Java—网络程序设计
Socket介绍
Socket是网络上运行的两个程序间双向通信的一端,它既可以接受请求,也可以发送请求,利用它可以较为方便地实现网络上数据的传递。在Java中,有专门的socket类来处理用户的请求和响应。利用Socket类的方法,就可以实现两台计算机之间的通信。
在Java中,可以将Socket理解为客户端或者服务器端的一个特殊的对象,这个对象有两个关键的方法,一个是getInputStream()方法,另一个是getOutputStream()方法。getInputStream()方法用于得到一个输入流,客户端的Socket对象上的getInputStream()方法得到的输入流其实就是从服务器端发回的数据流。getOutputStream()方法用于得到一个输出流,客户端Socket对象上的getOutputStream()方法返回的输出流就是将要发送到服务器端的数据流(其实是一个缓冲区,暂时存储将要发送过去的数据)。
Socket有两种主要的操作方式:面向连接的和无连接的。面向连接的Socket操作就像一部电话,它们必须建立一个连接和一个呼叫。所有的事情到达时的顺序与它们出发时的顺序是一样的。无连接的Socket操作就像是一个邮件投递,没有什么保证,多个邮件可能到达时的顺序与出发时的顺序不一样。
到底用哪一种模式应根据应用程序的需要决定。如果可靠性更重要的话,用面向连接的操作会好一些。比如文件服务器需要保证数据的正确性和有序性,如果一些数据丢失了,系统的有效性将会失去。一些服务器,比如间歇性地发送一些数据块,如果数据丢了的话,服务器并不想要再重新发一次,因为当数据到达的时候,它可能已经过时了。确保数据的有序性和正确性需要的额外操作会消耗内存,额外的费用将会降低系统的回应速率。
无连接的操作使用数据报协议。一个数据报是一个独立的单元,它包含了所有的这次投递的信息。可以把它想象成一个信封,它有目的地址和要发送的内容。这个模式下的Socket不需要连接一个目的地的Socket,它只是简单地投出数据报。无连接的操作是快速的和高效的,但是数据安全性不佳。
面向连接的操作使用TCP。在这个模式下建立的Socket必须在发送数据之前与目的地的socket取得一个连接。一旦连接建立了,Socket就可以使用一个流:打开→读→写→关闭。所有发送的信息都会在另一端以同样的顺序被接收。面向连接的操作比无连接的操作效率更低,但是数据的安全性较高。
ServerSocket概念
在TCP/IP中,互相通信要有两方。我们叫做服务端和客户端。一般来讲,由客户端发起一个连接请求,服务端接受请求,双方开始通信。一旦互相通信建立起来,就好像双方连接起一个管道,双方随时可以互相发送消息和接受消息。
这里面,由一个稍微特殊的地方,就是,作为服务端的那方,需要等待客户端来连接。就好像两个人走散了的话,其中一方一般待在特定的地点等待另一方到来。否则,如果双方都跑出去互相找,或者都待在一个地方等对方,是永远不会重聚的。
这里,ServerSocket所封装的底层操作就是作为服务的提供端,监听某一个网络端口,等待客户端的连接请求。所以对于ServerSocket,主要用于完成以下功能。
- 绑定IP地址
绑定IP地址是为了让客户端能够在浩瀚的互联网上找到提供服务的这台服务器。
所谓绑定地址,就是一个IP地址。因为对于服务器,一般都会有2个以上的网络IP地址,其中, 127.0.0.1 这个IP地址代表这台机器自己。只要你的机器安装了IP,这个地址就分配给自己,但外界无法通过这个地址找到你。
另外,有一个或者多个让别的机器能识别你的IP地址。这个地址就有可能是任意的了。比如192.168.100.2 之类的。
其中,0.0.0.0 代表任意的一个网络接口,即同时在所有地址上绑定。
当你启动一个ServerSocket,你必须指定你要绑定到哪个网络地址上来等待请求。一般情况下,都是绑定到能够标识这台机器的外部IP地址上,用以对外提供服务。
但是,也有情况下,为了安全考虑,一些网络服务并不对外提供,仅仅是对本机的其他程序提供服务,比如说你装了一个数据库,数据库通过TCP/IP交互数据。那么这时候,出于安全考虑,你不想让网络上的其他机器访问到这个数据库,而自己又要访问它,你就可以把它绑定到127.0.0.1上。这样,就可以保证只有来自本机的请求,才能访问到。
最后,如果你的计算机上装了好几个网卡,有好几个IP地址,比如为了解决具有中国特色的南北互通问题,你一个网卡接网通机房,一个网卡接电信机房。这时候,为了方便,你就让你的服务绑定在0.0.0.0这个地址上,这就意味着你有几个网络接口,它就都通通包圆了。都给你监听上,任意一个网络接口上有请求,都会响应。
- 绑定端口
所谓绑定端口,实际上是为了解决一台服务器上标识好几个服务用的。比如说,你这台机器上有HTTP服务,FTP服务等。一个IP地址上的不同端口,一般对应不同的服务。自己写一个服务的时候,所谓你监听在某个端口上,实际上就是告诉服务器,如果有找这个端口号的请求,你就转给我。
明确了这个概念以后,我们来总结一下,如果你是一个客户端,你肯定要访问别人的服务的时候,就需要明白了:你要提供一个IP地址,这样才能找到人家那个服务器,等找到服务器后,还得告诉人家你的端口号,这样人家才能转给要给你提供服务的那个程序。所以,一个IP地址加一个端口号就可以唯一标示一个特定的服务。
有人说,我在浏览器里面输入“www.baidu.com”的时候(域名会被解析成一个IP地址),只给了地址,没给端口号,它不是也找到这个提供HTTP服务的程序了吗?没错,但是,由于HTTP服务在当今太出名了,干脆,一般情况下,你就可以把端口号省略。浏览器就默认你要访问的是HTTP服务,自动去找HTTP服务所用的80端口。
所以,省略的端口号实际是给用户的一种方便,浏览器在实现这个机制的时候,会自己给加上一个端口号,默认80。
Socket程序
在Java中面向连接的操作类有两种形式,分别是客户端和服务器端。下面先讨论服务器端。
首先建立服务器端程序,此服务器端程序只用于向客户端输出“hello world!”字符串。
Socket程序的使用(HelloServer.java)。



