grpc
分布式一致性算法2PC和3PC

莫名2013 关注 0人评论 61596人阅读 2018-01-08 16:21:10
为了解决分布式一致性问题,产生了不少经典的分布式一致性算法,本文将介绍其中的2PC和3PC。2PC即Two-Phase Commit,译为二阶段提交协议。3PC即Three-Phase Commit,译为三阶段提交协议。
分布式系统和分布式一致性问题
分布式系统,即运行在多台不同的网络计算机上的软硬件系统,并且仅通过消息传递来进行通信和协调。
分布式一致性问题,即相互独立的节点之间如何就一项决议达成一致的问题。
2PC
2PC,二阶段提交协议,即将事务的提交过程分为两个阶段来进行处理:准备阶段和提交阶段。
事务的发起者称协调者,事务的执行者称参与者。
阶段1:准备阶段
1、协调者向所有参与者发送事务内容,询问是否可以提交事务,并等待所有参与者答复。
2、各参与者执行事务操作,将Undo和Redo信息记入事务日志中(但不提交事务)。
3、如参与者执行成功,给协调者反馈YES,即可以提交;如执行失败,给协调者反馈NO,即不可提交。
阶段2:提交阶段
此阶段分两种情况:所有参与者均反馈YES、或任何一个参与者反馈NO。
所有参与者均反馈YES时,即提交事务。
任何一个参与者反馈NO时,即中断事务。
提交事务:(所有参与者均反馈YES)
1、协调者向所有参与者发出正式提交事务的请求(即Commit请求)。
2、参与者执行Commit请求,并释放整个事务期间占用的资源。
3、各参与者向协调者反馈Ack完成的消息。
4、协调者收到所有参与者反馈的Ack消息后,即完成事务提交。
附如下示意图:

中断事务:(任何一个参与者反馈NO)
1、协调者向所有参与者发出回滚请求(即Rollback请求)。
2、参与者使用阶段1中的Undo信息执行回滚操作,并释放整个事务期间占用的资源。
3、各参与者向协调者反馈Ack完成的消息。
4、协调者收到所有参与者反馈的Ack消息后,即完成事务中断。
附如下示意图:

2PC的缺陷
1、同步阻塞:最大的问题即同步阻塞,即:所有参与事务的逻辑均处于阻塞状态。
2、单点:协调者存在单点问题,如果协调者出现故障,参与者将一直处于锁定状态。
3、脑裂:在阶段2中,如果只有部分参与者接收并执行了Commit请求,会导致节点数据不一致。
由于2PC存在如上同步阻塞、单点、脑裂问题,因此又出现了2PC的改进方案,即3PC。
3PC
3PC,三阶段提交协议,是2PC的改进版本,即将事务的提交过程分为CanCommit、PreCommit、do Commit三个阶段来进行处理。
阶段1:CanCommit
1、协调者向所有参与者发出包含事务内容的CanCommit请求,询问是否可以提交事务,并等待所有参与者答复。
2、参与者收到CanCommit请求后,如果认为可以执行事务操作,则反馈YES并进入预备状态,否则反馈NO。
阶段2:PreCommit
此阶段分两种情况:
1、所有参与者均反馈YES,即执行事务预提交。
2、任何一个参与者反馈NO,或者等待超时后协调者尚无法收到所有参与者的反馈,即中断事务。
事务预提交:(所有参与者均反馈YES时)
1、协调者向所有参与者发出PreCommit请求,进入准备阶段。
2、参与者收到PreCommit请求后,执行事务操作,将Undo和Redo信息记入事务日志中(但不提交事务)。
3、各参与者向协调者反馈Ack响应或No响应,并等待最终指令。
中断事务:(任何一个参与者反馈NO,或者等待超时后协调者尚无法收到所有参与者的反馈时)
1、协调者向所有参与者发出abort请求。
2、无论收到协调者发出的abort请求,或者在等待协调者请求过程中出现超时,参与者均会中断事务。
阶段3:do Commit
此阶段也存在两种情况:
1、所有参与者均反馈Ack响应,即执行真正的事务提交。
2、任何一个参与者反馈NO,或者等待超时后协调者尚无法收到所有参与者的反馈,即中断事务。
提交事务:(所有参与者均反馈Ack响应时)
1、如果协调者处于工作状态,则向所有参与者发出do Commit请求。
2、参与者收到do Commit请求后,会正式执行事务提交,并释放整个事务期间占用的资源。
3、各参与者向协调者反馈Ack完成的消息。
4、协调者收到所有参与者反馈的Ack消息后,即完成事务提交。
中断事务:(任何一个参与者反馈NO,或者等待超时后协调者尚无法收到所有参与者的反馈时)
1、如果协调者处于工作状态,向所有参与者发出abort请求。
2、参与者使用阶段1中的Undo信息执行回滚操作,并释放整个事务期间占用的资源。
3、各参与者向协调者反馈Ack完成的消息。
4、协调者收到所有参与者反馈的Ack消息后,即完成事务中断。
注意:进入阶段三后,无论协调者出现问题,或者协调者与参与者网络出现问题,都会导致参与者无法接收到协调者发出的do Commit请求或abort请求。此时,参与者都会在等待超时之后,继续执行事务提交。
附示意图如下:

3PC的优点和缺陷
优点:降低了阻塞范围,在等待超时后协调者或参与者会中断事务。避免了协调者单点问题,阶段3中协调者出现问题时,参与者会继续提交事务。
缺陷:脑裂问题依然存在,即在参与者收到PreCommit请求后等待最终指令,如果此时协调者无法与参与者正常通信,会导致参与者继续提交事务,造成数据不一致。
后记
无论2PC或3PC,均无法彻底解决分布式一致性问题。
解决一致性问题,唯有Paxos,后续将单独总结。
===========================================================================================================================================================================================================================================================================
RocketMQ支持事务消息机制

wxxy20071547
1.6 2018.07.03 19:24* 字数 4480 阅读 10849评论 14喜欢 25赞赏 1
事务消费
我们经常支付宝转账余额宝,这是日常生活的一件普通小事,但是我们思考支付宝扣除转账的钱之后,如果系统挂掉怎么办,这时余额宝账户并没有增加相应的金额,数据就会出现不一致状况了。
上述场景在各个类型的系统中都能找到相似影子,比如在电商系统中,当有用户下单后,除了在订单表插入一条记录外,对应商品表的这个商品数量必须减1吧,怎么保证?!在搜索广告系统中,当用户点击某广告后,除了在点击事件表中增加一条记录外,还得去商家账户表中找到这个商家并扣除广告费吧,怎么保证?!等等,相信大家或多或多少都能碰到相似情景。
本质上问题可以抽象为:当一个表数据更新后,怎么保证另一个表的数据也必须要更新成功。
如果是单机系统(数据库实例也在同一个系统上)的话,我们可以用本地事务轻松解决:
还是以支付宝转账余额宝为例(比如转账10000块钱),假设有
支付宝账户表:A(id,userId,amount)
余额宝账户表:B(id,userId,amount)
用户的userId=1;
从支付宝转账1万块钱到余额宝的动作分为两步:
1)支付宝表扣除1万:update A set amount=amount-10000 where userId=1;
2)余额宝表增加1万:update B set amount=amount+10000 where userId=1;
如何确保支付宝余额宝收支平衡呢?
有人说这个很简单嘛,可以用事务解决。
Begin transaction
update A set amount=amount-10000 where userId=1;
update B set amount=amount+10000 where userId=1;
End transaction
commit;
这样确实能解决,如果你使用spring的话一个注解就能搞定上述事务功能。
@Transactional(rollbackFor=Exception.class)
public void update() {
updateATable();
//更新A表
updateBTable();
//更新B表
}
如果系统规模较小,数据表都在一个数据库实例上,上述本地事务方式可以很好地运行,但是如果系统规模较大,比如支付宝账户表和余额宝账户表显然不会在同一个数据库实例上,他们往往分布在不同的物理节点上,这时本地事务已经失去用武之地。
下面我们来看看比较主流的两种方案:
1.分布式事务—————— 两阶段提交协议
两阶段提交协议(Two-phase Commit,2PC)经常被用来实现分布式事务。一般分为协调器TC和若干事务执行者两种角色,这里的事务执行者就是具体的数据库,协调器可以和事务执行器在一台机器上。

