腾讯视频弹幕爬取----------之亲爱的,热爱的
因为很喜欢杨紫演的亲爱的热爱的,想看看上头姐妹都是怎么花式夸杨紫的,所以,爬取腾讯视频的弹幕分析看看!
1.爬取单集弹幕
首先打开腾讯视频F12查询网站代码,从下面的图片中可以看出,有一个JSdanmu的请求在这个请求里面,包含我们准备要爬取的弹幕评论内容。
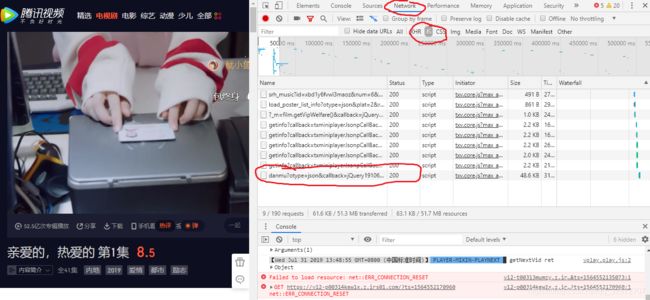
打开这个JS请求:
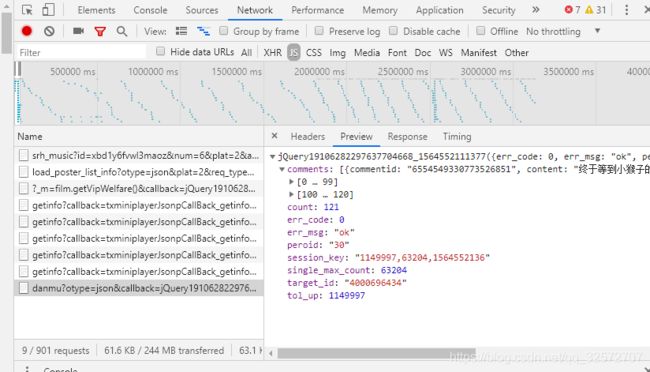
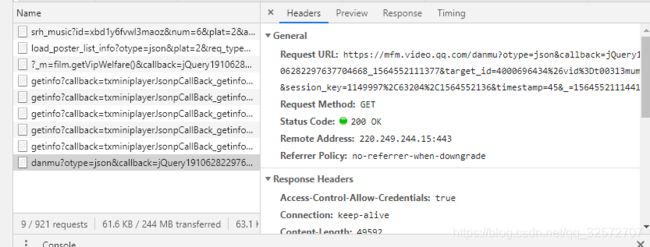
左图中comments就是弹幕评论,右图为该弹幕请求的URL。
url = 'https://mfm.video.qq.com/danmu?otype=json&callback=jQuery19106282297637704668_1564552111377&target_id=4000696434%26vid%3Dt00313mumzy&session_key=1149997%2C63204%2C1564552136×tamp=15&_=1564552111441'这个网址很长,其中很多去掉对网址访问结果没有影响,所以经过简化得到如下的:
url = 'https://mfm.video.qq.com/danmu?otype=json&target_id=4000696434%26vid%3Dt00313mumzy×tamp=15'通过对比第一张图中出现的第二个danmu请求的URl可以看出url只有时间戳timetamp变化了,每次变化为30秒:
url2 = 'https://mfm.video.qq.com/danmu?otype=json&target_id=4000696434%26vid%3Dt00313mumzy×tamp=45'以此类推可以得到一集电视弹幕URL变化的规律,从而获取一集的全部弹幕。
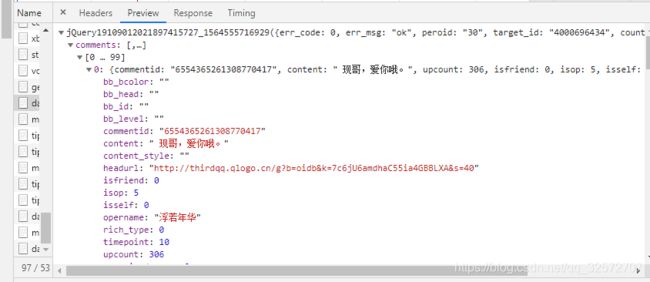
上图是一条弹幕请求中包含的信息。我们需要的信息是 opername 用户名 、 commentid 评论id、content 内容 、 timepoint 评论时间、 uservip_degree 会员等集、upcount 评论点赞量。这几个要素。
import requests
import json
import time
import pandas as pd
#一个JS请求的内容
def parse_base_info(url,headers,df):
html = requests.get(url,headers=headers)
html.text[:500]
bs = json.loads(html.text,strict = False)
for i in bs['comments']:
content = i['content']
upcount = i['upcount']
name = i['opername']
user_degree = i['uservip_degree']
timepoint = i['timepoint']
comment_id = i['commentid']
cache = pd.DataFrame({'用户名':[name],'内容':[content],'会员等级':[user_degree],'评论时间点':[timepoint],'评论点赞':[upcount],'评论id':[comment_id]})
df = pd.concat([df, cache])
#print(df.info())
#df.to_csv('one.csv')
return df
