ENAS代码解读
ENAS代码解读
参考代码:https://github.com/TDeVries/enas_pytorch
数据集:cifar10
main函数:
def main():
global args
np.random.seed(args.seed)
torch.cuda.manual_seed(args.seed)
if args.fixed_arc:
sys.stdout = Logger(filename='logs/' + args.output_filename + '_fixed.log')
else:
sys.stdout = Logger(filename='logs/' + args.output_filename + '.log')
print(args)
data_loaders = load_datasets()
controller = Controller(search_for=args.search_for,
search_whole_channels=True,
num_layers=args.child_num_layers,
num_branches=args.child_num_branches,
out_filters=args.child_out_filters,
lstm_size=args.controller_lstm_size,
lstm_num_layers=args.controller_lstm_num_layers,
tanh_constant=args.controller_tanh_constant,
temperature=None,
skip_target=args.controller_skip_target,
skip_weight=args.controller_skip_weight)
controller = controller.cuda()
shared_cnn = SharedCNN(num_layers=args.child_num_layers,
num_branches=args.child_num_branches,
out_filters=args.child_out_filters,
keep_prob=args.child_keep_prob)
shared_cnn = shared_cnn.cuda()
# https://github.com/melodyguan/enas/blob/master/src/utils.py#L218
controller_optimizer = torch.optim.Adam(params=controller.parameters(),
lr=args.controller_lr,
betas=(0.0, 0.999),
eps=1e-3)
# https://github.com/melodyguan/enas/blob/master/src/utils.py#L213
shared_cnn_optimizer = torch.optim.SGD(params=shared_cnn.parameters(),
lr=args.child_lr_max,
momentum=0.9,
nesterov=True,
weight_decay=args.child_l2_reg)
# https://github.com/melodyguan/enas/blob/master/src/utils.py#L154
shared_cnn_scheduler = CosineAnnealingLR(optimizer=shared_cnn_optimizer,
T_max=args.child_lr_T,
eta_min=args.child_lr_min)
if args.resume:
if os.path.isfile(args.resume):
print("Loading checkpoint '{}'".format(args.resume))
checkpoint = torch.load(args.resume)
start_epoch = checkpoint['epoch']
# args = checkpoint['args']
shared_cnn.load_state_dict(checkpoint['shared_cnn_state_dict'])
controller.load_state_dict(checkpoint['controller_state_dict'])
shared_cnn_optimizer.load_state_dict(checkpoint['shared_cnn_optimizer'])
controller_optimizer.load_state_dict(checkpoint['controller_optimizer'])
shared_cnn_scheduler.optimizer = shared_cnn_optimizer # Not sure if this actually works
print("Loaded checkpoint '{}' (epoch {})"
.format(args.resume, checkpoint['epoch']))
else:
raise ValueError("No checkpoint found at '{}'".format(args.resume))
else:
start_epoch = 0
if not args.fixed_arc:
train_enas(start_epoch,
controller,
shared_cnn,
data_loaders,
shared_cnn_optimizer,
controller_optimizer,
shared_cnn_scheduler)
else:
assert args.resume != '', 'A pretrained model should be used when training a fixed architecture.'
