PASSRnet论文阅读:Learning Parallax Attention for Stereo Image Super-Resolution
Learning Parallax Attention for Stereo Image Super-Resolution
原论文作者 Longguang Wang,Yingqian Wang,Zhengfa Liang, Zaiping Lin,Jungang Yang,Wei An,Yulan Guo
原论文链接
原代码链接
参考文章
PPT:










部分翻译如下:
摘要
立体图像对可以用来提高超分辨率(SR)的性能,因为额外的信息提供了第二种观点。然而,由于立体图像之间的差异非常大,因此将这些信息纳入SR非常具有挑战性。在本文中,我们提出了一个基于视差注意力机制的立体超分辨率网络(PASSRnet)来集成来自立体图像对的信息。特别地,我们引入了一种沿极线具有全局感受野的视差注意机制来处理具有较大视差变化的不同立体图像。我们还提出了一个新的、最大的立体图像SR数据集(即Flickr1024)。大量实验表明,该视差注意机制能够以较小的计算和内存开销捕获立体图像之间的对应关系,从而提高SR性能。对比结果表明,PASSRnet在Middlebury、KITTI 2012和KITTI 2015数据集上实现了最先进的性能。
1 介绍
超分辨率(SR)旨在从低分辨率(LR)图像中重建高分辨率(HR)图像。从单个镜头中恢复HR图像是一个长期存在的问题[1,2,3]。最近,双摄像头在手机和自动驾驶汽车上越来越受欢迎。已有研究表明,LR立体图像中包含的亚像素位移可以用来提高SR[4]的性能。然而,由于不同的基线、焦距、深度和分辨率,立体图像之间的差异可能会有很大的不同,因此将立体对应关系纳入SR是非常具有挑战性的。
传统的多图像SR方法[7,8]使用图像间的patch递归来获得对应关系。然而,这些方法不能充分利用亚像素对应,计算量大。最近基于cnn的框架[9,10,11]将光流估计和SR结合到统一网络中,解决了视频SR问题。然而,这些方法不能直接应用于立体图像SR,因为视差比它们的感受野要大得多。
为了获得立体图像对之间的对应关系[12,13,14],对立体匹配进行了研究。最近基于cnn的方法[15,16,17,18]在其网络中使用3D或4D代价卷来建模立体图像对之间的长期依赖关系。直观地,这些基于cnn的立体匹配方法可以与SR集成,提供准确的对应关系。然而,基于4d成本体积方法(15、16)遭受高的计算和记忆负担,这对于立体图像SR是无法忍受的。虽然基于成本效率的3 d体积(17、18)是改善方法,这些方法不能处理视差变化较大的立体图像,因为使用一个固定的最大视差构建一个成本卷。