#一集弹幕内容
def one_Series(url1,headers,dff):
df2 = pd.DataFrame()
#file = codecs.open(filename='book.json', mode='w+', encoding='utf-8')
for i in range(90):#88
url = url1.format(15+i*30)
#print(url)
df1 = parse_base_info(url,headers,dff)
print('第'+str(15+i*30) +'秒')
df2 = pd.concat([df2, df1])
print('end')
#df2.to_csv('one.csv')
return df2
if __name__ == "__main__":
# 基础网址
url = 'https://mfm.video.qq.com/danmu?otype=json&target_id=4033196415%26vid%3Ds0031deflzd×tamp={}'
# 伪装header
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36'}
df = pd.DataFrame()
#file = codecs.open(filename='book.json', mode='w+', encoding='utf-8')
df3 = one_Series(url, headers, df)
df3.to_csv('b2.csv', encoding='utf_8_sig')#存入本地
print(df3.info())
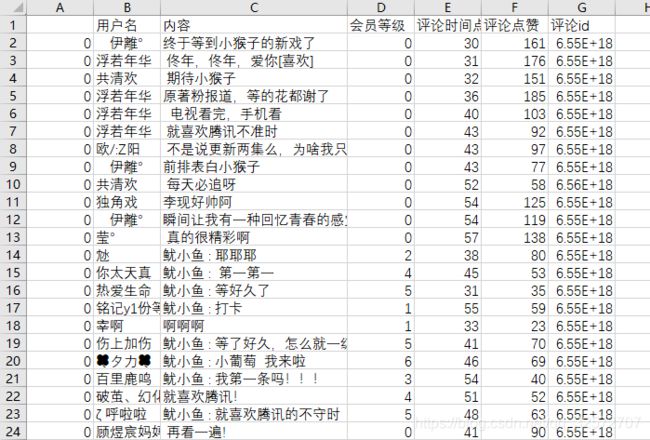
下载到本地的CSV文件:
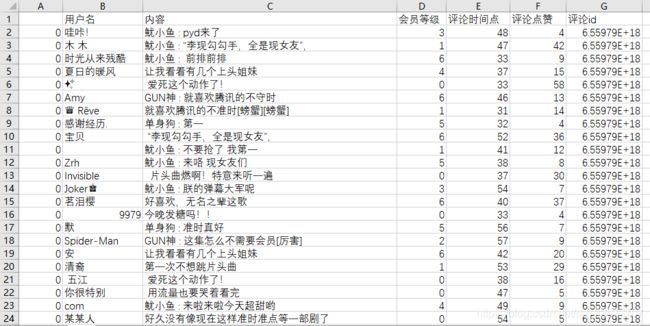
获得的评论动态数据看起来还是很不错的。
2.爬取多集弹幕
单集剧集的弹幕我们已经成功爬到了,下面看看多集怎么爬。
爬取多集弹幕,首先要得到不同剧集之间的URL网址的变化规律。
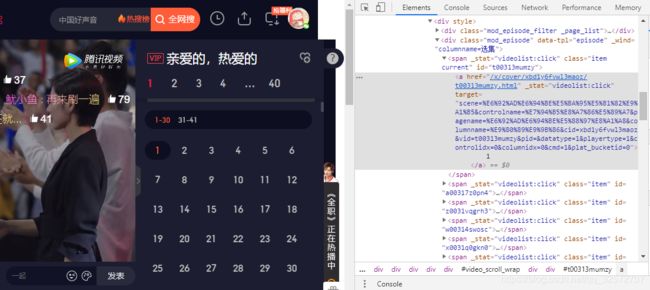
打开选集的面板,鼠标右键点击第一集的按钮,选择检查,就会自动定位到这个按键的代码上。看右面的代码,就是换集的时候链接请求的变化情况。
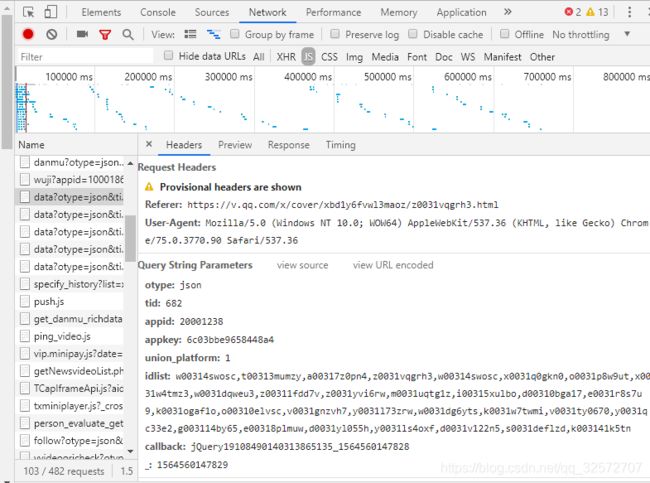
对比不同剧集之间链接的差别主要在 “id”那里。但弹幕的请求URL和视频页面的请求URL不同,我们再对比弹幕的URL看看有什么规律。
PS:简化是把对请求没有影响的删掉了,怎么可以确定没有影响呢,将连接在浏览器中打开,如果还是能获得这样的JSON页面,且获得的弹幕评论没有改变,那么就是没有影响。
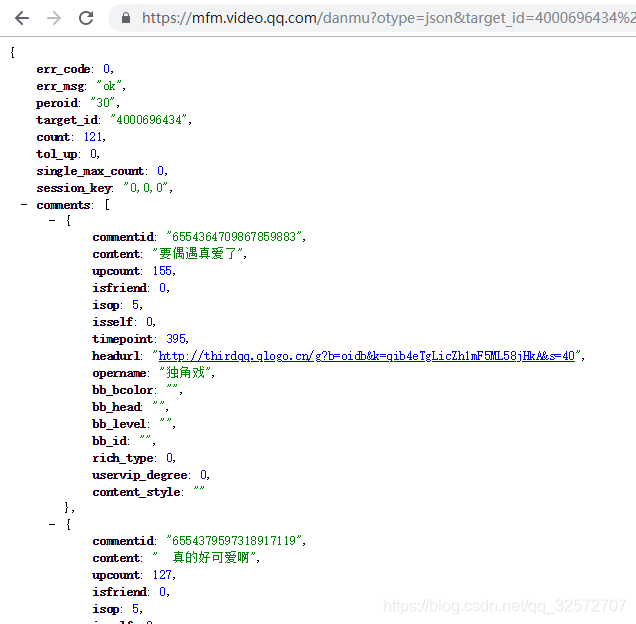
下面就是1、2、3三集的弹幕请求URL,当然,看长度就知道是经过简化的了。可以看出来,target_id是不同剧集之间URL请求变化的原因。
https://mfm.video.qq.com/danmu?otype=json&target_id=4000696434%26vid%3Dt00313mumzy×tamp=105
https://mfm.video.qq.com/danmu?otype=json&target_id=4002742132%26vid%3Da00317z0pn4×tamp=105
https://mfm.video.qq.com/danmu?otype=json&target_id=4002742130%26vid%3Dz0031vqgrh3×tamp=105在JS请求中这一条是一个id池,包含30集的id地址,从右图打开的可以看到剧集信息。上面URL的中%3D后面的后缀id就是下面idlist中的id。