从运行结果可以看到,执行Java HelloServer之后,程序停在原处不动了,这表示服务器在等待客户端的连接。下面为客户端程序。
第7行声明了一个ServerSocket的对象。
第8行声明了一个PrintWriter的对象,用于向客户端打印输出。
第9~18行实例化ServerSocket对象,在9999端口进行监听。
第19行声明了一个Socket对象clientsocket,此对象用于接收客户端的Socket连接。
第20~29行通过ServerSocket类中的accept()方法,接收客户端的Socket请求,此方法返回一个客户端的Socket请求。
第30行通过客户端的Socket对象去实例化PrintWriter对象,此时out对象就具备了向客户端打印信息的能力。
第31行调用println()方法,将信息打印至客户端。
第32行关闭客户端Socket连接。
第33行关闭服务器端Socket连接。
客户端程序编写(HelloClient.java)。



第7行声明了一个Socket的对象hellosocket。
第8行声明了一个BufferedReader的对象in,此对象用于读取服务器端发送过来的数据。
第12行实例化hellosocket对象,此连接在本机的9999端口上监听。
第13行通过hellosocket对象实例化BufferedReader对象。
第25行等待服务器端发送过来的信息并打印。
第26行关闭BufferedReader。
第27行关闭Socket对象。
下面再来看一个Socket的经典范例— Echo程序,读者可以自行分析。
Echo服务器端程序编写(EchoServer.java)



