操作系统 第六章 文件管理
目录
0x00 文件的定义
0x01 文件的逻辑结构
0x02 文件的存取方式
0x03 文件的目录
文件目录实现的功能:
文件目录结构分类:
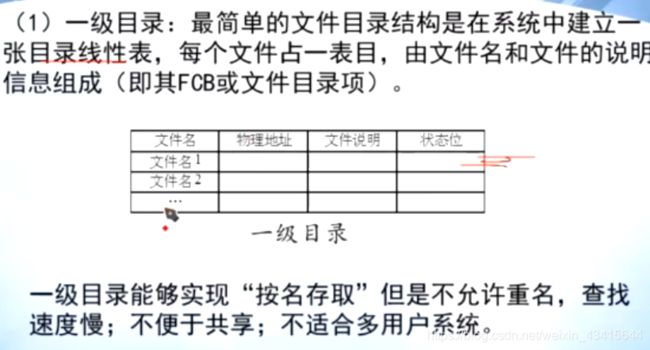
1.一级目录
2.二级目录
3.多级目录
0x04 文件共享
(1)基于索引结点的共享方式
<1>动态共享:
内存INode 和 磁盘iNode 之间的关系:
系统打开文件表:
用户(用户进程)打开文件表:
0x05 文件保护
0x06 文件控制
0x07 文件的物理结构
全章的重点!
#文件系统的一致性检查
0x08 外存空间管理
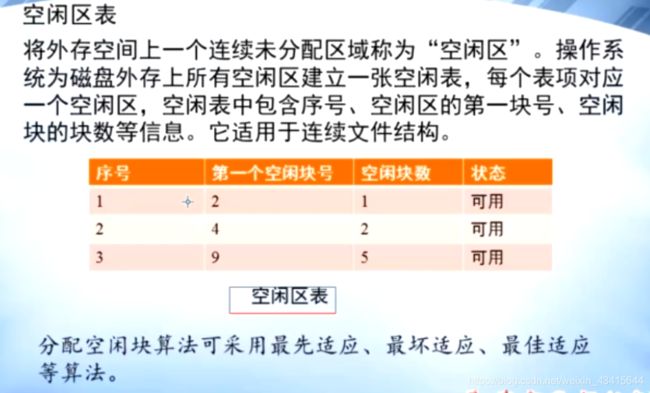
#1.空闲区表
#2.位示图
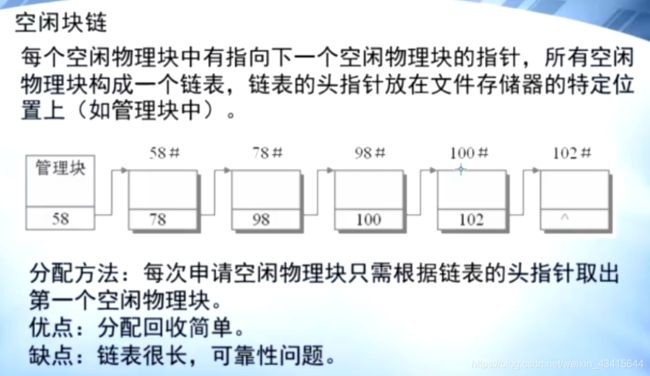
#3.空闲块链:
#4.成组链接法
0x09 磁盘管理
#循环电梯调度算法
#信息的优化分布:
0x00 文件的定义
文件的组成部分:
1.文件体:文件的真实内容
2.文案说明(FCB ):操作系统为了管理文件所用到的信息
文件系统:
0x01 文件的逻辑结构
(1)无结构的 流式文件:文件体为字节流,利用读写指针指出下一个要访问的字符。
(2)有结构的 记录式文件: 文件体由若干记录组成
例如:excel表
分为:定长记录文件 和变长记录文件
定长记录支持 顺序存取 和随机存取
变长记录支持顺序存取 ,但是随机存取困难
0x02 文件的存取方式
顺序存取
随机存取(直接存取):用户可以随意存取文件中的任何一个记录
例如 数组 就支持 随机存取 arr[3] ,这是因为每个数组项 的大小相同。
所以,流式文件 和 定长记录文件 容易支持这种 随机存取
0x03 文件的目录
文件目录:各种文件的FCB的集合
将文件目录存在 磁盘上就构成了一个目录文件,说白了就是 文件夹。
胖目录和瘦目录:
胖目录:文件名和文件说明绑在一起
瘦目录:文件名 和 文件说明(inode)分离

文件目录实现的功能:
1.实现按名存取
2.提高对目录的检索速度
3.实现文件共享
4.解决文件重名问题
文件目录结构分类:
1.一级目录
2.二级目录
每个用户都有自己的用户文件目录
然后建立一个主文件目录,存每个用户的 用户文件目录的名称和地址