最近,Jeon等人提出了一种stereo SR network (StereoSR)[6],利用图像栈为SR提供对应线索。具体地说,图像堆栈是通过将左图像与以不同间隔移动右图像生成的图像连接起来得到的。然后得到视差位移与HR图像之间的直接映射。然而,这种方法对于不同的传感器和场景的灵活性是有限的,因为在这个算法中允许的最大视差是固定的。
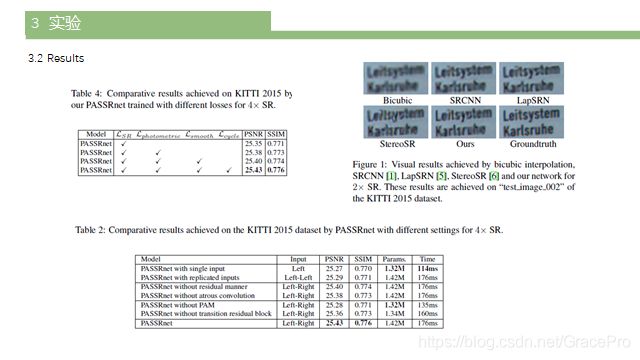
在本文中,我们提出了一种视差注意力机制的立体图像超分辨率网络(PASSRnet),它包含了用于SR任务的立体匹配。在给定立体图像对的情况下,首先利用残差空洞金字塔池化(ASPP)模块生成多尺度特征。然后,将这些特征输入视差注意力模块(PAM),以捕获立体匹配。对于左侧图像中的每个像素,计算其特征与右侧图像中所有可能的差异的相似性,从而生成注意图。因此,PAM可以在保持高灵活性的同时捕获全局通信。然后,执行注意力驱动的特征聚合来更新左侧图像的特征。最后,使用这些特征生成SR结果。消融研究在KITTI 2015数据集上进行,以测试PASSRnet。通过对Middlebury、KITTI 2012和KITTI 2015数据集的对比实验,进一步验证了该网络的优越性能(如图1所示)。
论文的主要贡献可以总结如下:1)我们提出了一个包含立体匹配的SR密码;2)针对不同的视差变化较大的立体图像,提出了一种沿极线具有全局感受野的通用视差注意机制。结果表明,采用视差注意机制可以有效地生成可靠的对应关系,提高SR性能;3)提出了一种新的立体图像SR网络训练数据集Flickr1024。Flickr1024数据集由1024对高质量立体图像对组成,覆盖多种场景;4)PASSRnet实现了最新的单图像SR和立体图像SR方法的最先进的性能。
2. Related Work
在本节中,我们简要回顾了SR和长期依赖学习的几个主要工作。
2.1. Superresolution
自超分辨率卷积神经网络(SRCNN)[1]的开创性工作以来,基于学习的方法一直主导着单图像SR. Kim等人的研究。[19]提出了一个包含20个卷积层的超分辨率超深网络(VDSR)。Tai等人开发了一种深度递归剩余网络(DRRN)来控制模型参数。最近,Zhang等人提出了一种残差密集网络(RDN),通过一种连续存储机制来促进有效的特征学习。
Video SR Liao等人[22]为Video SR引入了第一个CNN,他们对SR-drafts进行运动补偿生成一个集合,然后使用CNN从集合中重构HR帧。Caballero等人提出了一种端到端视频SR框架,将运动补偿模块与SR模块相结合。Tao等人将[10]与LSTM集成成一个编解码器网络,充分利用时间通信。该体系结构进一步促进了时间上下文的提取。由于相邻帧之间的对应主要存在于局部区域内,因此视频SR方法侧重于利用局部依赖关系。因此,由于立体图像的非局域性和长程依赖性,不能直接应用于立体图像SR。
