数据分析岗笔试卷五
网易2020校招数据分析方向正式批笔试题
更多数据分析试卷请点击数据分析真题
考点涉及:数据结构(二叉树、链表、树的遍历等)、斐波那契数列、PCA、概率论、高数、SQL、业务分析能力、编程
1. 以下关于主成分分析说法错误的是 C
A.PCA可以用来降维处理
B.PCA可以通过SVD来实现
C.PCA实现线性组合最小化样本方差
D.PCA可以通过特征值分解来实现
知识点扩展:PCA原理解释
PCA实现线性组合最大化样本方差
2. 2个盒子被小牛分别放入中有两个大小相同的球,这两个球只可能是红和蓝两种颜色,并且一个球是红的还是蓝的是等可能的。小牛让小客来猜盒子里球的颜色分别是什么样颜色。在小客猜的过程中,小牛告诉小客其中一个是盒子里面是红色的小球,那么另一个盒子里球还是红色的概率是多少( 1/3 )
解析:一共有4种可能:红红、红蓝、蓝蓝、蓝红
已知其中一个盒子是红色的,则另一个盒子里球还是红色的概率是1/3
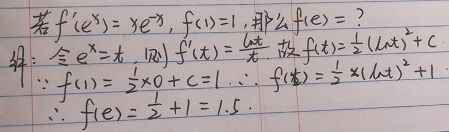
4. 数据结构中,沿着某条搜索路线,依次对树中每个结点均做一次且仅做一次访问。对二叉树的结点从1开始进行连续编号,要求每个结点的编号大于其左、右孩子的编号,同一结点的左右孩子中,其左孩子的编号小于其右孩子的编号,可采用( 后序 )次序的遍历实现编号。
解析:满足后序遍历(左右中)
5. 现在假设F是一个森林,B是由F转换得到的二叉树,F中有n个非终端结点,B中右指针域为空的结点有( n+1 )个?
6. 现在假设对N个元素的链表做顺序查找时,若查找每个元素的概率相同,则平均查找长度为( (N+1)/2 )?
解析:总比较次数:1+2+3+……+N = N(N+1)/2
则平均比较次数:(N+1)/2
7. 完全二叉树是指深度为K的,有n个结点的二叉树,当且仅当其每一个结点都与深度为K的满二叉树中编号从1至n的结点一 一对应将一棵有50个结点的完全二叉树按节点编号,如根节点的编号为1,那么编号为25的结点是( B )?
A.无左、右孩子
B.有左孩子,无右孩子
C.有右孩子,无左孩子
D.有左、右孩子
解析:完全二叉树,结点k的左右孩子结点为2k, 2k+1
满二叉树的每层结点个数为:1,2,4……, 2 i 2^i 2i其中,i=0,1,2,……,K
8. 假设有选课表course_relation(student_id, course_id),其中student_id表示学号,course_id表示课程编号,如果小易现在想获取每个学生所选课程的个数信息,请问如下的sql语句正确的是( )
select student_id,count(course_id)
from course_relation
group by student_id;9. 城市A当前剩余的车牌号为70000-99999之间,假设不能有两个相同的数字,那么剩余车牌号有( )个
解析:第一个数字有三种选择:7,8,9
所以, C 3 1 C 9 1 C 8 1 C 7 1 C 6 1 = 9072 C_3^1C_9^1C_8^1C_7^1C_6^1=9072 C31C91C81C71C61=9072
10. 15个阶梯,你一次可以上一阶或两阶,走上去,共有多少种走法? 987
解析:该题考查斐波那契数列(Fibonacci sequence),又称黄金分割数列
F(n) = F(n-1) + F(n-2)
可以记下常用的序列:1,1,2,3,5,8,13,21,34,55,89,144,233,377,610,987,1597,2584,4181,6765,10946,17711……
11. 用户分析是电商数据分析中重要的模块,在对用户特征深度理解和用户需求充分挖掘基础上,进行全生命周期的运营管理(拉新—>活跃—>留存—>价值提升—>忠诚),请尝试回答以下3个问题:
① 现在数据库中有一张用户交易表order,其中有userid(用户ID)、orderid(订单ID)、amount(订单金额)、paytime(支付时间),请写出对应的SQL语句,查出每个月的新客数(新客指在严选首次支付的用户),当月有复购的新客数,新客当月复购率(公式=当月有复购的新客数/月总新客数)。
一、查找每个月的新客数
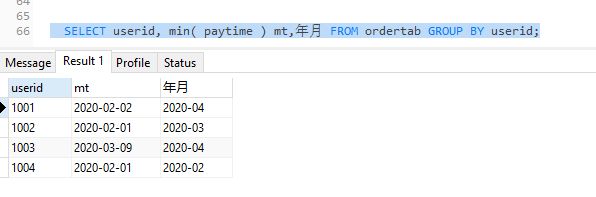
注意“SELECT userid, min( paytime ) mt , 年月 FROM ordertab GROUP BY userid”的查询结果是错误的,下图是错误运行结果
SELECT
年月,
count( userid ) AS 新客户数
FROM
(
SELECT
minres.userid,
