python-合并Excel文件-上百个不同文件夹下Excel-处理过程超多
python-合并Excel文件【上百个不在同一文件夹下的Excel文件,处理过程超多】
- 前言:
- 1、今天的excel数据
- 1.1、数据展示
- 2、合并思路分析
- 3、步入代码
- 3.1、导入模块
- 3.2、解决思路步骤4*
- 3.3、解决空、缺失值以保提取完整数据
- 3.4、合并表格与其他提醒控制语句
- 4、主函数
- 5、结语
- 6、文末彩蛋--开心一刻
更多关于Python的知识请加关注哟~~。若需联系博主请私信或者加博主联系方式:
QQ:1542334210
微信公众号:不一样的数据分析
微信号:ZDSL1542334210
前言:
T_T最近离职了,重新找工作中,所以有时间来更新文章T_T,那么今天来个重头戏,就是利用python批量合并excel文件。我们在工作中,避不了有这样的情况,就是老板让你把历史以来的订单数据或者日常报单数据合并为一个excel文档方便入库,这些数据每天都会产生一张表格,如果刚好是一个月的,你可能复制粘贴,但是如果是2020整年呢?现在日期是2020.06.24,那么总共有31+29+31+30+31+24=176张excel表格…我想说的是,我写了一个合并excel的脚本,你慢慢复制吧,我去看会电影…
当然我们上面仅仅是不到6个月的数据,如果是几年的数据那么基本上就不用做了,直接把电脑砸了吧!
1、今天的excel数据
不得不说,我这个案例是比较难的,如果python基础不太好的同学,建议【关注我的博客和微信公众号一波,后期我将会写出python基础教程,敬请关注!】不过呢认真练习和阅读你会发现,并不是那么难。你操作操作也能上手。
1.1、数据展示
这是数据存放文件夹,这里有4个月数据的文件夹,每个月份对应文件下又有对应天数个excel数据文件。
这是展示一月份的文件夹,对应有31个数据文件
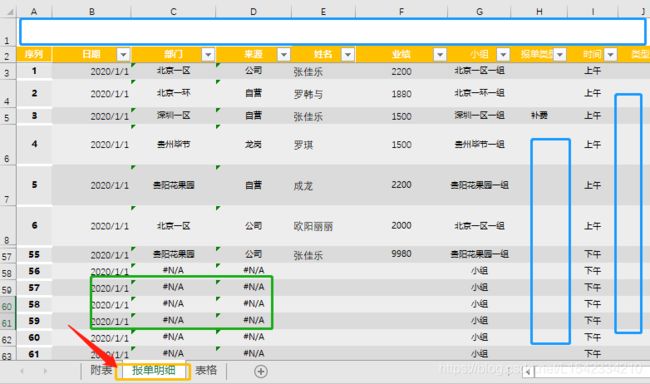
随便打开一个表格看看,每个表格大概有50多条数据,而且我们只要"报单明细"这个标签表(这里我增加了难度,故意空出一行和多个缺失值与空值,为的就是能够处理更加复杂的问题,把一些"捣乱"的因素考虑进去)
2、合并思路分析
首先必须明确,要想合并这些表格,肯定会使用到循环,我们的步骤是这样的(如果单是训练技术,请重点看步骤3,如果未满18岁请在父母陪同下观看,较为血腥暴力):
1、获取"每日数据"文件夹下的所有文件夹名,目的是为了用其拼接出每月的数据存放路径;
2、用步骤1得到的各月数据存放路径获取该月各日的数据文件路径;
3、利用循环将步骤2中的表格挨个合并(纵向拼接,该步骤是最复杂的)圈下来,要考的!
4*、这里主要是要考虑设置一些代码块作为提示-- 比如,我们的数据是每天都有一份,那万一数据少了一天或几天的数据呢?再比如,我们需要设置一个时间预测,就是预计合并需要多长时间,这样方便监控(数据越多越有必要)!
3、步入代码
3.1、导入模块
导入模块
import pandas as pd
import os
import warnings # 警告模块
import numpy as np
import time
import datetime
3.2、解决思路步骤4*
这里要作准备工作,需要计算我们现存文件夹下有多少个excel数据文件与实际应该有多少个。那么怎么计算呢?
