数据挖掘算法和实践(五):泰坦尼克号titanic的乘客生存预测模型剖析
titanic乘客的生存预测是数据挖掘的入门级实例,根据船上乘客的多维特征预测事故发生后乘客的生还几率,属于监督学习中典型的分类问题。本文结合对数据挖掘流程的理解和经典案列,呈现数据挖掘过程。
该模型属于监督学习,需要训练集和数据集:
数据集地址:https://www.kaggle.com/omarelgabry/titanic/a-journey-through-titanic
该文章同步更新在公众号:数据社,欢迎关注!

什么是数据挖掘
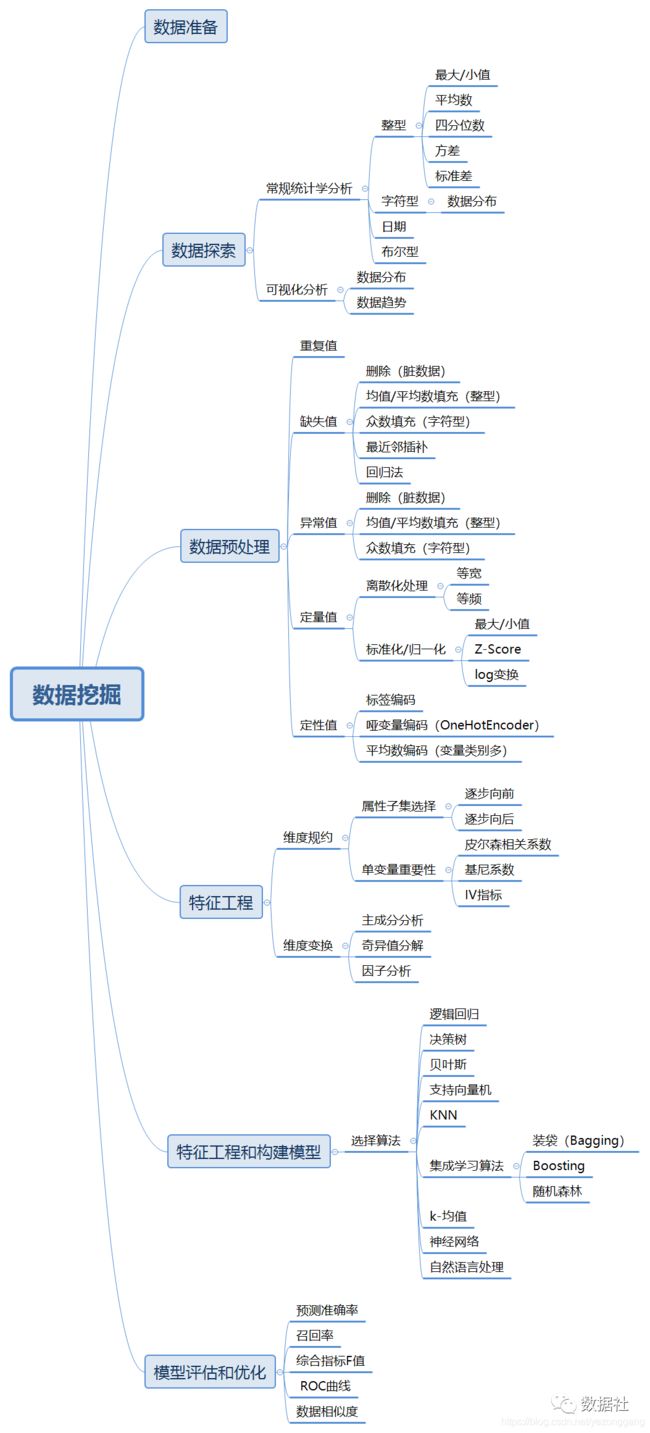
数据分析/挖掘是以概率论、线性代数、统计学、信息论为基础,根据之前接触到的数据挖掘流程,可定义为:数据准备-->数据探索--> 数据预处理-->特征工程-->模型建立-->模型评估,其中数据探索、数据预处理、特征工程针对某一属性同时进行。
构建模型的前几个步骤占数据挖掘工作量的80%以上,剩下20%优化模型,构建模型和模型评估几行代码可以搞定,若是数据质量无非保证,模型质量无从谈起;
数据挖掘常用工具包
工具使用anaconda自带的notebook,首先引入pandas的DataFrame对象,numpy包,matplotlib包,seaborn包;
import pandas as pd
from pandas import DataFrame
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier数据挖掘流程
一、数据准备
pandas读取并查看数据集,注意文件分隔符:
titanic_df=pd.read_csv('d:\\yzg\\ML_data\\titanic\\train.csv', dtype={"Age": np.float64}, )
test_df=pd.read_csv('d:\\yzg\\ML_data\\titanic\\test.csv', dtype={"Age": np.float64}, )
titanic_df.head()
可以看出测试数据集的passageId是唯一ID,其他属性表征了着乘客这一entry的特征。
titanic_df.info()
print("----------------------------")
二、数据探索、数据预处理、特征工程
数据探索的过程要求有很高的数据嗅觉,根据数据的分布和相关性分析快速做好特征工程和模型构建。数据导入后开始进行数据集探索,首先是查看数据的完整性,上图可看出训练集包含891行,12个属性,其中cabin字段数据缺失率高,考虑丢弃,passengerID和name属性无表征含义,考虑丢弃。
test_df.info()
titanic_df = titanic_df.drop(['PassengerId','Name','Ticket'], axis=1)
test_df = test_df.drop(['Name','Ticket'], axis=1)
1、数据探索
Embarked字段,字符型,表征登录的港口信息,思路是将其进行哑变量处理,该字段有2个null值,值域为“S,Q,C”:
titanic_df.Embarked[titanic_df.Embarked.isnull()
titanic_df.groupby('Embarked').Survived.count()
titanic_df.groupby('Embarked').Survived.count()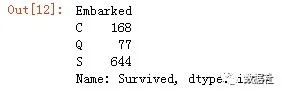
Embarked的每个值对应的人数有统计量,发现基本上大部分取值都是'S'。因此将两个空值用出现次数最多的'S'来填补 (如果是数值int类型,并且缺失率在可接受范围内(<20%)可以用均值、中位数来填补)。开始进行数据可视化探索,seaborn是面向对象的数据可视化包;
titanic_df["Embarked"] = titanic_df["Embarked"].fillna("S")
sns.catplot('Embarked','Survived',data=titanic_df,height=3,aspect=3)
生成一个画布包括3个图(2个生还统计图和1个生还概率图)均值图,titanic_df[['Embarked','Survived"]].groupby(['Embarked']相当于sql语句中的groupby函数,mean()函数对它计算均值后,生成了一个数据框DataFrame:
fig,(axis1,axis2,axis3) = plt.subplots(1,3,figsize=(15,5))
sns.countplot(x='Embarked', data=titanic_df, ax=axis1)
sns.countplot(x='Survived', hue="Embarked", data=titanic_df, order=[1,0], ax=axis2)
embark_perc = titanic_df[['Embarked','Survived']].groupby(["Embarked"],as_index=False).mean()
sns.barplot(x='Embarked', y='Survived', data=embark_perc,order=['S','C','Q'],a
2、数据处理
哑变量变黄:使用pd.get_dummies()方法得到Embarked这个变量的指标,类似于列转行,将Embarked的三个值域变成S、C、Q三个特征属性(字段),样本集和数据集作同样处理,删除S这一属性:
embark_dummies_titanic = pd.get_dummies(titanic_df['Embarked'])
embark_dummies_titanic.drop(['S'], axis=1, inplace=True)
embark_dummies_test = pd.get_dummies(test_df['Embarked'])
embark_dummies_test.drop(['S'], axis=1, inplace=True)
titanic_df = titanic_df.join(embark_dummies_titanic)
test_df = test_df.join(embark_dummies_test)将原来的Emabrked这个特征属性删除:
titanic_df.drop(['Embarked'], axis=1,inplace=True)
test_df.drop(['Embarked'], axis=1,inplace=True)Fare字段表征票价,整型,通过常规的统计分析和可视化分析进行数据探索(这里未做归一化处理),数值类型可以用describe方法查看统计特性:
test_df.Fare.describe()
# 发现test数据中有一个Fare变量是空值,用fillna()方法填充中值:
test_df["Fare"].fillna(test_df["Fare"].median(), inplace=True)
# 数据处理转换,将float转换成int类型:
titanic_df['Fare'] = titanic_df['Fare'].astype(int)
test_df['Fare'] = test_df['Fare'].astype(int)
# 分别得到Fare变量对应的幸存和没有幸存的记录,(这种引用很像R语言中的which()函数):
fare_not_survived = titanic_df["Fare"][titanic_df["Survived"] == 0]
fare_survived = titanic_df["Fare"][titanic_df["Survived"] == 1]
# 转换成数据框DataFrame,并作图出来:
avgerage_fare = DataFrame([fare_not_survived.mean(), fare_survived.mean()])
std_fare = DataFrame([fare_not_survived.std(), fare_survived.std()])
titanic_df['Fare'].plot(kind='hist', figsize=(10,3),bins=100, xlim=(0,50))
# 求均值和标准差
titanic_df['Fare'].plot(kind='hist', figsize=(10,3),bins=100, xlim=(0,50))
# 进行可视化探索
avgerage_fare.index.names = std_fare.index.names = ["Survived"]
avgerage_fare.plot(yerr=std_fare,kind='bar',legend=False)
age特征属性,面向对象画2个图,分别设置title:
fig, (axis1,axis2) = plt.subplots(1,2,figsize=(15,4))
axis1.set_title('Original Age values - Titanic')
axis2.set_title('New Age values - Titanic')
average_age_titanic = titanic_df["Age"].mean()
std_age_titanic = titanic_df["Age"].std()
count_nan_age_titanic = titanic_df["Age"].isnull().sum()
average_age_test = test_df["Age"].mean()
std_age_test = test_df["Age"].std()
count_nan_age_test = test_df["Age"].isnull().sum()
# 随机生产年龄填充空值
# generate random numbers between (mean - std) & (mean + std)
rand_1 = np.random.randint(average_age_titanic - std_age_titanic, average_age_titanic + std_age_titanic, size = count_nan_age_titanic)
rand_2 = np.random.randint(average_age_test - std_age_test, average_age_test + std_age_test, size = count_nan_age_test)
titanic_df['Age'].dropna().astype(int).hist(bins=70, ax=axis1)
test_df['Age'].dropna().astype(int).hist(bins=70, ax=axis1)
titanic_df["Age"][np.isnan(titanic_df["Age"])] = rand_1
test_df["Age"][np.isnan(test_df["Age"])] = rand_2
titanic_df['Age'] = titanic_df['Age'].astype(int)
test_df['Age'] = test_df['Age'].astype(int)
titanic_df['Age'].hist(bins=70, ax=axis1)
test_df['Age'].hist(bins=70, ax=axis2)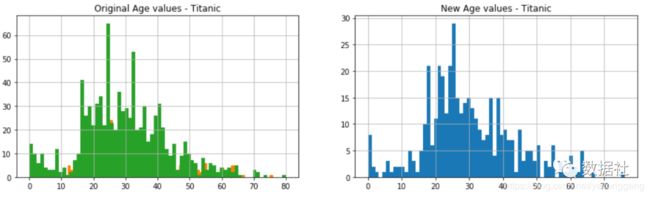
继续作图,seaborn的FaceGrid()方法,需要查一下:
facet = sns.FacetGrid(titanic_df, hue="Survived",aspect=4)
facet.map(sns.kdeplot,'Age',shade= True)
facet.set(xlim=(0, titanic_df['Age'].max()))
facet.add_legend()
# 每个年龄的存活率:
fig, axis1 = plt.subplots(1,1,figsize=(18,4))
average_age = titanic_df[["Age", "Survived"]].groupby(['Age'],as_index=False).mean()
sns.barplot(x='Age', y='Survived', data=average_age)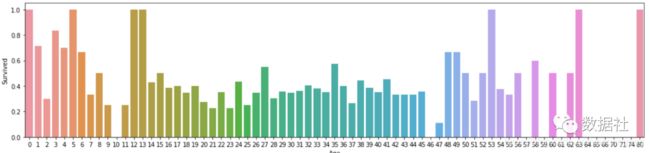
Cabin特征变量,表征的是船舱号,无任何表征意义被舍弃。
titanic_df.shap
titanic_df.Cabin.count()
# 发现总共891个记录,只有204个记录是非空的,而且它是一个字符型的,质量太差所以这个变量被删除了。
titanic_df.drop("Cabin",axis=1,inplace=True)
test_df.drop("Cabin",axis=1,inplace=True)整合/规约Parch和SibSp特征属性表征的是乘客的家庭信息(sibsp 是sibling spouse的缩写就是堂兄妹和配偶数量,parch是父母小孩的个数),这里涉及到数据规约思想,将Parch和SibSp变量整合为一个Famliy变量,作为一个取值为0和1的标签变量。
titanic_df.Parch.describe()
titanic_df.Parch[titanic_df.Parch!=0].count()
titanic_df.SibSp[titanic_df.SibSp!=0].count()
# 这两个属性,只有极少数不是0值,故:
titanic_df['Family'] = titanic_df["Parch"] + titanic_df["SibSp"]
titanic_df['Family'].loc[titanic_df['Family'] > 0] = 1
titanic_df['Family'].loc[titanic_df['Family'] == 0] = 0
test_df['Family'] = test_df["Parch"] + test_df["SibSp"]
test_df['Family'].loc[test_df['Family'] > 0] = 1
test_df['Family'].loc[test_df['Family'] == 0] = 0作图,观察和一家人出行和独自一个人的差别:
titanic_df = titanic_df.drop(['SibSp','Parch'], axis=1)
test_df = test_df.drop(['SibSp','Parch'], axis=1)
fig, (axis1,axis2) = plt.subplots(1,2,sharex=True,figsize=(10,5))
sns.countplot(x='Family', data=titanic_df, order=[1,0], ax=axis1)
family_perc = titanic_df[["Family", "Survived"]].groupby(['Family'],as_index=False).mean()
sns.barplot(x='Family', y='Survived', data=family_perc, order=[1,0], ax=axis2)
axis1.set_xticklabels(["With Family","Alone"], rotation=0)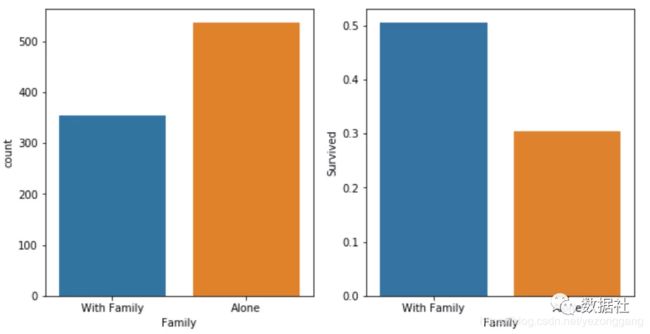
Sex属性转换,这里采用数据分箱方法,定义一个函数来判断age是否超过16岁,小于16岁分类为’child’,大于16岁保留性别,然后进行哑变量处理增加Child和Female两个标签变量;
def get_person(passenger):
age,sex = passenger
return 'child' if age < 16 else sex# 分类
titanic_df['Person'] = titanic_df[['Age','Sex']].apply(get_person,axis=1)
test_df['Person'] = test_df[['Age','Sex']].apply(get_person,axis=1)
# 删除sex
titanic_df.drop(['Sex'],axis=1,inplace=True)
test_df.drop(['Sex'],axis=1,inplace=True)列转行,把child','Female','Male'变成标签属性,删除male这一属性;
person_dummies_titanic = pd.get_dummies(titanic_df['Person'])
person_dummies_titanic.columns = ['Child','Female','Male']
person_dummies_titanic.drop(['Male'], axis=1, inplace=True)
person_dummies_test = pd.get_dummies(test_df['Person'])
person_dummies_test.columns = ['Child','Female','Male']
person_dummies_test.drop(['Male'], axis=1, inplace=True)
titanic_df = titanic_df.join(person_dummies_titanic)
test_df = test_df.join(person_dummies_test)fig, (axis1,axis2) = plt.subplots(1,2,figsize=(10,5))
