https://www.toutiao.com/search/?keyword=%E8%A1%97%E6%8B%8D',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36',
'x-requested-with': 'XMLHttpRequest'
}
#抓取索引页的内容
def get_page_index(offset,keyword,timestamp):
data = { #构造data把要请求的参数在网页的请求参数里复制过来
'aid': '24',
'app_name': 'web_search',
'offset': offset,
'format': 'json',
'keyword': keyword,
'autoload': 'true',
'count': '20',
'en_qc': '1',
'cur_tab': '1',
'from': 'search_tab',
'pd': 'synthesis',
'timestamp': timestamp #时间戳,现在的今日头条的url最后会有一个13位的时间戳
}
url = 'https://www.toutiao.com/api/search/content/?' + urlencode(data) #urlencode方法可以把字典类型转化为URL的请求参数
try:
response =requests.get(url,headers=headers)
if response.status_code == 200 : #判断返回的状态码
return response.text
return None
except RequestException:
print('请求索引页出错')
return None
#解析数据
def parse_page_index(html):
try:
data = json.loads(html) #把json字符串转化为json格式的变量
if data and 'data' in data.keys():#判断json里面是含有data属性, data.keys为键名
for item in data.get('data'): #遍历data
yield item.get('article_url') #构造生成器
except JSONDecodeError:
pass
#获取详情页信息
def get_page_detail(url):
try:
response =requests.get(url,headers=headers)
if response.status_code == 200 : #判断返回的状态码
return response.text
return None
except RequestException:
print('请求详情页出错',url)
return None
#解析详情页内容
def parse_page_detail(html,url): #图片的详情是存放在原始的HTML里面
soup = BeautifulSoup(html,'lxml') #使用BeautifulSoup解析
title = soup.select('title')[0].get_text() #获取标题
print(title)
images_pattern = re.compile('JSON.parse\(\"(.*?)\"\),',re.S) #括号需要转义
result = re.search(images_pattern,html)
if result:
#匹配json串数据,并解析
#格式调整
newResult = result.group(1).replace('\\\\', '#') #group(1)即为第一个括号里面的内容
newResult = newResult.replace('\\', '')
newResult = newResult.replace('#', '\\\\')
newResult = newResult.replace('\/', '/')
newResult = newResult.replace('\\u002F', '/')
data =json.loads(newResult)
if data and 'sub_images' in data.keys():
sub_images =data.get('sub_images')
images = [item.get('url') for item in sub_images] #获取sub_images元素里面的url
for image in images: download_image(image) #下载图片
return{
'title':title,
'url':url,
'images':images
}
#定义一个存储到mongodb的方法
def save_to_mongo(result):
if result: #必须加一个判断,因为有些爬取结果为空,否则会报'TypeError:‘NoneType’ object is not iterable'错误
if db[MONGO_TABLE].insert(result):
print('存储成功',result)
return True
return False
#图片下载
def download_image(url):
print('正在下载',url)
try:
response =requests.get(url,headers=headers)
if response.status_code == 200 : #判断返回的状态码
save_image(response.content)
return None
except RequestException:
print('请求图片出错',url)
return None
#存储图片
def save_image(content):
#第一次参数为路径,第二个为文件名,第三个为后缀名,使用md5避免下载重复,os.getcwd()是获取当前目录
file_path = '{0}/{1}.{2}'.format(os.getcwd(),md5(content).hexdigest(),'jpg')
if not os.path.exists(file_path):
with open(file_path,'wb') as f :
f.write(content)
f.close()
def main(offset):
timestamp =int(round(time.time() * 1000)) #获取本地时间的13位时间戳
html = get_page_index(offset,KEYWORD,timestamp)
for url in parse_page_index(html):
html =get_page_detail(url)
if html:
result = parse_page_detail(html,url)
save_to_mongo(result)
if __name__ == '__main__':
os.chdir('images') #切换到images目录,把下载的图片下载到images目录里去,而不是根目录
print ("当前工作目录 : %s" % os.getcwd())
groups =[x*20 for x in range(GROUP_START,GROUP_END+1)]
pool = Pool() #声明进程池
pool.map(main,groups)
config.py:
# -*- coding: utf-8 -*-
"""
Created on Thu Aug 15 14:11:43 2019
@author: Mr.zeng
"""
MONGO_URL='localhost' #链接地址
MONGO_DB='toutiao' #数据库名
MONGO_TABLE='toutiao' #表名
GROUP_START=1 #起始循环
GROUP_END=20 #终止循环点
KEYWORD='街拍'
运行结果截图:
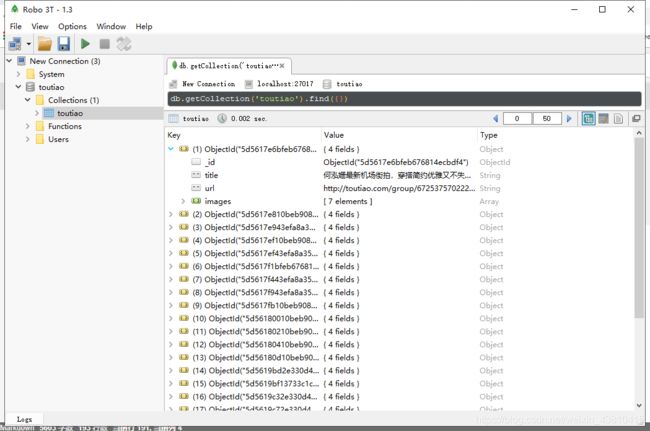
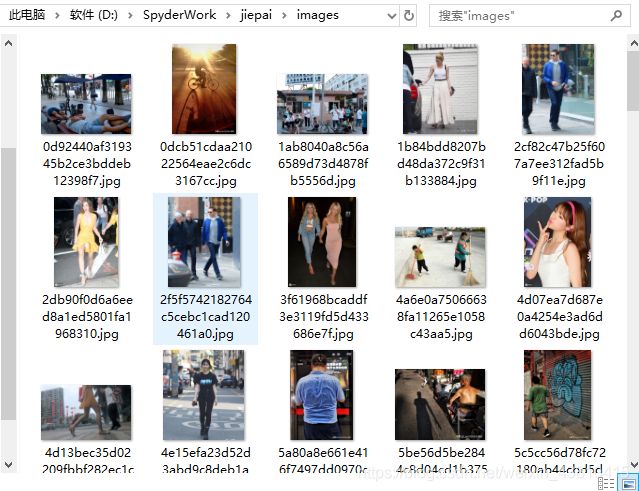
在运行代码前还需要在工作目录下还需要创建images目录来存放下载的图片