Python多进程中的文件写入问题
因项目数据量庞大需要使用多进程的方法计算数据(计算密集型)
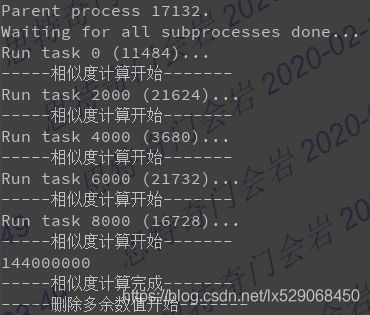
在写完代码之后,发现如果按照如下写法,则并不会并发执行,而是执行完一个接着执行第二个
print('Parent process %s.' % os.getpid())
p = Pool(5)
for i in range(0, len(dataB), int(len(dataB) / 5)):
dataC = (dataB.iloc[i:int(i + len(dataB) / 5)])
df_list = pd.concat([dataA, dataC], sort=True)
res = p.apply_async(long_time_task, args=(i, df_list, dataA.iloc[:, :1], dataC.iloc[:, :1],))
res.get().to_csv('result0211.csv', mode='a', header=False, index=False)
print('Waiting for all subprocesses done...')
p.close()
p.join()
print('All subprocesses done.')
测试发现,只有当
res = p.apply_async(long_time_task, args=(i, df_list, dataA.iloc[:, :1], dataC.iloc[:, :1],))
这句话后面没有语句的时候,进程才会并发执行(还没查到什么原因),但这样带来的问题就是,每个进程的数据无法存储
如果把存储语句写到long_time_task()函数,文件为空,可能原因是:
1)主进程不会等待IO读写完毕,而是运算完直接关闭所有进程;
2)多进程中不同进程是相互独立,即在多个进程下把数据写入同一文件由于是并发进行操作系统中会不清楚到底要写入哪个数据到文件中,所以会出现资源竞争混乱,导致文件内容出现空
而且如果进程都需要写入同一个文件,那么就会出现多个进程争用资源的问题,如果不解决,那就会使文件的内容顺序杂乱。这就需要涉及到锁了,但是加锁一般会造成程序的执行速度下降,而且如果进程在多处需要向文件输出,也不好把这些代码整个都锁起来,如果都锁起来,那跟单进程还有什么区别。
后来百度的解决方法为,使用回调函数
具体思路跟把文件输出集中在一起也差不多,就是把进程需要写入文件的内容作为返回值返回给惠和的回调函数,使用回调函数向文件中写入内容。这样做在windows下面还有一个好处,在windows环境下,python的多进程没有像linux环境下的多进程一样,linux环境下的multiprocessing库是基于fork函数,父进程fork了一个子进程之后会把自己的资源,比如文件句柄都传递给子进程。但是在windows环境下没有fork函数,所以如果你在父进程里打开了一个文件,在子进程中写入,会出现ValueError: I/O operation on closed file这样的错误,而且在windows环境下最好加入if name == 'main’这样的判断,以避免一些可能出现的RuntimeError或者死锁。
def mycallback(res):
res.to_csv('result_0211.csv', mode='a', header=False, index=False)
if __name__=='__main__':
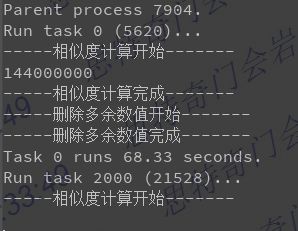
print('Parent process %s.' % os.getpid())
p = Pool(5)
for i in range(0, len(dataB), int(len(dataB) / 5)):
dataC = (dataB.iloc[i:int(i + len(dataB) / 5)])
df_list = pd.concat([dataA, dataC], sort=True)
p.apply_async(long_time_task, args=(i, df_list, dataA.iloc[:, :1], dataC.iloc[:, :1],), callback=mycallback)
print('Waiting for all subprocesses done...')
p.close()
p.join()
print('All subprocesses done.')
可以看到程序并发执行了