爱奇艺蒙版AI:弹幕穿人过,爱豆心中坐

来源:机器之心
本文约3200字,建议阅读9分钟。
看起来非常可观的“人脸与背景分割”,究竟是基于人工智能还是基于人工?
作为(伪)AI 行业从业者,编辑部里的小伙伴们自认都能够以不错的置信度人工识别“人工智能与人工智障”。但是,当我把下面这张爱奇艺 app 的截图放在大家面前时,编辑部的“识别器”们纷纷表示,这次置信度不高。

开启人像区域弹幕屏蔽的《中国好声音》
热门视频里,“弹幕盖脸”几乎是必然事件,然而这个视频里,密密麻麻的弹幕都仿佛被李健老师的气场所折服,非常准确地“绕开”了他英俊的脸。偶尔还会有一些小失误,但这样的失误反而显得更像是算法而不是人工做出来的。

稍微失手的人像屏蔽
在学界,一个众所周知的事实是,尽管在目标检测任务里,数家巨头研究团队都在论文中报告出了“超越人类”的结果,图像分割任务似乎仍然给研究者们留下了不小的进步空间。谷歌今年 2 月发表的 DeepLabv3+,在利用 3 亿张内部数据做预训练的前提下,在 PASCAL VOC 2012 数据分割数据集上拿到了当前的最佳效果(state-of-the-art),IOU 89%。在 Cityscapes 数据集上,这个数字仅仅是 82.1%。
给定这样的研究水平,图像分割技术已经可以用于业界了吗?爱奇艺应用里看起来非常可观的“人脸与背景分割”,究竟是基于人工智能还是基于人工?带着全编辑部的一箩筐问题,我们一路辗转,联系到了爱奇艺技术产品中心,并且捉到了这项名为“AI 弹幕蒙版”项目的算法负责人,爱奇艺技术产品中心研究员,冯巍。他给了我们非常详尽的答案。
问题一:是不是分割?是什么分割?
首先是我们最关心的问题还是:这个“弹幕蒙版”究竟是人工智能还是人工?
是不是图像分割?是!是哪一种图像分割?语义分割(semantic segmentation)!
更确切地说,是一个有两个类别的语义分割:图像里每一个像素都会被分配到“前景”类别或者“背景”类别,然后系统会基于分割结果生成对应的蒙版文件。

原图,分割结果(蒙版文件可视化),以及蒙版效果
算法正是基于谷歌 DeepLabv3 模型,技术团队也尝试过 FCN 等其他分割模型,但是 DeepLab 的模型效果确实有突破。
冯巍也向我们展示了一些在综艺和影视剧场景下的分类结果。
中国新说唱弹幕蒙版效果
延禧攻略弹幕蒙版效果
为什么会想要用图像分割做“弹幕蒙版”?
爱奇艺团队的图像分割技术作为技术储备已经储备了相当长时间了,初衷是想用于短视频的背景替换。
所谓背景替换,就是把用户录制的短视频里的人像抠出来,换到另一个不同的背景里。但是从技术角度来讲,单张图像分割效果合格不等于视频分割效果合格:分割结果在视频前后几帧图像中稍有不连续,就会造成帧间分割边缘不停地抖动,而这样的分割不连贯是非常影响用户体验的。
那么有没有要求比背景替换低一点的场景?有,比如那就是保留原始背景,在原始背景和分割出来的人像层中间插入动态背景。这样分割边缘和原始背景仍然在一起,误差就不那么明显。这也是弹幕蒙版的来源了。
“技术 ready 了之后我们就一直在不同业务部门 demo 自己的各种能力,这样产品的同学就能想出很多好的点子。”冯巍说。
实际上,弹幕蒙版里用到的深度学习模型不只是分割,还有识别。在对视频进行分割前,“景别识别模型”会先对每一帧图像进行一次识别,判断当前帧属于近景还是远景。
这个景别识别任务,目的是判断图像是否是特写或近景镜头画面,这样的图像才会进入到分割模型中生成蒙版,而远景画面则不会生成蒙版,弹幕会像原来一样覆盖整个画面。这样一来,帧间蒙版抖动的问题就得到了很好的解决。

不需要生成蒙版的远景和需要生成蒙版的近景
值得一提的是,这个景别识别分类器也是一个已有技术积累换了个场景再利用的例子:之前这个分类器主要用于爱奇艺的智能辅助后期制作等功能。
分割结束之后,系统会进一步利用“腐蚀”和“膨胀”等图像形态学处理算法对分割模块输出的前景区域进行精细的剪裁,并根据应用场景的需要删掉画面占比小的前景区域。
经过这一系列的处理之后,才进入到蒙版文件的生成、压缩等生产流程。
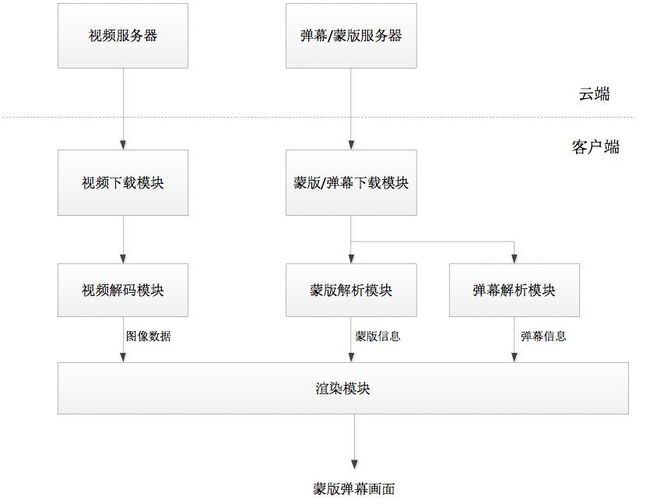
爱奇艺弹幕蒙版系统流程图
问题二:需不需要自己标数据?标了多少数据?
答案是需要!标了数万张。
通用的分割模型都是用 MS COCO 等通用数据集进行的训练,直接用在综艺场景上效果就非常一般了。
“场景切换和舞台光是两个通用分割模型很难处理好的问题。所以我们自己挑了数万张典型场景的图像,标注团队前后花了三周时间。”冯巍说。
训练集和测试集的分布一致性也得到了很好的保证:“我们第一个上线弹幕蒙版功能的节目是《中国新说唱第二季》,所以我们就用《中国新说唱第一季》以及同一个拍摄团队创作的《热血街舞团》做了训练集。”
值得一提的是,因为系统最终并不需要蒙版的分割“精细到头发丝”,所以标注工作也相对于一般的语义分割标注也更为容易一些,冯巍展示了一些补充训练集里的样例,“并不需要精细到像素,用直线把人物部分框出来就行了”。