光场图像SR光场成像能够以空间分辨率为代价获取光的附加角信息。为了提高空间分辨率,Yoon等人[23]引入了第一个光场卷积神经网络(LFCNN)。Yuan等人[24]提出了一种具有单图像SR模块和极平面图像增强模块的CNN框架。为了模拟相邻子孔径图像之间的对应关系,Wang等人开发了一种双向循环CNN。他们的网络使用一个隐式多尺度特征融合方案来为高级图像积累上下文信息。由于立体成像通常具有比光场成像大得多的基线,这些方法不适用于立体成像。
立体图像SR Bhavsar等人认为,在立体背景下,图像SR与HR深度估计是相互交织的。因此,他们提出了一种综合方法,从LR立体图像中联合估计SR图像和HR差异。最近,Jeon等人提出了一种利用视差先验的立体osr。给定一个立体图像对,用不同的间隔对右图像进行移位,并与左图像连接,生成一个立体张量。然后将张量反馈给一个普通的CNN,通过检测视差信道中的相似块来生成SR结果。然而,由于右移图像的数目是固定的,使得StereoSR无法处理视差变化较大的不同立体图像。
2.2. Longrange Dependency Learning
为了处理不同分辨率的立体图像,需要捕获立体图像中的远程依赖关系。在本节中,我们将回顾两种用于长期依赖学习的方法。
匹配[15,16,17]和光流估计[27,28]。对于立体匹配,有几种方法[15,16]使用朴素级联构造4D代价体。这些方法将所有差异的左特征图与对应的右特征图连接起来,得到4D的代价卷(即heightwidthdisparitychannel)。然后,通常使用三维神经网络进行成本匹配学习。然而,从4D成本卷中学习匹配成本会带来很高的计算和内存负担。为了达到更高的效率,使用点积来降低特征维数[17,18],导致3D的成本体积(即, heightwidth*disparity).然而,由于三维成本体积最大视差固定,这些方法无法处理视差变化较大的不同立体图像对。
自我注意机制注意机制被广泛用于捕获长期依赖性[29,30]。对于自我注意机制[31,32,33],将空间和/或时间域中所有位置的加权和计算为一个位置的响应。通过矩阵乘法,自我注意机制可以捕捉任意两个位置之间的相互作用。因此,可以用计算和内存开销的少量增加来建模远程依赖关系。自注意机制已成功地应用于图像建模[32]和语义分割[33]。最近的非本地网络[34,35]也有类似的想法,可以认为是自我注意机制的概括。注意,由于自我注意机制对整个图像的依赖性建模,直接将这些机制应用于立体图像SR涉及不必要的计算。
受自我注意机制的启发,我们开发了一种视差注意机制来模拟立体图像中的全局依赖关系。与成本相比,视差注意机制更加灵活和有效。与自注意机制相比,视差注意机制充分利用了外极约束,减少了搜索空间,提高了搜索效率。此外,视差注意机制迫使网络专注于最相似的特征,而不是收集所有相似的特征来生成通信。结果表明,视差注意机制能够产生可靠的对应关系,从而提高SR性能(第4.3.1节)。
3. Method