sns.countplot(x='Person', data=titanic_df, ax=axis1)
person_perc = titanic_df[["Person", "Survived"]].groupby(['Person'],as_index=False).mean()
sns.barplot(x='Person', y='Survived', data=person_perc, ax=axis2, order=['male','female','child'])
# 删除Person 属性
titanic_df.drop(['Person'],axis=1,inplace=True)
test_df.drop(['Person'],axis=1,inplace=True)Pclass属性表征船舱等级,字符型,采用哑变量变换成新得标签变量;
sns.factorplot('Pclass','Survived',order=[1,2,3], data=titanic_df,size=5)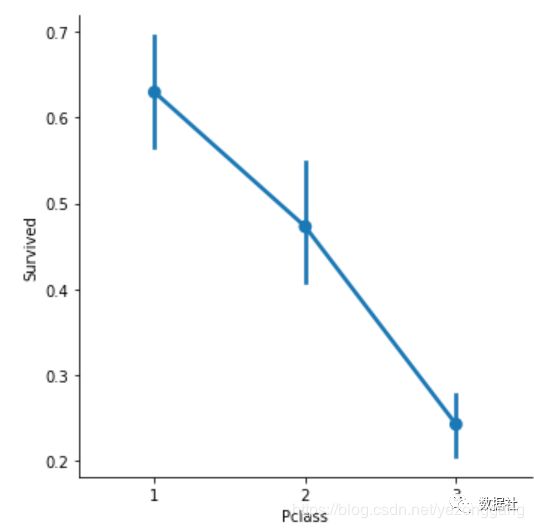
将Pclass的三个取值做成标签变量,并删除train和test中的class_3变量,因为它的幸存率太低。、
pclass_dummies_titanic = pd.get_dummies(titanic_df['Pclass'])
pclass_dummies_titanic.columns = ['Class_1','Class_2','Class_3']
pclass_dummies_titanic.drop(['Class_3'], axis=1, inplace=True)
pclass_dummies_test = pd.get_dummies(test_df['Pclass'])
pclass_dummies_test.columns = ['Class_1','Class_2','Class_3']
pclass_dummies_test.drop(['Class_3'], axis=1, inplace=True)
titanic_df.drop(['Pclass'],axis=1,inplace=True)
test_df.drop(['Pclass'],axis=1,inplace=True)
titanic_df = titanic_df.join(pclass_dummies_titanic)
test_df = test_df.join(pclass_dummies_test)三、构建模型
至此,数据预处理和数据探索结束,开始选择模型,既然是一个二分类问题,首先考虑逻辑回归和决策树算法。(关于常用的数据挖掘算法,将在后续文章更新讲解)
X_train = titanic_df.drop("Survived",axis=1)
Y_train = titanic_df["Survived"]
X_test = test_df.drop("PassengerId",axis=1).copy()应用sklearn中封装的算法包,首先用逻辑回归去拟合Xtrain和Ytrain,然后用logreg.predict()函数去预测X_test的数据,最后用拟合的结果去给模型打分,逻辑回归模型的准确率是0.808。
logreg = LogisticRegression()
logreg.fit(X_train, Y_train)
Y_pred = logreg.predict(X_test)
# 模型打分
logreg.score(X_train, Y_train)一般集成学习算法的效果好过单个算法的效率,采用随机森林算法,随机森林算法的准确率是0.968:
random_forest = RandomForestClassifier(n_estimators=100)
random_forest.fit(X_train, Y_train)
Y_pred = random_forest.predict(X_test)
# 模型打分
random_forest.score(X_train, Y_train)最后得出数据集的预测结果
submission = pd.DataFrame({
"PassengerId": test_df["PassengerId"],
"Survived": Y_pred
})
submission.to_csv('titanic.csv', index=False)