优点:
1.树形结构,提高了检索目录的速度
2.在不同的用户目录下 可以有相同的文件名
3.不同用户可以访问系统中同一个共享文件,例如上图中test指向同一个
文件地址。
缺点:不能对文件分类管理
3.多级目录



问题:查找/usr/dir需要启动磁盘几次
2次。第一启动磁盘,将/下的文件目录 装入内存中
第二次启动磁盘,将/usr/下的文件目录装入内存中
这个问题,说白了就是问 要打开几次文件夹。
0x04 文件共享
为什么要共享文件?
就是为了只保留一个文件副本,节约存储空间。
文件名 和文件说明(inode)分离有利于实现 文件共享
(1)基于索引结点的共享方式
<1>动态共享:
往往出现在进程之间共享文件(多个进程之间可以以不同的或者相同的方式同时打开同一个文件)时,
进程终止则共享终止。
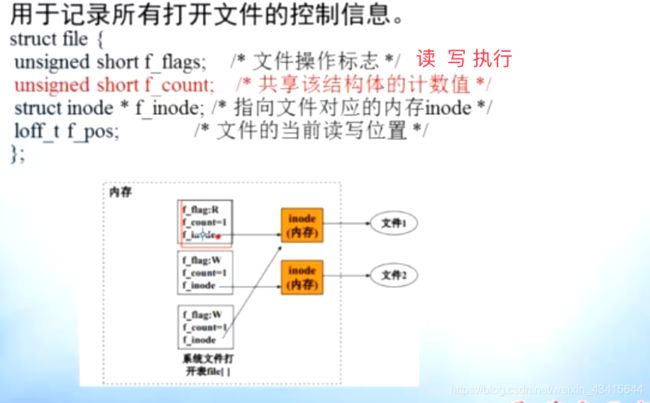
打开文件机构:
文件打开后 由 “打开文件机构管理”,关闭时退出 打开文件机构
"打开文件机构"的结构:
- 内存文件控制块(内存iNode)
- 系统打开文件表
- 用户打开文件表
- 磁盘iNode(内存iNode只是 磁盘iNode一个副本)

注意:
i_count 记录该文件被多少个进程共享
i_number 指向 该内存INode 对应的磁盘INode的地址
i_p 或者 i_addr 指向 该文件 在磁盘中的地址
磁盘iNode

内存INode 和 磁盘iNode 之间的关系:
磁盘INode存储在磁盘上
内存INode存储在内存上
当打开文件时,如果发现内存中不存在该文件的内存INode,就会将磁盘中对应的INode
拷贝一份到内存作为内存INode,如果打开文件过程中,内存INode被修改,那么当关闭
文件时,修改的内存INode将会被写入磁盘INode
当我们需要读写文件时,直接查内存INode就可以知道文件在磁盘中地址。
系统打开文件表:
f_inode 指向该文件的内存inode,
该文件的内存inode 中的i_addr 指向 磁盘中的文件
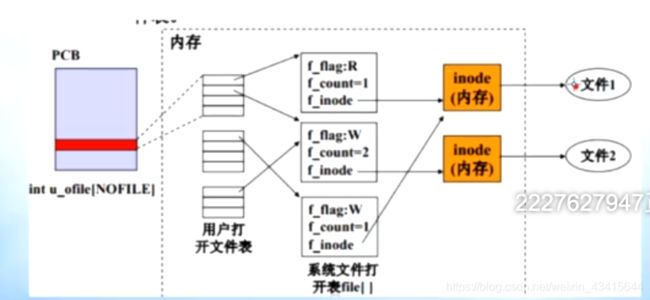
用户(用户进程)打开文件表:
用户打开文件表的表项 指向 系统打开文件表
系统打开文件表的inode 指向 内存inode
内存inode 指向 磁盘中的文件
例题:
我们在编程时, open()函数返回的文件描述符, 其实就保存在 用户进程
打开文件表中,一个进程打开多个文件就得到多个 文件描述符,这些描述
符,就规规矩矩的存在 该进程的 用户打开文件表中
文件描述符 并不是 直接文件地址
而是指向该文件对应的 系统打开文件表
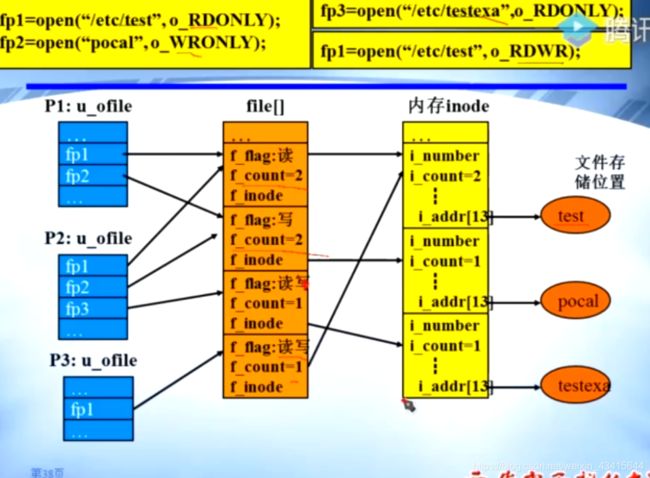
由上图可以看出:用户进程打开文件表 由 进程自己维护, 可以有多个
而系统打开文件表只能有一个,由操作系统维护。
因为两个进程的操作方式不同,所以系统打开文件表中就需要有两个表项
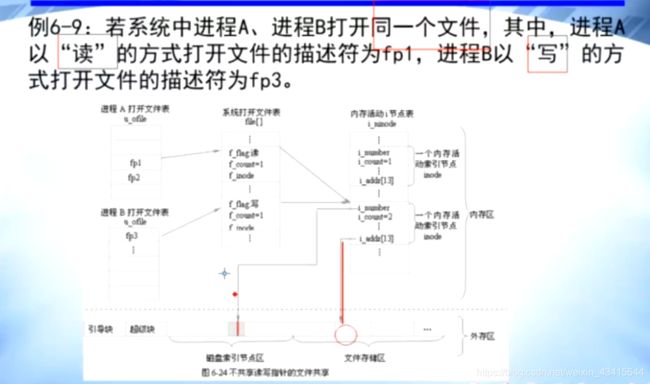
如果两个进程都是以读的方式打开同一个文件,因为操作方式相同
那么系统打开文件表中 只需要有一个表项,该表项的f_count =2