train_fixed(start_epoch,
controller,
shared_cnn,
data_loaders)
再来看看Controller类的init
class Controller(nn.Module):
'''
https://github.com/melodyguan/enas/blob/master/src/cifar10/general_controller.py
'''
def __init__(self,
search_for="macro",
search_whole_channels=True,
num_layers=12,
num_branches=6,
out_filters=36,
lstm_size=32,
lstm_num_layers=2,
tanh_constant=1.5,
temperature=None,
skip_target=0.4,
skip_weight=0.8):
super(Controller, self).__init__()
self.search_for = search_for # macro
self.search_whole_channels = search_whole_channels # True
self.num_layers = num_layers # 12
self.num_branches = num_branches # 6
self.out_filters = out_filters # 36
self.lstm_size = lstm_size # 64
self.lstm_num_layers = lstm_num_layers # 1
self.tanh_constant = tanh_constant # 1.5
self.temperature = temperature # None
self.skip_target = skip_target # 0.4
self.skip_weight = skip_weight # 0.8
self._create_params()
num_layer为12代表最终生成12层的网络,num_branches为6代表6组操作:3x3,5x5正常卷积层,3x3,5x5深度分离卷积层,平均池化和最大池化,
再看Controller的 _create_params(self)函数:
def _create_params(self):
'''
https://github.com/melodyguan/enas/blob/master/src/cifar10/general_controller.py#L83
'''
self.w_lstm = nn.LSTM(input_size=self.lstm_size,
hidden_size=self.lstm_size,
num_layers=self.lstm_num_layers)
self.g_emb = nn.Embedding(1, self.lstm_size) # Learn the starting input
if self.search_whole_channels:
self.w_emb = nn.Embedding(self.num_branches, self.lstm_size)
self.w_soft = nn.Linear(self.lstm_size, self.num_branches, bias=False)
else:
assert False, "Not implemented error: search_whole_channels = False"
self.w_attn_1 = nn.Linear(self.lstm_size, self.lstm_size, bias=False)
self.w_attn_2 = nn.Linear(self.lstm_size, self.lstm_size, bias=False)
self.v_attn = nn.Linear(self.lstm_size, 1, bias=False)
self._reset_params()
没啥好解释的,这里值得注意的是第九行,controller的初始输入为1的embbeding:
self.g_emb = nn.Embedding(1, self.lstm_size)
重点看看forward()函数:
def forward(self):
'''
https://github.com/melodyguan/enas/blob/master/src/cifar10/general_controller.py#L126
'''
h0 = None # setting h0 to None will initialize LSTM state with 0s
anchors = []
anchors_w_1 = []
arc_seq = {}
entropys = []
log_probs = []
skip_count = []
skip_penaltys = []
inputs = self.g_emb.weight
# print('cccccccccccccccc')
# print(inputs)
# print(inputs.shape)
# import sys
# sys.exit()
skip_targets = torch.tensor([1.0 - self.skip_target, self.skip_target]).cuda()
for layer_id in range(self.num_layers):
if self.search_whole_channels:
inputs = inputs.unsqueeze(0)
output, hn = self.w_lstm(inputs, h0)
output = output.squeeze(0)
h0 = hn
logit = self.w_soft(output)
if self.temperature is not None:
logit /= self.temperature
if self.tanh_constant is not None:
logit = self.tanh_constant * torch.tanh(logit)
branch_id_dist = Categorical(logits=logit)
branch_id = branch_id_dist.sample()
arc_seq[str(layer_id)] = [branch_id]
log_prob = branch_id_dist.log_prob(branch_id)
log_probs.append(log_prob.view(-1))
entropy = branch_id_dist.entropy()
entropys.append(entropy.view(-1))
inputs = self.w_emb(branch_id)
inputs = inputs.unsqueeze(0)
else:
# https://github.com/melodyguan/enas/blob/master/src/cifar10/general_controller.py#L171
assert False, "Not implemented error: search_whole_channels = False"
output, hn = self.w_lstm(inputs, h0)
output = output.squeeze(0)
if layer_id > 0:
query = torch.cat(anchors_w_1, dim=0)
query = torch.tanh(query + self.w_attn_2(output))
query = self.v_attn(query)
logit = torch.cat([-query, query], dim=1)
if self.temperature is not None:
logit /= self.temperature
if self.tanh_constant is not None:
logit = self.tanh_constant * torch.tanh(logit)
skip_dist = Categorical(logits=logit)
skip = skip_dist.sample()
skip = skip.view(layer_id)
arc_seq[str(layer_id)].append(skip)
skip_prob = torch.sigmoid(logit)
kl = skip_prob * torch.log(skip_prob / skip_targets)
kl = torch.sum(kl)
skip_penaltys.append(kl)
log_prob = skip_dist.log_prob(skip)
log_prob = torch.sum(log_prob)
log_probs.append(log_prob.view(-1))