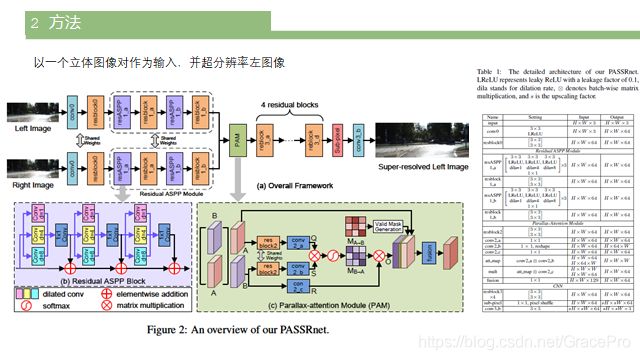
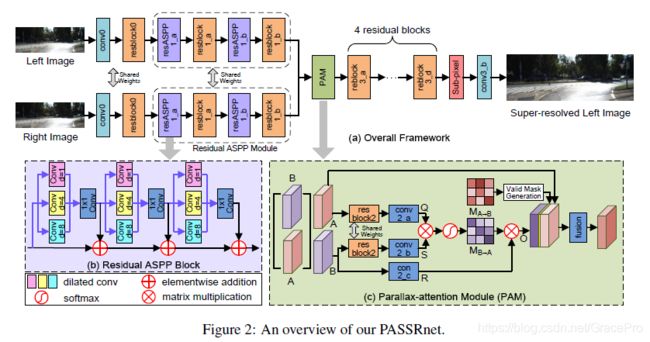
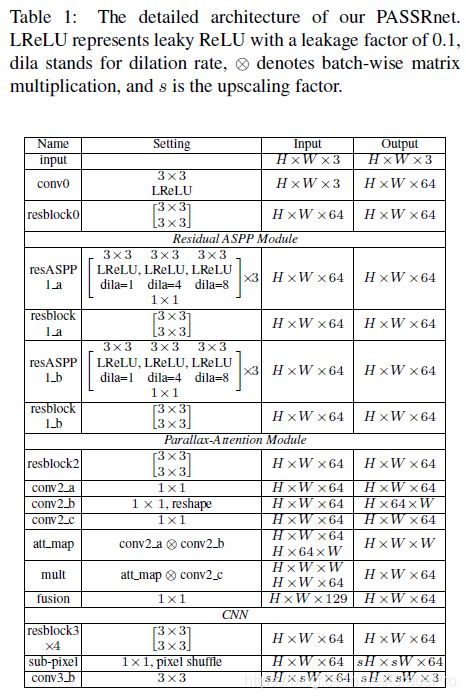
PASSRnet以一个立体图像对作为输入,并超分辨率左图像。PASSRnet架构如图2和表1所示。
3.1. Residual Atrous Spatial Pyramid Pooling (ASPP) Module
具有丰富上下文信息的特征表示对于对应估计[16]非常重要。因此,为了获得一个有区别的表示,需要大的接受域和多尺度的特征学习。为此,我们提出了一个残差ASPP模块来扩大接收域,提取具有密集像素采样率和尺度的层次特征。
如图2 (a)所示,残差ASPP模块由残差ASPP块与残差块交替级联而成。首先将输入特征输入到残差ASPP块中,生成多尺度特征。然后将这些结果特征发送到残差块进行特征融合。这个结构重复两次以产生最终的特征。在每个残差ASPP块内(如图2 (b)所示),我们首先将三个膨胀卷积(膨胀率分别为1、4、8)组合成一个ASPP组,然后以残差的方式将三个ASPP组级联。残差ASPP块不仅扩大了接收域,而且丰富了卷积的多样性,形成了具有不同接收区域和膨胀率的卷积的集合。残差ASPP模块学习到的高分辨特性有利于SR的整体性能,如第4.3.1节所示。
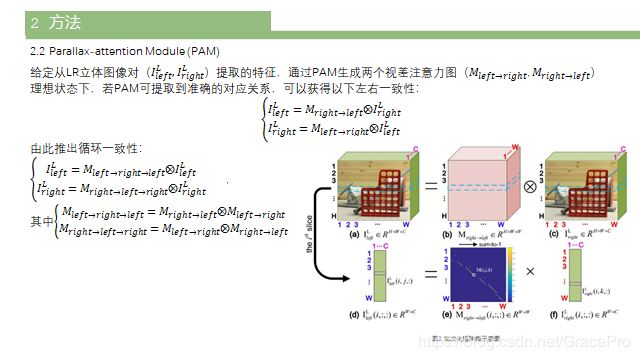
3.2. Parallaxattention Module (PAM)
受自我注意机制的启发[32,33],我们开发了PAM来捕捉立体图像中的全局对应关系。PAM有效地集成了来自立体图像对的信息。
视差注意力机制PAM结构如图2©所示。
![]()

与自我注意机制不同[32,33],视差注意机制强制网络专注于沿着极线的最相似的特征,而不是收集所有相似的特征,导致稀疏的注意力图。
4. 实验结果
在本节中,我们首先介绍数据集和实现细节,然后进行烧蚀实验来测试网络。我们进一步比较了网络与最近的单图像SR和立体图像SR方法。
4.1. Datasets
为了进行训练,我们跟踪了[6],并将Middlebury的60张[38]图像降采样2倍,以生成HR图像。我们进一步从Flickr收集了1024张立体图像来构建一个新的Flickr1024数据集。该数据集作为我们PASSRnet的增强训练数据。有关Flickr1024数据集的更多细节,请参阅补充材料。为了测试,我们使用了来自Middlebury数据集的5张图像、来自KITTI 2012数据集[39]的20张图像和来自KITTI 2015数据集[40]的20张图像作为基准数据集。我们进一步从Flickr收集了10张近景立体图像(视差大于200),以测试网络对较大视差变化的灵活性。为了验证,我们从KITTI 2012数据集中选择了另外20张图片。