网盘分享视频自动存储
本节为大家介绍百度网盘登录及分享视频自动转存,参考了一些网上案例最后整理出来的,希望对大家有所帮助。
工作流程
登录网盘获取cookie
解析分析视频url,获取一些参数、shareid、from、uk、bdstoken、appid
构建url,添加到网盘
分析转存url
https://pan.baidu.com/share/transfer?shareid=2986040315&from=4010302105&channel=chunlei&web=1&app_id=250528&bdstoken=633291617bb481c0cd8d23c1c469e441&logid=MTUyMzI2MzIzMjk2NDAuMjA1MzUzNTY5OTM3MDY3NjY=
通过几次登录可以发现有几个参数是变化的shareid、from、uk、bdstoken、appid,logid参数是随机加密的可以不用变,我们再回到请求视频的页面中
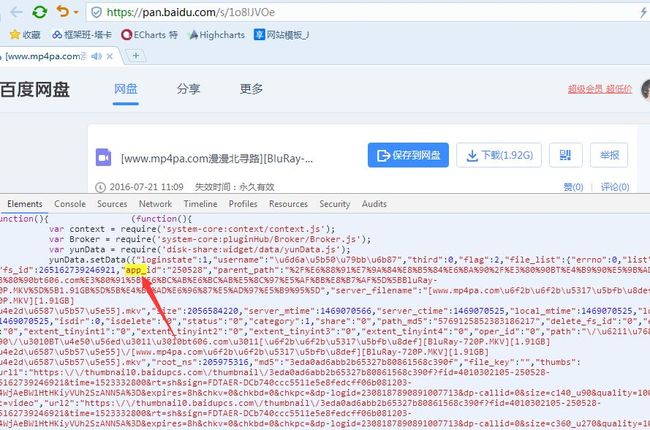
通过页面分析可以得到这些数据,然后传递到分享url转存
实战开始
导入Python库
import re
import urllib2
import urllib
import json
url='https://pan.baidu.com/s/1gfjZOVD'
res_content=r'"app_id":"(\d*)".*"path":"([^"]*)".*"uk":(\d*).*"bdstoken":"(\w*)".*"shareid":(\d*)'
Cookie='填写自己登录的cookie'
headers = {'Host':"pan.baidu.com",
'Accept':'*/*',
'Accept-Language':'en-US,en;q=0.8',
"Accept-Encoding":"",
'Cache-Control':'max-age=0',
'Referer':'https://pan.baidu.com/s/1jHREdLG?errno=0&errmsg=Auth%20Login%20Sucess&&bduss=&ssnerror=0&traceid=',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0',
'Cookie':Cookie
}
req=urllib2.Request(url,headers=headers)
f=urllib2.urlopen(req)
content=f.read()
pattern=re.compile(res_content)
L=pattern.findall(content.decode("unicode-escape"))
if len(L)>0:
app_id=L[0][0]
path=L[0][1]
uk=L[0][2]
bdstoken=L[0][3]
shareid=L[0][4]
print app_id,path,uk,bdstoken,shareid最后查看一下结果
![]()
构建转存url
url_post="https://pan.baidu.com/share/transfer?shareid="+shareid+"&from="+uk+"&channel=chunlei&web=1&app_id="+app_id+"&bdstoken="+bdstoken+"&logid=MTUyMzI2MzIzMjk2NDAuMjA1MzUzNTY5OTM3MDY3NjY="
payload="filelist=%5B%22"+path+"%22%5D&path=/"#资源名称和保存路径,表单提交
print "[Info]Url_Post:",url_post
print "[Info]payload:",payload
![]()
最后就是存储了
try:
req=urllib2.Request(url=url_post,data=payload,headers=headers)
f=urllib2.urlopen(req)
str_code=f.read().replace("\/","").strip().decode("unicode-escape").split(",")[0]+"}"
result=json.loads(str_code)
tag=result["errno"]
print tag
if tag==0:
print "[Result]Add Success"#转存成功
elif tag==12:
print "[Result]Already Exist"#资源已经存在
else:
print "[Result]Have Error"有错误
except Exception,e:
print "[Error]",str(e)保存成功
0
[Result]Add Success
下面整理一下代码,批量转存
#! -*- coding:utf-8 -*-
import re
import urllib2