entropy = skip_dist.entropy()
entropy = torch.sum(entropy)
entropys.append(entropy.view(-1))
# Calculate average hidden state of all nodes that got skips
# and use it as input for next step
skip = skip.type(torch.float)
skip = skip.view(1, layer_id)
skip_count.append(torch.sum(skip))
inputs = torch.matmul(skip, torch.cat(anchors, dim=0))
inputs /= (1.0 + torch.sum(skip))
else:
inputs = self.g_emb.weight
anchors.append(output)
anchors_w_1.append(self.w_attn_1(output))
self.sample_arc = arc_seq
entropys = torch.cat(entropys)
self.sample_entropy = torch.sum(entropys)
log_probs = torch.cat(log_probs)
self.sample_log_prob = torch.sum(log_probs)
skip_count = torch.stack(skip_count)
self.skip_count = torch.sum(skip_count)
skip_penaltys = torch.stack(skip_penaltys)
self.skip_penaltys = torch.mean(skip_penaltys)
32-35行及61至64行对应的是论文Training details里描述的:我们将tanh常数2.5和温度5.0应用于控制器的logits,并将控制器样本的熵添加到奖励中,权重为0.1。
37-38行是按logit的概率进行采样,返回采样的index。
42行log_prob解释(https://pytorch.org/docs/stable/distributions.html#torch.distributions.categorical.Categorical.log_prob):
当概率密度函数的参数可微时,我们只需要sample()和log_prob()来实现REINFORCE:
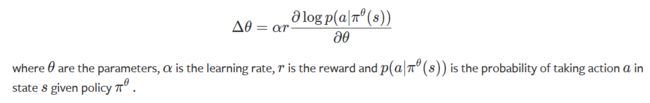
在实践中,我们将从网络的输出中取样一个操作,将该操作应用到环境中,然后使用log_prob构造一个等效的损失函数。注意,我们使用了一个负数,因为优化器使用梯度下降,而上面的规则假设梯度上升。有了明确的政策,实施加强的准则如下:
probs = policy_network(state)
# Note that this is equivalent to what used to be called multinomial
m = Categorical(probs)
action = m.sample()
next_state, reward = env.step(action)
loss = -m.log_prob(action) * reward
loss.backward()
接下来42-45将控制器的样本熵添加到奖励中,然后把被采样的branch_id(对应于上面描述的6个卷积,池化等操作),再把branch_id embbeding一下,得到下一时刻LSTM的输入。
72-75行对应的论文里Training details里描述的:在宏搜索空间中,我们通过增加两层之间的KL散度来增强跳跃连接的稀疏性:1)任意两层之间的跳跃连接概率;2)我们选择的概率ρ=0.4,它表示形成跳跃连接的先验信念。这个KL发散项的权重是0.8。
KL散度公式:

57-59行为attention。
60行是为了形成0,1分类,
接下来再看看ShareCNN( )代码:
先看 init()函数:
class SharedCNN(nn.Module):
def __init__(self,
num_layers=12,
num_branches=6,
out_filters=24,
keep_prob=1.0,
fixed_arc=None
):
super(SharedCNN, self).__init__()
self.num_layers = num_layers # 12
self.num_branches = num_branches # 6
self.out_filters = out_filters # 36
self.keep_prob = keep_prob # 0.9
self.fixed_arc = fixed_arc
pool_distance = self.num_layers // 3
self.pool_layers = [pool_distance - 1, 2 * pool_distance - 1]
self.stem_conv = nn.Sequential(
nn.Conv2d(3, out_filters, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_filters, track_running_stats=False))
self.layers = nn.ModuleList([])
self.pooled_layers = nn.ModuleList([])
for layer_id in range(self.num_layers):
if self.fixed_arc is None:
layer = ENASLayer(layer_id, self.out_filters, self.out_filters)
else:
layer = FixedLayer(layer_id, self.out_filters, self.out_filters, self.fixed_arc[str(layer_id)])
self.layers.append(layer)
if layer_id in self.pool_layers:
for i in range(len(self.layers)):
if self.fixed_arc is None:
self.pooled_layers.append(FactorizedReduction(self.out_filters, self.out_filters))
else:
self.pooled_layers.append(FactorizedReduction(self.out_filters, self.out_filters * 2))
if self.fixed_arc is not None:
self.out_filters *= 2
self.global_avg_pool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(p=1. - self.keep_prob)
self.classify = nn.Linear(self.out_filters, 10)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_uniform_(m.weight, mode='fan_in', nonlinearity='relu')
注意17-18行,第3,7层为pool layer。20-22行输入经过一个3x3卷积和BatchNorm层,再进入网络架构搜索模块。当fixed_arc为None时,调用ENASLayer()函数,代码如下:
class ENASLayer(nn.Module):
'''
https://github.com/melodyguan/enas/blob/master/src/cifar10/general_child.py#L245
'''
def __init__(self, layer_id, in_planes, out_planes):
super(ENASLayer, self).__init__()
self.layer_id = layer_id
self.in_planes = in_planes
self.out_planes = out_planes
self.branch_0 = ConvBranch(in_planes, out_planes, kernel_size=3)
self.branch_1 = ConvBranch(in_planes, out_planes, kernel_size=3, separable=True)
self.branch_2 = ConvBranch(in_planes, out_planes, kernel_size=5)
self.branch_3 = ConvBranch(in_planes, out_planes, kernel_size=5, separable=True)
