绝对有效的B站爬虫
B站爬虫
- 关于爬虫
- B站爬虫
关于爬虫
之前学习爬虫的时候,研究过如何爬一些知名网站,在这里就先说爬B经验(第一次写博客,可能有一些不好的地方,见谅)。
B站爬虫
B站非vip视频爬虫(https://www.bilibili.com/video/BV1KZ4y1j7rP):
1.进入b站右键打开源代码;
2.查找视频url,在源代码中视频网址是以键值对的方式来显示的,而键一般为"url",“baseUrl”,"backupUrl"这三种,所以查找看有没有以他们开头的键值对,而值就是这个视频的网址,但是如果访问是不成功的,因为需要携带一些参数
![]()
3.再次进入b站打开调试模式(F12);
4. 进入Network,选择其中一个有cookie或者referer的请求;
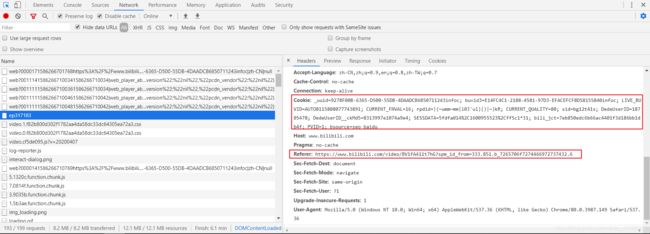
5. 打开代码填入数据,其中需要cookie,referer和网站的url,但是url只能取?前面的部分,如:(https://www.bilibili.com/video/BV1KZ4y1j7rP?spm_id_from=333.851.b_7265706f7274466972737432.8)/(https://www.bilibili.com/video/BV1KZ4y1j7rP);
import requests
import re
import random
class BLBL(object):
def __init__(self, url, cookie, referer):
# 需要爬取的网页前缀 例如:https://www.bilibili.com/video/av49035382 ?from=search&seid=1058195128616882249
self.base_url = url
# cookie内容
self.cookie = cookie
# referer内容
self.referer = referer
# 请求头信息
self.accept = 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3'
self.accept_Encoding = 'gzip, deflate, br'
self.accept_Language = 'zh-CN,zh;q=0.9,en;q=0.8'
self.user_agent = "User-Agent:Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) "
def html(self):
# 访问起始网页需添加的请求头,不加的话,得不到完整的源代码(反爬)
base_headers = {
'Accept': self.accept,
'Accept-Encoding': self.accept_Encoding,
'Accept-Language': self.accept_Language,
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Cookie': self.cookie,
'Host': 'www.bilibili.com',
'Referer': self.referer,
'Upgrade-Insecure-Requests': '1',
'User-Agent': self.user_agent
}
# 请求网页
base_response = requests.get(self.base_url, headers=base_headers)
print(base_headers)
# 获取网页html代码
html = base_response.text
# print(html.headers)
return html
def xin_xi(self, html):
print(html)
try:
# 获取视频名称
video_name = re.search('(.+) ', html, re.S).group(1) + '.flv'
except:
# 如果获取失败,就随机一个名字
video_name = str(random.randint(100000,1000000))+'.flv'
print(video_name)
# 获取视频链接
download_url = re.search(r'("url":"|"baseUrl":"|"backupUrl":\[")(.+?)("|"])', html, re.S).group(2)
print(download_url,111)
# 获取主机信息
host = re.search(r'//(.+\.com)', download_url, re.S).group(1)
print(host)
return video_name, download_url, host
def video(self, html):
# 获取视频名称,视频网址,主机
video_name, download_url, host = self.xin_xi(html)
# 请求视频下载地址时需要添加的请求头
download_headers = {
'User-Agent': self.user_agent,
'Referer': self.referer,
'Origin': 'https://www.bilibili.com',
'Host': host,
'Accept': self.accept,
'Accept-Encoding': self.accept_Encoding,
'Accept-Language': self.accept_Language
}
a = ['1.195.11.157:21158',
'121.20.53.252:15060',
'125.111.118.224:19365',
'121.230.211.50:18537',
'106.226.239.28:20426',
'106.9.171.20:20621',
'220.248.157.204:18528',
'117.81.173.226:17273',
'171.12.176.88:21839',
'125.105.49.23:20986'
]
proxies = {'http':a[random.randint(0,len(a)-1)],
"https":a[random.randint(0,len(a)-1)]}
# 获取视频资源,并写入文件
with open(video_name, 'wb') as f:
f.write(requests.get(download_url, headers=download_headers, stream=True, verify=False).content)
def run(self):
html = self.html()
self.video(html)
print('爬取成功')
if __name__ == '__main__':
url = "https://www.bilibili.com/video/BV1KZ4y1j7rP"
cookie = "_uuid=9278F00B-6365-D500-55DB-4DAADCB6850711243infoc; buvid3=E14FC4C1-2188-4581-97D3-EFACEFCF8D58155840infoc; LIVE_BUVID=AUTO8115808077743891; CURRENT_FNVAL=16; rpdid=|(~umm~mm|l0J'ul)|)|~)kR; CURRENT_QUALITY=80; sid=bg12t41s; DedeUserID=18705478; DedeUserID__ckMd5=8313997e1074a9e4; SESSDATA=5fdfa014%2C1600955523%2Cff5c1*31; bili_jct=7eb850edc6b66ac4401f3d186bb1db4f; PVID=1; bsource=seo_baidu"
referer = "https://www.bilibili.com/video/BV1KZ4y1j7rP?spm_id_from=333.851.b_7265706f7274466972737432.8"
blbl = BLBL(url, cookie, referer)
blbl.run()
- 运行代码如果打印爬取成功那么就完成了;
- 代码还需要运用requests,re,random模块,没有的话自行安装,视频爬取后是flv后缀结尾,可以下载爱奇艺万能播放器来播放,可能打开以后显示只有5秒,其实是完整的;
- B站vip视频普通用户是暂时没办法爬,普通用户打开vip视频和会员用户打开vip视频页面显示的源代码不一样,如果你是会员用户那么代码也能正常使用,还是只要替换url,cookie和referer就行。
如果各位喜欢的话,下次我发布一篇爱奇艺,腾讯的爬虫.