minres.mt,
ordertab.年月
FROM
( SELECT userid, min( paytime ) mt FROM ordertab GROUP BY userid ) minres,
ordertab
WHERE
minres.userid = ordertab.userid
AND minres.mt = ordertab.paytime
) a02
GROUP BY
年月 二、查询每月复购的新客数
SELECT
年月,
count( userid ) AS `有复购的新客户数`
FROM
(
SELECT
count( a01.userid ) 次数,
a01.userid,
a01.年月
FROM
(
SELECT
minres.userid,
minres.mt,
ordertab.年月
FROM
( SELECT userid, min( paytime ) mt FROM ordertab GROUP BY userid ) minres,
ordertab
WHERE
minres.userid = ordertab.userid
AND minres.mt = ordertab.paytime
) a02,
ordertab a01
WHERE
a02.userid = a01.userid
AND a01.年月 = a02.年月
GROUP BY
a01.userid
) o3
WHERE
次数 >= 2
GROUP BY
年月 将上述分解步骤进行综合
SELECT
order1.年月,
order1.新客户数 AS 每月新客户数,
ifnull( order2.有复购的新客户数, 0 ) AS 当月有复购的新客数,
( ifnull( order2.有复购的新客户数, 0 ) / order1.新客户数 ) AS 新客当月复购率
FROM
(
SELECT
年月,
count( userid ) AS 新客户数
FROM
(
SELECT
minres.userid,
minres.mt,
ordertab.年月
FROM
( SELECT userid, min( paytime ) mt FROM ordertab GROUP BY userid ) minres,
ordertab
WHERE
minres.userid = ordertab.userid
AND minres.mt = ordertab.paytime
) a02
GROUP BY
年月
) AS order1
LEFT JOIN (
SELECT
年月,
count( userid ) AS `有复购的新客户数`
FROM
(
SELECT
count( a01.userid ) 次数,
a01.userid,
a01.年月
FROM
(
SELECT
minres.userid,
minres.mt,
ordertab.年月
FROM
( SELECT userid, min( paytime ) mt FROM ordertab GROUP BY userid ) minres,
ordertab
WHERE
minres.userid = ordertab.userid
AND minres.mt = ordertab.paytime
) a02,
ordertab a01
WHERE
a02.userid = a01.userid
AND a01.年月 = a02.年月
GROUP BY
a01.userid
) o3
WHERE
次数 >= 2
GROUP BY
年月
) order2 ON order1.年月 = order2.年月
ORDER BY
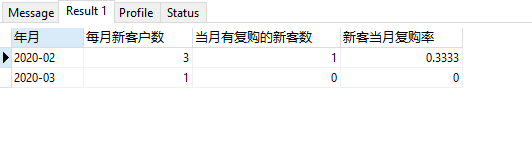
order1.年月;运行结果图
② 当你发现最近一周APP端新访用户当天转化率(公式=新访当天支付人数/新访用户数,新访是指首次访问严选APP的设备)环比最近4周日均转化率大幅下跌(超30%),你会如何去探查背后的原因?请描述你的思路和其中涉及的关键指标③ 在进行用户运营之前,我们通常会对用户进行分层,针对不同类型用户实施差异化的运营策略和资源投入,请你帮助设计严选用户分层的方案,包括关键特征的选择,分层的方法,如涉及模型/算法,请说明选择的算法类型、基本原理和步骤
2、3两小题和网易2020校招数据分析方向提前批笔试题中一样
12. 网易严选是网易旗下原创生活类自营电商品牌,深度贯彻“好的生活,没那么贵”的品牌理念。商品覆盖居家、餐厨、配件、服装、洗护、母婴、原生态饮食等几大类目,兼具品质和性价比,得到用户的广泛好评。若你是网易严选负责商品的数据分析师,当面对以下业务问题时,你会如何解决?