self.branch_4 = PoolBranch(in_planes, out_planes, 'avg')
self.branch_5 = PoolBranch(in_planes, out_planes, 'max')
self.bn = nn.BatchNorm2d(out_planes, track_running_stats=False)
def forward(self, x, prev_layers, sample_arc):
layer_type = sample_arc[0]
if self.layer_id > 0:
skip_indices = sample_arc[1]
else:
skip_indices = []
if layer_type == 0:
out = self.branch_0(x)
elif layer_type == 1:
out = self.branch_1(x)
elif layer_type == 2:
out = self.branch_2(x)
elif layer_type == 3:
out = self.branch_3(x)
elif layer_type == 4:
out = self.branch_4(x)
elif layer_type == 5:
out = self.branch_5(x)
else:
raise ValueError("Unknown layer_type {}".format(layer_type))
for i, skip in enumerate(skip_indices):
if skip == 1:
out += prev_layers[i]
out = self.bn(out)
return out
branch_0 — branch_5分别为3x3正常卷积,3x3分离卷积,5x5正常卷积,5x5分离卷积,平均池化,最大池化。
回到ShareCNN的init函数,当layer_id为3,7时,后面还要加上一个Reduction层,及FactorizedReduction()函数。
FactorizedReduction函数代码:
class FactorizedReduction(nn.Module):
'''
Reduce both spatial dimensions (width and height) by a factor of 2, and
potentially to change the number of output filters
https://github.com/melodyguan/enas/blob/master/src/cifar10/general_child.py#L129
'''
def __init__(self, in_planes, out_planes, stride=2):
super(FactorizedReduction, self).__init__()
assert out_planes % 2 == 0, (
"Need even number of filters when using this factorized reduction.")
self.in_planes = in_planes
self.out_planes = out_planes
self.stride = stride
if stride == 1:
self.fr = nn.Sequential(
nn.Conv2d(in_planes, out_planes, kernel_size=1, bias=False),
nn.BatchNorm2d(out_planes, track_running_stats=False))
else:
self.path1 = nn.Sequential(
nn.AvgPool2d(1, stride=stride),
nn.Conv2d(in_planes, out_planes // 2, kernel_size=1, bias=False))
self.path2 = nn.Sequential(
nn.AvgPool2d(1, stride=stride),
nn.Conv2d(in_planes, out_planes // 2, kernel_size=1, bias=False))
self.bn = nn.BatchNorm2d(out_planes, track_running_stats=False)
def forward(self, x):
if self.stride == 1:
return self.fr(x)
else:
path1 = self.path1(x)
# pad the right and the bottom, then crop to include those pixels
path2 = F.pad(x, pad=(0, 1, 0, 1), mode='constant', value=0.)
path2 = path2[:, :, 1:, 1:]
path2 = self.path2(path2)
out = torch.cat([path1, path2], dim=1)
out = self.bn(out)
return out
代码逻辑很简洁,没啥好介绍的。
接下来看train_eans( )函数:
def train_enas(start_epoch,
controller,
shared_cnn,
data_loaders,
shared_cnn_optimizer,
controller_optimizer,
shared_cnn_scheduler):
"""Perform architecture search by training a controller and shared_cnn.
Args:
start_epoch: Epoch to begin on.
controller: Controller module that generates architectures to be trained.
shared_cnn: CNN that contains all possible architectures, with shared weights.
data_loaders: Dict containing data loaders.
shared_cnn_optimizer: Optimizer for the shared_cnn.
controller_optimizer: Optimizer for the controller.
shared_cnn_scheduler: Learning rate schedular for shared_cnn_optimizer
Returns: Nothing.
"""
baseline = None
for epoch in range(start_epoch, args.num_epochs):
train_shared_cnn(epoch,
controller,
shared_cnn,
data_loaders,
shared_cnn_optimizer)
baseline = train_controller(epoch,
controller,
shared_cnn,
data_loaders,
controller_optimizer,
baseline)
if epoch % args.eval_every_epochs == 0:
evaluate_model(epoch, controller, shared_cnn, data_loaders)
shared_cnn_scheduler.step(epoch)
state = {'epoch': epoch + 1,
'args': args,
'shared_cnn_state_dict': shared_cnn.state_dict(),
'controller_state_dict': controller.state_dict(),
'shared_cnn_optimizer': shared_cnn_optimizer.state_dict(),
'controller_optimizer': controller_optimizer.state_dict()}
filename = 'checkpoints/' + args.output_filename + '.pth.tar'
torch.save(state, filename)
先固定Controller,训练ShareCNN,再固定ShareCNN,训练Controller,迭代进行。
train_share_cnn()函数:
def train_shared_cnn(epoch,
controller,
shared_cnn,
data_loaders,
shared_cnn_optimizer,
fixed_arc=None):
"""Train shared_cnn by sampling architectures from the controller.