<2>静态共享
一个文件同时属于多个文件目录项(例如被多个用户共享)
并且这种关系不管文件此时是否在被使用,都存在。
硬连接共享:
两个文件目录中文件名 都指向 同一个INode,
INode指向 文件在磁盘中的地址。
例如下图中ls 和 usr 指向的都是INode 10
此时di_nlink = 2
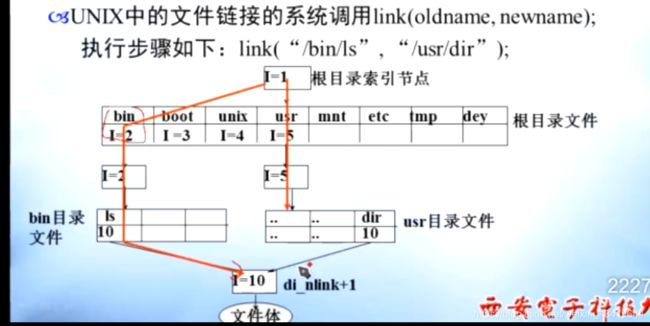
硬链接共享的缺点:
1.文件主删除文件困难,文件主删除的只是链接,不见得能删除文件本身

2.文件共享不能跨文件系统
(2)软链接(利用符号链实现文件共享)
下图中INode 11 指向的文件体 中保存的内容 其实 INode 10指向的文件的 文件路径
这样一来INode 10 和INode 11 的count 都是 1,文件主可以直接删除INode 对应的文件。
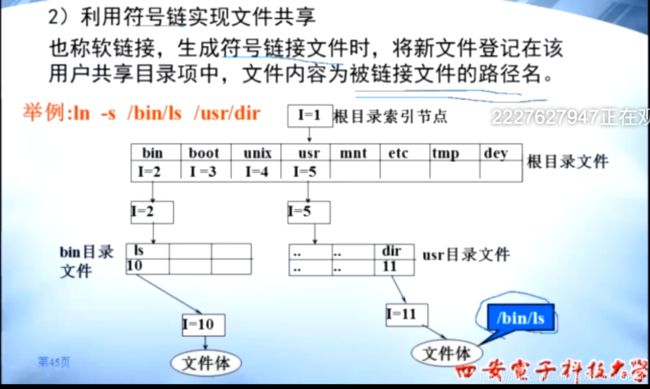


上题中 的 文件的引用计数 指的就是该文件名 指向的INode 的 count 计数。
0x05 文件保护
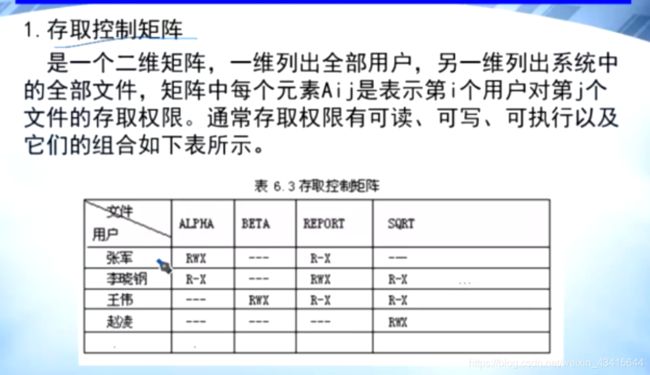
缺点:用户如果很多的话,表会非常大


