Flume_日志收集工具
目录
一、前言
二、简介
2.1 概述
2.2 发展历程
2.3 基本思想及特点
三、Flume NG 基本架构
3.1 基本架构
3.2 Agent 内部组件
1、Source
2、Channel
3、Sink
3.3 高级组件
1、Interceptor
2、Channel Selector
3、Sink Processer
四、Flume NG 数据流拓扑构建方法
4.1 如何构建数据流拓扑
4.2 流式数据获取方式
4.2 常见拓扑架构
1、多路合并
2、多路复用
4.3 Agent配置方式
1、配置Agent
2、配置单个组件
五、Flume的应用
5.1 flume的安装
5.2 简单的一对一案例(LogAgent实例)
5.3 数据流拓扑实例剖析
1、多路合并拓扑实例
2、多路复用拓扑实例
一、前言
任何一个生产系统在运行过程中都会产生大量的日志,日志往往隐藏了很多有价值的信息。在没有分析方法之前,这些日志存储一段时间后就会被清理。随着技术的发展和分析能力的提高,日志的价值被重新重视起来。在分析这些这些日志之前,需要将分散在各个生产系统中的日志收集起来。本篇介绍广泛应用的Flume日志收集系统。
二、简介
2.1 概述
Flume是一款高性能、高可用的分布式日志收集系统。它有效地组装、聚集大量的日志数据并立即传输至一个集中的位置。同Flume相似的日志收集系统还有 Facebook Scribe、Apache Chuwka。
官网地址:http://flume.apache.org
文档地址:http://flume.apache.org/documentation.html
2.2 发展历程
Flume初始的发行版本目前被统称为 Flume OG,属于Cloudera。但随着Flume功能的扩展,Flume OG代码工程臃肿、核心组件设计不合理、核心配置不标准等缺点逐渐暴露出来,尤其是在 Flume OG 的最后一个发行版本 0.94.0中,日志传输现象尤为严重。为了解决这些问题,2011年10月22日,Cloudera完成了Flume-728,对Flume进行了里程碑式的改动:重构核心组件、核心配置及代码架构,重构后的版本统称为Flume NG;改动的另一原因是将Flume纳入Apache旗下,Cloudera Flume更名为 Apache Flume。
2.3 基本思想及特点
基本思想:Flume采用了插拔式软件架构,所有组件均是可插拔的,用户可以根据自己的需要定制每个组件。Flume本质上是一个中间件,它屏蔽了流式数据源和后端中心化存储系统之间的异构性,使得整个数据流非常容易扩展和演化。
特点:
- 良好的扩展性:Flume架构是完全分布式的,没有任何中心化组件,这使得它非常容易扩展。
- 高度定制化:各个组件(比如Source、Channel和Sink等)是可插拔的,用户很容易根据需求进行定制。
- 良好的可靠性:Flume内置了事务支持,能够保证发送的每条数据能够被下一跳收到而不会丢失。(事务体现在Sink必须在Event被存入Channel后,或者已经被成功传递给下一个Agent后,才能把Event从Channel中删掉)
- 声明化动态配置:Flume提供了一套声明式配置语言,用户可根据需要动态配置一个基于Flume的数据流拓扑结构。
- 语意路由:可根据用户的配置,将流式数据路由到不同的组件或存储系统中,这使得搭建一个支持异构的数据流变的非常容易。
三、Flume NG 基本架构
3.1 基本架构
Flume的数据流是通过一系列称为Agent的组件构成的,如下图所示,一个Agent可以从客户端或前一个Agent接收数据,经过过滤(可选)、路由等操作后,传递给下一个或多个Agent(完全分布式),直到抵达指定的目标系统。用户可根据需要拼接任意多个Agent构成一个数据流水线。

Flume将数据流水线中传递的数据称为“Event”,每个Event由头部和字节数组(数据内容)两部分构成,其中头部由一系列key/value对构成,可用于数据路由,字节数组封装了实际要传递的数据内容,通常使用Avro,Thrift、Protobuf等对象序列化而成。
Flume中Event可由专门的客户端程序产生,这些客户端程序将要发送的数据封装成Event对象,并调用Flume提供的SDK发送给Agent。
3.2 Agent 内部组件

1、Source
Flume数据流中接收Event的组件,通常从Client程序或上一个Agent接收数据并写入一个或多个Channel。为了方便用户使用,Flume提供了很多Source实现,主要包括:
Avro Source、Thrift Source、Exec Source、Spooling Directory Source、Kafka Source、Syslog Source、HTTP Source。