首先现存文件夹下共有多少excel数据文件计算方法就是获取每个月份文件夹下的所有excel数据进行求和,代码为
path='D:/zhuge/每日数据/' #数据存放路径
filenames = os.listdir(path)
file=[path+i for i in filenames] #列表推导式
for i in file:
len1=len(os.listdir(i))
fillen=fillen+len1 #得到现存的文件个数 这里是121个
再次就是按照日期实际上应有的文件个数,这里我的思路是这样的(方法有很多,这里仅供参考,欢迎大家自行发挥并留言,我们一起讨论),我获取一月份文件夹下第一个excel文件且获得对应时间,记为,再获取四月份文件夹下最后一个excel文件获得对应时间,记为endyear,然后让两个时间作差取天数,这样就得按照日期实际上应该有多少excel文件,最后利用endyear-bgyear就得到我们少了多少文件或者多了多少文件,无论少或者多都是错的,所以要排除这可能,相等时才合并。这样作差的好处是计算精确,因为最近一个月总是不足对应月份天数的,所以不能直接用月份对应天数相加。这样代码为:
bgyear=os.listdir(file[0])[0][0:10].replace('.','-') #用replace函数是因为之前文件命名为"2020.01.01"将其修改为"2020-01-01"
endyear=os.listdir(file[len(file)-1])[len(os.listdir(file[len(file)-1]))-1][0:10].replace('.','-')
trueday=datetime.datetime.strptime(endyear,'%Y-%m-%d')-datetime.datetime.strptime(bgyear,'%Y-%m-%d')
truefil=trueday.days+1
# 这里加1是因为两个日期相减会少一天,我们将其补回来。部分同学可能不太清楚
#举例:1号到6号,6-1=5天,但实际上我们是算6天,因为作差,缺失了一天
print("按日期实际应有的文件个数为:"+str(truefil))
3.3、解决空、缺失值以保提取完整数据
我们对初始的数据可以看到,有大量的空值和 缺失值需要处理,那么我的方式就是:1、先提取“报单明细”标签表;2、删除第一行空值;3、根据姓名列,找到最后一个为空的单元格位置,将中间的所有行数提取出来;4、日期就以对应文件名称为准(这是因为表格中文件填写的日期是不准确的,故采用对应文件名称),具体代码实现为:
# 该部分代码需要结合总主函数进行观看,如有不懂得伙伴可加关注在微信公众号留言私聊我
for filename in filenames:
paths=path+filename+'/'
excelnam = os.listdir(paths)
for i in excelnam:
data=i[0:10].replace('.','-')
print("正在合并日期 {} 数据".format(data))
df=''
df = pd.read_excel(paths+i,sheet_name='报单明细')
df=df.iloc[:,0:8]
df.columns = ['序列', '日期', '部门', '来源','姓名','业绩','小组','求和']
df1=df.drop([0]) #删除第一行
df1['日期']=data
df1=df1.reset_index(drop=True) #重置索引
Notnaem=np.where(df1['姓名'].notnull())[0][0]
df2=df1.drop([i for i in range(Notnaem)])
df3=df2.reset_index(drop=True)
NAnaem=np.where(df3['姓名'].isnull())[0][0]
3.4、合并表格与其他提醒控制语句
每当数据提取出来后,我们使用pd.concat()将数据截着拼接上即可,当然其他控制就是通过提示打印出合并过程中的具体步骤了,难度并不是很大。
# 此步骤为上一步的后续,需要结合一起看。
df4[["业绩"]] = df4[["业绩"]].astype(float)
df4['求和']=sum(df4['业绩'])
df4['序列']=[i for i in range(1,len(df4)+1)]
df5=pd.concat([df5,df4])
# 提醒类控制语句
print('='*10+'恭喜!共{}日数据合并完成,耗时:{}秒'.format(fillen,round(time2-time1,3)))
print('Error'+'*'*3+' '*20+'合并失败!'+' '*20+'*'*3+'Error')
print('Error'+'*'*3+'文件个数有误,有累积%s天数据未放入指定文件夹下'%(truefil-fillen)+'*'*3+'Error')
print('Error'+'*'*3+' '*13+'请检查数据文件天数!'+' '*13+'*'*3+'Error')
4、主函数
主函数部分就是.py文件放到任一文件夹下[当然注意你数据存放类型和位置是否对],我一般是利用cmd命令来执行.py文件,当然了我们函数中已经将存放路径写为默认的了。