0x06 文件控制



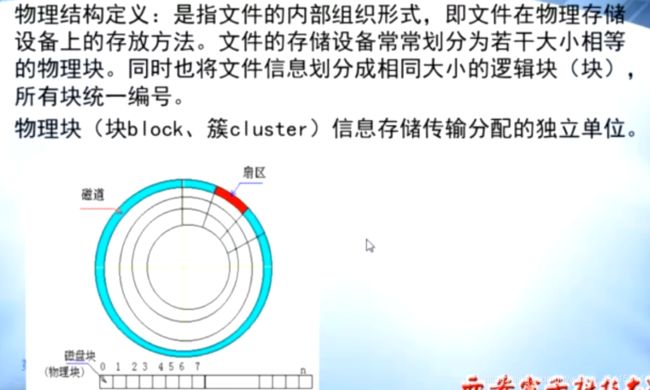
0x07 文件的物理结构
将磁盘分成若干个物理块,
将文件分成若干个相同大小的逻辑块
将逻辑块装入 物理块中
几种常见的物理存储方式:
1.连续存储:
逻辑上连续的逻辑块 放到编号连续的 物理块上

2.链接结构:

缺点:
可靠性不好,如果有一个磁盘块坏了,后面其他的文件块就找不到了
不能随机访问,比如从链表头开始往下找。

3.索引结构:


存在的问题:
如果一个物理块 大小为1K(1024字节) ,一个索引表项 3字节
那么一个物理块只能 放341个表项,对应341个物理块 ,对应341K 也就是说如果一个
文件的大小大于341K,那么它生成的表项 将 不能装入一个 物理块中。

解决方法:
(1)将索引表 以链表的形式组织起来

(2)多级索引方式

unix系统采用的文件物理结构:三级索引结构

unix 中分配一个 文件的文件索引表的大小只有40个字节,一个表项 3个字节
也就说只能 有13个表项

全章的重点!
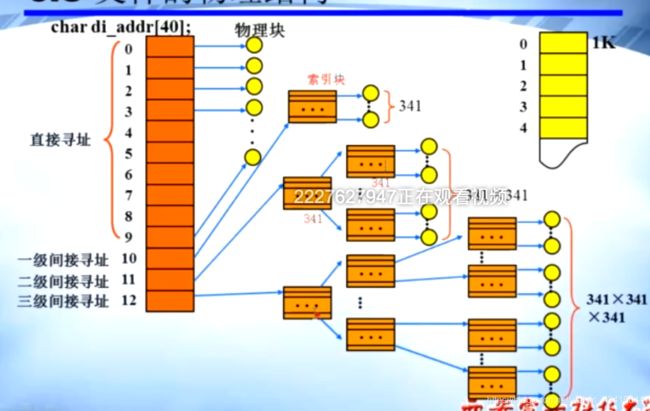
一个磁盘数据块 (256/4) = 64 个表项
4*256 + 2 * 64 * 256 + 1*64 *64 *256 = 1057KB


冲突: 多个值对应同一个键
拉链法: 将对应同一个键的值用链表串起来
#文件系统的一致性检查

表一中:1表示 该块正在使用
表二中:1表示该块处于空闲状态
所以,正常情况下 不能一个物理块 既是空闲 又 在使用。
下图中,物理块2,即没有在使用 又 不是空闲状态, 说明该物理块没有被登记,即已经丢失

上图中第5块,两张表中都是1,表一中的1表示 该物理块 正在被使用
表2中的块表示 该物理块 可以被 分配给 其他文件,这样就可能导致两个文件同时向
该物理块写入数据。

0x08 外存空间管理
文件系统 对外存 空间的管理: 实际上 就是 对空闲块的组织和管理问题
常用的空闲空间管理方法:
1.空闲区表
2.位示图
3.空闲块链
#1.空闲区表
#2.位示图