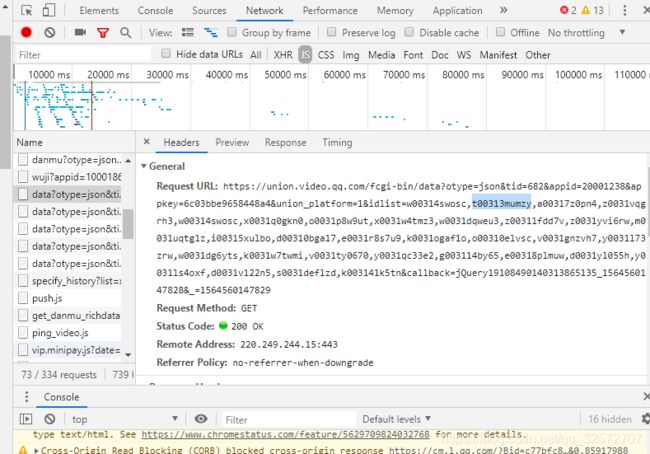
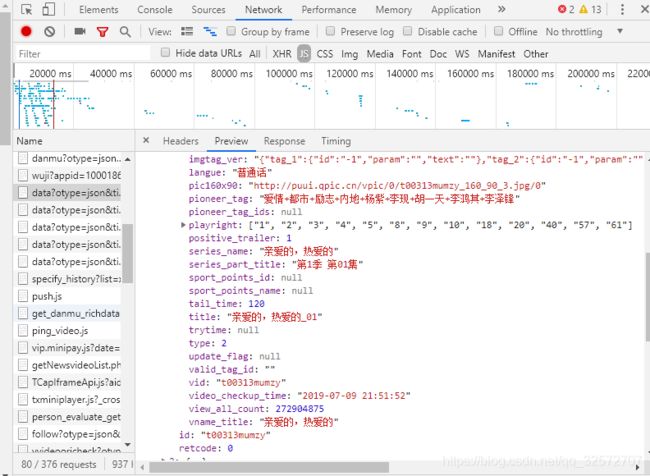
看下面idlist就是
其中一个URL中有30集这里共有四个URL请求,而这部剧目前播放到40集,所以,其他的都是片花、预告,在存取后缀id的时候,只取正片的,那就取两个URL请求就可以,从中挑正片留下就可以。
def multy_Series():
#打开任意一集,1 - 30和31 - 40存储在两个网页
part1_url = 'https://union.video.qq.com/fcgi-bin/data?otype=json&tid=682&appid=20001238&appkey=6c03bbe9658448a4&union_platform=1&idlist=w00314swosc,t00313mumzy,a00317z0pn4,z0031vqgrh3,w00314swosc,x0031q0gkn0,o0031p8w9ut,x0031w4tmz3,w0031dqweu3,z00311fdd7v,z0031yvi6rw,m0031uqtg1z,i00315xulbo,d00310bga17,e0031r8s7u9,k0031ogaf1o,o00310elvsc,v0031gnzvh7,y0031l73zrw,w0031dg6yts,k0031w7twmi,v0031ty0670,y0031qc33e2,g003114by65,e00318plmuw,d0031yl055h,y0031ls4oxf,d0031v122n5,s0031deflzd,k003141k5tn&callback=jQuery19108490140313865135_1564560147828&_=1564560147829'
part2_url = 'https://union.video.qq.com/fcgi-bin/data?otype=json&tid=682&appid=20001238&appkey=6c03bbe9658448a4&union_platform=1&idlist=n0031zcnfar,b0031x9yun6,y0031sxf84y,q0031cvniyp,v0031v7ybc8,c00315gyvxf,j0031102kef,h0031vuiv9h,o0031248liy,z0031o9k8ee,x0031mgwa14,a003128kcpi,i0031lmqvhz,v0031fu8t14,c0031cp1t55,o0031fyrrjf,d0031wvajb7,l0031p8rw12,i00319gq1v3,i0031cjqd5o,m0031dy6y14,g0031scuuh4,u0031fvmljd,y0031k0hge7,l0031fusb5c,f0031rhftw9,x0031cuajxj,n09064dwxf3,d0031imjgta,j0031lojk91&callback=jQuery19108490140313865135_1564560147830&_=1564560147831'
mu_df = pd.DataFrame()
for url in [part1_url, part2_url]:
html = requests.get(url, headers=headers)
bs = json.loads(html.text[html.text.find('{'):-1])
print(bs)
for i in bs['results']:
# 后缀ID
v_id = i['id']
# 这一集的名字,比如“亲爱的,热爱的_01”
title = i['fields']['title']
# 播放量
view_count = i['fields']['view_all_count']
# 整型存储的集数,片花则为0
episode = int(i['fields']['episode'])
# 去掉片花,只留下正片和预告
if episode == 0:
pass
else:
cache = pd.DataFrame({'id': [v_id], 'title': [title], '播放量': [view_count], '第几集': [episode]})
mu_df = pd.concat([mu_df, cache])
print(mu_df.head())下面是输出的部分结果:

这只是获取targe_id的后半个,前半个还需要继续从其他请求中获得。在XHR中有一个URL请求是通过后缀 id 获取前缀id的:
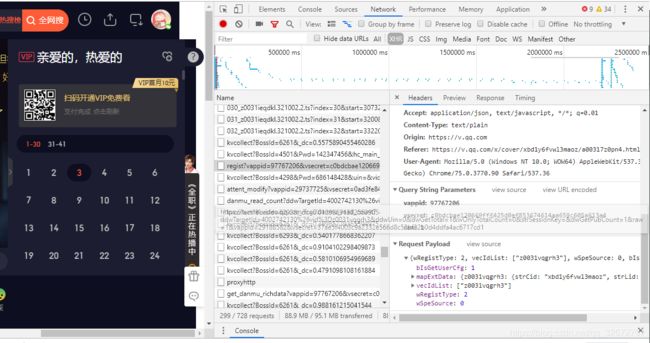

从上图可以看出来这是第三集,他的后缀id 为 (z0031vqgrh3)通过这个后缀id 向服务器发送请求,获取完整的target_id。
base_url = 'https://access.video.qq.com/danmu_manage/regist?vappid=97767206&vsecret=c0bdcbae120669fff425d0ef853674614aa659c605a613a4&raw=1'因为这是一个请求URL所以,获取结果与传入参数有关,我们这里的传入参数就是已经获取到的 mu_df 里面保存的后缀id。
def get_episode_danmu(v_id, headers):
# target_id所在基础网址
base_url = 'https://access.video.qq.com/danmu_manage/regist?vappid=97767206&vsecret=c0bdcbae120669fff425d0ef853674614aa659c605a613a4&raw=1'
# 传递参数,只需要改变后缀ID
pay = {"wRegistType": 2, "vecIdList": [v_id],
"wSpeSource": 0, "bIsGetUserCfg": 1,
"mapExtData": {v_id: {"strCid": "wu1e7mrffzvibjy", "strLid": ""}}}
html = requests.post(base_url, data=json.dumps(pay), headers=headers)
bs = json.loads(html.text)
# 定位元素
danmu_key = bs['data']['stMap'][v_id]['strDanMuKey']
# 解析出target_id
target_id = danmu_key[danmu_key.find('targetid') + 9: danmu_key.find('vid') - 1]
return [v_id, target_id]
if __name__ == "__main__":
# 基础网址
#url = 'https://mfm.video.qq.com/danmu?otype=json&target_id=4033196415%26vid%3Ds0031deflzd×tamp={}'
# 伪装header
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36'}
mu_df = multy_Series()