2、Channel
Channel是一个缓存区,它暂存Source写入的Event,直到被Sink发送出去。目前Flume主要提供了以下几种Channel实现:
Memory Channel、File Channel、JDBC Channel、Kafka Channel
3、Sink
负责从Channel中读取数据,并发送给下一个Agent(的Source)或目标系统。Flume主要提供以下几种Sink实现:
HDFS Sink、HBase Sink、Avro/Thrift Sink、MorphlineSolrSink/ElasticSeratchSink、Kafka Sink
3.3 高级组件
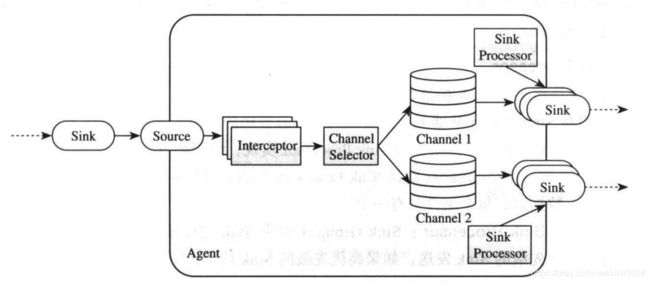
1、Interceptor
允许用户修改或丢弃传输过程中的Event。Interceptor是一个实现了org.apache.flume.interceptor.Interceptor接口的类。用户可配置多个Interceptor,形成一个Interceptor链,这样,前一个Interceptor返回的Event将被传递给下一个Interceptor,而传递过程中,任何一个Interceptor均可修改或者丢弃当前的Event。Flume自带了很多Interceptor实例,常用的有:
Timestamp Interceptor、Host Interceptor、UUID Interceptor、Regex Filtering Interceptor、Regex Extractor Interceptor
2、Channel Selector
允许Flume Source选择一个或多个目标Channel,并将当前Event写入这些Channel。Flume提供了两种Channel Selector实现,分别如下:
Replicating Channel Selector(默认)、Multiplexing Channel Selector
3、Sink Processer
允许将多个Sink组装在一起形成一个逻辑实体(称为“Sink Group”),而Sink Processer则在Sink Group基础上提供负载均衡以及容错的功能(当一个Sink挂掉了,可由另一个Sink接替)。Flume提供的Sink Processor实现:
Default Sink Processor(默认)、Failover Sink Processer、Load balancing Sink Processer(round_robin\random)
四、Flume NG 数据流拓扑构建方法
4.1 如何构建数据流拓扑
步骤 1:确定流式数据获取方式
步骤 2:根据需求规划Agent,包括Agent数目,Agent依赖关系等。
步骤 3:设置每个Agent,包括Source,Channel 和 Sink等组件的基本配置。可参考Flume官方文档全面而详细地了解各个组件等配置项。
步骤 4:测试构建的数据流拓扑。
步骤 5:在生产环境部署该数据流拓扑
以下重点关注步骤1~3的操作方法。
4.2 流式数据获取方式
1)远程过程调用(RPC):Flume支持目前主流的RPC协议,包括Avro和Thrift,比如下面的示例:
bin/flume-ng avro-client -H localhost -p 41414 -F /usr/logs/ngnix.log解释:该命令启动了一个Avro客户端,将 /usr/logs/ngnix.log 中的数据发送到指定的Avro服务器(启动在本地的41414端口)上。
2)TCP 或 UDP:Flume提供了syslog source,支持TCP和UDP两种协议,用户可以通过这两种协议将外部数据写入Flume。
3)执行命令:Flume提供了Exec Source,允许用户执行一个shell命令产生流式数据。
4.2 常见拓扑架构
1、多路合并
在流式日志收集应用中,常见的一种场景是大量的日志产生客户端将日志发送到少数几个聚集节点上,由这些节点对日志进行聚集合并后,写入后端的HDFS中,整个数据流如下所示:

解释:在该数据流中,每个Web Server 将流式日志发送到一个对应的Flume Agent上,Flume Agent收到数据后,统一发送给一个汇总的Agent,由它写入HDFS。
2、多路复用
Flume支持将数据路由到多个目标系统中,这是通过Flume内置的多路复用功能实现的,典型拓扑图如下:

解释:在该数据流中,Source产生的数据按照类别被写入不同的Channel,之后由不同Sink写入不同的目标系统中,需要注意的是,Sink可进一步写入另外一个Agent,进而实现Agent级联。