例题:
注意:从1开始编号
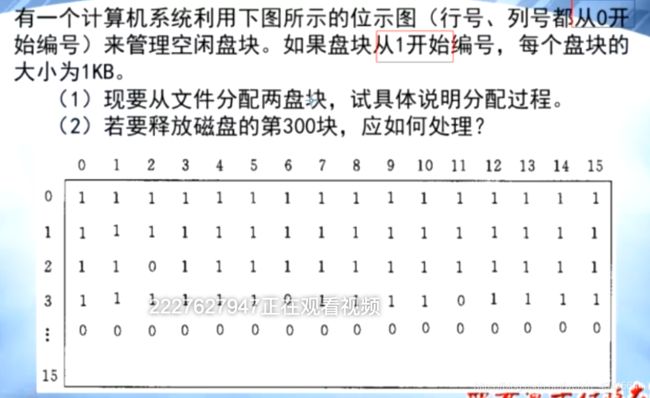
 3
3
#3.空闲块链:
#4.成组链接法
空闲链表法导致 链表很长, 一块丢失就可能造成 整个链条断裂,不利于维护
成组链接法,先将空闲块100块分成一组,然后每个组用链表链接起来。
(每组的第一个空闲块 用于记录下一组的 物理盘块号 和 本组的空闲块数)
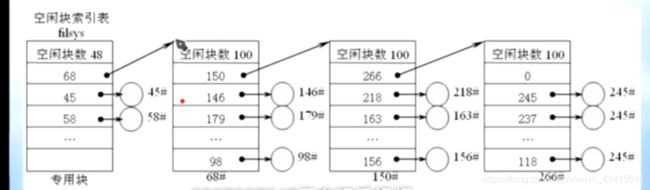
空闲盘块号栈:这个要读入内存
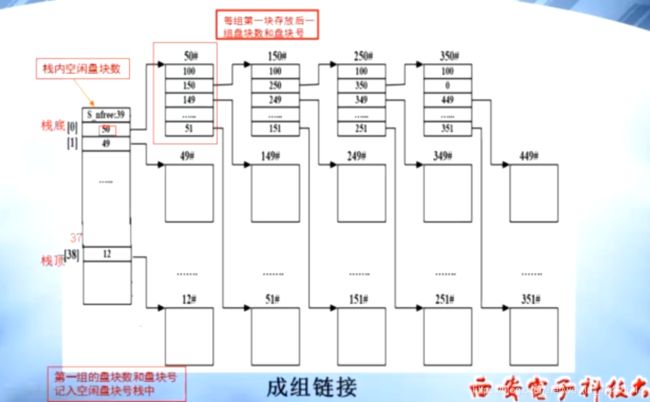
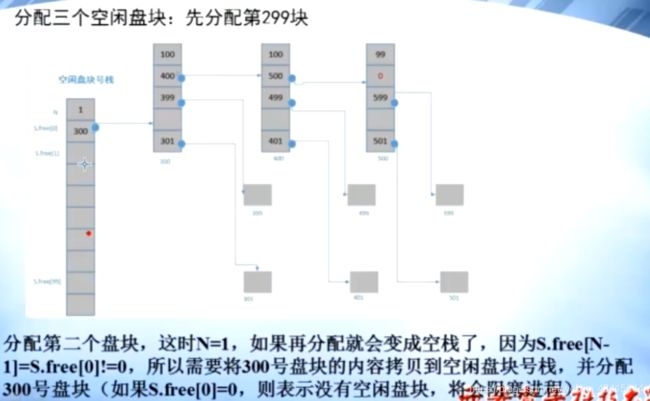
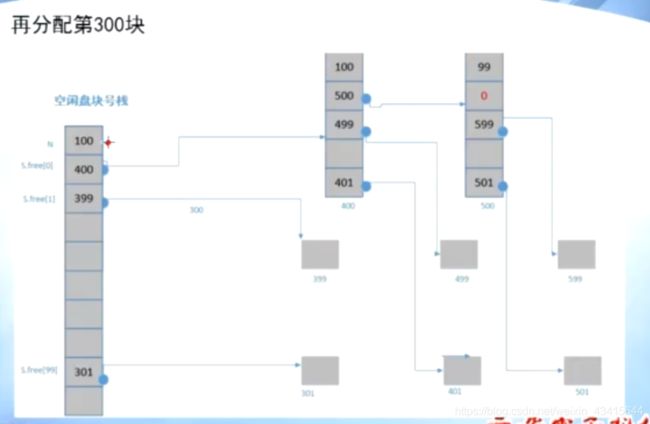
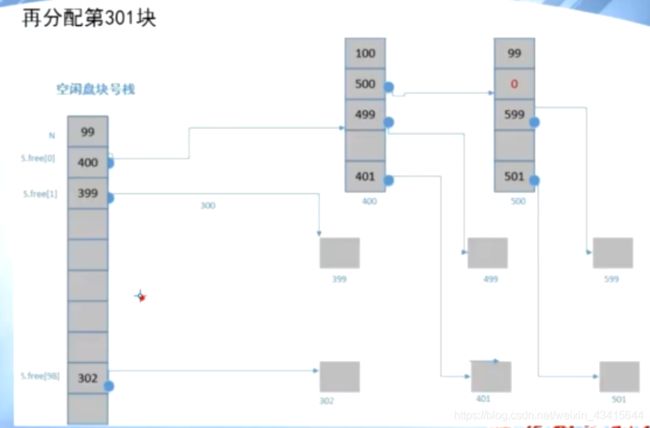
分配算法:
首相将一组空闲块 读入 到 内存中的 空闲盘块号栈中
当系统需要 空闲块 时,就从 此栈 pop 一个 元素,该元素指向一个 物理块
如果 栈中只有 一个 元素了,就检查该元素是否为0
如果为0则表示没有空闲块了
否则,就读取该元素指向的 一组空闲块 ,将其push 到 空闲盘块号栈中