Echo客户端程序编写(EchoClient.java)。



运行上面的程序可以看到,无论客户端输入什么,服务器端都会对数据进行回显,输入“bye”之后程序会退出。
但细心的读者可能会发现,此程序只能允许一个客户端进行操作,即其他客户端程序无法再进行Socket连接,那该如何去解决这个问题呢?读者应该还记得之前讲解过的多线程的概念,只要在服务器端实现多线程,那么服务器就可以同时处理多个客户端请求。下面的代码是改进后的EchoServer程序。
EchoServer程序的改进(EchoMultiServerThread.java)。


多线程的服务器端程序编写(EchoServerThread.java)。


运行上面的服务器端程序之后,可以看到服务器可以同时处理多个客户端的Socket连接。
DatagramSocket程序
使用流套接字的每个连接均需要花费一定的时间,要减少这种开销,网络API提供了第2种套接字:自寻址套接字(datagram socket)。自寻址使用UDP发送寻址信息(从客户程序到服务程序或从服务程序到客户程序),不同的是可以通过自寻址套接字发送多个IP信息包,自寻址信息包含在自寻址包中,自寻址包又包含在IP包内,这样就将寻址信息长度限制在60000字节内。下图显示了位于IP包内的自寻址包的自寻址信息。

与TCP保证信息到达信息目的地的工作方式不同,UDP提供了另外一种方法,如果自寻址信息包没有到达目的地,那么UDP也不会请求发送者重新发送自寻址包。这是因为UDP在每一个自寻址包中包含了错误检测信息,在每个自寻址包到达目的地之后UDP只进行简单的错误检查,如果检测失败, UDP将抛弃这个自寻址包,也不会从发送者那里重新请求替代者,这与通过邮局发送信件相似,发信人在发信之前不需要与收信人建立连接,同样也不能保证信件能到达收信人那里。
自寻址套接字工作常用的类包括DatagramPacket和DatagramSocket。DatagramPacket对象描绘了自寻址包的地址信息,DatagramSocket表示客户程序和服务程序自寻址套接字,这两个类均位于java.net包内。
- DatagramPacket类
在使用自寻址包之前,需要首先熟悉DatagramPacket类,地址信息和自寻址包以字节数组的方式同时压缩进入这个类创建的对象中。
DatagramPacket有数个构造方法,即使这些构造方法的形式不同,但通常情况下它们都有两个共同的参数:byte [] buffer 和 int length。buffer参数包含了一个对保存自寻址数据包信息的字节数组的引用,length表示字节数组的长度。
最简单的构造方法是DatagramPacket(byte [] buffer, int length),这个构造方法确定了自寻址数据包数组和数组的长度,但没有任何自寻址数据包的地址和端口信息,这些信息可以在后面通过调用方法setAddress(InetAddress addr)和setPort(int port)添加上。
- DatagramSocket类
DatagramSocket类在客户端创建自寻址套接字与服务器端进行通信连接,并发送和接收自寻址套接字。虽然有多个构造方法可供选择,但创建客户端自寻址套接字最便利的选择是DatagramSocket()方法,而服务器端则是DatagramSocket(intport)方法。如果未能创建自寻址套接字或绑定自寻址套接字到本地端口,那么这两个方法都将抛出一个SocketException对象,一旦程序创建了DatagramSocket对象,程序就会分别调用send(DatagramPacket dgp)和 receive(DatagramPacketdgp)来发送和接收自寻址数据包。
UDP接收数据范例(UdpReceive.java)。


