中国民营500强企业爬取数据展示
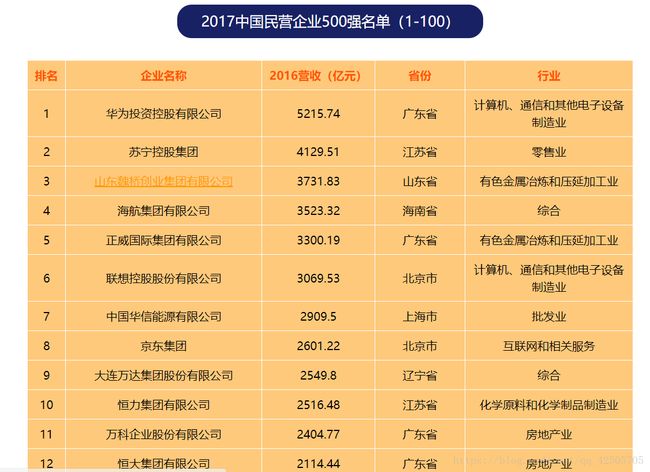
8月24日,全国工商联在山东济南发布2017年民营企业500强报告;华为技术有限公司以5215.74亿元的营业收入再次蝉联榜单之首,苏宁控股、山东魏桥集团,海南航空集团和正威国际集团排名二到五位,京东集团进入第八位,是首次入围前十强的互联网企业。
下面利用爬虫技术,更直观得来感受这些数据
需要用到一下库
import requests
import operator
import pickle
import matplotlib.pyplot as plt
from selenium import webdriver
from matplotlib.font_manager import FontProperties
利用谷歌开发者工具知道了,我们需要信息并不直接在返回的内容里面。得用selenium库。
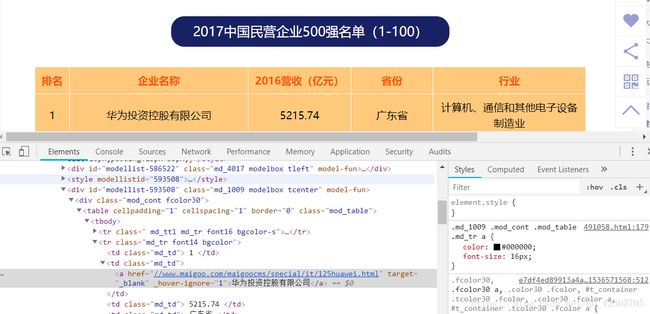
发现我们要的信息都在 td class=“md_td” 下
使用find_elements_by_class_name()方法找到“md_td”属性
td = browser.find_elements_by_class_name('md_td')
info5 = open('info5.txt','rb')
信息存入文本
for i in range(5,len(td),5):
info = {}
info['rank']=td[i].text; info['name']=td[i+1].text;
info['profit']=td[i+2].text; info['province']=td[i+3].text;
info['industry']=td[i+4].text
pickle.dump(info,info5)
计算500个名单中每个省出现的次数
proSet = {}
for i in range(504): #这里的pickle.load()每次只加载一条信息
sinfo5 = pickle.load(info5)
if sinfo5['province'] not in proSet:
proSet[sinfo5['province']] = 1
else:
proSet[sinfo5['province']] += 1
由于每个表只展示100个排名,而在下一个表中标题中的“ 省份”、“排名”等汉字也会被提取到

pop掉
proSet.pop('省份')
从大到小排序,并将省份和出现次数分别保存
proList = sorted(proSet.items(),key=operator.itemgetter(1),reverse=True)
labels = []; values = []
for i in range(len(proList)):
labels.append(proList[i][0])
values.append(proList[i][1])
为了避免出现下面的情况
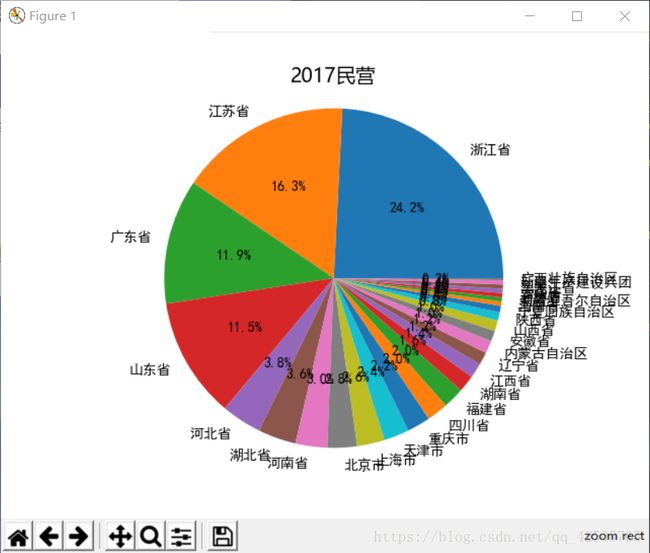
改为显示排名前十使图片更美观
labels1 = labels[:10]; values1 = values[:10]
sleft = 0
for i in range(10,len(values)):
sleft += values[i]
values1.append(sleft)
labels1.append('其他')
如果出现汉字乱码出现方框,可以尝试加上
# 设置全局字体
plt.rcParams['font.sans-serif'] = ['SimHei']
# 解决‘-’表现为方块的问题
plt.rcParams['axes.unicode_minus'] = False
