Selenium Web自动化测试(一)基础课程
课程内容:
- Python3的基本语法和函数面向对象编程
- 学会使用 PythonIde(社区免费版) 和快速整理代码
- PEP8编码
- Ctrl+Alt+L
- Project文件模块读写文件 路径拼接
- WebDriver API
- 断言unittest.TestCase
Selenium历史
- IE Firefox Chrome 选择拉起 根据市场份额
- B/s 结构
- Selenium Rc 依赖Js,并且效率较低
- WebDriver 3.x版本
pip install -U selenium安装最新版本selenium
WebDriver是什么
- Py -3 –m pydoc – p 4567

- (Web应用程序自动测试的快速框架)
- 3.0取代了嵌入到被测Web应用中的JavaScript
- 强大的API模拟用户输入(send_keys,12306验证码)\操作浏览器
Selenium拉起浏览器
- 新建了项目&文件 webProject/testcase(保存测试用例)/test_1_query.py
- 新建文件夹driver/驱动浏览器.exe 文件
安装的依赖,在Mac上不方便配置环境变量
注意浏览器版本,不要升到最新版本

- 调用selenium核心:From selenium import webdriver
selenium相当于一个模块包,webdriver相当于一个类
from 路径 import 内容
- 类可以继承超类,超类和单元测试类不能一起被继承(python允许多态继承)
超类即object类
- 类全局变量 路径拼接 读取驱动浏览器.exe
import os,time
import unittest
currentPath = os.path.abspath(os.path.dirname(__file__)) #当前目录
projectPath = os.path.split(currentPath)[0] #取下标
toolsPath = projectPath.replace("\\",'/')+'/driver/chromedriver'
url = 'https://www.baidu.com'
print(currentPath)
print(projectPath)
print(toolsPath)D:\sdk\tools\untitled4\testcase (上一级文件夹路径,类型为str)
D:\sdk\tools\untitled4
D:/sdk/tools/untitled4/driver/chromedriver
定位到截图目录
toolsPath = projectPath.replace("\\",'/')+'/driver/chromedriver'
- 类外面全局变量 路径拼接
class SavePng(unittest.TestCase):
@classmethod
def setUpClass(cls):
cls.driver = webdriver.Chrome(executable_path = toolsPath)
cls.driver.get(url) #成员方法
cls.driver.implicityl_wait(10) #隐式等待类和类的调用需要实例化
- Path.replace(“//”,”\”)
- 缺乏驱动执行文件会抛错
- 拉起浏览器(executable_path) 可执行
- @classmethod装饰器
Selenium 拉起浏览器
- 构造函数 成员变量driver
- 需要被实例化中实例
- 超类中使用
- 加了装饰器,不需要被实例化
- 归属当前类本身
- 函数形参 类初始化 def __init__(self,url, imp_time):
- 超类需要初始化
- url,imp_time为入参;数据类型、顺序一致
- self.driver = webdriver.Chrome() (右边连接左边)
- self.driver.get(url) testerhome网站
- self.driver. implicitly_wait(单位秒) 隐式等待 全局有效的 最好不要用 用显式等待、强制等待和输入等待(实际8秒,设置20秒,不会浪费时间)
- return 和是否需要return 在堆里不被释放掉就不需要return
import os,time
import unittest
currentPath = os.path.abspath(os.path.dirname(__file__)) #当前目录
projectPath = os.path.split(currentPath)[0] #取下标
toolsPath = projectPath.replace("\\",'/')+'/driver/chromedriver'
url = 'https://www.baidu.com' #文件的全局变量
print(currentPath)
print(projectPath)
print(toolsPath)
class SavePng(unittest.TestCase):
#不用被实例化,不能当做类变量
@classmethod
def setUpClass(cls):
url = 'https://www.baidu.com' # 局部变量
cls.driver = webdriver.Chrome(executable_path = toolsPath)
cls.driver.get(url) #成员方法
cls.driver.implicityl_wait(10) #隐式等待Selenium 过渡-单元测试
- 同文件下新建1个函数 test_*.py开头
- testcase目录介代于某个功能
- test_a_login.py
- test_b_index.py
- testcase目录介代于某个功能
- Cmp规则 ascii码 文件计算顺序和文件夹
- 字符串用ord的方式转换成ASCII码
- cmp有A-Z,a-z 和所有的数字,由test来命名(继承于unittest.TestCase)
- 读取ini模式
ini用于服务器配置

def get_ini_date(secions, items):
iniconf = r"D:\trx\selenium_uses\Conf\config.ini" #路径中出现 \t 字符转义
conf = configparser.ConfigParser() #读取路径实例化
conf.read(iniconf, encoding = "utf-8") #读取方式 转义为utf-8 否则出现gbk问题
return conf.get(sections, items)注意:return conf.get(sections, items) 与ini文件中的大小写 upper()或lower()
括号内为入参,读取方法get_ini_date(),读取ini文件,被调用 (注意:调用和引用的区别,调用有返回?,没有返回形参没有意义)
self.driver.get(get_ini_date("Url","baidu_url") #入参,实参
- Setup()case执行顺序 assertUnitDemo.py
- 每个case执行前先执行setup(),执行时setup中的问题会多次报错
class Mytest(unittest.TestCase):
def setUp(self): #初始化
self.driver = browser()
self.driver.implicitly_wait(10)
self.driver.maximize_window()
def tearDown(self): #回收
self.driver.quite()- 创建等待开关,能否看到由断言决定,不需要等待时间;上下文切换需要等待时间
- 隐式等待 implicityl_wait 对整个webdriver有效
- debug 锁的概念
- 冒号意味闭合条件符
- 抽象精简
- 重复步骤
- 代码级别单元测试,不推荐web自动化中使用,case中有上下文关联
- 反复抽象
-
class demo(): def _time(self, time1, time2): # 类私有,别的类不能被继承,类的成员方法,成员方法 if debug: time.sleep (time1) else: time.sleep (time2) def test_a_indexUrl(self): """ :return: """ try: self._time(5, 10) tt = client.assert_title("理想生活") self.assertTrue(tt,msg="判断正确") if DEBUG: _logger.info("进入天猫") except NoSuchElementException as err: print(format(err))
-
- Try…except(异常处理)
try:
被保护代码
except .... exception as xxx:
raise xxx
Selenium 异常处理&API
- try…except
- Except 断言模式(元素找不到)
- webProject/base/Err.py
- Err.py 文件思想
- 抛错定位到2层
- Except xxx as error: raise func(“”) from error
创建base模块

__init__ python包,可被其他模块引用(from base import Err)
class RunTimeOut(Exception):
pass
class AssertErrorOut(Exception):
pass
class TimeOut(Exception):
pass引用
from base import Err
class Demo(unitTest.TestCase):
def test_a_Tittle(self):
#print("调式title",pc.get_option_value("Title","baidu_tt"))
#res修改了
try:
log._logger.info("验证网站的tittle")
res =commond.assert_title(pc.get_option_value("Title","baidu_tt")) #断言title
self.assertTrue(res,"百度的title验证正确")
except Exception as err:
commond.get_windows_img(r"E:\selenium_uses\Pic\test_a_Tittle")
# print("assertTrue test fail", err)
raise Err.RunTimeOut("assertTrue test fail")from err #调用
Selenium 单元测试&断言
- Example
- 强制等待 肉眼check -->引入断言
- self.assertEqual 相等性 |msg日志 (完全匹配)
- self.assertNotEqual 和上面反向的 (原先本身判断相等)
- self.assertTrue 断言条件为真 (字符串为空即为false,可验证所有问题)
网页title![]() ,非空字符串
,非空字符串
查看方法

from base import Err
class Demo(unittest.TestCase):
def test_a_Tittle(self):
#print("调式title",pc.get_option_value("Title","baidu_tt"))
#res修改了
try:
self.assertEqual("百度一下,你就知道", self.driver.title)
print("assertEqual test pass")
# self.assertTrue(res,"百度的title验证正确")
self.assertTrue(0, msg="这里为0") #####
except Exception as err:
commond.get_windows_img(r"E:\selenium_uses\Pic\test_a_Tittle")
# print("assertTrue test fail", err)
raise Err.RunTimeOut("assertTrue test fail")from err #调用
Selenium 单元测试
- 自动化原则:没有断言是不完整的
- 新增 import unitest
- 类继承unittest.TestCase 不能不同层级进行继承 (被类继承,传递性)
class Baidu_Api(unittest.TestCase):
@classmethod
def setUpClass(cls):
cls.driver =commond.get_driver("chrome","https://www.baidu.com")
log._logger.info("启动浏览器")
commond.time_sleep(3)
@classmethod
def tearDownClass(cls):
log._logger.info("执行,关闭浏览器")
commond.quit()class Demo(unittest.Testcase):
def test_findtype_title(self):
try:
print("验证类型",type(self.driver.title))
self.assertIsInstance(self.driver.title,str,"测试对象类型是str类型")
print("asserIsInstance test pass")
except Exception as err:
raise RuntimeError("get元素失败")from err
- setUp(),tearDown() 只执行一次 每个case前后执行一次
- tearDownClass()里面移值cls.driver.quit() 固定写法 (进程结束)
- 演示setUp()和setUpClass(cls)顺序
Selenium 单元测试&API
- @classmethod setUpClass(cls) tearDownClass(cls)
- 保留单个testcase 开始和结束 的结构 pass占位符
- 套入项目的演示 driver.title
- 元素定位到 if(element)
- 对象生效时类型检查且转换
- 验证当前网页driver.current_url
Selenium 单元测试&断言
- return 函数返回对象会做类型相等 self.assertInstance
![]()
import unittest
class Demo(unittest.TestCase):
def test_findtype_title(self):
try:
print("验证类型",type(self.driver.title))
t = self.driver.current_url #当前的URL
print("当前是什么",t)
t1 = self.driver.current_url
self.assertEqual(t, "https://www.baidu.com/",msg="当前URL为{}正确".format(t)) #
self.assertIsInstance(self.driver.title,str,"测试对象类型是str类型")
print("asserIsInstance test pass")
except Exception as err:
raise RuntimeError("get元素失败")from err

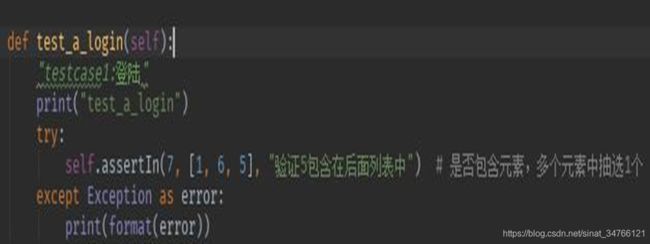
- self. assertIn 验证数据是否包含的
def test_findtype_title(self):
try:
print("验证类型",type(self.driver.title))
t = self.driver.current_url #当前的URL
print("当前是什么",t)
t1 = self.driver.current_url
self.assertIn("https://www.baidu.com/", t, msg="当前URL为{}正确".format(t)) #assertIn
self.assertIsInstance(self.driver.title,str,"测试对象类型是str类型")
print("asserIsInstance test pass")
except Exception as err:
raise RuntimeError("get元素失败")from err- self.assertNotIn 反向的 比较少 比如用于不确定对方参数是什么
- self.assertFalse 断言条件为假 反向的
Selenium 单元测试&跳过
- @ unittest.skip(msg) 无条件跳过
class Mytest(unittest.TestCase):
@unittest.skip("本次不执行")
def setUp(self):
self.driver = browser()
self.driver.implicitly_wait(10)
self.driver.maximize_window()- @ unittest.skipIf(条件表达式= true,msg) 条件满足 跳过
@unittest.skipUnless(debug>6,"失败条件不跳出")
def test_admin_login(self):
username = "xx"
password = "xx"
Login().user_login(self.driver, username, password)
- @unittest.skipunless (条件表达式=false ,msg) 条件不满足 跳过
@unittest.skipIf(debug<5,"debug全局满足条件")
def test_user_login(self):
username = "www"
password = username
Login().user_login(self.driver, username, password)- 跳过的应用场景
- test_utest_skip.py
单元测试框架
webdriver基础操作图谱
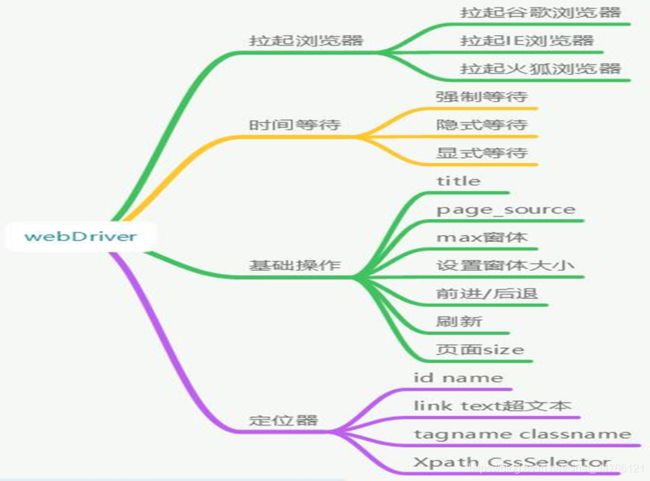
定位器识别控件属性
定位元素顺序:
1.id
2.name
3.xpath或css-selector
id(当前页面唯一,即page_source唯一,变换位置也没关系) name (不唯一)
定义一个目录去写入文件,文件拼接
open(前面定义path,“w+”)
启动webdriver.Chrome time.time()
文件关闭 条件
tagname
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
driver.implicitly_wait(10)
a = driver.find_element_by_tag_name("a")
# a = driver.find_element_by_tag_name("a").text
# print(a)
if a:
print("found a!")
driver.quit()tagname会拿到很多元素,然后用in去找元素
classname
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
driver.implicitly_wait(10)
a = driver.get_window_size()
driver.maximize_window()
driver.find_element_by_class_name("soutu-btn").click()
sleep(4)
Selenium API
- test_size.py
objsize = self.driver.page_source.__sizeof__() #单位为bytes
print("当前网页大小{}kb".format(int(objsize / 1024)))
time.sleep(2)
if int(objsize / 1024) > 60: # 判断尺寸
print(self.driver.current_url, "该网页尺寸过大")

