python初级实战系列教程《三、爬虫之应对网页反爬虫》
有些网站为了避免别人使用爬虫恶意爬取信息会进行一些反爬虫的操作
如:通过请求头里的User-Agent 检查访问来源是否为正常的访问途径
1、修改请求头来模拟正常的访问
使用chrome浏览器自带的开发者工具查看http头的方法
1.在网页任意地方右键选择检查打开chrome开发者工具;
2.选择network标签, 刷新网页
3.刷新后在左边找到该网页url,点击后右边选择headers,就可以看到当前网页的http头了;
如下图所示:
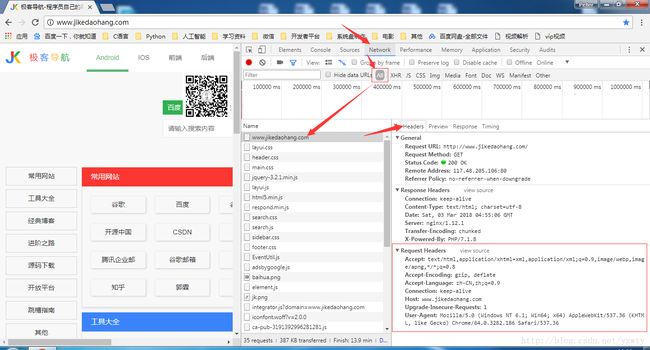
请求Header(HTTP request header )介绍:
Host:请求的域名
User-Agent :浏览器端浏览器型号和版本
Accept :可接受的内容类型
Accept-Language :语言
Accept-Encoding :可接受的压缩类型 gzip,deflate
Accept-Charset :可接受的内容编码 UTF-8,*
服务器端的响应Header(response header)
Date :服务器端时间
Server :服务器端的服务器软件 Apache/2.2.6
Etag :文件标识符
Content-Encoding:传送启用了GZIP压缩 gzip
Content-Length: 内容长度
Content-Type :内容类型
所以我们设置header如下:
headers = {
'User-Agent': ' Mozilla/5.0 (Windows NT 6.1; Win64; x64)'
' AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/64.0.3282.186 Safari/537.36',
'Connection': 'keep-alive'
}我们把上节的爬取网页小说的代码简单的修改如下:
#coding=utf-8
from bs4 import BeautifulSoup
import urllib.request
from urllib import error
import http.client
#解决http.client.IncompleteRead: IncompleteRead(0 bytes read错误"
http.client.HTTPConnection._http_vsn = 10
http.client.HTTPConnection._http_vsn_str = 'HTTP/1.0'
#小说地址
novel_url = "http://www.biqukan.com/2_2537/"
#小说内容前半部分地址
content_base_url = "http://www.biqukan.com"
#小说保存的路径
novel_dir = 'MyNovel/'
#https请求头
headers = {
'User-Agent': ' Mozilla/5.0 (Windows NT 6.1; Win64; x64)'
' AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/64.0.3282.186 Safari/537.36',
'Connection': 'keep-alive'
}
#获取所有章节的url和title
def get_url_title():
try:
chapter_request = urllib.request.Request(novel_url, headers=headers)
chapter_response = urllib.request.urlopen(chapter_request)
chapter_content = chapter_response.read()
#使用BeautifulSoup
chapter_beautiful_soup = BeautifulSoup(chapter_content, 'html.parser')
all_chapter = chapter_beautiful_soup.find_all(attrs={"class": "listmain"})
list_a = []
for i in all_chapter:
for j in i.find_all('a'):
list_a.append(j)
#去掉不需要的...
url_title_list = list_a[12:]
return url_title_list
except error.URLError as reason:
print(str(reason))
#下载小说
def down_navel_content(url_title):
#拼接每章的url
contents_url = content_base_url+url_title.attrs.get('href')
#每获取章节名字
content_title = url_title.string
try:
chapter_request = urllib.request.Request(contents_url, headers=headers)
chapter_response = urllib.request.urlopen(chapter_request)
chapter_content = chapter_response.read()
#使用BeautifulSoup
chapter_beautiful_soup = BeautifulSoup(chapter_content, 'html.parser')
#获取小说内容
contents = chapter_beautiful_soup.find_all(attrs={"class": "showtxt"})
for txt in contents:
save_navel(txt, novel_dir+content_title+'.txt')
except error.URLError as reason:
print(str(reason))
#保存小说
def save_navel(content, path):
try:
#设置编码方式为utf-8
with open(path, 'w+', encoding='utf-8')as f:
#get_text(strip=True)是去掉空格和换行
f.write(content.get_text(strip=True))
except error.URLError as reason:
print(str(reason))
else:
print('下载完'+path)
if __name__ == '__main__':
novel_chapter = get_url_title()
for chapter in novel_chapter:
down_navel_content(chapter)
print('全部下载完成')2、使用代理IP
一般服务器会对请求的IP进行记录,如果单位时间里访问的次数达到一个阀值, 会认为该IP地址是爬虫,会弹出验证码验证或者直接对IP进行封禁。
这时候我们就可以用代理IP来处理这种情况,通过不断更改代理ip去访问目标网址。
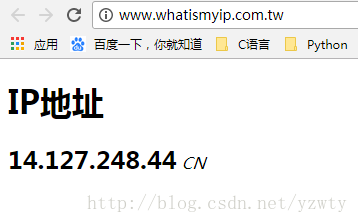
1)首先我们先通过网址http://www.whatismyip.com.tw/来查看我们当前的IP
2)简单写一个使用代理IP例子:
import urllib.request
from urllib import error
#查询当前访问所使用IP的网址
query_ip_url = "http://www.whatismyip.com.tw/"
# 创建代理处理器,ProxyHandler参数是一个字典{类型:代理ip:端口}
ip_proxy = urllib.request.ProxyHandler({'http': '120.79.202.189:6666'})
# 创建opener
opener = urllib.request.build_opener(ip_proxy)
#install opener
urllib.request.install_opener(opener)
#https请求头
headers = {
'User-Agent': ' Mozilla/5.0 (Windows NT 6.1; Win64; x64)'
' AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/64.0.3282.186 Safari/537.36',
'Connection': 'keep-alive'
}
try:
query_request = urllib.request.Request(query_ip_url, headers=headers)
query_response = urllib.request.urlopen(query_request)
print(query_response.read().decode("utf-8"))
except error.URLError as e:
print(str(e))打印可以看到IP地址已经变为我们所使用的代理IP:
<h1>IP位址h1> <span data-ip='120.79.202.189'><b style='font-size: 1.5em;'>120.79.202.189b>span> <span data-ip-country='CN'><i>CNi>span>
<script type="application/json" id="ip-json">
{
"ip": "120.79.202.189",
"ip-country": "CN",
"ip-real": "",
"ip-real-country": ""
}
script>
纸上得来终觉浅,绝知此事要躬行
我,秦始皇,打赏…