Args:
epoch: Current epoch.
controller: Controller module that generates architectures to be trained.
shared_cnn: CNN that contains all possible architectures, with shared weights.
data_loaders: Dict containing data loaders.
shared_cnn_optimizer: Optimizer for the shared_cnn.
fixed_arc: Architecture to train, overrides the controller sample
...
Returns: Nothing.
"""
global vis_win
controller.eval()
if fixed_arc is None:
# Use a subset of the training set when searching for an arhcitecture
train_loader = data_loaders['train_subset']
else:
# Use the full training set when training a fixed architecture
train_loader = data_loaders['train_dataset']
train_acc_meter = AverageMeter()
loss_meter = AverageMeter()
for i, (images, labels) in enumerate(train_loader):
start = time.time()
images = images.cuda()
labels = labels.cuda()
if fixed_arc is None:
with torch.no_grad():
controller() # perform forward pass to generate a new architecture
sample_arc = controller.sample_arc
else:
sample_arc = fixed_arc
shared_cnn.zero_grad()
pred = shared_cnn(images, sample_arc)
loss = nn.CrossEntropyLoss()(pred, labels)
loss.backward()
grad_norm = torch.nn.utils.clip_grad_norm_(shared_cnn.parameters(), args.child_grad_bound)
shared_cnn_optimizer.step()
train_acc = torch.mean((torch.max(pred, 1)[1] == labels).type(torch.float))
train_acc_meter.update(train_acc.item())
loss_meter.update(loss.item())
end = time.time()
if (i) % args.log_every == 0:
learning_rate = shared_cnn_optimizer.param_groups[0]['lr']
display = 'epoch=' + str(epoch) + \
'\tch_step=' + str(i) + \
'\tloss=%.6f' % (loss_meter.val) + \
'\tlr=%.4f' % (learning_rate) + \
'\t|g|=%.4f' % (grad_norm) + \
'\tacc=%.4f' % (train_acc_meter.val) + \
'\ttime=%.2fit/s' % (1. / (end - start))
print(display)
controller.train()
先用Controller sample出一个子模型,然后进行训练,然后记录acc。
train_controller代码:
def train_controller(epoch,
controller,
shared_cnn,
data_loaders,
controller_optimizer,
baseline=None):
"""Train controller to optimizer validation accuracy using REINFORCE.
Args:
epoch: Current epoch.
controller: Controller module that generates architectures to be trained.
shared_cnn: CNN that contains all possible architectures, with shared weights.
data_loaders: Dict containing data loaders.
controller_optimizer: Optimizer for the controller.
baseline: The baseline score (i.e. average val_acc) from the previous epoch
Returns:
baseline: The baseline score (i.e. average val_acc) for the current epoch
For more stable training we perform weight updates using the average of
many gradient estimates. controller_num_aggregate indicates how many samples
we want to average over (default = 20). By default PyTorch will sum gradients
each time .backward() is called (as long as an optimizer step is not taken),
so each iteration we divide the loss by controller_num_aggregate to get the
average.