info_list= []
for i in mu_df['id']:
info = get_episode_danmu(i,headers)
print(info)
info_list.append(info)
time.sleep(3 + random.random())这里使用了前面获取后缀id的程序,没有写上来,在测试的时候可以自行加上。
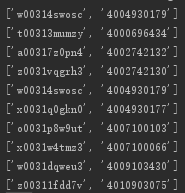
上图是获得的结果,下面只要按照 target_id 的结构放进去,就可以进行爬虫了,但第一条是重复的,需要去重。但我觉得不去重也可以,因为第一个0位的剧集应该是记录当前浏览到的剧集的id,放在这里相当于占位,因为我后面设置的输入是剧集从1开始算,所以0位的剧集id不会有提取的机会。
3.完整代码
为了保证程序的可读性,加了一些函数帮助处理。还有很多可以完善的地方,但今天就先到这里了。如果有人观看,并觉得有用的话,欢迎点赞,给我点支持和鼓励,谢谢!
下面附上完整代码。
import requests
import json
import time
import pandas as pd
import random
def parse_base_info(url,headers,df):
html = requests.get(url,headers=headers)
html.text[:500]
bs = json.loads(html.text,strict = False)
for i in bs['comments']:
content = i['content']
upcount = i['upcount']
name = i['opername']
user_degree = i['uservip_degree']
timepoint = i['timepoint']
comment_id = i['commentid']
cache = pd.DataFrame({'用户名':[name],'内容':[content],'会员等级':[user_degree],'评论时间点':[timepoint],'评论点赞':[upcount],'评论id':[comment_id]})
df = pd.concat([df, cache])
#print(df.info())
#df.to_csv('one.csv')
return df
def one_Series(url1,headers,dff,pagestar,pageend):
df2 = pd.DataFrame()
#file = codecs.open(filename='book.json', mode='w+', encoding='utf-8')
for i in range(pagestar,pageend+1):#88
url = url1.format(15+i*30)
#print(url)
df1 = parse_base_info(url,headers,dff)
#print('第'+str(15+i*30) +'秒')
df2 = pd.concat([df2, df1])
print('爬完%d页'%i)
#df2.to_csv('one.csv')
return df2
def multy_Series():
#打开任意一集,1 - 30和31 - 46存储在两个网页
