网关
网关(gateway): 资源和应用程序之间的粘合剂。应用程序可以(通过HTTP或其它已定义的接口)请求网关来处理某条请求,网关可以提供一条响应。网关可以向数据库发送查询语句,或者生成动态的内容,像一扇门一样,进去一个请求,出来一个响应。
网关和代理的区别:
代理连接的是两个或多个使用相同协议的应用程序,而网关连接的则是两个或多个使用不同协议的端点。网关扮演的是“协议转换器”的角色。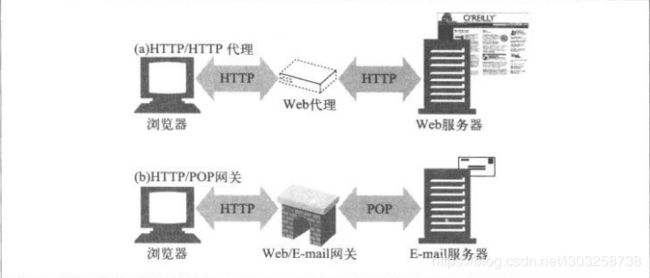
客户端和服务器端网关:
- Web网关在一侧使用HTTP协议,在另一侧使用另一种协议。
- <客户端协议>/<服务器端协议>
- (HTTP/*)服务器端网关:通过HTTP协议 与客户端对话,通过其他协议与服务器通信。
- (*/HTTP)客户端网关:通过其他协议与客户端对话,通过HTTP协议与服务器通信。
二、协议网关
服务器端Web网关(服务器协议转换器)、服务器端安全网关、客户端安全网关以及应用程序服务器。
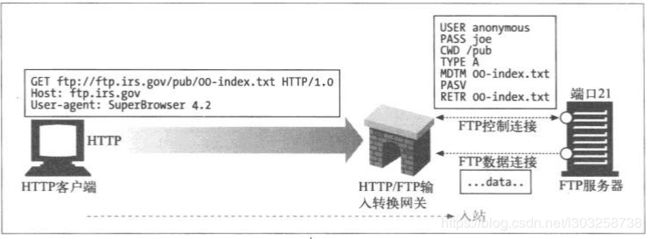
2.1(HTTP/*)服务器端Web网关
客户端发送HTTP请求,服务器Web网关会将该请求转换为其他协议与服务器进行连接。完成获取资源以后,会将对象放在一条HTTP响应中会送给客户端。
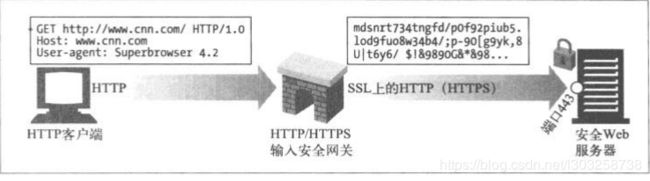
2.2(HTTP/HTTPS)服务器端安全网关:
客户端发送HTTP请求,网关会自动加密来自客户端的请求,然后再发送给服务器。
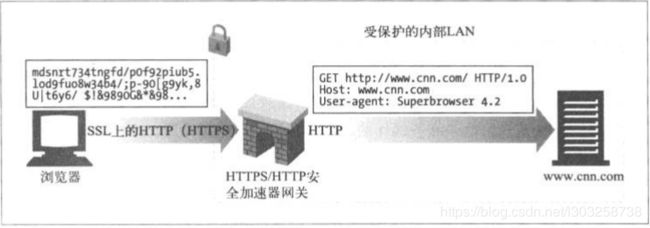
2.3(HTTPS/HTTP)客户端安全加速器网关
客户端发送的请求是经过加密的安全的HTTPS流量,通过网关进行解密,再向Web服务器发送普通的HTTP请求。
这些网关中通常都包含专用的解密硬件,解密效率高于原始服务器,可以减轻原始服务器的负荷。
2.4 资源网关
应用程序服务器,将目标服务器与网关结合在一个服务器中。应用程序服务器是服务器端网关,与客户端通过HTTP进行通信,并与服务器端的应用程序相连接。
客户端通过HTTP连接到应用程序服务器,服务器并不回送文件,而是将请求通过网关API发送给应用程序(运行在服务器上)。应用程序将请求资源回送给客户端。
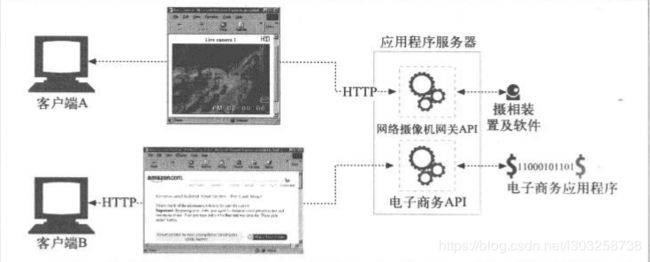
CGI(Common Gateway Interface )——通用网关接口
第一个流行的应用程序网关 API 就是通用网关接口(Common Gateway Interface, CGI)。CGI 是一个标准接口集,Web服务器可以用它来装载程序以响应对特定 URL 的 HTTP 请求,并收集程序的输出数据,将其放在 HTTP 响应中回送。
CGI应用程序是独立于服务器的
URL中出现字符cgi和可能出现的“?”是客户端发现使用了CGI应用程序的唯一线索。
三、隧道
Web隧道 允许用户通过HTTP连接发送非HTTP流量,这样就可以在HTTP附带其它协议数据,也就是说,可以在HTTP连接中嵌入非HTTP流量,非HTTP流量就可以穿过只允许Web流量通过的防火墙了。
web隧道是用HTTP的CONNECT方法建立起来的。
3.1 数据隧道和连接管理
隧道一旦建立起了,数据就可以在任意时间流向任意方向。隧道的两端必须做好任意时间接收数据的准备,并且需要将数据立即转发出去。
因为隧道仅仅是进行数据的转发,对于数据之间的关系和顺序不能做任何假设和干预,而且有可能转发的数据之间存在有依赖关系,所以隧道不能忽略任何数据,而且要按照原顺序做及时转发,否则可能出现数据问题。如果数据的消费端出现数据消耗不足,就可能造成生成者这端的挂起。
3.2 SSL隧道
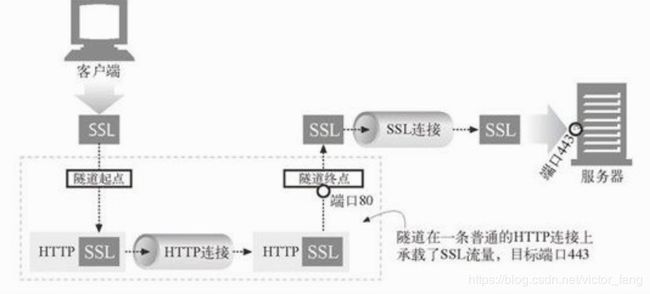
SSL协议,其信息是加密的,虽然我们一般可以通过443端口直接进行SSL连接,但是无法通过传统的有HTTP防火墙的代理服务器转发。这个时候可以利用隧道通过一条 HTTP 连接来传输 SSL 流量,以穿过端口 80 的 HTTP 防火墙。