① 居家品类期望了解购买居家类目的用户是哪群人,期望你帮助她进行品类用户画像的构建,以作为居家品类规划和商品运营的参考,你会从哪些维度去完成类目用户的刻画?
解析:本小题考查用户画像的刻画,构建用户画像是为精准销售
从以下维度去刻画居家类目的用户画像:
(1)人口属性:包括性别、年龄等;
(2)社会属性:职业、住址、教育情况、婚恋情况、用户移动轨迹等;
(3)兴趣特征:浏览内容、收藏内容、阅读咨询、购买物品偏好等;
(4)行为数据:访问时间、浏览路径等用户在网易严选网站上的行为日志数据;
(5)社交数据:用户社交相关数据;
② 如果需要选择一批商品来吸引新用户,你会从哪些维度进行选择?请写出维度,选择的原因,对应的指标
(1)根据用户画像确定目标客户;
(2)获取最佳潜客的数据源;
(3)通过数据发掘确认潜客的“前期征兆”;
(4)制定获得顾客的流程,如从同行业网易严选的品类多、质量优、性价比高、好评多等维度精准宣传商品;
(5)采用KPI测试并不断修正获得顾客的流程。
13. 小易给定你数字 A , B ( A < B ) A,B(A \lt B) A,B(A<B)和系数 p , q p,q p,q。每次操作你可以将 A A A变成 A + p A+p A+p或者将p变成 p × q p\times{q} p×q。问至少几次操作使得。
def doubleSolution():
A,B,p,q = list(map(int, input().split()))
count = 0
while (A<B):
if (A+p>=B):
A = A+p
else:
p=p*q
count += 1
return count
if __name__ == '__main__':
T = int(input())
while (T>0):
T -= 1
print(doubleSolution())14. 有三种葡萄,每种分别有a,b,c颗。有三个人,第一个人只吃第1,2种葡萄,第二个人只吃第2,3种葡萄,第三个人只吃第1,3种葡萄。适当安排三个人使得吃完所有的葡萄,并且三个人中吃的最多的那个人吃得尽量少。
解析:三个人平分吃或者最多的葡萄被两人平分
T = int(input())
for i in range(T):
a,b,c = list(map(int, input().split()))
#“//”代表向下取整的除法,返回的是整数,如5.0//2=2,8//4 = 2
#“/”代表浮点除法,返回的是浮点数
mean = (a+b+c+2)//3
maxinum = (max(a,b,c)+1)//2
print(max(mean,maxinum))15. 小易定义一个数字序列是完美的,当且仅当对于任意 2 ≤ i ≤ n 2\le i \le n 2≤i≤n,都满足 ∑ 1 ≤ j < i A j ≤ A i \sum_{1\le{j}\lt{i}}A_j\le{A_i} ∑1≤j<iAj≤Ai,即每个数字都要大于等于前面所有数字的和。现在给定数字序列 A i A_i Ai,小易想请你从中找出最长的一段连续子序列,满足它是完美的。
def perfectSequence(array):
i, j = 0, 1
current = 0
while i < n and j < n:
while j < n and sum(array[i:j]) <= array[j]:
j += 1
current = max(current, j - i)
i = j
j = i + 1
return current
if __name__ == '__main__':
T = int(input())
for i in range(T):
n = int(input())
array = list(map(int, input().split()))
print(perfectSequence(array))16. 小易的公司一共有n名员工, 第i个人每个月的薪酬是 x i x_i xi万元。现在小易的老板向小易提了m次询问, 每次询问老板都会给出一个整数k, 小易要快速回答老板工资等于k的员工的数量。
方法一、使用Counter
from collections import Counter
n, m = map(int, input().split())
salary = list(map(int, input().split()))
frequency_dict = dict(Counter(salary))
for i in range(m):
query = int(input())
#get()方法:返回指定键的值,如果值不在字典中返回默认值None。
#get(query,0)表示如果不存在的话,就返回0
print(frequency_dict.get(query,0))方法二、使用字典
n, m = map(int, input().split())
salary = list(map(int, input().split()))
salary_dict = {}
for i in salary:
if i not in salary_dict.keys():
salary_dict[i] = 1
else:
salary_dict[i] += 1
for j in range(m):
query = int(input())
if query not in salary_dict.keys():
print(0)
else:
print(salary_dict[query])方法三、运算复杂度较大,且case通过率为50.00%
n, m = map(int, input().split())
salary = list(map(int, input().split()))
query = []
for i in range(m):
query.append(int(input()))
for j in query:
print(salary.count(j))