替换DOM中的文本,解决?
本文为翻译,原文:http://james.padolsey.com/javascript/replacing-text-in-the-dom-solved/
两年前,写了篇关于替换DOM中文本的文章,"I'ts not simple" ,本人翻译版 ,这几天又重新审视了下这个问题,找到了一个好的解决办法。
问题大概是这样子滴,假设有一段HTML:
This is a test. Testing is fun!
你想找出包含字符"test"的各种情况,并用个标签包裹起来,像这样:
This is a test. Testing is fun!
换个说法就是,要使用正则/\btest\w*\b/gi (所有以test开头的单词) 去匹配所有元素里的文本内容,并且替换掉, 替换不能使用DOM简单的字符串操作,比如:
element.innerHTML = element.innerHTML.replace(
/\btest\w*\b/gi,
'$0'
);因为,这种方式虽然可以达到目的,但是会造成下面这些结果:
1.innerHTML 会包含HTML里的所有内容,html标签本身里出现的字符也被替换了,比如
里的test也会被替换
2.被替换掉的内容会重新生成DOM,原来的dom上的事件,引用等都会被破坏。
同样用 innerText (or textContent)的方式替换也会有问题:
element.innerHTML = element.innerText.replace(
/\btest\w*\b/gi,
'$0'
);好的解决办法
遍历所有文本节点,单独去匹配它们,并把匹配的文本节点分割成几部分,把匹配的部分用一个新的元素替换掉。
这种方式毫无疑问要比innerHTML/Text 要好,但是也有些需要注意的地方:
这种方案往往假设不存在相邻的文本节点,如果节点内容是动态添加的,不要忘记调用Node#normalize.
个重要的是,如果一个匹配的单词跨节点了改如何处理?比如:
This is a test.
This is a test.
或者这样:
This is a test.
包裹整个匹配的部分包括跨节点,或者单独的包裹匹配的部分。
为什么会如此棘手?
为了匹配一段正则表达式,我们需要一段测试文本。如果测试单独的文本节点我们可能不出遇到上面说的这种情况,“te”是一个文本节点,"st"是另外一个文本节点。
替换也是一个难题,因为你要把匹配的节点在正确的位置分割,并替换,这不是一项简单的工作....(你妹啊,老外太闲了吧,说了一大段就是为了说有多难干,有木有啊,元芳?)
要完美的解决问题需要做到以下几点:
1.可以支持任何js表达式进行匹配。
2.可以匹配跨节点单词,比如:apple,可以是 apple 或者 What is apple
3.不能破坏原有的dom节点,出text node之外。
如何解决?
(注:targetElement = 查找匹配的根节点)
1.收集所有targetElement 节点下的所有text内容,(用innerText/textContent)
2.用正则进行匹配,把所有匹配的start,end索引位置记录下来
3.遍历targetElement 下的节点树,并用一个记录变量保存当前分析到的text的index,当找到一个匹配位置时,记录start-node,end-node,intersecting nodes(交叉节点,就是把某个单词分割开的那个节点),然后把记录结果串给第4步。
4.根据当前的DOM区间(start-node, intersecting-nodes, and end-node):
如果start-node ,end-node一致,就把当前node分割成三部分,Before-match, match, After-match,用把match部分包裹起来;
如果start-node ,end-node不一致,分别把它们分割成match and non-match parts两部分,用把match部分包裹起来,同是也包裹intersecting nodes
New: findAndReplaceDOMText
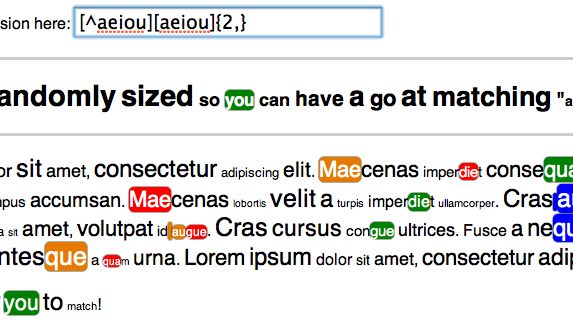
DOME:http://padolsey.github.com/findAndReplaceDOMText/demo.html
GIT源代码:https://github.com/padolsey/findAndReplaceDOMText