与街景分割相比,精细度要求下调许多的人物分割
通用语义分割模型使用专用数据集做了全盘精调之后,IOU 从 87.6% 提升到 93.6%。
问题三:效率怎么样?快吗?贵吗?
推理阶段,一台 GPU 分割 1 分钟的视频,大约需要数分钟,仍然在 O(1) 时间之内。
实际生产中,系统也经常遇到比较严苛的时间需求。“《中国新说唱》的制作团队有一定的保密要求,比如节目周六八点要上线,我们可能四点钟才能拿到片子。所以我们通过视频分片数来控制生产服务的并发,并在所有分片完成后再通过消息队列通知业务层,每个分片的生产有单独的状态监控和重试机制。最终系统同时使用了 多台 GPU,处理一段 90 分钟的视频大概需要 40 分钟。”
团队也在测试将弹幕蒙版用于晚会直播等实时场景中了。
问题四:有什么“升级”打算?
除了防止“弹幕盖脸”之外还能做什么?
首先,防止“弹幕盖脸”也存在升级版,比如从语义分割升级到实例分割,把“所有人的防挡弹幕”变成“你爱豆的专属防挡光环”。
图像分割任务也分为好几种,语义分割只要求系统把所有图像里的"人"都分到“类别人"里就好。除此之外,还有需要将不同人物分入不同类别的“实例分割”(instance segmentation)以及连背景都不放过的“全景分割”(panoptic segmentation)。
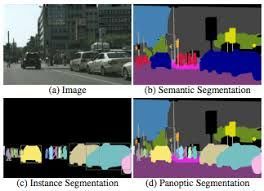
原图、语义分割、实例分割和全景分割
爱奇艺的技术团队也在研究基于 MaskRCNN 的实例分割,辅以爱奇艺的长项:明星人脸识别,尝试做“粉丝专属弹幕蒙版”。
“举个例子,如果你喜欢吴亦凡,那么其他明星出来的时候,弹幕还是会把他们挡住,只有吴亦凡出来的时候,弹幕会绕过他。”听起来是非常符合粉丝心理学的设计了。
还有一种是拓展一下语义分割里类别的边界。比如,能不能分出镜头焦距内的像素和焦距外的像素。
这个想法也来自于实际需求:“《延禧攻略》里,分割模型不光会识别出占了镜头主要位置的主角,和主角一起出现的、角落里一个在焦外的、完全虚化了的小太监的背影也会被分割出来。而其实后面这部分是不需要的,分出来反而影响用户体验。”
换言之,系统真正想要分割的是镜头的“焦内”和“焦外”,但是因为现在并没有进行这一类特定分割任务的模型,所以就用“有人物出现的部分”作为“焦内”的指代了。那些指代得没那么好的情况,也仍然是一个需要解决的问题,开发一些新的分割门类,或许是一个解决方案,但是这就不是数万张精调数据能够就解决的问题了。
而就算是语义分割本身,也还能拓展出很多不一样的应用场景,例如,商品的识别,也大有用处。
“比如一个手机厂商赞助了某一个节目,但是它并不是我们平台的赞助商,我们就需要把商标打码,或者把商品抽取出来替换掉。这个工作现在还是编辑手工完成的。”
除此之外,还有跟踪算法和分割算法的结合、用于移动端的模型加速与模型压缩等等……听起来,技术产品中心的研究员们的工作排期已经排到 8102 年了!
回到编辑部和小伙伴们交流完爱奇艺的做法,一点共同的体会是:弹幕蒙版的最终产品效果非常好,一言以蔽之,可以说是摆正对模型效果的期望,“量力而行”。
尽管分割模型还只是个正确率 80% 左右的“宝宝”,但是如果不刻意“刁难”它,而是选择一些不精细分割到头发丝也不影响使用的简单场景,再辅以一系列工程化的做法(例如用识别模型排除场景里困难的情况、通过图形学方法进一步优化分割效果),最终系统仍然能有上佳的成品效果。
虽然深度学习的思想是端到端的,但是需要正视的问题是,现实永远比训练集更复杂,在“一步登天”的模型出现之前,把“登天”的过程像“把大象放进冰箱”一样分成三步,拿到一个可用的版本后再用迭代的方法解决新问题,是不是也是一个不错的选择?