https://github.com/melodyguan/enas/blob/master/src/cifar10/general_controller.py#L270
"""
print('Epoch ' + str(epoch) + ': Training controller')
# global vis_win
shared_cnn.eval()
valid_loader = data_loaders['valid_subset']
reward_meter = AverageMeter()
baseline_meter = AverageMeter()
val_acc_meter = AverageMeter()
loss_meter = AverageMeter()
controller.zero_grad()
for i in range(args.controller_train_steps * args.controller_num_aggregate):
start = time.time()
images, labels = next(iter(valid_loader))
images = images.cuda()
labels = labels.cuda()
controller() # perform forward pass to generate a new architecture
sample_arc = controller.sample_arc
with torch.no_grad():
pred = shared_cnn(images, sample_arc)
val_acc = torch.mean((torch.max(pred, 1)[1] == labels).type(torch.float))
# detach to make sure that gradients aren't backpropped through the reward
reward = torch.tensor(val_acc.detach())
reward += args.controller_entropy_weight * controller.sample_entropy
if baseline is None:
baseline = val_acc
else:
baseline -= (1 - args.controller_bl_dec) * (baseline - reward)
# detach to make sure that gradients are not backpropped through the baseline
baseline = baseline.detach()
loss = -1 * controller.sample_log_prob * (reward - baseline)
if args.controller_skip_weight is not None:
loss += args.controller_skip_weight * controller.skip_penaltys
reward_meter.update(reward.item())
baseline_meter.update(baseline.item())
val_acc_meter.update(val_acc.item())
loss_meter.update(loss.item())
# Average gradient over controller_num_aggregate samples
loss = loss / args.controller_num_aggregate
loss.backward(retain_graph=True)
end = time.time()
# Aggregate gradients for controller_num_aggregate iterationa, then update weights
if (i + 1) % args.controller_num_aggregate == 0:
grad_norm = torch.nn.utils.clip_grad_norm_(controller.parameters(), args.child_grad_bound)
controller_optimizer.step()
controller.zero_grad()
if (i + 1) % (2 * args.controller_num_aggregate) == 0:
learning_rate = controller_optimizer.param_groups[0]['lr']
display = 'ctrl_step=' + str(i // args.controller_num_aggregate) + \
'\tloss=%.3f' % (loss_meter.val) + \
'\tent=%.2f' % (controller.sample_entropy.item()) + \
'\tlr=%.4f' % (learning_rate) + \
'\t|g|=%.4f' % (grad_norm) + \
'\tacc=%.4f' % (val_acc_meter.val) + \
'\tbl=%.2f' % (baseline_meter.val) + \
'\ttime=%.2fit/s' % (1. / (end - start))
print(display)
shared_cnn.train()
return baseline
用强化学习训练,用采样子模型的acc和控制器熵添作为reward,熵权重为0.1,为了减少方差,reward减去一个baseline,baseline为reward的移动平均基线。然后用策略梯度公式更新controller。66行为计算强化学习loss。68-69行为把前面提到的KL作为损失加入进loss里,以增强跳跃连接的稀疏性。加个负号后反向传播loss,用梯度下降更新模型。
补充:
得分函数
当概率密度函数相对于其参数可微分时, 我们只需要sample()和log_prob()来实现REINFORCE:
![]()
![]() 是参数,
是参数, ![]() 是学习速率,
是学习速率, ![]() 是奖励 并且
是奖励 并且 ![]() 是在状态
是在状态 ![]() 以及给定策略
以及给定策略 ![]() 执行动作
执行动作 ![]() 的概率.
的概率.
在实践中, 我们将从网络输出中采样一个动作, 将这个动作应用于一个环境中, 然后使用log_prob构造一个等效的损失函数. 请注意, 我们使用负数是因为优化器使用梯度下降, 而上面的规则假设梯度上升. 有了确定的策略, REINFORCE的实现代码如下:
probs = policy_network(state)
# Note that this is equivalent to what used to be called multinomial
m = Categorical(probs)
action = m.sample()
next_state, reward = env.step(action)
loss = -m.log_prob(action) * reward
loss.backward()
转存中…(img-vAU4Xiu8-1594179710154)]
[外链图片转存中…(img-2SQqq9RE-1594179710155)] 是参数, [外链图片转存中…(img-XItub8OJ-1594179710156)] 是学习速率, [外链图片转存中…(img-7in5zxVt-1594179710156)] 是奖励 并且 [外链图片转存中…(img-0pFmPxGF-1594179710157)] 是在状态 [外链图片转存中…(img-hHi0NgtV-1594179710157)] 以及给定策略 [外链图片转存中…(img-lTprVpkz-1594179710157)]执行动作 [外链图片转存中…(img-x22cUOjD-1594179710158)] 的概率.
在实践中, 我们将从网络输出中采样一个动作, 将这个动作应用于一个环境中, 然后使用log_prob构造一个等效的损失函数. 请注意, 我们使用负数是因为优化器使用梯度下降, 而上面的规则假设梯度上升. 有了确定的策略, REINFORCE的实现代码如下:
probs = policy_network(state)
# Note that this is equivalent to what used to be called multinomial
m = Categorical(probs)
action = m.sample()
next_state, reward = env.step(action)
loss = -m.log_prob(action) * reward
loss.backward()