业余学习之RocketMQ中级篇
我们根据上面的图来看看主要流程:
1) 我们的应用程序(client)发起一个开始请求到TC(transaction);
2) TC先将prepare消息写到本地日志,之后向所有的Si发起prepare消息。以支付宝转账到余额宝为例,TC给A的prepare消息是通知支付宝数据库相应账目扣款1万,TC给B的prepare消息是通知余额宝数据库相应账目增加1w。为什么在执行任务前需要先写本地日志,主要是为了故障后恢复用,本地日志起到现实生活中凭证的效果,如果没有本地日志(凭证),出问题容易死无对证;
3) Si收到prepare消息后,执行具体本机事务,但不会进行commit,如果成功返回yes,不成功返回no。同理,返回前都应把要返回的消息写到日志里,当作凭证。
4) TC收集所有执行器返回的消息,如果所有执行器都返回yes,那么给所有执行器发生送commit消息,执行器收到commit后执行本地事务的commit操作;如果有任一个执行器返回no,那么给所有执行器发送abort消息,执行器收到abort消息后执行事务abort操作。
注:TC或Si把发送或接收到的消息先写到日志里,主要是为了故障后恢复用。如某一Si从故障中恢复后,先检查本机的日志,如果已收到commit,则提交,如果abort则回滚。如果是yes,则再向TC询问一下,确定下一步。如果什么都没有,则很可能在prepare阶段Si就崩溃了,因此需要回滚。
现如今实现基于两阶段提交的分布式事务也没那么困难了,如果使用java,那么可以使用开源软件atomikos(http://www.atomikos.com/)来快速实现。来快速实现。)
不过但凡使用过的上述两阶段提交的同学都可以发现性能实在是太差,根本不适合高并发的系统。为什么?
1)两阶段提交涉及多次节点间的网络通信,通信时间太长!
2)事务时间相对于变长了,锁定的资源的时间也变长了,造成资源等待时间也增加好多!
正是由于分布式事务存在很严重的性能问题,大部分高并发服务都在避免使用,往往通过其他途径来解决数据一致性问题。
2.使用消息队列来避免分布式事务
如果仔细观察生活的话,生活的很多场景已经给了我们提示。
比如在北京很有名的姚记炒肝点了炒肝并付了钱后,他们并不会直接把你点的炒肝给你,而是给你一张小票,然后让你拿着小票到出货区排队去取。为什么他们要将付钱和取货两个动作分开呢?原因很多,其中一个很重要的原因是为了使他们接待能力增强(并发量更高)。
还是回到我们的问题,只要这张小票在,你最终是能拿到炒肝的。同理转账服务也是如此,当支付宝账户扣除1万后,我们只要生成一个凭证(消息)即可,这个凭证(消息)上写着“让余额宝账户增加1万”,只要这个凭证(消息)能可靠保存,我们最终是可以拿着这个凭证(消息)让余额宝账户增加1万的,即我们能依靠这个凭证(消息)完成最终一致性。
那么我们如何可靠保存凭证(消息)有两种方法:
1.业务与消息耦合的方式
支付宝在完成扣款的同时,同时记录消息数据,这个消息数据与业务数据保存在同一数据库实例里(消息记录表表名为message)。
Begin transaction
update A set amount=amount-10000 where userId=1;
insert into message(userId, amount,status) values(1, 10000, 1);
End transaction
commit;
上述事务能保证只要支付宝账户里被扣了钱,消息一定能保存下来。
当上述事务提交成功后,我们通过实时消息服务将此消息通知余额宝,余额宝处理成功后发送回复成功消息,支付宝收到回复后删除该条消息数据。
2.业务与消息解耦方式
上述保存消息的方式使得消息数据和业务数据紧耦合在一起,从架构上看不够优雅,而且容易诱发其他问题。为了解耦,可以采用以下方式。
1)支付宝在扣款事务提交之前,向实时消息服务请求发送消息,实时消息服务只记录消息数据,而不真正发送,只有消息发送成功后才会提交事务;
2)当支付宝扣款事务被提交成功后,向实时消息服务确认发送。只有在得到确认发送指令后,实时消息服务才真正发送该消息;
3)当支付宝扣款事务提交失败回滚后,向实时消息服务取消发送。在得到取消发送指令后,该消息将不会被发送;
4)对于那些未确认的消息或者取消的消息,需要有一个消息状态确认系统定时去支付宝系统查询这个消息的状态并进行更新。为什么需要这一步骤,举个例子:假设在第2步支付宝扣款事务被成功提交后,系统挂了,此时消息状态并未被更新为“确认发送”,从而导致消息不能被发送。
优点:消息数据独立存储,降低业务系统与消息系统间的耦合;
缺点:一次消息发送需要两次请求;业务处理服务需要实现消息状态回查接口。
那么如何解决消息重复投递的问题?
还有一个很严重的问题就是消息重复投递,以我们支付宝转账到余额宝为例,如果相同的消息被重复投递两次,那么我们余额宝账户将会增加2万而不是1万了(上面讲顺序消费是讲过,这里再提一下)。
为什么相同的消息会被重复投递?比如余额宝处理完消息msg后,发送了处理成功的消息给支付宝,正常情况下支付宝应该要删除消息msg,但如果支付宝这时候悲剧的挂了,重启后一看消息msg还在,就会继续发送消息msg。
解决方法很简单,在余额宝这边增加消息应用状态表(message_apply),通俗来说就是个账本,用于记录消息的消费情况,每次来一个消息,在真正执行之前,先去消息应用状态表中查询一遍,如果找到说明是重复消息,丢弃即可,如果没找到才执行,同时插入到消息应用状态表(同一事务) 。
for each msg in queue
Begin transaction
select count(*) as cnt from message_apply where msg_id=msg.msg_id;
if cnt==0 then
update B set amount=amount+10000 where userId=1;
insert into message_apply(msg_id) values(msg.msg_id);
End transaction
commit;
为了方便大家理解,我们再来举一个银行转账的示例(和上一个例子差不多):
比如,Bob向Smith转账100块。
在单机环境下,执行事务的情况,大概是下面这个样子:

业余学习之RocketMQ中级篇
当用户增长到一定程度,Bob和Smith的账户及余额信息已经不在同一台服务器上了,那么上面的流程就变成了这样:
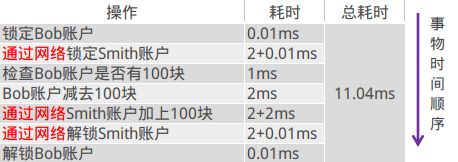
业余学习之RocketMQ中级篇
这时候你会发现,同样是一个转账的业务,在集群环境下,耗时居然成倍的增长,这显然是不能够接受的。那如何来规避这个问题?
大事务 = 小事务 + 异步
将大事务拆分成多个小事务异步执行。这样基本上能够将跨机事务的执行效率优化到与单机一致。转账的事务就可以分解成如下两个小事务:

业余学习之RocketMQ中级篇
图中执行本地事务(Bob账户扣款)和发送异步消息应该保证同时成功或者同时失败,也就是扣款成功了,发送消息一定要成功,如果扣款失败了,就不能再发送消息。那问题是:我们是先扣款还是先发送消息呢?
首先看下先发送消息的情况,大致的示意图如下:
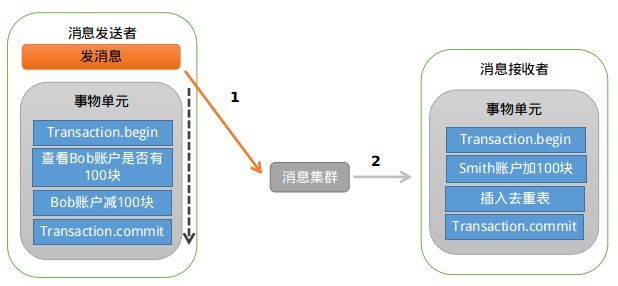
业余学习之RocketMQ中级篇
存在的问题是:如果消息发送成功,但是扣款失败,消费端就会消费此消息,进而向Smith账户加钱。
先发消息不行,那就先扣款吧,大致的示意图如下:
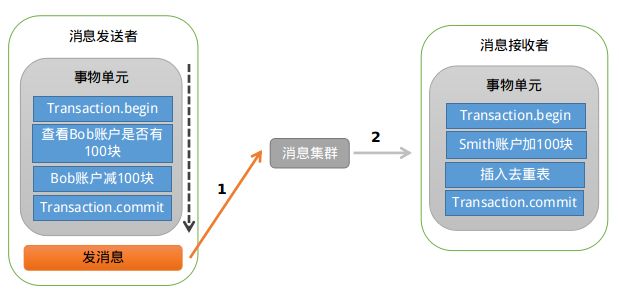
业余学习之RocketMQ中级篇
存在的问题跟上面类似:如果扣款成功,发送消息失败,就会出现Bob扣钱了,但是Smith账户未加钱。
可能大家会有很多的方法来解决这个问题,比如:直接将发消息放到Bob扣款的事务中去,如果发送失败,抛出异常,事务回滚。这样的处理方式也符合“恰好”不需要解决的原则。
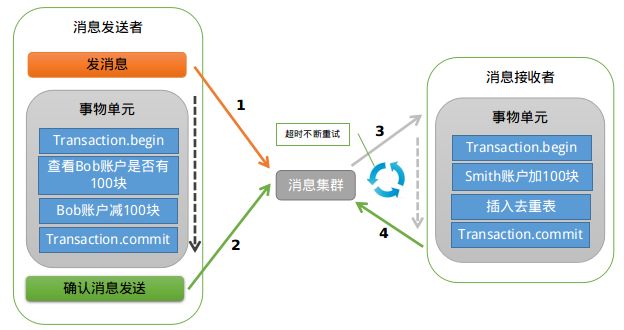
RocketMQ支持事务消息,下面来看看RocketMQ是怎样来实现的?
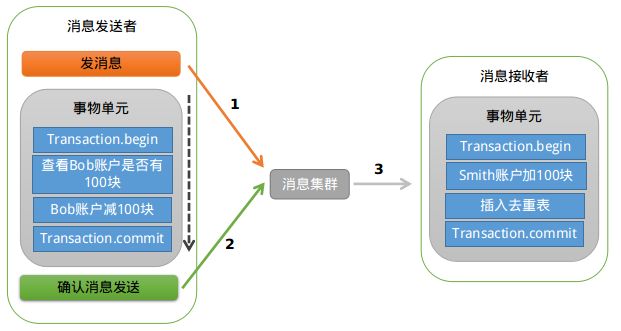
业余学习之RocketMQ中级篇
RocketMQ第一阶段发送Prepared消息时,会拿到消息的地址,第二阶段执行本地事物,第三阶段通过第一阶段拿到的地址去访问消息,并修改消息的状态。
细心的你可能又发现问题了,如果确认消息发送失败了怎么办?RocketMQ会定期扫描消息集群中的事物消息,如果发现了Prepared消息,它会向消息发送端(生产者)确认,Bob的钱到底是减了还是没减呢?如果减了是回滚还是继续发送确认消息呢?
RocketMQ会根据发送端设置的策略来决定是回滚还是继续发送确认消息。这样就保证了消息发送与本地事务同时成功或同时失败。
那我们来看下RocketMQ源码,是如何处理事务消息的。
客户端发送事务消息的部分(完整代码请查看:rocketmq-example工程下的com.alibaba.rocketmq.example.transaction.TransactionProducer)
// =============================发送事务消息的一系列准备工作========================================
// 未决事务,MQ服务器回查客户端
// 也就是上文所说的,当RocketMQ发现`Prepared消息`时,会根据这个Listener实现的策略来决断事务
TransactionCheckListener transactionCheckListener = new TransactionCheckListenerImpl();
// 构造事务消息的生产者
TransactionMQProducer producer = new TransactionMQProducer("groupName");
// 设置事务决断处理类
producer.setTransactionCheckListener(transactionCheckListener);
// 本地事务的处理逻辑,相当于示例中检查Bob账户并扣钱的逻辑
TransactionExecuterImpl tranExecuter = new TransactionExecuterImpl();
producer.start()
// 构造MSG,省略构造参数
Message msg = new Message(......);
// 发送消息
SendResult sendResult = producer.sendMessageInTransaction(msg, tranExecuter, null);
producer.shutdown();
接着查看sendMessageInTransaction方法的源码,总共分为3个阶段:发送Prepared消息、执行本地事务、发送确认消息。
// ================================事务消息的发送过程=============================================
public TransactionSendResult sendMessageInTransaction(.....) {
// 逻辑代码,非实际代码
// 1.发送消息
sendResult = this.send(msg);
// sendResult.getSendStatus() == SEND_OK
// 2.如果消息发送成功,处理与消息关联的本地事务单元
LocalTransactionState localTransactionState = tranExecuter.executeLocalTransactionBranch(msg, arg);
// 3.结束事务
this.endTransaction(sendResult, localTransactionState, localException);
}
endTransaction方法会将请求发往broker(mq server)去更新事务消息的最终状态:
1.根据sendResult找到Prepared消息 ,sendResult包含事务消息的ID
2.根据localTransaction更新消息的最终状态
如果endTransaction方法执行失败,数据没有发送到broker,导致事务消息的 状态更新失败,broker会有回查线程定时(默认1分钟)扫描每个存储事务状态的表格文件,如果是已经提交或者回滚的消息直接跳过,如果是prepared状态则会向Producer发起CheckTransaction请求,Producer会调用DefaultMQProducerImpl.checkTransactionState()方法来处理broker的定时回调请求,而checkTransactionState会调用我们的事务设置的决断方法来决定是回滚事务还是继续执行,最后调用endTransactionOneway让broker来更新消息的最终状态。
再回到转账的例子,如果Bob的账户的余额已经减少,且消息已经发送成功,Smith端开始消费这条消息,这个时候就会出现消费失败和消费超时两个问题,解决超时问题的思路就是一直重试,直到消费端消费消息成功,整个过程中有可能会出现消息重复的问题,按照前面的思路解决即可。
业余学习之RocketMQ中级篇
消费事务消息
这样基本上可以解决消费端超时问题,但是如果消费失败怎么办?阿里提供给我们的解决方法是:人工解决。大家可以考虑一下,按照事务的流程,因为某种原因Smith加款失败,那么需要回滚整个流程。如果消息系统要实现这个回滚流程的话,系统复杂度将大大提升,且很容易出现Bug,估计出现Bug的概率会比消费失败的概率大很多。这也是RocketMQ目前暂时没有解决这个问题的原因,在设计实现消息系统时,我们需要衡量是否值得花这么大的代价来解决这样一个出现概率非常小的问题,这也是大家在解决疑难问题时需要多多思考的地方。
我们需要注意的是,在3.2.6版本中移除了事务消息的实现,所以此版本不支持事务消息。也就是说,消息失败不会进行检查。
下面我们来看一个简单的例子:
Consumer
public class Consumer {
public static void main(String[] args) throws MQClientException {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("transaction_producer");
consumer.setNamesrvAddr("192.168.1.114:9876;192.168.1.115:9876;192.168.1.116:9876;192.168.1.116:9876");
/**
* 设置Consumer第一次启动是从队列头部开始消费还是队列尾部开始消费
* 如果非第一次启动,那么按照上次消费的位置继续消费
*/
consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_FIRST_OFFSET);
consumer.subscribe("TopicTransaction", "*");
consumer.registerMessageListener(new MessageListenerOrderly() {
private Random random = new Random();
@Override
public ConsumeOrderlyStatus consumeMessage(List msgs, ConsumeOrderlyContext context) {
//设置自动提交
context.setAutoCommit(true);
for (MessageExt msg:msgs){
System.out.println(msg+ " , content : "+ new String(msg.getBody()));
}
try {
//模拟业务处理
TimeUnit.SECONDS.sleep(random.nextInt(5));
}catch (Exception e){
e.printStackTrace();
return ConsumeOrderlyStatus.SUSPEND_CURRENT_QUEUE_A_MOMENT;
}
return ConsumeOrderlyStatus.SUCCESS;
}
});
consumer.start();
System.out.println("consumer start ! ");
}
}
Producer
public class Producer {
public static void main(String[] args) throws MQClientException, InterruptedException {
String group_name = "transaction_producer";
final TransactionMQProducer producer = new TransactionMQProducer(group_name);
//namesev服务
producer.setNamesrvAddr("192.168.1.114:9876;192.168.1.115:9876;192.168.1.116:9876;192.168.1.116:9876");
//事务回查最小并发数
producer.setCheckThreadPoolMinSize(5);
//事务回查最大并发数
producer.setCheckThreadPoolMaxSize(20);
//队列数
producer.setCheckRequestHoldMax(2000);
producer.start();
//服务器回调producer,检查本地事务分支成功还是失败
producer.setTransactionCheckListener(new TransactionCheckListener() {
@Override
public LocalTransactionState checkLocalTransactionState(MessageExt messageExt) {
System.out.println("state --" + new String(messageExt.getBody()));
return LocalTransactionState.COMMIT_MESSAGE;
}
});
TransactionExecuterImpl transactionExecuter = new TransactionExecuterImpl();
for (int i = 0; i < 2; i++) {
Message msg = new Message("TopicTransaction",
"Transaction" + i,
("Hello RocketMq" + i).getBytes()
);
SendResult sendResult = producer.sendMessageInTransaction(msg, transactionExecuter, "tq");
System.out.println(sendResult);
TimeUnit.MICROSECONDS.sleep(1000);
}
Runtime.getRuntime().addShutdownHook(new Thread(new Runnable() {
@Override
public void run() {
producer.shutdown();
}
}));
System.exit(0);
}
}
TransactionCheckListenerImpl
/**
* 执行本地事务,由客户端回调
*/
public class TransactionExecuterImpl implements LocalTransactionExecuter{
@Override
public LocalTransactionState executeLocalTransactionBranch(Message msg, Object arg) {
System.out.println("msg=" + new String(msg.getBody()));
System.out.println("arg = "+arg);
String tag = msg.getTags();
if (tag.equals("Transaction1")){
//这里有一个分阶段提交的概念
System.out.println("这里是处理业务逻辑,失败情况下进行ROLLBACK");
return LocalTransactionState.ROLLBACK_MESSAGE;
}
return LocalTransactionState.COMMIT_MESSAGE;
//return LocalTransactionState.UNKNOW;
}
}
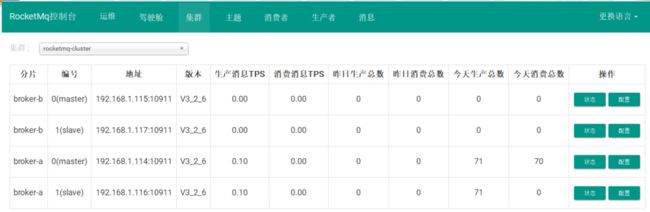
我们先启动消费端,然后启动生产端:
在运行之前,我们先来看一下,web控制台的消息:
业余学习之RocketMQ中级篇
运行结果如下:
生产端:
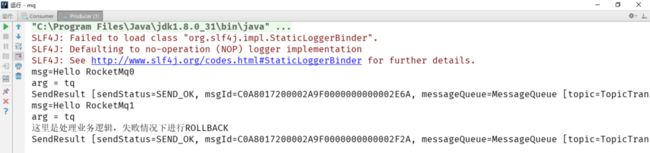
业余学习之RocketMQ中级篇
消费端:

业余学习之RocketMQ中级篇
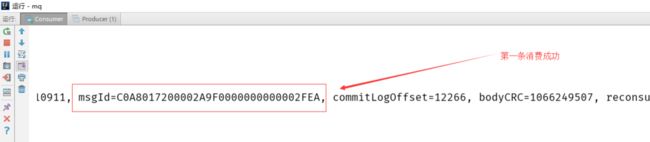
业余学习之RocketMQ中级篇
我们发送了两条消息,消费端只收到一条(第一条),我们在看看控制台:
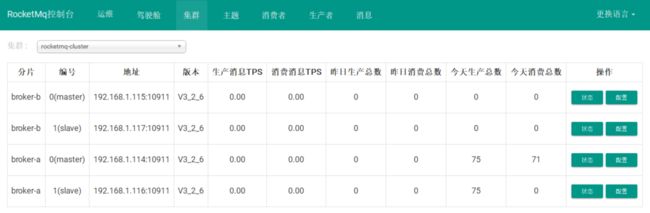
业余学习之RocketMQ中级篇
我们发现一种生产了四条消息,原因如下:

业余学习之RocketMQ中级篇
这就是为什么我们生产了四条消息,最后却只消费了一条。
我们上面的代码还有这么一段:
//服务器回调producer,检查本地事务分支成功还是失败
producer.setTransactionCheckListener(new TransactionCheckListener() {
@Override
public LocalTransactionState checkLocalTransactionState(MessageExt messageExt) {
System.out.println("state --" + new String(messageExt.getBody()));
return LocalTransactionState.COMMIT_MESSAGE;
}
});
这一段代码已经不能够实现相应的功能了(阿里把回查接口实现已经给删除了),回查的逻辑已经不进行开源了(3.2.6),商业版的RocketMQ可以实现消息回查(3.0.8版本也有相应的回查代码。有兴趣的可以进行查看源代码)
===========================================================================================================================================================================================================================================================================
什么是gRPC?
本文会介绍gRPC和协议缓冲。gRPC可以使用协议缓冲作为它的IDL和底层信息交换格式。如果你刚接触gRPC或者协议缓冲,那就看本文!如果你想深入或者实战,查看Quick Starts。
概述
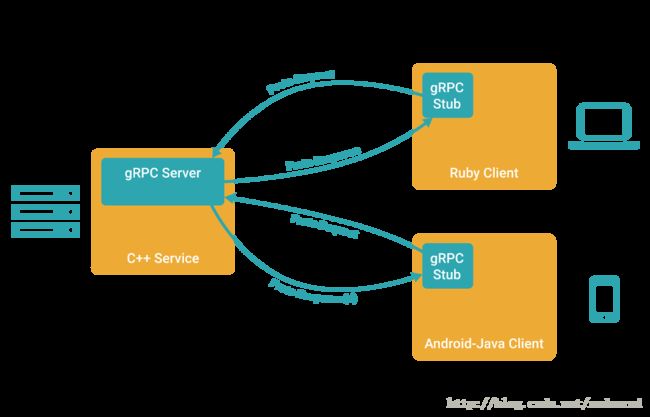
在gRPC里,客户端可以直接调用不同机器上的服务应用的方法,就像是本地对象一样,所以创建分布式应用和服务就很简单了。在很多RPC(Remote Procedure Call Protocol)系统里,gRPC是基于定义一个服务,指定一个可以远程调用的带有参数和返回类型的的方法。在服务端,服务实现这个接口并且运行gRPC服务处理客户端调用。在客户端,有一个stub提供和服务端相同的方法。

在各种环境里,gRPC客户端和服务端都能运行并且互相通讯 - 从谷歌内部服务到你自己的桌面 - 并且可以写在任何gRPC支持的语言。比如,可以简单的创建java作为gRPC的服务端,Go,Python或者Ruby作为客户端。另外,最新的谷歌APIs将会有gRPC版本的接口,可以方便的在应用里构建Google功能。
使用协议缓冲
默认gRPC使用protocol buffers,Google成熟开源的序列化结构数据(尽管可以使用其他数据格式,比如JSON)。这里有简单的介绍他是如何工作的。如果你已经熟悉了协议缓冲,可以直接看下一章节。
使用协议缓冲的第一步是在proto file里为数据定义你想序列化的结构:可以是普通的.proto扩展的文本文件。协议缓冲数据结构为messages,每条message是一个小的逻辑记录的信息包含一些name-value对名为fields。比如:
message Person {
string name = 1;
int32 id = 2;
bool has_ponycopter = 3;
}
然后,一旦你指定了你的数据结构,使用协议缓冲解析器protoc生成数据访问类在proto定义的语言。这些为每个字段(比如name()和set_name())和方法序列化/解析整个结构到/从raw bytes提供了简单的访问器 - 比如,你选择的语言是C++,对上面的例子运行编译会生成一个Person类。然后就可以在应用里使用这个类去populate,序列化和获取Person协议缓冲messages。
你将会在示例里看到更详细的定义在普通proto文件里的gRPC services,有RPC方法参数和指定的返回类型作为协议缓冲messages:
// The greeter service definition.
service Greeter {
// Sends a greeting
rpc SayHello (HelloRequest) returns (HelloReply) {}
}
// The request message containing the user's name.
message HelloRequest {
string name = 1;
}
// The response message containing the greetings
message HelloReply {
string message = 1;
}
gRPC同样使用protoc和指定的gRPC插件从你的proto文件里生成代码。但是,使用gRPC插件,你会得到生成的gRPC客户端和服务端代码和普通的用来populating,序列化和获取你的消息类型protocol buffer代码。我们将会在下面的实例详细说明。
可以在Protocol Buffers documentation查看更多的关于protocal buffers, 和如何安装相应语言的protoc和插件。
Protocol buffer versions
虽然protocal buffers有些时候对开源用户可用,我们的示例使用了新风格的protocal buffers,叫做proto3,有着更简单的语法,一些有用的新特性,并且支持更多的语言。现在对以下语言可用:Java,C++,Python,Objective-C,C#,alite-runtime(Android Java),Ruby和JavaScript from theprotocol buffers Github repo,同时Go语言生成器golang/protobuf Github repo,还有更多语言在开发中。查看proto3 language guide了解更多,还有相关可用的每种语言的文档,在release notes查看每个版本的区别。更多的proto3文档还在更新中。
一般,虽然可以使用proto2(当前默认的protocal buffers版本),我们还是建议你使用proto3搭配gRPC,让你可以使用全部的gRPC支持的语言,同时避免与proto2客户端与proto3服务端通选的兼容问题(或者proto3客户端-proto2服务端的问题)。
===========================================================================================================================================================================================================================================================================
gRPC
概述
gRPC 一开始由 google 开发,是一款语言中立、平台中立、开源的远程过程调用(RPC)系统。
在 gRPC 里客户端应用可以像调用本地对象一样直接调用另一台不同的机器上服务端应用的方法,使得您能够更容易地创建分布式应用和服务。与许多 RPC 系统类似,gRPC 也是基于以下理念:定义一个服务,指定其能够被远程调用的方法(包含参数和返回类型)。在服务端实现这个接口,并运行一个 gRPC 服务器来处理客户端调用。在客户端拥有一个存根能够像服务端一样的方法。
特性
- 基于HTTP/2
HTTP/2 提供了连接多路复用、双向流、服务器推送、请求优先级、首部压缩等机制。可以节省带宽、降低TCP链接次数、节省CPU,帮助移动设备延长电池寿命等。gRPC 的协议设计上使用了HTTP2 现有的语义,请求和响应的数据使用HTTP Body 发送,其他的控制信息则用Header 表示。 - IDL使用ProtoBuf
gRPC使用ProtoBuf来定义服务,ProtoBuf是由Google开发的一种数据序列化协议(类似于XML、JSON、hessian)。ProtoBuf能够将数据进行序列化,并广泛应用在数据存储、通信协议等方面。压缩和传输效率高,语法简单,表达力强。 - 多语言支持(C, C++, Python, PHP, Nodejs, C#, Objective-C、Golang、Java)
gRPC支持多种语言,并能够基于语言自动生成客户端和服务端功能库。目前已提供了C版本grpc、Java版本grpc-java 和 Go版本grpc-go,其它语言的版本正在积极开发中,其中,grpc支持C、C++、Node.js、Python、Ruby、Objective-C、PHP和C#等语言,grpc-java已经支持Android开发。
gRPC已经应用在Google的云服务和对外提供的API中,其主要应用场景如下:
- 低延迟、高扩展性、分布式的系统
- 同云服务器进行通信的移动应用客户端
- 设计语言独立、高效、精确的新协议
- 便于各方面扩展的分层设计,如认证、负载均衡、日志记录、监控等
HTTP2.0 特性
HTTP/2,也就是超文本传输协议第2版,不论是1还是2,HTTP的基本语义是不变的,比如方法语义(GET/PUST/PUT/DELETE),状态码(200/404/500等),Range Request,Cacheing,Authentication、URL路径, 不同的主要是下面几点:
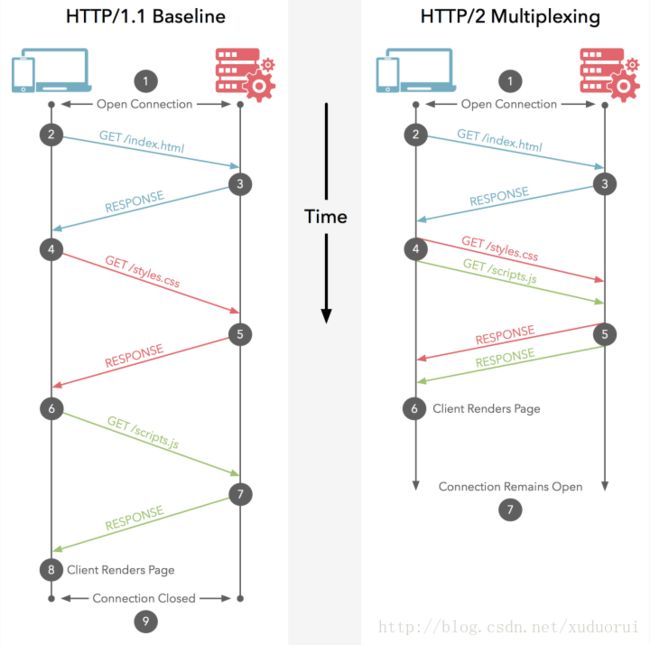
多路复用 (Multiplexing)
在 HTTP/1.1 协议中 「浏览器客户端在同一时间,针对同一域名下的请求有一定数量限制。超过限制数目的请求会被阻塞」。
HTTP/2 的多路复用(Multiplexing) 则允许同时通过单一的 HTTP/2 连接发起多重的请求-响应消息。
因此 HTTP/2 可以很容易的去实现多流并行而不用依赖建立多个 TCP 连接,HTTP/2 把 HTTP 协议通信的基本单位缩小为一个一个的帧,这些帧对应着逻辑流中的消息。并行地在同一个 TCP 连接上双向交换消息。
二进制帧
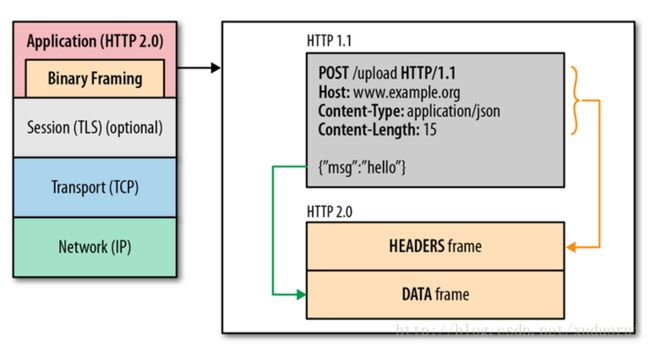
HTTP/2 传输的数据是二进制的。相比 HTTP/1.1 的纯文本数据,二进制数据一个显而易见的好处是:更小的传输体积。这就意味着更低的负载。二进制的帧也更易于解析而且不易出错,纯文本帧在解析的时候还要考虑处理空格、大小写、空行和换行等问题,而二进制帧就不存在这个问题。
首部压缩(Header Compression)
HTTP是无状态协议。简而言之,这意味着每个请求必须要携带服务器需要的所有细节,而不是让服务器保存住之前请求的元数据。因为http2没有改变这个范式,所以它也需要这样(携带所有细节),因此 HTTP 请求的头部需要包含用于标识身份的数据比如 cookies,而这些数据的量也在随着时间增长。每一个请求的头部都包含这些大量的重复数据,无疑是一种很大的负担。对请求头部进行压缩,将会大大减轻这种负担,尤其对移动端来说,性能提高非常明显。
HTTP/2 使用的压缩方式是 HPACK。 http://http2.github.io/http2-spec/compression.html
HTTP2.0在客户端和服务器端使用“首部表”来跟踪和存储之前发送的键-值对,对于相同的数据,不再通过每次请求和响应发送;通信期间几乎不会改变的通用键-值对(用户代理、可接受的媒体类型,等等)只需发送一次。
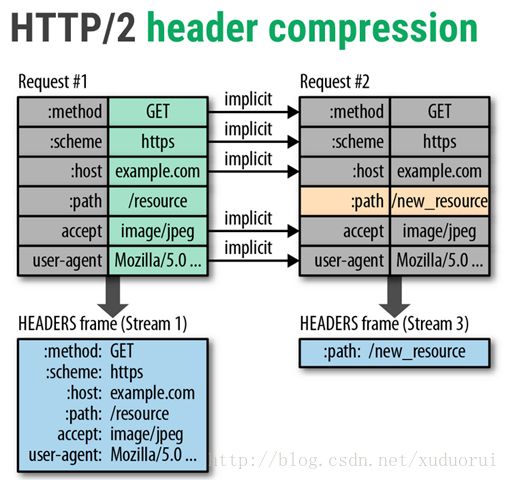
事实上,如果请求中不包含首部(例如对同一资源的轮询请求),那么首部开销就是零字节。此时所有首部都自动使用之前请求发送的首部。
如果首部发生变化了,那么只需要发送变化了数据在Headers帧里面,新增或修改的首部帧会被追加到“首部表”。首部表在 HTTP2.0的连接存续期内始终存在,由客户端和服务器共同渐进地更新。
服务端推送(Server Push)
HTTP/2 的服务器推送所作的工作就是,服务器在收到客户端对某个资源的请求时,会判断客户端十有八九还要请求其他的什么资源,然后一同把这些资源都发送给客户端,即便客户端还没有明确表示它需要这些资源。
客户端可以选择把额外的资源放入缓存中(所以这个特点也叫 Cache push),也可以选择发送一个 RST_STREAM frame 拒绝任何它不想要的资源。
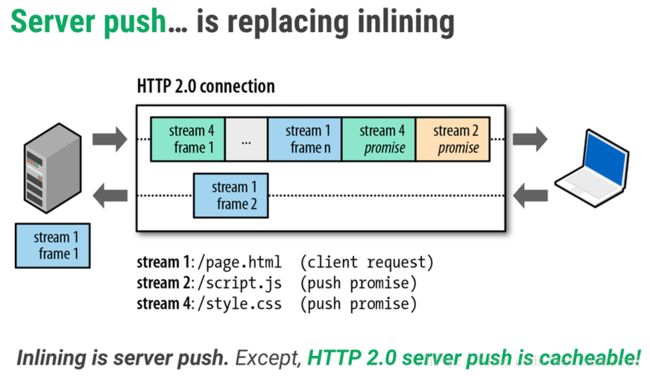
主动重置链接
Length的HTTP消息被送出之后,我们就很难中断它了。当然,通常我们可以断开整个TCP链接(但也不总是可以这样),但这样导致的代价就是需要重新通过三次握手建立一个新的TCP连接。
HTTP/2 引入了一个 RST_STREAM frame 来让客户端在已有的连接中发送重置请求,从而中断或者放弃响应。当浏览器进行页面跳转或者用户取消下载时,它可以防止建立新连接,避免浪费所有带宽。
与其他rpc比较
与thrift,dubbo,motan等比较
| * | Motan | Dubbox | thrift | gRPC | rpcx |
|---|---|---|---|---|---|
| 开发语言 | Java | Java | 跨语言 | 跨语言 | go |
| 分布式服务治理 | Y | Y | 可以配合zookeeper, Eureka等实现 | 可以配合etcd(go),zookeeper,consul等实现 | 自带服务注册中心,也支持zookerper,etcd等发现方式 |
| 底层协议 | motan协议,使用tcp长连接 | Dubbo 协议、 Rmi 协议、 Hessian 协议、 HTTP 协议、 WebService 协议、Dubbo Thrift 协议、Memcached 协议 | tpc/http/frame | http2 | tcp长链接 |
| 消息序列化 | hessian2,json | hessian2,json,resr,kyro,FST等,可扩展protobuf等 | thrift | protobuf | Gob、Json、MessagePack、gencode、ProtoBuf等 |
| 跨语言编程 | N(支持php client和c server) | N | Y | Y | N |
| 负载均衡 | ActiveWeight 、Random 、 RoundRobin 、LocalFirst 、 Consistent 、ConfigurableWeight | Random 、RoundRobin 、ConsistentHash 、 LeastActive | Haproxy, zookerper+客户端负载均衡等方案 | 负载均衡软件HaProxy等 | 支持随机请求、轮询、低并发优先、一致性 Hash等 |
| 容错 | Failover 失效切换、Failfast 快速失败 | Failover 、 Failfast 、Failsafe 、 Failback 、 Forking、 Broadcast | Failover | 具有 Failover 失效切换的容错策略 | 失败重试(Failover)、快速失败(Failfast) |
| 注册中心 | consul | zookeeper | zookeeper | etcd,zookeeper,consul | zookerper,etcd |
| 性能 | ★★ | ★★ | ★★★★ 比grpc快2-5倍 | ★★★ 比dubbox,motan快 | ★★★★★ 比thrift快1-1.5倍 |
| 侧重优势 | 服务管理 | 服务管理 | 跨语言,性能++ | 跨语言,性能 | 性能++,服务治理 |
| 客户端异步调用方案 |
|
stream传输,双向通信 | |||
| 服务端异步处理 | 1、TNonblockingServer(java/c++,php); THsHaServer(java/c++); TThreadpoolServer(java/c++); TThreadSelectorServer(java/c++) 2、结合消息队列或中间件 3、swoole/goroutine等多任务支持 |
同上,使用stream传输。Stream对象在传输过程中会被当做集合,用Iterator来遍历处理 |
grpc vs thrift:

使用gRPC的公司或项目:
Google
Mochi中国
阿里OTS
腾讯部分部门
Tensorflow项目中使用了grpc
CoreOS — Production API for etcd v3 is entirely gRPC. etcd v3的接口全部使用grpc
Square — replacement for all of their internal RPC. one of the very first adopters and contributors to gRPC.
ngrok — all 20+ internal services communicate via gRPC 一个内网转发产品
Netflix
Yik Yak
VSCO
Cockroach
使用Thrift的公司或项目:
Facebook
雪球
饿了么
今日头条
evernote
友盟
小米
美团
Quora
Twitter
Pinterest
Foursquare
Maxeler Technologies
gRPC优缺点:
优点:
protobuf二进制消息,性能好/效率高(空间和时间效率都很不错)
proto文件生成目标代码,简单易用
序列化反序列化直接对应程序中的数据类,不需要解析后在进行映射(XML,JSON都是这种方式)
支持向前兼容(新加字段采用默认值)和向后兼容(忽略新加字段),简化升级
支持多种语言(可以把proto文件看做IDL文件)
Netty等一些框架集成
缺点:
1)GRPC尚未提供连接池,需要自行实现
2)尚未提供“服务发现”、“负载均衡”机制
3)因为基于HTTP2,绝大部多数HTTP Server、Nginx都尚不支持,即Nginx不能将GRPC请求作为HTTP请求来负载均衡,而是作为普通的TCP请求。(nginx1.9版本已支持)
4) Protobuf二进制可读性差(貌似提供了Text_Fromat功能)
默认不具备动态特性(可以通过动态定义生成消息类型或者动态编译支持)
grpc坑:
来自https://news.ycombinator.com/item?id=12345223的网友:
http2只允许单个链接传输10亿流数据。原因在于:
htt2使用31位整形标示流,服务端使用奇数,客户端使用偶数,所以总共10亿可用。
-
HTTP/2.0 uses an unsigned 31-bit integer to identity individual streams over a connection. -
Server-initiated streams must use even identifiers. -
Client-initiated streams must use odd identifiers.
解决思路:超过一定数量的流,需要重启链接。
gRPC通信方式
gRPC有四种通信方式:
1、 Simple RPC
简单rpc
这就是一般的rpc调用,一个请求对象对应一个返回对象
proto语法:
rpc simpleHello(Person) returns (Result) {}2、 Server-side streaming RPC
服务端流式rpc
一个请求对象,服务端可以传回多个结果对象
proto语法
rpc serverStreamHello(Person) returns (stream Result) {}3、 Client-side streaming RPC
客户端流式rpc
客户端传入多个请求对象,服务端返回一个响应结果
proto语法
rpc clientStreamHello(stream Person) returns (Result) {}4、 Bidirectional streaming RPC
双向流式rpc
结合客户端流式rpc和服务端流式rpc,可以传入多个对象,返回多个响应对象
proto语法
rpc biStreamHello(stream Person) returns (stream Result) {}服务定义及ProtoBuf
gRPC使用ProtoBuf定义服务, 我们可以一次性的在一个 .proto 文件中定义服务并使用任何支持它的语言去实现客户端和服务器,反过来,它们可以在各种环境中,从云服务器到你自己的平板电脑—— gRPC 帮你解决了不同语言及环境间通信的复杂性。使用 protocol buffers 还能获得其他好处,包括高效的序列号,简单的 IDL 以及容易进行接口更新。
protoc编译工具
protoc工具可在https://github.com/google/protobuf/releases 下载到源码。
linux下安装
protobuf语法
1、syntax = “proto3”;
文件的第一行指定了你使用的是proto3的语法:如果你不指定,protocol buffer 编译器就会认为你使用的是proto2的语法。这个语句必须出现在.proto文件的非空非注释的第一行。
2、message SearchRequest {……}
message 定义实体,c/c++/go中的结构体,php中类
3、基本数据类型 
4、注释符号: 双斜线,如://xxxxxxxxxxxxxxxxxxx
5、字段唯一数字标识(用于在二进制格式中识别各个字段,上线后不宜再变动):Tags
1到15使用一个字节来编码,包括标识数字和字段类型(你可以在Protocol Buffer 编码中查看更多详细);16到2047占用两个字节。因此定义proto文件时应该保留1到15,用作出现最频繁的消息类型的标识。记得为将来会继续增加并可能频繁出现的元素留一点儿标识区间,也就是说,不要一下子把1—15全部用完,为将来留一点儿。
标识数字的合法范围:最小是1,最大是 229 - 1,或者536,870,911。
另外,不能使用19000 到 19999之间的数字(FieldDescriptor::kFirstReservedNumber through FieldDescriptor::kLastReservedNumber),因为它们被Protocol Buffers保留使用
6、字段修饰符:
required:值不可为空
optional:可选字段
singular:符合语法规则的消息包含零个或者一个这样的字段(最多一个)
repeated:一个字段在合法的消息中可以重复出现一定次数(包括零次)。重复出现的值的次序将被保留。在proto3中,重复出现的值类型字段默认采用压缩编码。你可以在这里找到更多关于压缩编码的东西: Protocol Buffer Encoding。
默认值: optional PhoneType type = 2 [default = HOME];
proto3中,省略required,optional,singular,由protoc自动选择。
7、代理类生成
1)、C++, 每一个.proto 文件可以生成一个 .h 文件和一个 .cc 文件
2)、Java, 每一个.proto文件可以生成一个 .java 文件
3)、Python, 每一个.proto文件生成一个模块,其中为每一个消息类型生成一个静态的描述器,在运行时,和一个metaclass一起使用来创建必要的Python数据访问类
4)、Go, 每一个.proto生成一个 .pb.go 文件
5)、Ruby, 每一个.proto生成一个 .rb 文件
6)、Objective-C, 每一个.proto 文件可以生成一个 pbobjc.h 和一个pbobjc.m 文件
7)、C#, 每一个.proto文件可以生成一个.cs文件.
8)、php, 每一个message消息体生成一个.php类文件,并在GPBMetadata目录生成一个对应包名的.php类文件,用于保存.proto的二进制元数据。
8、字段默认值
- strings, 默认值是空字符串(empty string)
- bytes, 默认值是空bytes(empty bytes)
- bools, 默认值是false
- numeric, 默认值是0
- enums, 默认值是第一个枚举值(value必须为0)
- message fields, the field is not set. Its exact value is langauge-dependent. See the generated code guide for details.
- repeated fields,默认值为empty,通常是一个空list
9、枚举
-
// 枚举类型,必须从0开始,序号可跨越。同一包下不能重名,所以加前缀来区别 -
enum WshExportInstStatus { -
INST_INITED = 0; -
INST_RUNNING = 1; -
INST_FINISH = 2; -
INST_FAILED = 3; -
}
10、Maps字段类型
map map_field = N; 其中key_type可以是任意Integer或者string类型(所以,除了floating和bytes的任意标量类型都是可以的)value_type可以是任意类型。
例如,如果你希望创建一个project的映射,每个Projecct使用一个string作为key,你可以像下面这样定义:
map projects = 3; - Map的字段可以是repeated。
- 序列化后的顺序和map迭代器的顺序是不确定的,所以你不要期望以固定顺序处理Map
- 当为.proto文件产生生成文本格式的时候,map会按照key 的顺序排序,数值化的key会按照数值排序。
- 从序列化中解析或者融合时,如果有重复的key则后一个key不会被使用,当从文本格式中解析map时,如果存在重复的key。
11、默认值
字符串类型默认为空字符串
字节类型默认为空字节
布尔类型默认false
数值类型默认为0值
enums类型默认为第一个定义的枚举值,必须是0
12、服务
服务使用service{}包起来,每个方法使用rpc起一行申明,一个方法包含一个请求消息体和一个返回消息体
-
service HelloService { -
rpc SayHello (HelloRequest) returns (HelloResponse); -
} -
message HelloRequest { -
string greeting = 1; -
} -
message HelloResponse { -
string reply = 1; -
}
更多protobuf参考(google)
更多protobuf参考(csdn)
gRPC服务发现与服务治理的方案
目前gRPC主流分布式方案有这么几种: etcd, zookeeper, consul.
1、集中式LB(Proxy Model)
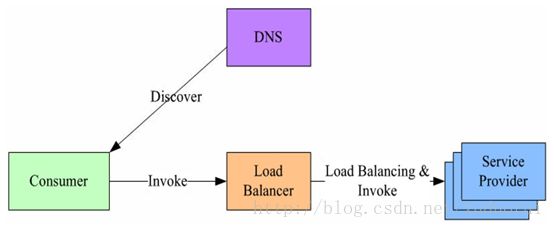
在服务消费者和服务提供者之间有一个独立的LB,通常是专门的硬件设备如 F5,或者基于软件如 LVS,HAproxy等实现。LB上有所有服务的地址映射表,通常由运维配置注册,当服务消费方调用某个目标服务时,它向LB发起请求,由LB以某种策略,比如轮询(Round-Robin)做负载均衡后将请求转发到目标服务。LB一般具备健康检查能力,能自动摘除不健康的服务实例。 该方案主要问题:
- 1、 单点问题,所有服务调用流量都经过LB,当服务数量和调用量大的时候,LB容易成为瓶颈,且一旦LB发生故障影响整个系统;
- 2、服务消费方、提供方之间增加了一级,有一定性能开销。
2、进程内LB(Balancing-aware Client)
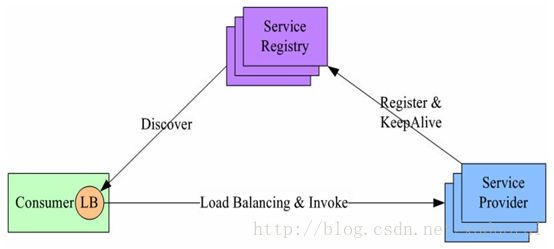
针对第一个方案的不足,此方案将LB的功能集成到服务消费方进程里,也被称为软负载或者客户端负载方案。服务提供方启动时,首先将服务地址注册到服务注册表,同时定期报心跳到服务注册表以表明服务的存活状态,相当于健康检查,服务消费方要访问某个服务时,它通过内置的LB组件向服务注册表查询,同时缓存并定期刷新目标服务地址列表,然后以某种负载均衡策略选择一个目标服务地址,最后向目标服务发起请求。LB和服务发现能力被分散到每一个服务消费者的进程内部,同时服务消费方和服务提供方之间是直接调用,没有额外开销,性能比较好。该方案主要问题:
- 1、开发成本,该方案将服务调用方集成到客户端的进程里头,如果有多种不同的语言栈,就要配合开发多种不同的客户端,有一定的研发和维护成本;
- 2、另外生产环境中,后续如果要对客户库进行升级,势必要求服务调用方修改代码并重新发布,升级较复杂。
3、独立 LB 进程(External Load Balancing Service)
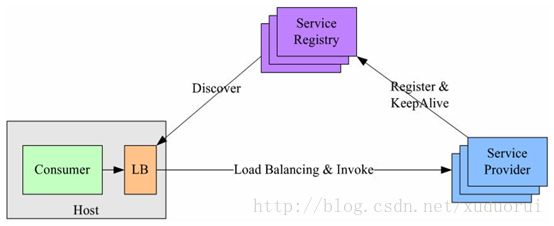
该方案是针对第二种方案的不足而提出的一种折中方案,原理和第二种方案基本类似。
不同之处是将LB和服务发现功能从进程内移出来,变成主机上的一个独立进程。主机上的一个或者多个服务要访问目标服务时,他们都通过同一主机上的独立LB进程做服务发现和负载均衡。该方案也是一种分布式方案没有单点问题,一个LB进程挂了只影响该主机上的服务调用方,服务调用方和LB之间是进程内调用性能好,同时该方案还简化了服务调用方,不需要为不同语言开发客户库,LB的升级不需要服务调用方改代码。
该方案主要问题:部署较复杂,环节多,出错调试排查问题不方便。
服务发现负载均衡实现
gRPC开源组件官方并未直接提供服务注册与发现的功能实现,但其设计文档已提供实现的思路,并在不同语言的gRPC代码API中已提供了命名解析和负载均衡接口供扩展。 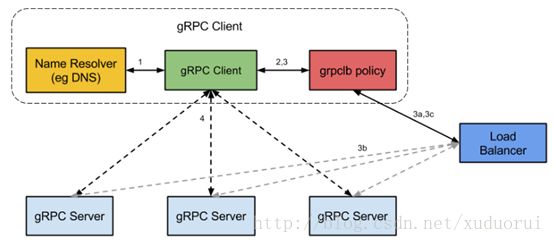
其基本实现原理:
- 1、服务启动后gRPC客户端向命名服务器发出名称解析请求,名称将解析为一个或多个IP地址,每个IP地址标示它是服务器地址还是负载均衡器地址,以及标示要使用那个客户端负载均衡策略或服务配置。
- 2、客户端实例化负载均衡策略,如果解析返回的地址是负载均衡器地址,则客户端将使用grpclb策略,否则客户端使用服务配置请求的负载均衡策略。
- 3、负载均衡策略为每个服务器地址创建一个子通道(channel)。
- 4、当有rpc请求时,负载均衡策略决定那个子通道即grpc服务器将接收请求,当可用服务器为空时客户端的请求将被阻塞。
根据gRPC官方提供的设计思路,基于进程内LB方案(即第2个案,阿里开源的服务框架 Dubbo 也是采用类似机制),结合分布式一致的组件(如Zookeeper、Consul、Etcd),可找到gRPC服务发现和负载均衡的可行解决方案。接下来以GO语言为例,简单介绍下基于Etcd3的关键代码实现:
1)命名解析实现:resolver.go
-
package etcdv3 -
import ( -
"errors" -
"fmt" -
"strings" -
etcd3 "github.com/coreos/etcd/clientv3" -
"google.golang.org/grpc/naming" -
) -
// resolver is the implementaion of grpc.naming.Resolver -
type resolver struct { -
serviceName string // service name to resolve -
} -
// NewResolver return resolver with service name -
func NewResolver(serviceName string) *resolver { -
return &resolver{serviceName: serviceName} -
} -
// Resolve to resolve the service from etcd, target is the dial address of etcd -
// target example: "http://127.0.0.1:2379,http://127.0.0.1:12379,http://127.0.0.1:22379" -
func (re *resolver) Resolve(target string) (naming.Watcher, error) { -
if re.serviceName == "" { -
return nil, errors.New("grpclb: no service name provided") -
} -
// generate etcd client -
client, err := etcd3.New(etcd3.Config{ -
Endpoints: strings.Split(target, ","), -
}) -
if err != nil { -
return nil, fmt.Errorf("grpclb: creat etcd3 client failed: %s", err.Error()) -
} -
// Return watcher -
return &watcher{re: re, client: *client}, nil -
}
2)服务发现实现:watcher.go
-
package etcdv3 -
import ( -
"fmt" -
etcd3 "github.com/coreos/etcd/clientv3" -
"golang.org/x/net/context" -
"google.golang.org/grpc/naming" -
"github.com/coreos/etcd/mvcc/mvccpb" -
) -
// watcher is the implementaion of grpc.naming.Watcher -
type watcher struct { -
re *resolver // re: Etcd Resolver -
client etcd3.Client -
isInitialized bool -
} -
// Close do nothing -
func (w *watcher) Close() { -
} -
// Next to return the updates -
func (w *watcher) Next() ([]*naming.Update, error) { -
// prefix is the etcd prefix/value to watch -
prefix := fmt.Sprintf("/%s/%s/", Prefix, w.re.serviceName) -
// check if is initialized -
if !w.isInitialized { -
// query addresses from etcd -
resp, err := w.client.Get(context.Background(), prefix, etcd3.WithPrefix()) -
w.isInitialized = true -
if err == nil { -
addrs := extractAddrs(resp) -
//if not empty, return the updates or watcher new dir -
if l := len(addrs); l != 0 { -
updates := make([]*naming.Update, l) -
for i := range addrs { -
updates[i] = &naming.Update{Op: naming.Add, Addr: addrs[i]} -
} -
return updates, nil -
} -
} -
} -
// generate etcd Watcher -
rch := w.client.Watch(context.Background(), prefix, etcd3.WithPrefix()) -
for wresp := range rch { -
for _, ev := range wresp.Events { -
switch ev.Type { -
case mvccpb.PUT: -
return []*naming.Update{{Op: naming.Add, Addr: string(ev.Kv.Value)}}, nil -
case mvccpb.DELETE: -
return []*naming.Update{{Op: naming.Delete, Addr: string(ev.Kv.Value)}}, nil -
} -
} -
} -
return nil, nil -
} -
func extractAddrs(resp *etcd3.GetResponse) []string { -
addrs := []string{} -
if resp == nil || resp.Kvs == nil { -
return addrs -
} -
for i := range resp.Kvs { -
if v := resp.Kvs[i].Value; v != nil { -
addrs = append(addrs, string(v)) -
} -
} -
return addrs -
}
3)服务注册实现:register.go
-
package etcdv3 -
import ( -
"fmt" -
"log" -
"strings" -
"time" -
etcd3 "github.com/coreos/etcd/clientv3" -
"golang.org/x/net/context" -
"github.com/coreos/etcd/etcdserver/api/v3rpc/rpctypes" -
) -
// Prefix should start and end with no slash -
var Prefix = "etcd3_naming" -
var client etcd3.Client -
var serviceKey string -
var stopSignal = make(chan bool, 1) -
// Register -
func Register(name string, host string, port int, target string, interval time.Duration, ttl int) error { -
serviceValue := fmt.Sprintf("%s:%d", host, port) -
serviceKey = fmt.Sprintf("/%s/%s/%s", Prefix, name, serviceValue) -
// get endpoints for register dial address -
var err error -
client, err := etcd3.New(etcd3.Config{ -
Endpoints: strings.Split(target, ","), -
}) -
if err != nil { -
return fmt.Errorf("grpclb: create etcd3 client failed: %v", err) -
} -
go func() { -
// invoke self-register with ticker -
ticker := time.NewTicker(interval) -
for { -
// minimum lease TTL is ttl-second -
resp, _ := client.Grant(context.TODO(), int64(ttl)) -
// should get first, if not exist, set it -
_, err := client.Get(context.Background(), serviceKey) -
if err != nil { -
if err == rpctypes.ErrKeyNotFound { -
if _, err := client.Put(context.TODO(), serviceKey, serviceValue, etcd3.WithLease(resp.ID)); err != nil { -
log.Printf("grpclb: set service '%s' with ttl to etcd3 failed: %s", name, err.Error()) -
} -
} else { -
log.Printf("grpclb: service '%s' connect to etcd3 failed: %s", name, err.Error()) -
} -
} else { -
// refresh set to true for not notifying the watcher -
if _, err := client.Put(context.Background(), serviceKey, serviceValue, etcd3.WithLease(resp.ID)); err != nil { -
log.Printf("grpclb: refresh service '%s' with ttl to etcd3 failed: %s", name, err.Error()) -
} -
} -
select { -
case <-stopSignal: -
return -
case <-ticker.C: -
} -
} -
}() -
return nil -
} -
// UnRegister delete registered service from etcd -
func UnRegister() error { -
stopSignal <- true -
stopSignal = make(chan bool, 1) // just a hack to avoid multi UnRegister deadlock -
var err error; -
if _, err := client.Delete(context.Background(), serviceKey); err != nil { -
log.Printf("grpclb: deregister '%s' failed: %s", serviceKey, err.Error()) -
} else { -
log.Printf("grpclb: deregister '%s' ok.", serviceKey) -
} -
return err -
}
4)接口描述文件:helloworld.proto
-
syntax = "proto3"; -
option java_multiple_files = true; -
option java_package = "com.midea.jr.test.grpc"; -
option java_outer_classname = "HelloWorldProto"; -
option objc_class_prefix = "HLW"; -
package helloworld; -
// The greeting service definition. -
service Greeter { -
// Sends a greeting -
rpc SayHello (HelloRequest) returns (HelloReply) { -
} -
} -
// The request message containing the user's name. -
message HelloRequest { -
string name = 1; -
} -
// The response message containing the greetings -
message HelloReply { -
string message = 1; -
}
5)实现服务端接口:helloworldserver.go
-
package main -
import ( -
"flag" -
"fmt" -
"log" -
"net" -
"os" -
"os/signal" -
"syscall" -
"time" -
"golang.org/x/net/context" -
"google.golang.org/grpc" -
grpclb "com.midea/jr/grpclb/naming/etcd/v3" -
"com.midea/jr/grpclb/example/pb" -
) -
var ( -
serv = flag.String("service", "hello_service", "service name") -
port = flag.Int("port", 50001, "listening port") -
reg = flag.String("reg", "http://127.0.0.1:2379", "register etcd address") -
) -
func main() { -
flag.Parse() -
lis, err := net.Listen("tcp", fmt.Sprintf("0.0.0.0:%d", *port)) -
if err != nil { -
panic(err) -
} -
err = grpclb.Register(*serv, "127.0.0.1", *port, *reg, time.Second*10, 15) -
if err != nil { -
panic(err) -
} -
ch := make(chan os.Signal, 1) -
signal.Notify(ch, syscall.SIGTERM, syscall.SIGINT, syscall.SIGKILL, syscall.SIGHUP, syscall.SIGQUIT) -
go func() { -
s := <-ch -
log.Printf("receive signal '%v'", s) -
grpclb.UnRegister() -
os.Exit(1) -
}() -
log.Printf("starting hello service at %d", *port) -
s := grpc.NewServer() -
pb.RegisterGreeterServer(s, &server{}) -
s.Serve(lis) -
} -
// server is used to implement helloworld.GreeterServer. -
type server struct{} -
// SayHello implements helloworld.GreeterServer -
func (s *server) SayHello(ctx context.Context, in *pb.HelloRequest) (*pb.HelloReply, error) { -
fmt.Printf("%v: Receive is %s\n", time.Now(), in.Name) -
return &pb.HelloReply{Message: "Hello " + in.Name}, nil -
}
6)实现客户端接口:helloworldclient.go
-
package main -
import ( -
"flag" -
"fmt" -
"time" -
grpclb "com.midea/jr/grpclb/naming/etcd/v3" -
"com.midea/jr/grpclb/example/pb" -
"golang.org/x/net/context" -
"google.golang.org/grpc" -
"strconv" -
) -
var ( -
serv = flag.String("service", "hello_service", "service name") -
reg = flag.String("reg", "http://127.0.0.1:2379", "register etcd address") -
) -
func main() { -
flag.Parse() -
r := grpclb.NewResolver(*serv) -
b := grpc.RoundRobin(r) -
ctx, _ := context.WithTimeout(context.Background(), 10*time.Second) -
conn, err := grpc.DialContext(ctx, *reg, grpc.WithInsecure(), grpc.WithBalancer(b)) -
if err != nil { -
panic(err) -
} -
ticker := time.NewTicker(1 * time.Second) -
for t := range ticker.C { -
client := pb.NewGreeterClient(conn) -
resp, err := client.SayHello(context.Background(), &pb.HelloRequest{Name: "world " + strconv.Itoa(t.Second())}) -
if err == nil { -
fmt.Printf("%v: Reply is %s\n", t, resp.Message) -
} -
} -
}
========================================================================================================================================================================================================================================================================================================================================================================================================================
【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【
zookeeper
Dubbo是一款高性能、轻量级的开源Java RPC框架,它提供了三大核心能力:面向接口的远程方法调用,智能容错和负载均衡,以及服务自动注册和发现。
】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】
这可能是把ZooKeeper概念讲的最清楚的一篇文章
相信大家对 ZooKeeper 应该不算陌生,但是你真的了解 ZooKeeper 是什么吗?如果别人/面试官让你讲讲 ZooKeeper 是什么,你能回答到哪个地步呢?
我本人曾经使用过 ZooKeeper 作为 Dubbo 的注册中心,另外在搭建 Solr 集群的时候,我使用到了 ZooKeeper 作为 Solr 集群的管理工具。
前几天,总结项目经验的时候,我突然问自己 ZooKeeper 到底是个什么东西?
想了半天,脑海中只是简单的能浮现出几句话:
- Zookeeper 可以被用作注册中心。
- Zookeeper 是 Hadoop 生态系统的一员。
- 构建 Zookeeper 集群的时候,使用的服务器最好是奇数台。
可见,我对于 Zookeeper 的理解仅仅是停留在了表面。所以,通过本文,希望带大家稍微详细的了解一下 ZooKeeper 。
如果没有学过 ZooKeeper,那么本文将会是你进入 ZooKeeper 大门的垫脚砖;如果你已经接触过 ZooKeeper ,那么本文将带你回顾一下 ZooKeeper 的一些基础概念。
最后,本文只涉及 ZooKeeper 的一些概念,并不涉及 ZooKeeper 的使用以及 ZooKeeper 集群的搭建。
网上有介绍 ZooKeeper 的使用以及搭建 ZooKeeper 集群的文章,大家有需要可以自行查阅。
什么是 ZooKeeper
ZooKeeper 的由来
下面这段内容摘自《从 Paxos 到 ZooKeeper 》第四章第一节的某段内容,推荐大家阅读一下:
Zookeeper 最早起源于雅虎研究院的一个研究小组。在当时,研究人员发现,在雅虎内部很多大型系统基本都需要依赖一个类似的系统来进行分布式协调,但是这些系统往往都存在分布式单点问题。
所以,雅虎的开发人员就试图开发一个通用的无单点问题的分布式协调框架,以便让开发人员将精力集中在处理业务逻辑上。
关于“ZooKeeper”这个项目的名字,其实也有一段趣闻。在立项初期,考虑到之前内部很多项目都是使用动物的名字来命名的(例如著名的Pig项目),雅虎的工程师希望给这个项目也取一个动物的名字。
时任研究院的首席科学家 Raghu Ramakrishnan 开玩笑地说:“在这样下去,我们这儿就变成动物园了!”
此话一出,大家纷纷表示就叫动物园管理员吧,因为各个以动物命名的分布式组件放在一起,雅虎的整个分布式系统看上去就像一个大型的动物园了。
而 Zookeeper 正好要用来进行分布式环境的协调,于是,Zookeeper 的名字也就由此诞生了。
ZooKeeper 概览
ZooKeeper 是一个开源的分布式协调服务,ZooKeeper 框架最初是在“Yahoo!"上构建的,用于以简单而稳健的方式访问他们的应用程序。
后来,Apache ZooKeeper 成为 Hadoop,HBase 和其他分布式框架使用的有组织服务的标准。
例如,Apache HBase 使用 ZooKeeper 跟踪分布式数据的状态。
ZooKeeper 的设计目标是将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一系列简单易用的接口提供给用户使用。
原语: 操作系统或计算机网络用语范畴。它是由若干条指令组成的,用于完成一定功能的一个过程。具有不可分割性,即原语的执行必须是连续的,在执行过程中不允许被中断。
ZooKeeper 是一个典型的分布式数据一致性解决方案,分布式应用程序可以基于 ZooKeeper 实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。
ZooKeeper 一个最常用的使用场景就是用于担任服务生产者和服务消费者的注册中心。
服务生产者将自己提供的服务注册到 ZooKeeper 中心,服务的消费者在进行服务调用的时候先到 ZooKeeper 中查找服务,获取到服务生产者的详细信息之后,再去调用服务生产者的内容与数据。
如下图所示,在 Dubbo 架构中 ZooKeeper 就担任了注册中心这一角色。
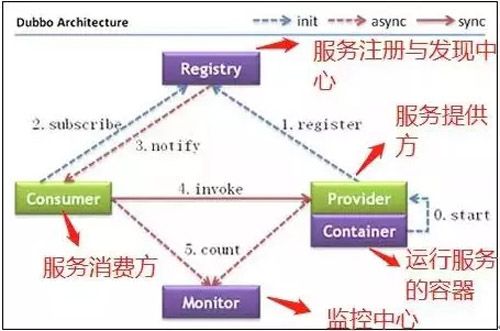
Dubbo 架构图
结合个人使用讲一下 ZooKeeper
在我自己做过的项目中,主要使用到了 ZooKeeper 作为 Dubbo 的注册中心(Dubbo 官方推荐使用 ZooKeeper 注册中心)。
另外在搭建 Solr 集群的时候,我使用 ZooKeeper 作为 Solr 集群的管理工具。
这时,ZooKeeper 主要提供下面几个功能:
- 集群管理:容错、负载均衡。
- 配置文件的集中管理。
- 集群的入口。
我个人觉得在使用 ZooKeeper 的时候,最好是使用集群版的 ZooKeeper 而不是单机版的。
官网给出的架构图就描述的是一个集群版的 ZooKeeper 。通常 3 台服务器就可以构成一个 ZooKeeper 集群了。
为什么最好使用奇数台服务器构成 ZooKeeper 集群?
我们知道在 ZooKeeper 中 Leader 选举算法采用了 Zab 协议。Zab 核心思想是当多数 Server 写成功,则任务数据写成功:
- 如果有 3 个 Server,则最多允许 1 个 Server 挂掉。
- 如果有 4 个 Server,则同样最多允许 1 个 Server 挂掉。
既然 3 个或者 4 个 Server,同样最多允许 1 个 Server 挂掉,那么它们的可靠性是一样的。
所以选择奇数个 ZooKeeper Server 即可,这里选择 3 个 Server。
关于 ZooKeeper 的一些重要概念
重要概念总结
关于 ZooKeeper 的一些重要概念:
- ZooKeeper 本身就是一个分布式程序(只要半数以上节点存活,ZooKeeper 就能正常服务)。
- 为了保证高可用,最好是以集群形态来部署 ZooKeeper,这样只要集群中大部分机器是可用的(能够容忍一定的机器故障),那么 ZooKeeper 本身仍然是可用的。
- ZooKeeper 将数据保存在内存中,这也就保证了 高吞吐量和低延迟(但是内存限制了能够存储的容量不太大,此限制也是保持 Znode 中存储的数据量较小的进一步原因)。
- ZooKeeper 是高性能的。在“读”多于“写”的应用程序中尤其地高性能,因为“写”会导致所有的服务器间同步状态。(“读”多于“写”是协调服务的典型场景。)
- ZooKeeper 有临时节点的概念。当创建临时节点的客户端会话一直保持活动,瞬时节点就一直存在。
而当会话终结时,瞬时节点被删除。持久节点是指一旦这个 ZNode 被创建了,除非主动进行 ZNode 的移除操作,否则这个 ZNode 将一直保存在 Zookeeper 上。
- ZooKeeper 底层其实只提供了两个功能:①管理(存储、读取)用户程序提交的数据;②为用户程序提交数据节点监听服务。
下面关于会话(Session)、 Znode、版本、Watcher、ACL 概念的总结都在《从 Paxos 到 ZooKeeper 》第四章第一节以及第七章第八节有提到,感兴趣的可以看看!
会话(Session)
Session 指的是 ZooKeeper 服务器与客户端会话。在 ZooKeeper 中,一个客户端连接是指客户端和服务器之间的一个 TCP 长连接。
客户端启动的时候,首先会与服务器建立一个 TCP 连接,从第一次连接建立开始,客户端会话的生命周期也开始了。
通过这个连接,客户端能够通过心跳检测与服务器保持有效的会话,也能够向 Zookeeper 服务器发送请求并接受响应,同时还能够通过该连接接收来自服务器的 Watch 事件通知。
Session 的 sessionTimeout 值用来设置一个客户端会话的超时时间。
当由于服务器压力太大、网络故障或是客户端主动断开连接等各种原因导致客户端连接断开时,只要在 sessionTimeout 规定的时间内能够重新连接上集群中任意一台服务器,那么之前创建的会话仍然有效。
在为客户端创建会话之前,服务端首先会为每个客户端都分配一个 sessionID。
由于 sessionID 是 Zookeeper 会话的一个重要标识,许多与会话相关的运行机制都是基于这个 sessionID 的。
因此,无论是哪台服务器为客户端分配的 sessionID,都务必保证全局唯一。
Znode
在谈到分布式的时候,我们通常说的“节点"是指组成集群的每一台机器。
然而,在 ZooKeeper 中,“节点"分为两类:
- 第一类同样是指构成集群的机器,我们称之为机器节点。
- 第二类则是指数据模型中的数据单元,我们称之为数据节点一ZNode。
ZooKeeper 将所有数据存储在内存中,数据模型是一棵树(Znode Tree),由斜杠(/)的进行分割的路径,就是一个 Znode,例如/foo/path1。每个上都会保存自己的数据内容,同时还会保存一系列属性信息。
在 Zookeeper 中,Node 可以分为持久节点和临时节点两类。所谓持久节点是指一旦这个 ZNode 被创建了,除非主动进行 ZNode 的移除操作,否则这个 ZNode 将一直保存在 ZooKeeper 上。
而临时节点就不一样了,它的生命周期和客户端会话绑定,一旦客户端会话失效,那么这个客户端创建的所有临时节点都会被移除。
另外,ZooKeeper 还允许用户为每个节点添加一个特殊的属性:SEQUENTIAL。
一旦节点被标记上这个属性,那么在这个节点被创建的时候,ZooKeeper 会自动在其节点名后面追加上一个整型数字,这个整型数字是一个由父节点维护的自增数字。
版本
在前面我们已经提到,Zookeeper 的每个 ZNode 上都会存储数据,对应于每个 ZNode,Zookeeper 都会为其维护一个叫作 Stat 的数据结构。
Stat 中记录了这个 ZNode 的三个数据版本,分别是:
- version(当前 ZNode 的版本)
- cversion(当前 ZNode 子节点的版本)
- aversion(当前 ZNode 的 ACL 版本)
Watcher
Watcher(事件监听器),是 ZooKeeper 中的一个很重要的特性。
ZooKeeper 允许用户在指定节点上注册一些 Watcher,并且在一些特定事件触发的时候,ZooKeeper 服务端会将事件通知到感兴趣的客户端上去,该机制是 ZooKeeper 实现分布式协调服务的重要特性。
ACL
ZooKeeper 采用 ACL(AccessControlLists)策略来进行权限控制,类似于 UNIX 文件系统的权限控制。
ZooKeeper 定义了 5 种权限,如下图:

其中尤其需要注意的是,CREATE 和 DELETE 这两种权限都是针对子节点的权限控制。
ZooKeeper 特点
ZooKeeper 有哪些特点呢?具体如下:
- 顺序一致性:从同一客户端发起的事务请求,最终将会严格地按照顺序被应用到 ZooKeeper 中去。
- 原子性:所有事务请求的处理结果在整个集群中所有机器上的应用情况是一致的,也就是说,要么整个集群中所有的机器都成功应用了某一个事务,要么都没有应用。
- 单一系统映像:无论客户端连到哪一个 ZooKeeper 服务器上,其看到的服务端数据模型都是一致的。
- 可靠性:一旦一次更改请求被应用,更改的结果就会被持久化,直到被下一次更改覆盖。
ZooKeeper 设计目标
简单的数据模型
ZooKeeper 允许分布式进程通过共享的层次结构命名空间进行相互协调,这与标准文件系统类似。
名称空间由 ZooKeeper 中的数据寄存器组成,称为 Znode,这些类似于文件和目录。
与为存储设计的典型文件系统不同,ZooKeeper 数据保存在内存中,这意味着 ZooKeeper 可以实现高吞吐量和低延迟。
可构建集群
为了保证高可用,最好是以集群形态来部署 ZooKeeper,这样只要集群中大部分机器是可用的(能够容忍一定的机器故障),那么 ZooKeeper 本身仍然是可用的。
客户端在使用 ZooKeeper 时,需要知道集群机器列表,通过与集群中的某一台机器建立 TCP 连接来使用服务。
客户端使用这个 TCP 链接来发送请求、获取结果、获取监听事件以及发送心跳包。如果这个连接异常断开了,客户端可以连接到另外的机器上。
ZooKeeper 官方提供的架构图:
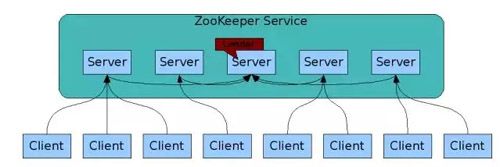
上图中每一个 Server 代表一个安装 ZooKeeper 服务的服务器。组成 ZooKeeper 服务的服务器都会在内存中维护当前的服务器状态,并且每台服务器之间都互相保持着通信。
集群间通过 Zab 协议(Zookeeper Atomic Broadcast)来保持数据的一致性。
顺序访问
对于来自客户端的每个更新请求,ZooKeeper 都会分配一个全局唯一的递增编号。
这个编号反应了所有事务操作的先后顺序,应用程序可以使用 ZooKeeper 这个特性来实现更高层次的同步原语。这个编号也叫做时间戳—zxid(ZooKeeper Transaction Id)。
高性能
ZooKeeper 是高性能的。在“读”多于“写”的应用程序中尤其地高性能,因为“写”会导致所有的服务器间同步状态。(“读”多于“写”是协调服务的典型场景。)
ZooKeeper 集群角色介绍
最典型集群模式:Master/Slave 模式(主备模式)。在这种模式中,通常 Master 服务器作为主服务器提供写服务,其他的 Slave 服务器从服务器通过异步复制的方式获取 Master 服务器最新的数据提供读服务。
但是,在 ZooKeeper 中没有选择传统的 Master/Slave 概念,而是引入了Leader、Follower 和 Observer 三种角色。
如下图所示:

ZooKeeper 集群中的所有机器通过一个 Leader 选举过程来选定一台称为 “Leader” 的机器。
Leader 既可以为客户端提供写服务又能提供读服务。除了 Leader 外,Follower 和 Observer 都只能提供读服务。
Follower 和 Observer 唯一的区别在于 Observer 机器不参与 Leader 的选举过程,也不参与写操作的“过半写成功”策略,因此 Observer 机器可以在不影响写性能的情况下提升集群的读性能。

ZooKeeper & ZAB 协议 & Paxos 算法
ZAB 协议 & Paxos 算法
Paxos 算法可以说是 ZooKeeper 的灵魂了。但是,ZooKeeper 并没有完全采用 Paxos 算法 ,而是使用 ZAB 协议作为其保证数据一致性的核心算法。
另外,在 ZooKeeper 的官方文档中也指出,ZAB 协议并不像 Paxos 算法那样,是一种通用的分布式一致性算法,它是一种特别为 ZooKeeper 设计的崩溃可恢复的原子消息广播算法。
ZAB 协议介绍
ZAB(ZooKeeper Atomic Broadcast 原子广播)协议是为分布式协调服务 ZooKeeper 专门设计的一种支持崩溃恢复的原子广播协议。
在 ZooKeeper 中,主要依赖 ZAB 协议来实现分布式数据一致性,基于该协议,ZooKeeper 实现了一种主备模式的系统架构来保持集群中各个副本之间的数据一致性。
ZAB 协议两种基本的模式
ZAB 协议包括两种基本的模式,分别是崩溃恢复和消息广播。
当整个服务框架在启动过程中,或是当 Leader 服务器出现网络中断、崩溃退出与重启等异常情况时,ZAB 协议就会进入恢复模式并选举产生新的 Leader 服务器。
当选举产生了新的 Leader 服务器,同时集群中已经有过半的机器与该 Leader 服务器完成了状态同步之后,ZAB 协议就会退出恢复模式。
其中,所谓的状态同步是指数据同步,用来保证集群中存在过半的机器能够和 Leader 服务器的数据状态保持一致。
当集群中已经有过半的 Follower 服务器完成了和 Leader 服务器的状态同步,那么整个服务框架就可以进人消息广播模式了。
当一台同样遵守 ZAB 协议的服务器启动后加入到集群中时,如果此时集群中已经存在一个 Leader 服务器在负责进行消息广播。
那么新加入的服务器就会自觉地进人数据恢复模式:找到 Leader 所在的服务器,并与其进行数据同步,然后一起参与到消息广播流程中去。
正如上文介绍中所说的,ZooKeeper 设计成只允许唯一的一个 Leader 服务器来进行事务请求的处理。
Leader 服务器在接收到客户端的事务请求后,会生成对应的事务提案并发起一轮广播协议。
而如果集群中的其他机器接收到客户端的事务请求,那么这些非 Leader 服务器会首先将这个事务请求转发给 Leader 服务器。
关于 ZAB 协议 & Paxos 算法需要讲和理解的东西太多了,推荐阅读下面两篇文章:
- 图解 Paxos 一致性协议:
http://blog.xiaohansong.com/2016/09/30/Paxos/
- Zookeeper ZAB 协议分析:
http://blog.xiaohansong.com/2016/08/25/zab/
关于如何使用 ZooKeeper 实现分布式锁,可以查看下面这篇文章:
- Zookeeper ZAB 协议分析:
https://blog.csdn.net/qiangcuo6087/article/details/79067136
总结
通过阅读本文,想必大家已从以下这七点了解了 ZooKeeper:
- ZooKeeper 的由来
- ZooKeeper 到底是什么
- ZooKeeper 的一些重要概念(会话(Session)、Znode、版本、Watcher、ACL)
- ZooKeeper 的特点
- ZooKeeper 的设计目标
- ZooKeeper 集群角色介绍(Leader、Follower 和 Observer 三种角色)
- ZooKeeper & ZAB 协议 & Paxos 算法
参考文章:
- 《从Paxos到Zookeeper 》
- https://cwiki.apache.org/confluence/display/ZOOKEEPER/ProjectDescription
- https://cwiki.apache.org/confluence/display/ZOOKEEPER/Index
- https://www.cnblogs.com/raphael5200/p/5285583.html
- https://zhuanlan.zhihu.com/p/30024403