爬虫实战系列(五):轻松获取B站弹幕
声明:本博客只是简单的爬虫示范,并不涉及任何商业用途。
一.前言
昨天我打开B站的视频搜索页面突然发现川普同志再次喜提热搜——特朗普签署行政令,当然这个新闻对我们中国来说并不是啥好事情。于是我便想通过弹幕爬取来了解广大网友对这件事的看法,下面是对小破站弹幕爬取过程的记录。
二.爬虫详细过程
2.1 视频链接提取
首先我在搜索页面输入关键词“特朗普签署行政令”,结果显示跟该关键词相关的视频总共有3页共58个视频,这里截取搜索首页展示如下:
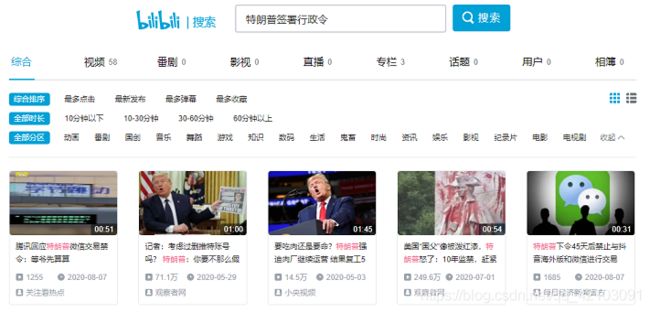
要想爬取这58个视频的弹幕,首先我要获取到这几页视频的链接,而获取方法其实很简单,我们选中一个视频->右键->检查可查看对应视频的源代码如下:
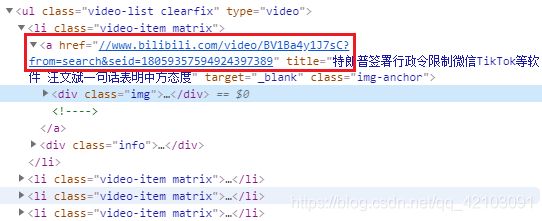
由上图可以发现,所有视频都在列表标项findAll()对这些视频的链接进行提取。另外,视频页数总共包含3页,点击下面页码按钮并对比所得的链接如下:
https://search.bilibili.com/all?keyword=%E7%89%B9%E6%9C%97%E6%99%AE%E7%AD%BE%E7%BD%B2%E8%A1%8C%E6%94%BF%E4%BB%A4
https://search.bilibili.com/all?keyword=%E7%89%B9%E6%9C%97%E6%99%AE%E7%AD%BE%E7%BD%B2%E8%A1%8C%E6%94%BF%E4%BB%A4&page=2
https://search.bilibili.com/all?keyword=%E7%89%B9%E6%9C%97%E6%99%AE%E7%AD%BE%E7%BD%B2%E8%A1%8C%E6%94%BF%E4%BB%A4&page=3
可知当翻页时改变的只是查询字符串中page的值。由此可得获取视频链接的流程如下:
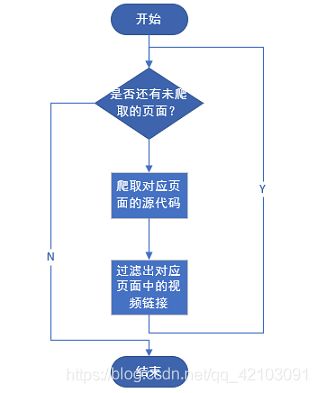
2.2 对应视频弹幕提取
当我选中一个视频进入对应页面后,先查看源码结果并没有弹幕数据,因此可以断定弹幕并不是通过静态的方式加载的,但我也没有在开发者工具中发现包含动态弹幕数据的文件,于是我便上网搜索,结果发现其实官方提供了弹幕数据的API接口:
http://comment.bilibili.com/{cid}.xml
要想获取某个视频的弹幕,只需要将该视频的cid代入上述链接即可,例如视频cid为221435566的弹幕数据链接如下:
http://comment.bilibili.com/221435566.xml
对应弹幕数据的xml文件展示如下:

因此现在问题便转化为了如何提取对应视频页面源码中的cid,首先点击查看视频源码,然后选中ctrl+F搜索cid,结果中可以找到包含cid的部分:
![]()
因此,我们可以使用正则表达式过滤出对应的cid的值,对应的正则表达式如下:
cid=(\d+)&aid
在过滤出cid后,便可利用上述的弹幕数据接口获取到包含弹幕的xml文件,然后利用BeautifulSoup即可获取到所有的弹幕。综上所示,视频弹幕的获取流程如下:
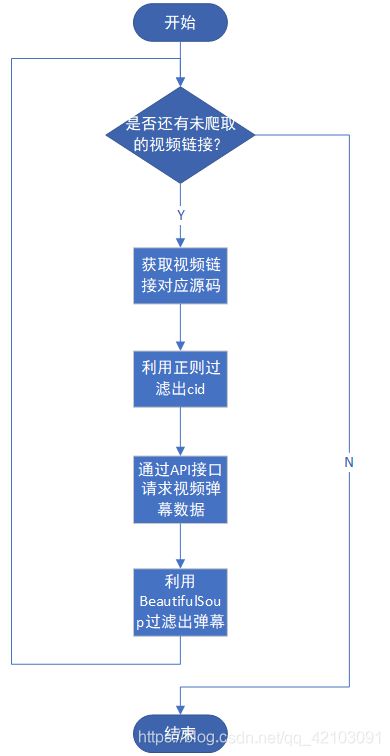
2.3 保存为csv文件
在获取到弹幕数据后,我将弹幕数据保存为列表,其中每个元素格式为[cid, 弹幕内容]。然后,利用pandas模块先将list对象转化为DataFrame对象,最后利用函数to_csv()即可实现弹幕数据保存到csv文件。
三.程序及结果展示
import requests
from bs4 import BeautifulSoup
import re
import traceback
import pandas as pd
headers = {
"User-Agent": "换上自己的User-Agent",
"cookie": "换上自己的cookie"
}
def GainVideoLink(pagenums = 3):
"""
功能:获取某页的视频链接
pagenums:视频总页数
返回值:一个链接列表
"""
i,vlink = 1,[]
while i <= pagenums:
try:
url = "https://search.bilibili.com/all?keyword=%E7%89%B9%E6%9C%97%E6%99%AE%E7%AD%BE%E7%BD%B2%E8%A1%8C%E6%94%BF%E4%BB%A4&page={}".format(i)
response = requests.get(url,headers=headers)
#print(response.text)
if response.status_code == 200:
i += 1
soup = BeautifulSoup(response.content,'lxml')
videos = soup.findAll('li',attrs={"class":"video-item matrix"})
for video in videos:
href = video.find('a').get('href')#获取视频的链接
print("http:" + href)
vlink.append("http:" + href)
except Exception:
print("第{}页视频链接爬取失败".format(i))
traceback.print_exc()
return vlink
def GainCid(url):
"""
功能:获取视频的cid
url:视频的链接
proxies:代理IP
返回值:视频的cid
"""
cid = 0
try:
response = requests.get(url,headers=headers)
if response.status_code == 200:
match_obj = re.search('cid=(\d+)&aid',response.text)
#print(response.text)
cid = match_obj.group(1)
return cid
except Exception:
print("cid获取失败,url:{}".format(url))
traceback.print_exc()
def GainComment(cid):
"""
功能:获取对应cid的视频的弹幕
cid:视频的cid
返回值:弹幕列表
"""
clist = [] #弹幕列表
try:
url = "http://comment.bilibili.com/{}.xml".format(cid)
response = requests.get(url,headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.content,"lxml",from_encoding="UTF-8")
comments = soup.findAll('d')
for c in comments:
comment = c.get_text()
clist.append([cid,comment])
return clist
except Exception:
print("弹幕爬取失败,cid:{}".format(cid))
traceback.print_exc()
def Saver(clist):
"""
功能:将视频数据保存为csv文件
clist:弹幕列表
"""
datas = pd.DataFrame(clist,columns=['视频cid','弹幕内容'])
datas.to_csv('bilibili_comments.csv',index = False)
def Spider():
"""
功能:爬虫主程序
IPs:代理IP列表
"""
comments = []
vlink = GainVideoLink()
for i,url in enumerate(vlink):
print("Crawing Video {},url:{}".format(i + 1,url))
cid = GainCid(url)
clist = GainComment(cid)
if clist != []:
comments += clist
Saver(comments)
if __name__ == "__main__":
Spider()
爬虫过程部分截图展示如下:
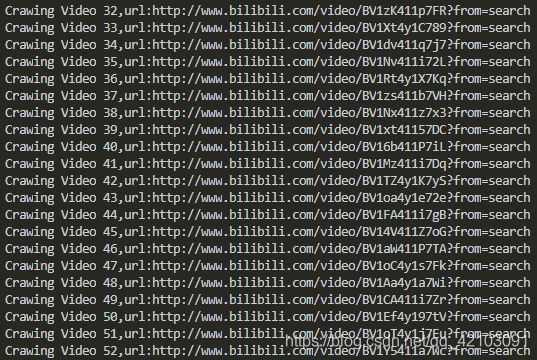
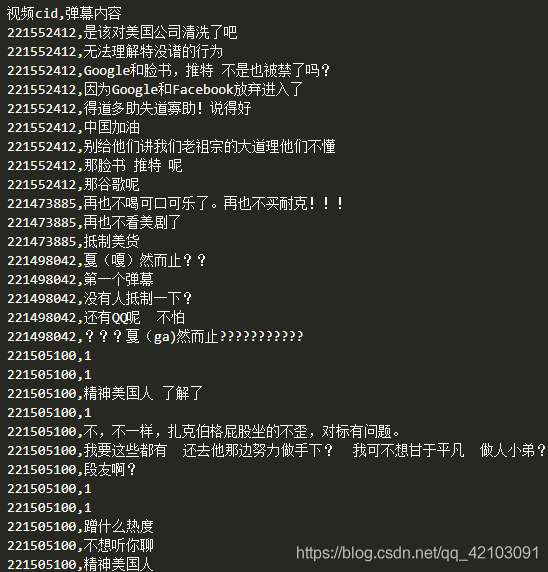
最后一共获取到4800多条弹幕数据,部分弹幕内容展示如下:
以上便是本文的全部内容,觉得不错的话点个赞支持一下吧!!!