UDP发送数据范例(UdpSend.java)。



UDP数据的发送,类似发送寻呼信号,发送者将数据发送出去就不管了,因此是不可靠的数据传输,有可能在发送的过程中数据丢失。就像寻呼机必须先处于开机接收状态才能接收寻呼一样的道理,这里要先运行UDP接收程序,再运行UDP发送程序,UDP数据包的接收是过期作废的。因此,前面的接收程序要比发送程序早运行才行。
当UDP接收程序运行到DatagramSocket.receive()方法接收数据时,如果还没有可以接收的数据,在正常情况下,receive()方法将阻塞,一直等到网络上有数据到来,receive才接收该数据并返回。
网络编程的基本概念
网络,就是将物理上不在一起的主机进行互联。
在网络上进行通信需要使用协议,常见的通信协议是TCP和UDP。
⑴ TCP:属于可靠的连接,使用三方握手的方式完成连接的确认。
⑵ UDP:属于不可靠的连接。
对于网络程序的开发有两种架构。
⑴ C/S:客户端/服务器端,对于这种程序需要开发两套代码,一套是是客户端,另外一套是服务器端,维护也要维护两套。
⑵ B/S:浏览器/服务器,类似于论坛,开发和维护的时候只需要一套代码即可。
TCP程序实现
在Java中,所有的网络开发包保存在java.net包中,在此包中可以使用ServerSocket、Socket类完成服务器和客户端的开发。
简单的TCP程序
如果想要开发TCP程序,首先要开发服务器端,在服务器端,要使用ServerSocket进行客户端的连接接收,每一个客户端在程序上都使用Socket对象表示。

如果此时想要进行连接的操作实验,则可通过telnet命令完成。
此时就完成了一个服务器程序的开发,此程序执行完一次之后将关闭。那么现在的程序是通过telnet命令完成的服务器的访问,也可以通过单独的客户端程序编写代码,进行访问。


加入多线程
每一个客户端都使用一个线程对象表示。
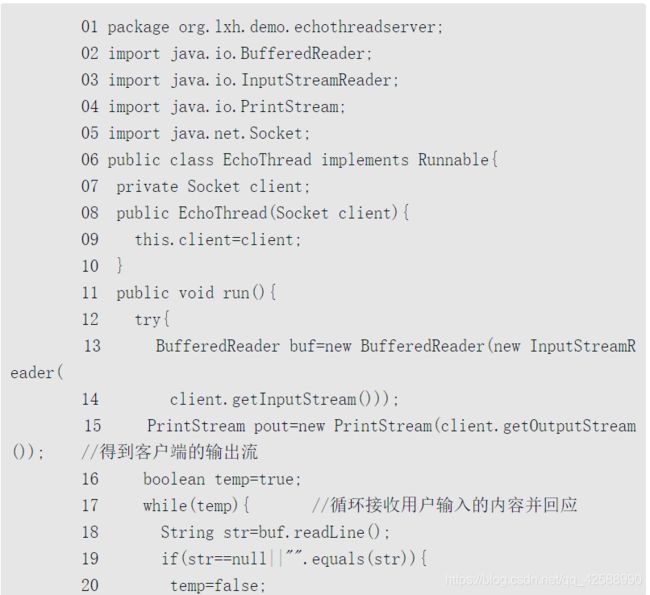

之后的服务器端在每次接收到客户端的请求之后,直接启动一个新的线程即可。


UDP程序实现
UDP程序使用数据报的形式出现,需要使用以下两个类。
⑴ 数据报的内容:DatagramPacket。
⑵ 发送和接收数据报:DatagramSocket。
在开发TCP程序的时候,是先要有服务器端,之后再进行客户端的开发。而UDP要运行的时候,则应该先运行客户端,之后再运行服务器端。
- 客户端

- 服务器端


网络编程的经典案例:Echo程序
下面通过ServerSocket和Socket类完成一个简单的Echo程序,Echo表示回应程序,输入的内容发送到服务器端之后,在前面加上“Echo”的字符串再返回。
对于服务器端而言,客户端的输出流是服务器端的输入流,服务器端的输出流是客户端的输入流。


那么,此时客户端的操作也应该是一样的,应该准备好输入流和输出流,而且现在的代码中存在了输入的操作,所以要使用键盘输入信息。


但是,以上的程序只适合于一个线程使用。如果有多个用户,则肯定无法同时连接,这就是传统单线程的操作。如果想要实现多线程,那么每一个客户端都应该使用线程表示出来。
开发网络程序时,如没有特殊要求,可考虑采用可序列化对象形式实现应用协议。即:直接将对象序列化为字节序列并发送至网络,接收端反序列化获得对象,可以省去大量的协议封装和解析的工作。