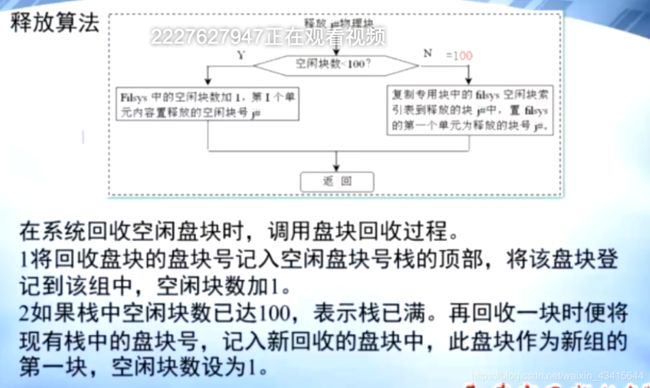
释放算法:
当系统产生新的空闲块时,
首先看 栈 中空闲块是否小于100,如果是,则将 新的空闲块直接push到栈中即可
否则,说明栈已经满了,因此将栈中现有块 作为一组,存入磁盘,在栈中保留一个指向
该组的元素即可。
例题:
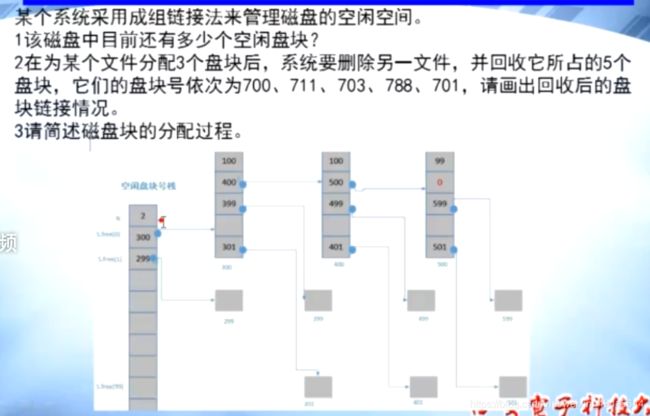
(1)2+100+100+99= 301
注意:最后一组的0不算空闲盘块,这里问的是空闲盘块数,而不是物理盘块数
每组的第一个空闲盘块也是指向物理盘块的,但是该物理块中保存了下一组的地址 和 空闲盘块的总数
(2)
分配3个空闲盘块,299,300,301
注意:第300块也被分配了
回收5块:
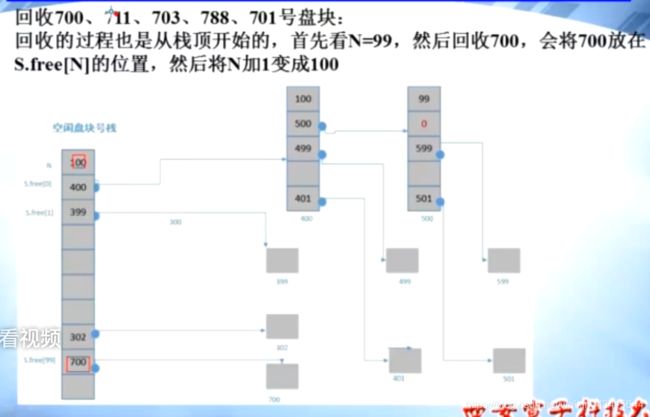
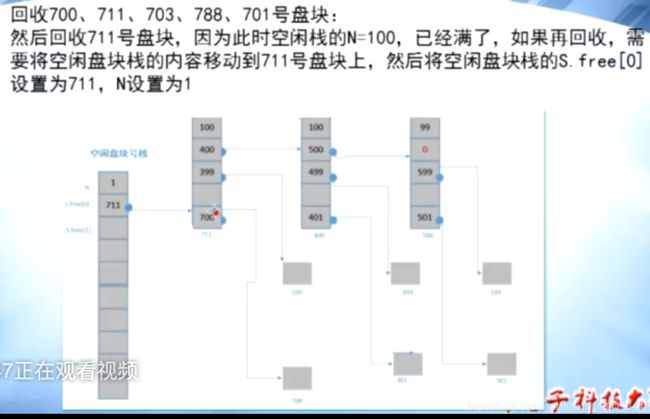
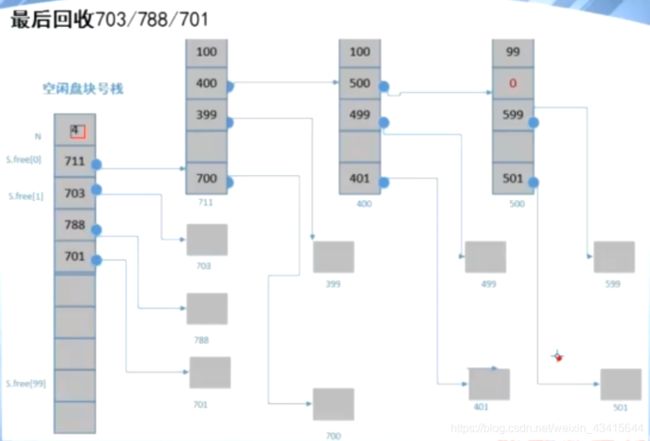
0x09 磁盘管理