part1_url = 'https://union.video.qq.com/fcgi-bin/data?otype=json&tid=682&appid=20001238&appkey=6c03bbe9658448a4&union_platform=1&idlist=w00314swosc,t00313mumzy,a00317z0pn4,z0031vqgrh3,w00314swosc,x0031q0gkn0,o0031p8w9ut,x0031w4tmz3,w0031dqweu3,z00311fdd7v,z0031yvi6rw,m0031uqtg1z,i00315xulbo,d00310bga17,e0031r8s7u9,k0031ogaf1o,o00310elvsc,v0031gnzvh7,y0031l73zrw,w0031dg6yts,k0031w7twmi,v0031ty0670,y0031qc33e2,g003114by65,e00318plmuw,d0031yl055h,y0031ls4oxf,d0031v122n5,s0031deflzd,k003141k5tn&callback=jQuery19108490140313865135_1564560147828&_=1564560147829'
part2_url = 'https://union.video.qq.com/fcgi-bin/data?otype=json&tid=682&appid=20001238&appkey=6c03bbe9658448a4&union_platform=1&idlist=n0031zcnfar,b0031x9yun6,y0031sxf84y,q0031cvniyp,v0031v7ybc8,c00315gyvxf,j0031102kef,h0031vuiv9h,o0031248liy,z0031o9k8ee,x0031mgwa14,a003128kcpi,i0031lmqvhz,v0031fu8t14,c0031cp1t55,o0031fyrrjf,d0031wvajb7,l0031p8rw12,i00319gq1v3,i0031cjqd5o,m0031dy6y14,g0031scuuh4,u0031fvmljd,y0031k0hge7,l0031fusb5c,f0031rhftw9,x0031cuajxj,n09064dwxf3,d0031imjgta,j0031lojk91&callback=jQuery19108490140313865135_1564560147830&_=1564560147831'
mu_df = pd.DataFrame()
for url in [part1_url, part2_url]:
html = requests.get(url, headers=headers)
bs = json.loads(html.text[html.text.find('{'):-1])
#print(bs)
for i in bs['results']:
# 后缀ID
v_id = i['id']
# 这一集的名字,比如“亲爱的,热爱的_01”
title = i['fields']['title']
# 播放量
view_count = i['fields']['view_all_count']
# 整型存储的集数,片花则为0
episode = int(i['fields']['episode'])
# 去掉片花,只留下正片和预告
if episode == 0:
pass
else:
cache = pd.DataFrame({'id': [v_id], 'title': [title], '播放量': [view_count], '第几集': [episode]})
mu_df = pd.concat([mu_df, cache])
return mu_df
#print(mu_df.head())
# 定义爬取单集target_id的函数
# 只需要向函数传入v_id(后缀ID)和headers
def get_episode_danmu(v_id, headers):