4.3 Agent配置方式
Flume采用标准的Java property文件格式描述各个组件的配置,当Agent启动时,会读取本地对应的Javaproperty文件,并按照配置要求创建和启动Agent内部的各个组件。举例如下:
bin/flume-ng agent -n flume_agent_name -c conf -f conf/flume-conf.properties解释:该命令指定了Agent名称(flume_agent_name),Flume配置文件存放目录(conf)和该Agent的配置文件(conf/flume-conf.properties),之后Flume将按照conf/flume-conf.properties的描述,启动名为flume_agent_name的Agent。
1、配置Agent
Agent由Source、Channel 和 Sink 构成,其中Source 和 Sink 充当生产者和消费者的角色,Channel可看作缓冲区,Source可对应多个Channel,但每个Sink只能与一个Channel关联。每个组件的定义描述由name、type和一系列特定属性构成。
Agent的格式如下:
# 列出 agent 包含的 source,sink 和 channel,可自定义名称
.sources =
.sinks =
.channels =
# 为source 设置 channel
.sources..channels = ,...
# 为sink 设置 channel
.sinks..channel = 2、配置单个组件
用户可对Agent内部每个组件单独进行配置,格式如下:
# 设置 source 的属性 值为
.sources.. =
# 设置 channel 的属性 值为
.channels.. =
# 设置 sink 的属性 值为
.sinks.. =
五、Flume的应用
5.1 flume的安装
flume各版本下载地址
解压已下载的文件到目标目录,将flume下的配置文件 conf/flume-env.sh 中 JAVA_HOME 的值改成本机的jdk地址即可。
5.2 简单的一对一案例(LogAgent实例)

需求:需要从本地磁盘/tmp/logs 目录下获取数据,写入分布式文件系统HDFS中,它对应的配置文件logagent.property如下:
# 配置Agent
LogAgent.sources = mysource
LogAgent.channels = mychannel
LogAgent.sinks = mysink
LogAgent.sources.mysource.channels = mychannel
LogAgent.sinks.mysink.channel = mychannel
# 配置名为“mysource”的Source,采用spooldir类型,从本地目录/tmp/logs获取数据
LogAgent.sources.mysource.type = spooldir
LogAgent.sources.mysource.spooldir = /tmp/logs
# 配置名为“mysink”的Sink,将结果写入HDFS中,每个文件10000行数据
LogAgent.sinks.mysink.type = hdfs
LogAgent.sinks.mysink.hdfs.path = hdfs://master:8020/data/logs/%Y/%m/%d/%H/
LogAgent.sinks.mysink.hdfs.batchSize = 1000
LogAgent.sinks.mysink.hdfs.rollSize = 0
LogAgent.sinks.mysink.hdfs.rollCount = 10000
LogAgent.sinks.mysink.hdfs.useLocalTimStamp = true
# 配置名为“mychannel”的Channel,采用memory类型
LogAgent.channels.mychannel.type = memory
LogAgent.channels.mychannel.capacity = 10000将配置文件logagent.property放到flume目录下,可以通过以下命令启动LogAgent:
bin/flume-ng agent -n LogAgent -c conf -f logagent.properties -Dflume.root.logger=DEBUG,console5.3 数据流拓扑实例剖析
1、多路合并拓扑实例
需求:设想在生产环境中,我们需要上线一批应用,这些应用会实时产生用户行为相关的流式日志。我们的一个任务是收集这些日志,并按照日志类别(比如搜索日志,点击日志等)写到不同的HDFS目录中。为了完成这个任务,构建了如下图的Flume拓扑:
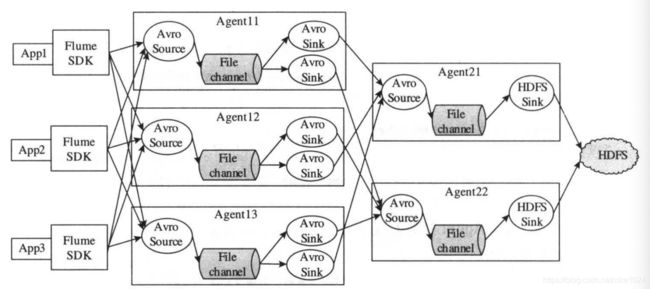
解释:在应用内部,我们采用Flume SDk将日志(采用Avro格式)发送到后端的各个Agent上,为了减少HDFS访问并发数和生成小文件数目,我们设计了两层Agent:第一层Agent采用Avro Source从应用程序端接收Event,并写入File Channel,之后由一组Avro Sink将数据发送给第二层Agent;第二层Agent接收到前一层Event数据后,通过HDFS Sink写入后端的HDFS。
(1)第一层配置(Agent11,Agent12/Agent13同理)
配置文件 agent11.properties:
# 定义Agent a11
a11.sources = r11
a11.channels = c11
a11.sinks = k11,k12
a11.sources.r11.channels = c11
a11.sinks.k11.channel = c11
a11.sinks.k12.channel = c11
# 为两个Sink s11、s12 构造一个Sink Group
a11.sinkgroups = g11
# 开启负载均衡功能
a11.sinkgroups.g11.processor.type = LOAD_BALANCE
# 采用轮训方式进行负载均衡
a11.sinkgroups.g11.processor.selector = ROUND_ROBIN
# 同时开启负载均衡和容错
a11.sinkgroups.g11.processor.backoff = true
# 配置source,类型为AVRO,并绑定本地的IP和端口号
a11.sources.r11.type = AVRO
a11.sources.r11.bind = 0.0.0.0
a11.sources.r11.port = 41414
# 配置channel,类型为FILE
a11.channels.c11.type = FILE
# 配置两个sink,类型为AVRO,并设置目标Agent 的 Avro Server 地址
a11.sinks.k11.type = AVRO
a11.sinks.k11.hostname = a21.example.org
a11.sinks.k11.port = 41414
a11.sinks.k12.type = AVRO
a11.sinks.k12.hostname = a22.example.org
a11.sinks.k12.port = 41414启动命令:
bin/flume-ng agent -n a11 -c conf -f agent11.properties(2)第二层 Agent 配置(Agent21,Agent22同理)
配置文件agent22.properties:
# 定义Agent a21
a21.sources = r21
a21.channels = c21
a21.sinks = k21
a21.sources.r21.channels = c21
a21.sinks.k21.channel = c21
# 配置source,类型为AVRO,并绑定本地的IP和端口号
a21.sources.r21.type = AVRO
a21.sources.r21.bind = 0.0.0.0
a21.sources.r21.port = 41414
# 配置channel,类型为FILE
a21.channels.c21.type = FILE
# 配置sink,类型为HDFS
a21.sinks.k21.type = hdfs
# 指定 HDFS 存放路径
a21.sinks.hdfsSink.hdfs.path = hdfs://bigdata/flume/appdata/%Y-%m-%d/%H%M
a21.sinks.hdfsSink.hdfs.filePrefix = log
a21.sinks.hdfsSink.hdfs.rollInterval = 600
a21.sinks.hdfsSink.hdfs.rollCount = 10000
a21.sinks.hdfsSink.hdfs.rollSize = 0
a21.sinks.hdfsSink.hdfs.round = true
a21.sinks.hdfsSink.hdfs.roundValue = 10
a21.sinks.hdfsSink.hdfs.roundUnit = minute
# fileType 可以是 SequenceFile,DataStream 或 CompressedStream,分别表示
# 二进制格式,未压缩原始数据格式,经压缩的原始数据格式
a21.sinks.k21.hdfs.fileType = DataStream启动命令:
bin/flume-ng agent -n a21 -c conf -f agent21.properties2、多路复用拓扑实例
需求:在上一个需求上扩展,直接躺应用程序通过TCP发送日志到对应的Agent,之后由Agent将所有数据写入HDFS,此外,Agent会按照Event头部的Severity属性值判断数据的重要性(共分为五种级别的数据:emergency,alert,critical,error和normal,分别用0~4表示),其中重要的数据会往HBase额外写入一份,具体拓扑如下图:

其中第一层和多路合并类似,这里重点介绍第二层,以Agent21为例:
# 定义Agent a21
a21.sources = r21
a21.channels = c21,c22
a21.sinks = k21,k22
a21.sources.r21.channels = c21 c22
a21.sinks.k21.channel = c21
a21.sinks.k22.channel = c22
# 配置source,类型为AVRO,并绑定本地的IP和端口号
a21.sources.r21.type = AVRO
a21.sources.r21.bind = 0.0.0.0
a21.sources.r21.port = 41414
# 配置channel,类型为FILE
a21.channels.c21.type = FILE
a21.channels.c22.type = FILE
# 为source添加Channel Selector,根据Event头部的Severity判断数据重要程度
a21.sources.r21.selector.type = MULTIPLEXING
a21.sources.r21.selector.header = Severity
a21.sources.r21.selector.default = c21
# 重要数据需同时写到HDFS和HBase中,显式指定重要度为0-3的数据同时写入c21和c22
a21.sources.r21.selector.mapping.0 = c21 c22
a21.sources.r21.selector.mapping.1 = c21 c22
a21.sources.r21.selector.mapping.2 = c21 c22
a21.sources.r21.selector.mapping.3 = c21 c22
# 为两个Sink s11、s12 构造一个Sink Group
a21.sinkgroups = g21
# 开启负载均衡功能
a21.sinkgroups.g21.processor.type = LOAD_BALANCE
# 采用轮训方式进行负载均衡
a21.sinkgroups.g21.processor.selector = ROUND_ROBIN
# 同时开启负载均衡和容错
a21.sinkgroups.g21.processor.backoff = true
# 配置hdfs Sink
a21.sinks.k21.type = hdfs
# 指定 HDFS 存放路径
a21.sinks.k21.hdfs.path = hdfs://bigdata/appdata/%Y-%m-%d/%H%M
# 每次生成的文件的前缀名
a21.sinks.k21.hdfs.filePrefix = FlumeData-%{host}-
# fileType 可以是 SequenceFile,DataStream 或 CompressedStream,分别表示
# 二进制格式,未压缩原始数据格式,经压缩的原始数据格式
a21.sinks.k21.hdfs.fileType = DataStream
# 每隔十分钟,生成一个新文件
a21.sinks.k21.hdfs.round = true
a21.sinks.k21.hdfs.roundValue = 10
a21.sinks.k21.hdfs.roundUnit = minute
# 配置HBase Sink
a21.sinks.k22.type = asynchbase
# 指定Hbase写入的表名和列簇名分别为appdata 和 log
a21.sinks.k22.table = app data
a21.sinks.k22.columnFamily = log---内容主要来自于《大数据技术体系详解:原理、架构与实践》