通过HTTP隧道建立SSL连接的过程如下:
四 中继
HTTP 中继(relay)是没有完全遵循 HTTP 规范的简单 HTTP 代理。中继负责处理 HTTP 中建立连接的部分,然后对字节进行盲转发。
所以中继的优点是实现简单,当我们只是提供一个简单的过滤、诊断或内容转换功能的代理的时候,可以考虑使用中继。但是由于其盲转发的特性,所以会引起很多互操作性的问题(如Connection首部等)。
注:简单的中继通常不会期待同一条连接上还会有另一条请求到达。
五 Web机器人
Web机器人 是能够在无需人类干预的情况下自动进行一系列 Web事物处理的软件程序。很多机器人会从一个Web站点逛到另一个Web站点,获取内容,跟踪超链接,并对它们找到的数据进行处理。如果一个Web站点有 robots.txt文件,那么在访问这个Web站点上的任意URL之前,机器人都必须去获取它并对其进行处理。由主机名和端口号定义的整个Web站点仅有一个 robots.txt资源。如果站点是虚拟主机,每个虚拟的docroot都可以有一个 robots.txt文件。
获取robots.txt
机器人会用HTTP的GET方法来获取robots.txt资源,就像获取Web服务器上所有其他资源一样,机器人应该在 From首部 和 User-Agent首部 中传输标识信息,以帮助站点管理员对机器人的访问进行跟踪。
# 例子: GET / robots.txt HTTP / 1.0 HOST:www.example.com User-Agent:Slurp / 2.0 Date:Web Oct 3 23:30:EST
响应码和状态码:
机器人会根据对robots.txt检索结果采取不同方案。
- 2xx:机器人对内容进行解析,并使用排斥规则从那个站点上获取内容;
- 404:机器人认为服务器没有任何排斥规则,对次站点的访问不受robots.txt限制;
- 401 / 403:机器人认为对此站点访问完全受限;
- 503:机器人会推迟对此站点的访问,知道可以获取资源为止;
- 3xx:如果服务器相应说明是重定向,机器人就应该跟着重定向,直到找到资源为止;
robots.txt文件格式:
文件中有三种类型行:空行、注释行和规则行。
- User - Agent:Slurp 允许机器人Slurp访问;
- User - Agent:Webcrawler 允许机器人Webcrawler访问;
- DisAllow: / private 访问除了private子目录;
- DisAllow: 阻止其它机器人访问该站点任何内容
# # 例子:robots.txt for Discuz! X3 # User-agent: * Disallow: /api/ Disallow: /data/ Disallow: /source/ Disallow: /install/ Disallow: /template/ Disallow: /config/ Disallow: /uc_client/ Disallow: /uc_server/ Disallow: /static/ Disallow: /admin.php Disallow: /search.php Disallow: /member.php Disallow: /api.php Disallow: /misc.php Disallow: /connect.php Disallow: /forum.php?mod=redirect* Disallow: /forum.php?mod=post* Disallow: /home.php?mod=spacecp* Disallow: /userapp.php?mod=app&* Disallow: /*?mod=misc* Disallow: /*?mod=attachment* Disallow: /*mobile=yes*
机器人的META标签:
NOINDEX:告诉机器人不要对页面的内容进行处理;
"ROBOTS" CONTENT = "NOINDEX">
NOFOLLOW:告诉机器人不要爬行这个页面的任务外链;
"ROBOTS" COMEN = "NOFOLLOW">