# target_id所在基础网址
base_url = 'https://access.video.qq.com/danmu_manage/regist?vappid=97767206&vsecret=c0bdcbae120669fff425d0ef853674614aa659c605a613a4&raw=1'
# 传递参数,只需要改变后缀ID
pay = {"wRegistType": 2, "vecIdList": [v_id],
"wSpeSource": 0, "bIsGetUserCfg": 1,
"mapExtData": {v_id: {"strCid": "wu1e7mrffzvibjy", "strLid": ""}}}
html = requests.post(base_url, data=json.dumps(pay), headers=headers)
bs = json.loads(html.text)
# 定位元素
danmu_key = bs['data']['stMap'][v_id]['strDanMuKey']
# 解析出target_id
target_id = danmu_key[danmu_key.find('targetid') + 9: danmu_key.find('vid') - 1]
return [v_id, target_id]
def get_all_id(headers):
last_id = multy_Series()
info_list = []
print('获取id')
for i in last_id['id']:
info = get_episode_danmu(i, headers)
info_list.append(info)
#1
# print('获取%d集id' % len(info_list))
time.sleep(1 + random.random())
print('id获取结束')
return info_list
def get_comments(series_num,pagestar,pageend,url,headers):
info_list_m = get_all_id(headers)
url_m = url.format(info_list_m[series_num][1],info_list_m[series_num][0],{})
df = pd.DataFrame()
print('第%d集,第%d页到第%d页'%(series_num,pagestar,pageend))
df_m = one_Series(url_m,headers,df,pagestar,pageend)
df_m.to_csv('df_m.csv', encoding='utf_8_sig')
print('end')
if __name__ == "__main__":
print('想要爬取的剧集:')
seri_num = input()
print('想要爬取的页首:')
page1 = input()
print('想要爬取的页尾:')
page2 = input()
# 基础网址
url = 'https://mfm.video.qq.com/danmu?otype=json&target_id={}%26vid%3D{}×tamp={}'
# 伪装header
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36'}
get_comments(int(seri_num),int(page1),int(page2), url, headers)运行结果如下: