python详解(7)--异常处理与文件操作
一、python中的异常处理
try…except…else…finally语句:是最基础的异常处理语句,其中
①try:后为要测试的函数体;
②except的作用为捕捉固定类别的异常,如except ValueError as e,即表示捕捉ValueError异常(其他类型异常不捕捉),并且将异常的具体信息保存在变量e中(注意e非str,且as e可省略),并运行except语句后的自定义输入内容,except语句可以有多个,也可将多个异常用一个except语句捕捉,但注意必须添加小括号;
③else:语句后的内容是当try语句中函数体没有发生异常时运行,当被except捕捉到异常时不运行;
④finally:语句后内容无论有没有异常都会运行,放在最后。
注:①except语句运行于异常发生后,其要捕捉的异常与语句是一个条件关系,异常的具体信息被保存在变量e中,若不需要则也不会显示;
②except捕捉异常的时间是在异常发生的时间点,而不是try语句运行完,如图所示代码,会一直要求用户输入直至合法;
③注意一般最后一个except省略异常名称,即通配所有异常,然后配合单独的raise用法,将异常再抛出,允许上层处理。

raise语句:相当于自定义异常的出现条件和具体内容(一般跟在if条件之后),在某条件满足时,raise ValueError(‘xxx’),即抛出ValueError异常并且将括号内内容作为异常的具体信息,这个异常可以被except语句捕捉(若不捕捉,则系统用红字显示’xxx’),异常名可自定义,但应尽量选择合理的异常对象(自定义的异常类也应继承于python的标准异常类)。
注:有单独的raise语句用法,其一般用于except捕获后再抛出,记录自己的信息和异常具体信息,在想明确当前异常抛出但不想处理时使用。

assert语句:用于对程序在某个时候必须满足的条件进行验证,assert 条件, ‘xxx’,其中若不满足条件,则会出现AssertionError异常,且’xxx’为自定义的异常内容,可以通过except语句捕捉。(注意assert语句只在调试阶段有效,在程序运行时可以通过-O命令来关闭)
错误处理:在多重调用出现异常时会抛出错误堆栈,使用logging模块中的exception函数可以记录错误信息并且将程序继续执行并正常退出,try:…except Exception as e: logging.exception(e),则会记录并打印出错误堆栈信息,并且继续执行下面的代码。
异常的自定义:在模块中可以根据需要自定义异常类,其应该直接或间接的从Exception类中派生,一般自定义的异常类与标准异常类似都以Error结尾,且尽量简单,只添加属性,在后续使用时根据需要用raise抛出。
执行顺序:在try…except…else…finally语句中,如果try语句中发生了except语句没有捕获的异常(或者在except或else语句中发生异常),则会将finally语句内容执行完毕后抛出异常,try语句中有break/continue/return语句退出时,finally语句也会执行,实际操作中,finally一般用于释放外部资源,即断开连接。
注:①可以在except语句中使用sys.exc_info()方法来获取当前异常的内容,它返回一个由异常名、描述信息、内存位置组成的元组。
②一种常用的解耦操作:在要import的模块中自定义新异常类,捕获可能出现的由另外的模块导入的异常类并用raise抛出,在最终代码中捕获自定义的新异常类,使最终代码只与导入的模块有关,而不需要为了捕获一个异常重新导入其他模块。
python中的日志处理与logging模块:
在开发过程中的问题追踪与排查是很容易的,但是部署到生产环境中后,代码的运行过程相当于是在一个黑盒中,对于问题的追踪和处理会变得相当困难,因此需要在开发时对可能出现问题的部分进行日志记录,这样,当出现问题时可以根据产生的日志文件中的记录追踪问题的具体位置、时间和错误信息等,这就是日志记录的好处。
在简单程序调试时,可以使用print语句进行,但是对于复杂的、规整的代码,应严格按照logging的规范记录日志,在python中日志记录流程的整体框架如下:
Logger:即 Logger Main Class,是我们进行日志记录时创建的对象,我们可以调用它的方法传入日志模板和信息,来生成一条条日志记录,称作 Log Record。
Log Record:就代指生成的一条条日志记录。
Handler:即用来处理日志记录的类,它可以将 Log Record 输出到我们指定的日志位置和存储形式等,如我们可以指定将日志通过 FTP 协议记录到远程的服务器上,Handler 就会帮我们完成这些事情。
Formatter:实际上生成的 Log Record 也是一个个对象,那么我们想要把它们保存成一条条我们想要的日志文本的话,就需要有一个格式化的过程,那么这个过程就由 Formatter 来完成,返回的就是日志字符串,然后传回给 Handler 来处理。
Filter:另外保存日志的时候我们可能不需要全部保存,我们可能只需要保存我们想要的部分就可以了,所以保存前还需要进行一下过滤,留下我们想要的日志,如只保存某个级别的日志,或只保存包含某个关键字的日志等,那么这个过滤过程就交给 Filter 来完成。
Parent Handler:Handler 之间可以存在分层关系,以使得不同 Handler 之间共享相同功能的代码。
总的来说 logging 模块相比 print 有这么几个优点:
①可以在 logging 模块中设置日志等级,在不同的版本(如开发环境、生产环境)上通过设置不同的输出等级来记录对应的日志,非常灵活。
②print 的输出信息都会输出到标准输出流中,而 logging 模块就更加灵活,可以设置输出到任意位置,如写入文件、写入远程服务器等。
③logging 模块具有灵活的配置和格式化功能,如配置输出当前模块信息、运行时间等,相比 print 的字符串格式化更加方便易用。
参:https://cuiqingcai.com/6080.html。
python中的单元测试与文档测试:
单元测试(模块测试)是开发者编写的一小段代码,用于检验被测代码的一个很小的、很明确的功能是否正确。通常而言,一个单元测试是用于判断某个特定条件(或者场景)下某个特定函数的行为。
与其他测试不同,单元测试的编写使用者和受益者都是开发者,应看作是编码工作的一部分,“测试驱动开发”(TDD:Test-Driven Development)。
python中提供了unittest模块用于单元测试,单元测试模块主要是整合了测试环境准备(如数据库连接)、测试函数集合执行、测试结果处理及显示、测试后环境还原等功能,将其封装为一个模块,使单元测试代码的开发变得轻松容易。

图片引自https://blog.csdn.net/peiyao456/article/details/81542377。
python中提供了doctest模块用于文档测试,文档测试即对类/函数的文档字符串中的python交互模式代码进行测试,其前提是被测试的类/函数中有文档字符串,doctest.testmod()。
以交互模式代码编写文档字符串的好处:①告诉函数的调用者期望的输入与输出,对阅读更友好;②可以使用doctest模块提取文档字符串中的交互模式代码进行测试;③文档测试只用于测试本模块中的类/函数,因此不会对其功能造成影响。
python中pdb模块的使用:
pdb(python debugger) 是 python 自带的一个包,为 python 程序提供了一种交互的源代码调试功能,主要特性包括设置断点、单步调试、进入函数调试、查看当前代码、查看栈片段、动态改变变量的值等。
其常用命令如下:

pdb可以通过python -m pdb xxx.py进行单步执行测试,也可以在代码中需要调试的地方放置pdb.set_trace(), 程序会在pdb.set_trace()暂停并进入pdb调试环境,可以用pdb 变量名查看变量,或者c继续运行。
小结:关于测试与日志的具体操作可以在使用时查询,重点是要有测试、调试、异常处理、添加日志的思想。
二、python中的文件操作
open函数:open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
其参数如下所示:
file: 必需,文件路径(相对或者绝对路径);
mode: 可选,文件打开模式,如下所示;
buffering: 设置缓冲,0表示不缓存,1表示缓存,大于1的值表示缓存区的大小,默认时采用如下策略:
1)对于二进制文件模式时,采用固定块内存缓冲区方式,内存块的大小根据系统设备的分配的磁盘块来决定,如果获取系统磁盘块的大小失败,就使用内部常量io.DEFAULT_BUFFER_SIZE定义的大小。一般的操作系统上,块的大小是4096或者8192字节大小。
2)对于交互的文本文件(采用isatty()判断为True)时,采用一行缓冲区的方式。其它文本文件使用跟二进制一样的方式。
encoding: 指定的编码,在使用open函数打开文件时默认为GBK编码(也叫ANSI,CP936,其包括了ASCII表,以两个字节来表示汉字,以一个字节表示字母和常见符号),可使用如上所示的方法改变打开文件时使用的编码(一般统一使用utf-8编码);
errors: 报错级别,不能在二进制的模式下使用:
1)当指明为’strict’时,编码出错则抛出异常ValueError。
2)当指明为’ignore’时,忽略错误。
3)当指明为’replace’时,使用某字符进行替代模式,比如使用’?’来替换出错的。
4)其它相应还有surrogateescape/xmlcharrefreplacs/backslashreplace。
newline:用来控制文本模式之下,一行的结束字符。可以是None,’’,\n,\r,\r\n等。
1)当在读取模式下,如果新行符为None,那么就作为通用换行符模式工作,意思就是说当遇到\n,\r或\r\n都可以作为换行标识,并且统一转换为\n作为文本输入的换行符。当设置为空’’时,也是通用换行符模式工作,但不作转换为\n,输入什么样的,就保持原样全输入。当设置为其它相应字符时,就会判断到相应的字符作为换行符,并保持原样输入到文本。
2)当在输出模式时,如果新行符为None,那么所有输出文本都是采用\n作为换行符。如果设置为’’或者\n时,不作任何的替换动作。如果是其它字符,会在字符后面添加\n作为换行符。
closefd: 用来当给一个文件句柄传进来时,而当退出文件使用时,而不对文件句柄进行关闭。如果传递一个文件名进来,这个参数无效,必定为True方式。
opener:用来实现自己定义打开文件方式,较复杂,此处略。
其返回字节流。

以二进制形式打开文件:与文本方式打开的最主要区别在于文本模式会修改换行符,会影响jpg/exe文件的数据,因此对于文本文件以文本方式打开,对于所有不包含文本的文件和以二进制创建的文件都以二进制方式打开,查看二进制文件看到的字符是ASCII码(bytes)。
关闭文件:file.close(),会先刷新缓存区中未写入的信息,然后再关闭文件;file.flush(),会刷新缓存区,但不会关闭文件。
with语句:with expression as target: with-body,其中expression是表达式(常用于open函数),target是表达式的返回值并将其赋值给的变量,with-body是将文件打开后的操作语句,其执行顺序为打开文件→赋值→执行with-body→关闭文件,打开文件和with-body出现异常时文件仍会关闭,但若文件无法打开,则会报出异常。
with open(r'c:\test.txt', 'r') as f:
data = f.read()
python中的上下文管理协议:在开发过程中,总会遇到一些任务,需求特定的上下文,即执行任务前需要进行准备,执行任务后需要进行清理(如数据库的连接与断开),且执行任务过程中可能出现异常,如果使用普通写法,则每次任务/测试都需要先处理上下文并捕获异常,非常繁琐而且易出错,在python中,提供了统一的上下文管理协议,即with语句。
python中的上下文管理可以有两种方式实现:
(1)定义类,只要一个类中定义了__enter__和__exit__方法,这个类就可以挂接到with语句。在一个用于with语句的对象中,其会自动调用这个对象的__enter__方法,在with语句的代码结束后,会调用__exit__方法,注意__exit__方法应该有处理with语句代码异常的能力,举例如下:
class Resource():
def __init__(self):
print('init')
def __enter__(self):
print('enter')
return self
def __exit__(self, exc_type, exc_val, exc_trace):
print('exit')
return True
def operate(self):
1/0
with Resource() as res:
res.operate()
①其中with语句的含义为,创建类的实例(此时会调用init方法),进入运行时上下文(执行enter方法),执行实例方法,退出运行时上下文(执行exit方法);
②enter方法必须返回实例本身,其用于as后的赋值;
③exit方法的三个参数exc_type(异常类型), exc_value(异常值), exc_trace(异常的错误栈信息),是固定的,当执行实例方法时产生异常,异常的信息就会通过这三个参数传入exit方法中,应在exit方法中执行完退出上下文语句后对异常进行处理(不建议将异常抛出),exit方法常规情况下应返回True。
(2)使用上下文装饰器,from contextlib import contextmanager,这是一个装饰器,可以使用@contextmanager 对函数进行装饰,通过yield将函数分为两部分,yield之前的部分相当于在enter语句中执行,yield后的部分在exit语句中执行,yield返回的是所需要的对象,其用法与类相同,但对于异常的处理相对没有类的方式明确。
(3)上下文管理器的好处:提高代码的复用率;提高代码的优雅度;提高代码的可读性。
文件写入:使用f.write('str')进行文件写入,注意执行文件写入时打开文件的打开模式不能为只读,f.write()方法不会自动添加换行符,f.writelines(list)可实现将字符串列表写入文件,但是不会自动添加换行符和空格。也可以使用print('', file=open对象)来写入,会添加换行符。
文件读取:file.read(size),其中size为可选参数表示要读取的字符个数(注意使用read时打开模式必须为r或r+,其默认的指针在文件开头,其size作用为防止爆内存,read读取的是字符串的字符数,即所有字符都按1个来计算);
file.seek(a,b)方法可以移动指针,其中a表示移动的字符个数,b表示从什么位置开始计算(0为默认值从文件头开始,1为从当前位置开始,2为从文件尾开始,注意如果没有使用rb模式只能从文件头开始),seek方法移动的字符数是按照不同编码方式对应的字符数来计算,注意a指定的位置不能是汉字的中间(在windows系统下,换行符会有奇怪的设定);
file.readline()方法,打开方式要求同read,会读取一行数据,注意文件中每一行末尾都有换行符,而若使用print其本身会添加一个换行符,因此连续使用readline方法输出时会空行,指针会随着readline方法的使用移动到下一行的开头(可使用for line in f,其中f是文件对象,可直接输出,但因为原文件中行末尾有换行符,因此也会空行,自动终止),当到达文件末尾时返回值为一个空字符串(区别于空行的’\n’,注意循环输出时需break,否则不断输出空行);
f.readlines()返回一个字符串列表,其中每一个字符串都是一行内容(每行末尾都有换行符);
f.tell()可以获取当前的指针位置,其是按比特数计算,返回一个整数。
小结:以上为文件读取的相关操作的简单介绍,python为文件读取提供了很多工具,若需要则再行查询学习。
三、python中的文件与目录操作
通过模块os及其子模块os.path(和模块shutil中的一部分功能)实现,os.name用于获取操作系统类型(win为’nt’,linux/Mac为’posix’),os.linesep用于获取当前操作系统的换行符,os.sep用于获取当前操作系统的路径分隔符。
相对路径与绝对路径:
①绝对路径:是指从磁盘的根目录开始定位,直到对应的位置为止。比如r"F:\a\"就是一个绝对路径(当使用\时,最好在路径前加r,或者使用/或\,就不存在这个问题,即在字符串正则匹配中提到过的字符串转义问题)。
②相对路径:是指从当前所在路径开始定位,直到对应的位置为止。用.表示当前目录,用…表示上级目录。比如:"../b"就是一个相对路径,表示跟文件操作目录同级的目录操作目录。
目录的一些常用操作方法如下:
os模块的常用函数
os.mknod("test.txt") 创建空文件,但需要权限
os.getcwd() 返回当前工作路径
os.listdir(path) 返回指定路径下的文件和目录信息
os.mkdir(path) 创建目录(直接括号中输入路径及新建的目录名称)
os.makedirs(path) 创建多级目录
os.rmdir(path) 当目录为空时删除一个目录
os.remove(path) 删除一个文件
os.removedirs(path) 当目录为空时删除多级目录(r'./a/b/c'目录形式,会将a,b,c都删掉)
os.chdir(path) 把path设置为工作目录
os.rename(src, dst) 重命名文件(src需要重命名的路径及文件,dst路径及新的文件名)
os.abspath(path) 获取文件或目录的绝对路径
os.system() 运行shell命令
os.getenv() 读取环境变量
os.putenv() 设置环境变量
os.stat(path) 获取文件属性
os.chmod(path) 修改文件权限与时间戳
os.exit() 终止当前进程
os.walk(top[, topdown=True[, onerror=None[, followlinks=False]]]) 遍历目录
shutil模块的常用函数
shutil.rmtree(path) 即使目录不为空,也强制删除目录及其下的文件
shutil.copyfile("oldfile","newfile") oldfile和newfile都只能是文件
shutil.copy("oldfile","newfile") oldfile只能是文件夹,newfile可以是文件,也可以是目标目录
shutil.copytree("olddir","newdir") olddir和newdir都只能是目录,且newdir必须不存在
shutil.move("oldpos","newpos") 移动文件/目录
os.path模块的常用函数
os.path.isabs() 判断是否是绝对路径
os.path.exists(path) 用于判断目录或文件是否存在,如果存在则返回True,否则返回False
os.path.splitext() 分离文件名和扩展名
os.path.basename(path) 从目录中提取文件名
os.path.dirname(path) 获取一个文件的上级绝对路径
os.path.isfile() 检验给出的路径是否是一个文件
os.path.isdir(path) 用于判断一个目录是否有效,有效返回True,无效返回False
os.path.getsize(path) 获取文件大小
os.path.split() 返回一个路径的目录名和文件名 (路径, 文件名包括扩展名)
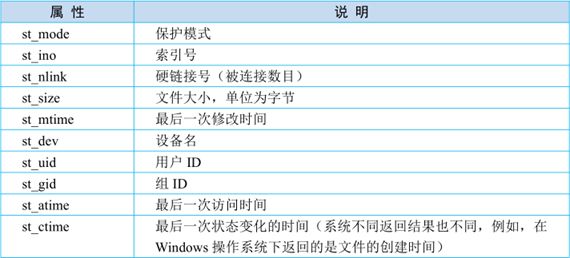
注:①os.stat(path)返回一个对象,其表示文件的基本信息,这个对象的属性如下所示,其中的时间为时间戳;
②目录遍历:os.walk(top,topdown,onerror,followlinks),其中:
top用于指定要遍历的内容的根目录(将指定目录下的全部子目录及文件访问一遍);
topdown是可选参数,用于指定遍历的顺序,值为True时从上至下,值为False时从下至上,默认为True;
onerror可选参数,用于指定错误处理方式,通常默认忽略;
followlinks可选参数,将该参数值设定为True时表示在支持的系统上访问由符号链接指向的目录,默认不解析符号链接;
walk函数的返回值是一个由3个元素组成的元组生成器对象(dirpath, dirnames, filenames),其中dirpath表示当前遍历目录或文件的路径,是一个字符串;dirnames表示当前路径下包含的子目录,是一个列表;filenames表示当前路径下包含的文件,是一个列表。(注意walk函数只用于windows系统和Unix系统)
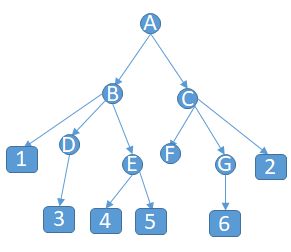
目录的遍历顺序:如图所示的目录结构,从上至下顺序为ABDECFG(即深度优先),从下至上顺序为DEBFGCA,文件位于filenames列表中。
总结:python中提供了相当丰富的异常处理、文件目录操作的功能函数,学会使用它们可以事半功倍。