磁盘高速缓存:
磁盘:
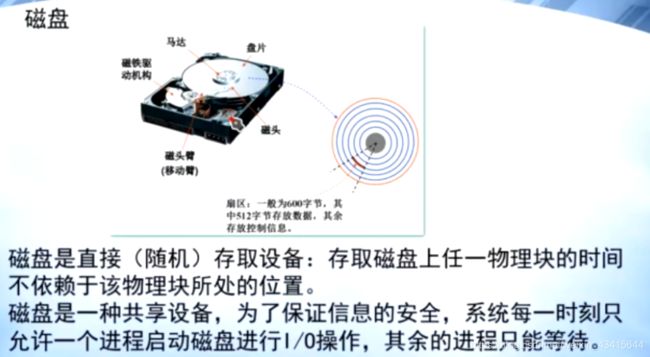
磁盘的构造:
一个盘面上下 两个 磁头
要确定一个物理块的地址:
首先要确定 磁头号,然后确定 磁道号,然后确定扇区号

磁盘调度算法:

数据传输时间可以忽略。
#磁盘移臂调度算法:

例如:

答案:建议考试时带上计算器
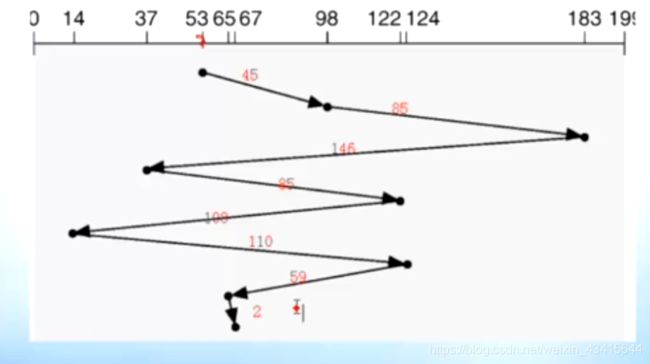
#最短寻道时间优先 Shortest Seek Time First

#电梯调度算法
#scan算法

例如65 ,这时,磁头正在往 0 方向走,虽然65距离53很近,但是需要等很久。
#look算法
到最远请求就折返
#循环电梯调度算法
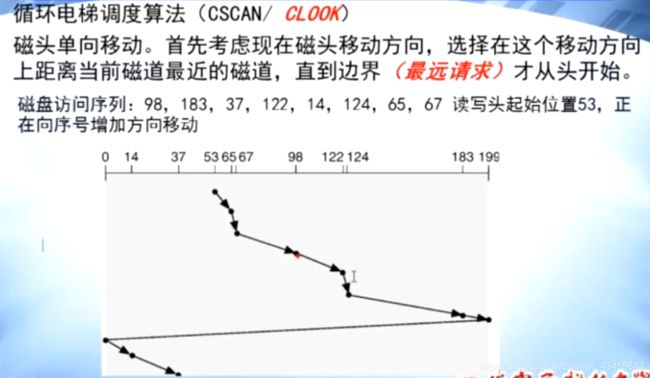
例题:

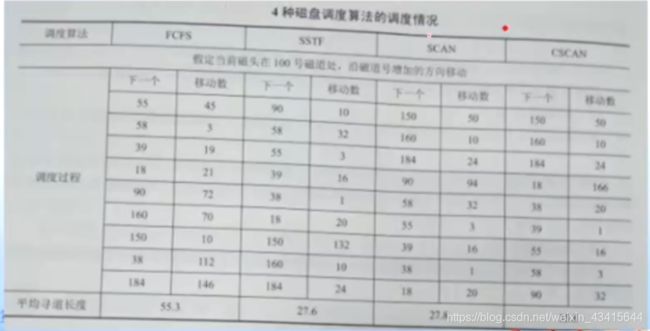
总结:
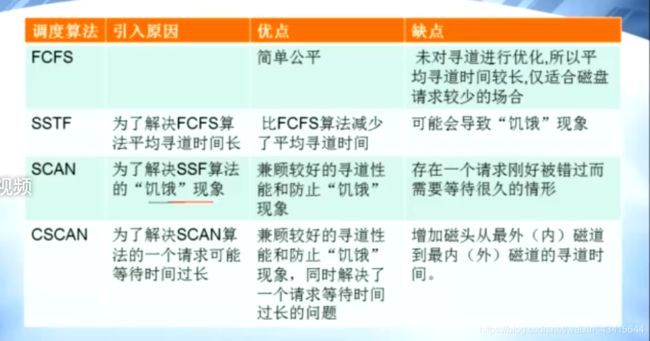
#旋转调度算法:
当移动臂找到磁道后,移动臂就不动了,依靠磁盘的旋转来找到对应的扇区
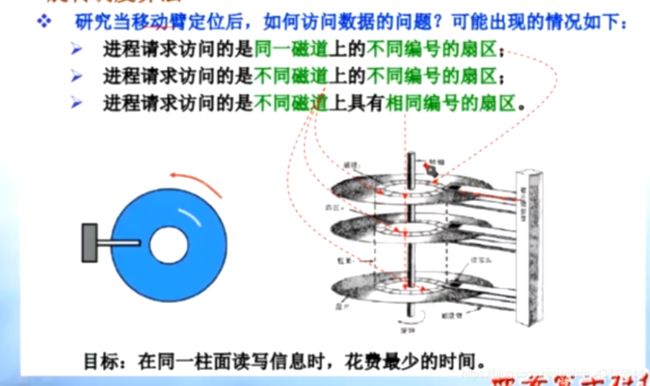

例题:
当移动 臂已经移动到一个磁道后,影响时间花费就只有 访问扇区号 的先后了

本地从小到大访问扇区号即可,因为 有两个6号扇区,可以随机选一个先访问。
因为先下压那个磁头并不会造成花费时间的不同,但是没有被选中的那个
就需要下一圈时才能访问了。

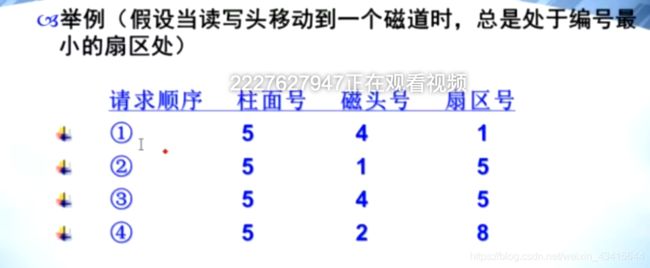
访问顺序:1 2 4 3 或者 13 42
因为第一圈 2 和 3 只能选一个访问,下一个必须留到第二圈访问
#信息的优化分布:
磁盘调度算法可以减少访问时间,优化数据的分布 也可以减少访问时间
物理块分布优化
索引节点分布优化
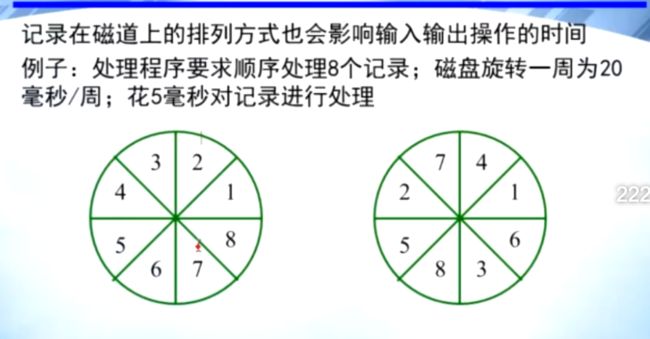
磁盘转一周20ms ,一共8个扇区,转过一个扇区需要2.5s
但是磁盘处理一个扇区的信息需要5ms
所以按照第一种信息排布方式,磁头在读取1号扇区后,需要等待5ms才能继续读2号,
但是磁盘这时并不会停下来等5ms,而是会继续转动,这样一来,磁头就不得不等到
磁盘转第二圈才能读取2号扇区。
所以优化为第二种信息分布方式,磁头在读取1号扇区后,5ms中处理信息的时间 正好
可以用来滑过 4,7两个扇区。
优化方法:处理信息时间能转几个扇区,就在相邻扇区之间间隔几个扇区
第五章测试讲解:1:18 5-14