import pandas as pd
import os
import warnings
import numpy as np
import time
import datetime
warnings.filterwarnings("ignore")
pat='./' #保存合并完成的路径
path='D:/zhuge/每日数据/' #合并报单存放路径
filenames = os.listdir(path)
file=[path+i for i in filenames]
bgyear=os.listdir(file[0])[0][0:10].replace('.','-')
endyear=os.listdir(file[len(file)-1])[len(os.listdir(file[len(file)-1]))-1][0:10].replace('.','-')
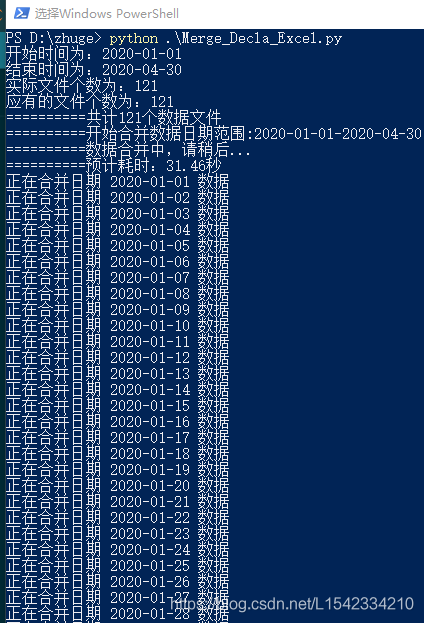
print("开始时间为:"+bgyear)
print("结束时间为:"+endyear)
trueday=datetime.datetime.strptime(endyear,'%Y-%m-%d')-datetime.datetime.strptime(bgyear,'%Y-%m-%d')
truefil=trueday.days+1
print("应有的文件个数为:"+str(truefil))
fillen=0
for i in file:
len1=len(os.listdir(i))
fillen=fillen+len1
print("现存的文件个数为:"+str(fillen))
if truefil==fillen:
print('='*10+'共计%s个数据文件'%(fillen))
print('='*10+'开始合并数据日期范围:%s-%s'%(bgyear,endyear))
print('='*10+'数据合并中,请稍后...')
print('='*10+'预计耗时:%s秒'%(round(fillen*0.26,3)))
df5=pd.DataFrame()
time1=time.time()
for filename in filenames:
paths=path+filename+'/'
excelnam = os.listdir(paths)
for i in excelnam:
data=i[0:10].replace('.','-')
print("正在合并日期 {} 数据".format(data))
df=''
df = pd.read_excel(paths+i,sheet_name='报单明细')
df=df.iloc[:,0:8]
df.columns = ['序列', '日期', '部门', '来源','姓名','业绩','小组','求和']
df1=df.drop([0]) #删除第一行
df1['日期']=data
df1=df1.reset_index(drop=True) #重置索引
Notnaem=np.where(df1['姓名'].notnull())[0][0]
df2=df1.drop([i for i in range(Notnaem)])
df3=df2.reset_index(drop=True)
NAnaem=np.where(df3['姓名'].isnull())[0][0]
df4=df3[0:NAnaem]
df4[["业绩"]] = df4[["业绩"]].astype(float)
df4['求和']=sum(df4['业绩'])
df4['序列']=[i for i in range(1,len(df4)+1)]
df5=pd.concat([df5,df4])
df5.to_excel(pat+"数据合并(%s-%s).xlsx"%(bgyear,endyear), index=False)
time2=time.time()
print('='*10+'恭喜!共{}日数据合并完成,耗时:{}秒'.format(fillen,round(time2-time1,3)))
else:
print('Error'+'*'*3+' '*20+'合并失败!'+' '*20+'*'*3+'Error')
print('Error'+'*'*3+'文件个数有误,有累积%s天数据未放入指定文件夹下'%(truefil-fillen)+'*'*3+'Error')
print('Error'+'*'*3+' '*13+'请检查数据文件天数!'+' '*13+'*'*3+'Error')
来吧展示心在跳爱在烧…
5、结语
本案例是合并excel的具体实列,主要为了体现python自动化操作的便捷和快速。如有问题或是小伙伴们有需要我帮合并的欢迎关注我微信公众号【扫描下方二维码】并留言,博主会在两个工作日内回复,若未回复请加博主微信:ZDSL1542334210.
6、文末彩蛋–开心一刻
这不是前不久我熊哥结婚了,恰好我们公司王总也是结婚了,他俩上班就经常在一起交流结婚后的心得体会。王总说:“我老婆可能到了更年期了,特别健忘,经常是提着菜刀还满屋子找菜刀,有的时候我真受不了她。结果这时候我熊哥说到:“你的处境比我好多了,我老婆经常是提着菜刀满屋子找我。”就是这么个情况嘛。
请扫码关注我微信公众号和相关渠道信息~~