import urllib
import json
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
##########################---filename和url任意填写一项
filename='baidu_pan.txt'#文件路径及名称
# url='https://pan.baidu.com/s/1gfjZOVD'
address='/movies'
#############################
res_content=r'"app_id":"(\d*)".*"path":"([^"]*)".*"uk":(\d*).*"bdstoken":"(\w*)".*"shareid":(\d*)'
Cookie='填写自己的cookie'
headers = {'Host':"pan.baidu.com",
'Accept':'*/*',
'Accept-Language':'en-US,en;q=0.8',
"Accept-Encoding":"",
'Cache-Control':'max-age=0',
'Referer':'https://pan.baidu.com/s/1jHREdLG?errno=0&errmsg=Auth%20Login%20Sucess&&bduss=&ssnerror=0&traceid=',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0',
'Cookie':Cookie
}
def get_url(url):
req=urllib2.Request(url,headers=headers)
f=urllib2.urlopen(req)
content=f.read()
# print content
pattern=re.compile(res_content)
L=pattern.findall(content)
if len(L)>0:
app_id=L[0][0]
path=L[0][1]
uk=L[0][2]
bdstoken=L[0][3]
shareid=L[0][4]
pare(app_id,path,uk,bdstoken,shareid)
def pare(app_id,path,uk,bdstoken,shareid):
url_post="https://pan.baidu.com/share/transfer?shareid="+shareid+"&from="+uk+"&channel=chunlei&web=1&app_id="+app_id+"&bdstoken="+bdstoken+"&logid=MTUyMzI2MzIzMjk2NDAuMjA1MzUzNTY5OTM3MDY3NjY="
payload="filelist=%5B%22"+path+"%22%5D&path="+address#资源名称和保存路径,表单提交
print "[Info]Url_Post:",url_post
print "[Info]payload:",payload
try:
req=urllib2.Request(url=url_post,data=payload,headers=headers)
f=urllib2.urlopen(req)
str_code=f.read().replace("\/","").strip().decode("unicode-escape").split(",")[0]+"}"
result=json.loads(str_code)
tag=result["errno"]
print tag
if tag==0:
print "[Result]Add Success"
elif tag==12:
print "[Result]Already Exist"
else:
print "[Result]Have Error"
except Exception,e:
print "[Error]",str(e)
def main():
if filename!="":
try:
with open(filename,"r") as w:
f=[i.strip("\n").strip("\r") for i in w.readlines()]
for i in f:
print "[Info]Shareurl:",i
get_url(i)
print "****************************"
except IOError:
print "[Error]selectfilename error"
else:
print url
get_url(url)
if __name__=="__main__":
main()程序在运行,很顺利
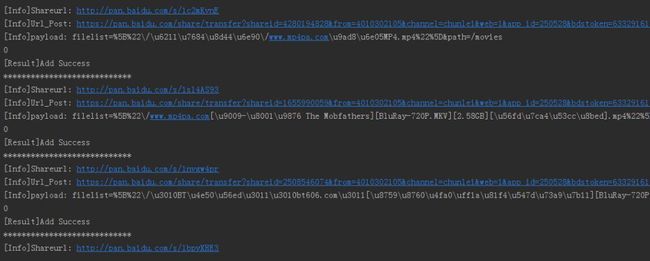
查看下网盘,见证奇迹的时刻,
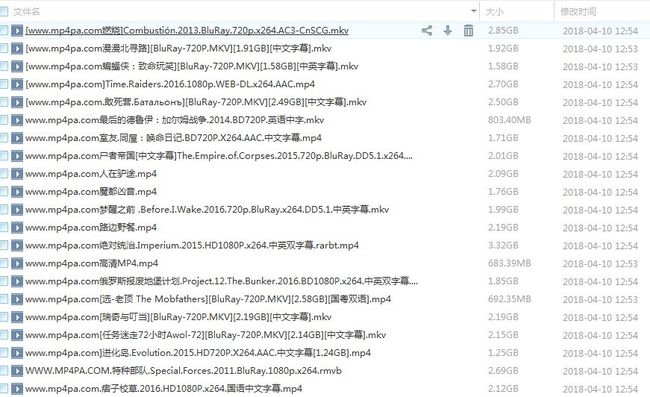
可以留下来慢慢看啦。