检查每个浏览器的占用size的比例
- 启动后全屏 self.driver.m
- maximize_window()
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
driver.implicitly_wait(10)
a = driver.get_window_size()
driver.maximize_window()
cookies = driver.get_cookies()
print("当前窗口尺寸{},缓存cookies为{}".format(a, cookies))
print("value值为{}".format(cookies[0].get("value")))
图片:
断言是字典类型
a.size
from selenium import webdriver
from time import sleep
try:
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
driver.implicitly_wait(10)
a = driver.get_window_size()
driver.maximize_window()
a = driver.find_element_by_css_selector("#form > span.bg.s_ipt_wr.quickdelete-wrap > span")
print("picture:",a.size, a.text)
driver.find_element_by_css_selector("#form > span.bg.s_ipt_wr.quickdelete-wrap > span").click()
except Exception as error:
print(error)
sleep(4)- driver. page_source
- page_source在自动化里应用
- 申请网页资源的size
- 转换1024b = 1kb
- find_element_...定位器
- 使用【谷歌开发者工具】id/name
- link_text /partial_link_text的差异
link(超文本) text (模糊搜索)
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
driver.implicitly_wait(10)
driver.find_element_by_link_text("新闻").click()
#driver.find_element_by_partial_link_text("新").click() #可进行模糊查询,不推荐
if "百度新闻" in driver.title:
print("arrive to news page!")
sleep(4)
driver.quit()- Xpath /css定位器
from selenium import webdriver
from time import sleep
try:
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
driver.implicitly_wait(10)
a = driver.get_window_size()
driver.maximize_window()
a = driver.find_element_by_css_selector("#form > span.bg.s_ipt_wr.quickdelete-wrap > span")
print("picture:",a.size, a.text)
driver.find_element_by_css_selector("#form > span.bg.s_ipt_wr.quickdelete-wrap > span").click()
except Exception as error:
print(error)
sleep(4)- 提炼的xpath语法关注点
- 定位器优先顺序 遵循这条原则
- 火狐浏览器拉起演示
Selenium&补充
- test_baidu
- Os拿到上级目录 一层层拿
- Input等待输出 第4种等待
- 使用场景介绍
- 元素定位到按钮.text上,在用上面断言
- 函数级别Api演示
Selenium作业
- 对百度进行登陆操作
- 登陆方式不限制
- 根据课堂上学习到{}的方式 判断是扫码的,还是账号登陆的。如果是扫码,需要再次使用{}定位器去跳转。ps:注意不要直接用get(url) 要验证界面逻辑是否生效 XXXXXX
- 短信验证 使用input等待输入