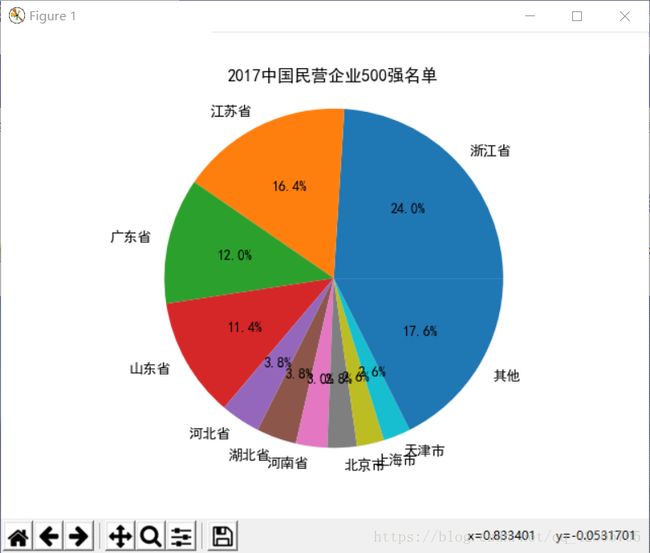
根据饼图显示,500强中江浙地图比较强的,哈哈
这是全部代码
#-*- coding: utf-8 -*-
import requests
import operator
import pickle
import matplotlib.pyplot as plt
from selenium import webdriver
from matplotlib.font_manager import FontProperties
# 设置全局字体
plt.rcParams['font.sans-serif'] = ['SimHei']
# 解决‘-’表现为方块的问题
plt.rcParams['axes.unicode_minus'] = False
browser = webdriver .Chrome()
browser.get('http://www.maigoo.com/news/491058.html')
td = browser.find_elements_by_class_name('md_td')
info5 = open('info5.txt','rb')
#rank name profit province industry
'''for i in range(5,len(td),5):
info = {}
info['rank']=td[i].text; info['name']=td[i+1].text;
info['profit']=td[i+2].text; info['province']=td[i+3].text;
info['industry']=td[i+4].text
pickle.dump(info,info5) #前面的加入后面'''
proSet = {}
for i in range(504): #这里的pickle.load()每次只加载一条信息
sinfo5 = pickle.load(info5)
if sinfo5['province'] not in proSet:
proSet[sinfo5['province']] = 1
else:
proSet[sinfo5['province']] += 1
proSet.pop('省份')
proList = sorted(proSet.items(),key=operator.itemgetter(1),reverse=True)
labels = []; values = []
for i in range(len(proList)):
labels.append(proList[i][0])
values.append(proList[i][1])
#显示排名前十,图形更美观
labels1 = labels[:10]; values1 = values[:10]
sleft = 0
for i in range(10,len(values)):
sleft += values[i]
values1.append(sleft)
labels1.append('其他')
plt.title(u'2017中国民营企业500强名单')
plt.pie(values1,labels=labels1,autopct='%1.1f%%')
plt.axis('equal')
plt.show()
browser.close()
额,中间的 for i in range(5,len(td),5): 那部分我注释掉了,是因为都第一次爬取的时候数据已经存进去了,后面在运行每次都要重新下载,很慢,所以索性注释掉了,第一次运行该代码应该把‘’‘ ’‘’ 去掉,后面想增加一些其他的功能(比如,500强中那个行业的比率最多等等),可以把那段注释掉来调试,哈哈。