python实现成语接龙接到指定成语(一个顶俩的扩展版)
昨天找到了新华字典的json就很开心,想到了一个顶俩那个项目,自己也想做一个接到口谐辞给。(因为没有给字开头的成语)
思路
算法过程其实很简单,就是广搜就可以,使用队列这个数据结构,每次pop一个,然后push进来一组当前读音的扩展。在此基础上进行广搜遍历,然后当满足输入要求的时候就停止。
扩展包
-
pypinyin
扩展包地址传送门 -
unicodedata anaconda好像自带?我这里可以直接import
成语词典数据来源
https://github.com/mozillazg/python-pinyin
嫌GitHub慢的也可去
http://ggalaxy.top/file/idiom.json自取
代码
import json
import pypinyin
import unicodedata
#广搜,用队列
flag = 0
def judge(a,b):
if(unicodedata.normalize('NFKD', pypinyin.lazy_pinyin(a)[0]).encode('ascii','ignore') == unicodedata.normalize('NFKD', pypinyin.lazy_pinyin(b)[0]).encode('ascii','ignore')):
return True
else:
return False
def display(c):#传进来一个字符串
list_play = c.split("+")
#print(list_play)
for i in range(len(list_play)-1):
print("第"+str(i)+"个成语:",end = "")
print(file_json[int(list_play[i])]["word"])
def degrade(a):#数据降维
b = str(a)
b = b.replace('[','')
b = b.replace(']','')
b = b.replace("'",'')
#print(b)
a = b.split(",")
return a
def search_idiom(p):
#进来一个拼音,返回一个list,是以传进来的拼音结尾的
global flag
ans1=[]
ans2=[]
for iiii in range(l):#json
ll = len(file_json[iiii]["word"])
#print(file_json[iiii]["pinyin"].split(" "))
if(judge(file_json[iiii]["pinyin"].split(" ")[-1] ,p)):
#print(file_json[iiii]["pinyin"].split(" ")[0])
ans1.append(file_json[iiii]["pinyin"].split(" ")[0].replace("'",""))#返回首字的拼音和索引
ans2.append(str(iiii)+"+")
if(judge(file_json[iiii]["pinyin"].split(" ")[0],pinyin2)):
flag = 1
#print(ans1,ans2)
return ans1,ans2
#print(ans1)
return ans1,ans2
def traverse(list_idiom,list_index):
idiom_tmp = degrade(list_idiom)
index_tmp = degrade(list_index)
#print(idiom_tmp)
global dp
global index
global flag
#l = len(np.array(list_idiom).shape)
l_tmp = len(idiom_tmp)
for i in range(l_tmp):
tmp1,tmp2 = search_idiom(idiom_tmp[i])
for j in range(len(tmp1)):
#print(tmp2[j])
tmp2[j]=tmp2[j]+index_tmp[i]
#print(tmp2[j])
if(flag !=0):
#print(tmp2[i])
print("成功了")
flag =1;
display(tmp2[-1])
break
if(len(tmp1)>0):
dp.append(tmp1)
#print(dp)
if(len(tmp2)>0):
index.append(tmp2)
file = open("H:/2020/idiom/idiom.json","rb")
file_json = json.load(file)
l = len(file_json)
while(1):
s = input("想要接龙到的成语(输入exit退出程序):")
if(s == ""):
continue
if(s == "exit"):
break
pinyin1 = pypinyin.pinyin(s)[0][0]#
#print(pinyin1)
while(1):
e = input("开始的成语(exit退出到上一级):")
if(e == ""):
continue
if(e == "exit"):
break
pinyin2 = pypinyin.pinyin(e)[-1][0]
#print(pinyin2)
#转为拼音
dp=[]#核心要维护的队列
index = []#对应dp的队列
dp.append(pinyin1)
index.append("")
times = 0
flag = 0
while(times < 10 and flag == 0):
for ii in range(len(dp)):
traverse(dp.pop(0),index.pop(0))
if(len(dp) == 0):
#print("dp=0")
flag =1
times+=1
print("第"+str(times)+"轮广搜查询")
# if(len(index)>0):
# for ij in range(len(index)):
# for ji in range(len(index[ij])):
# display(index[ij][ji])
# print("-------------------------------------\n")
强调
- 除了要维护一个子扩展的拼音队列外,还需要维护一个索引队列,size和拼音队列相等,在地下的代码里面分别是dp[]和index[],索引队列用与在找到答案之后的返回,我使用字符串拼接然后split的方法。效果不错。
- 一定要删除掉空的查询结果,不然你的数组会无穷大。。。。
效果
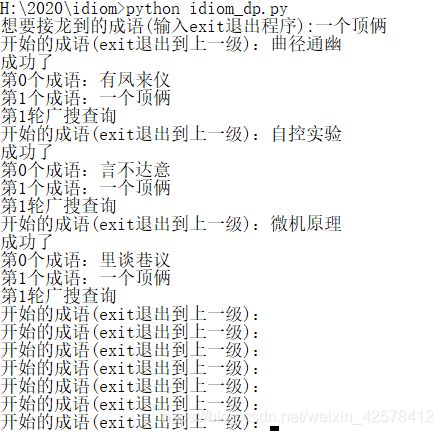
能算出来是真的
不过速度真的很慢,一般两轮以内能找到还行,轮次高了就很慢。
我寻思着深搜会不会更快?不过讲道理,一般人想到成语接龙要接到指定的成语肯定是先想着广搜吧,不可能一条道走到黑。
或者还有更好的搜索方法
