数据处理:离散型变量编码及效果分析
Datawhale
作者:小雨姑娘,Datawhale成员
离散型变量编码的Python库
首先我要介绍这个关于离散型编码的Python库,里面封装了十几种(包括文中的所有方法)对于离散型特征的编码方法,接口接近于Sklearn通用接口,非常实用。下面是这个库的链接:
http://contrib.scikit-learn.org/categorical-encoding/
1.Label Encoder / Ordered Encoder
这个编码方式非常容易理解,就是把所有的相同类别的特征编码成同一个值,例如女=0,男=1,狗狗=2,所以最后编码的特征值是在[0, n-1]之间的整数。
这个编码的缺点在于它随机的给特征排序了,会给这个特征增加不存在的顺序关系,也就是增加了噪声。假设预测的目标是购买力,那么真实Label的排序显然是 女 > 狗狗 > 男,与我们编码后特征的顺序不存在相关性。
2.OneHot Encoder / Dummy Encoder / OHE
大家熟知的OneHot方法就避免了对特征排序的缺点。对于一列有N种取值的特征,Onehot方法会创建出对应的N列特征,其中每列代表该样本是否为该特征的某一种取值。因为生成的每一列有值的都是1,所以这个方法起名为Onehot特征。Dummy特征也是一样,只是少了一列,因为第N列可以看做是前N-1列的线性组合。但是在离散特征的特征值过多的时候不宜使用,因为会导致生成特征的数量太多且过于稀疏。
3. Sum Encoder (Deviation Encoder, Effect Encoder)
求和编码通过比较某一特征取值下对应标签(或其他相关变量)的均值与标签的均值之间的差别来对特征进行编码。但是据我所知 ,如果做不好细节,这个方法非常容易出现过拟合,所以需要配合留一法或者五折交叉验证进行特征的编码。还有根据方差加入惩罚项防止过拟合的方法,如果有兴趣的话我以后会更。
4. Helmet Encoder
Helmet编码是仅次于OHE和SumEncoder使用最广泛的编码方法,与SumEncoder不同的是,它比较的是某一特征取值下对应标签(或其他相关变量)的均值与他之前特征的均值之间的差异,而不是和所有特征的均值比较。这个特征同样容易出现过拟合的情况。不知道Helmet这个词是指的什么方面……使用标签时容易出现过拟合。
5. Frequency Encoder / Count Encoder
这个方法统计训练集中每个特征出现的频率,在某些场景下非常有用(例如推荐系统中商品被购买的次数,直接反映了商品的流行程度),也不容易出现过拟合,但是缺点是在每个特征的取值数分布比较均匀时会遗漏大量的信息。
6. Target Encoder
以下是计算公式:

![]()
其中 n 代表的是该某个特征取值的个数,n+代表某个特征取值下正Label的个数,mdl为一个最小阈值,样本数量小于此值的特征类别将被忽略,prior是Label的均值。注意,如果是处理回归问题的话,n+/n可以处理成相应该特征下label取值的average / max。对于k分类问题,会生成对应的k-1个特征。
此方法同样容易引起过拟合,以下方法用于防止过拟合:
增加正则项a的大小
在训练集该列中添加噪声
使用交叉验证
7. M-Estimate Encoder
M-Estimate Encoder 相当于 一个简化版的Target Encoder
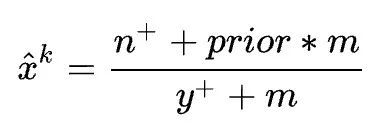
其中y+代表所有正Label的个数,m是一个调参的参数,m越大过拟合的程度就会越小,同洋的在处理连续值时n+可以换成label的求和,y+换成所有label的求和。
8. James-Stein Encoder
James-Stein Encoder 同样是基于target的一种算法。算法的思想很简单,对于特征的每个取值 k 可以根据下面的公式获得:
![]()
其中B由以下公式估计:

但是它有一个要求是target必须符合正态分布,这对于分类问题是不可能的,因此可以把y先转化成概率的形式。或者在实际操作中,使用grid search的方法选择一个比较好的B值。
9. Weight of Evidence Encoder
Weight Of Evidence 同样是基于target的方法。
基于以下公式计算:
![]()
![]()
最后每个特征取值可表示为:
WoE = ln(nomiinator / denominator})
10 . Leave-one-out Encoder (LOO or LOOE)
这个方法类似于SUM的方法,只是在计算训练集每个样本的特征值转换时都要把该样本排除(消除特征某取值下样本太少导致的严重过拟合),在计算测试集每个样本特征值转换时与SUM相同。可见以下公式:

11. Catboost Encoder
是Catboost中的encode方法,这个方法据说效果非常好,而且可以避免过拟合,可能有些复杂,在我写Catboost模型的时候会把它也写出来,这里就先不写了。
效果分析与讨论
数据集使用了八个存在离散型变量的数据集,最后的结果加权如下:
不使用交叉验证的情况:
HelmertEncoder 0.9517 SumEncoder 0.9434 FrequencyEncoder 0.9176 CatBoostEncoder 0.5728 TargetEncoder 0.5174 JamesSteinEncoder 0.5162 OrdinalEncoder 0.4964 WOEEncoder 0.4905 MEstimateEncoder 0.4501 BackwardDifferenceEncode0.4128 LeaveOneOutEncoder 0.0697
使用交叉验证的情况:
CatBoostEncoder 0.9726 OrdinalEncoder 0.9694 HelmertEncoder 0.9558 SumEncoder 0.9434 WOEEncoder 0.9326 FrequencyEncoder 0.9315 BackwardDifferenceEncode0.9108 TargetEncoder 0.8915 JamesSteinEncoder 0.8555 MEstimateEncoder 0.8189 LeaveOneOutEncoder 0.0729
下面是Kaggle上大佬们给出的一些建议,具体原因尚未分析,希望有大神在评论区可以给出解释。
对于无序的离散特征,实战中使用 OneHot, Hashing, LeaveOneOut, and Target encoding 方法效果较好,但是使用OneHot时要避免高基类别的特征以及基于决策树的模型,理由如下图所示:
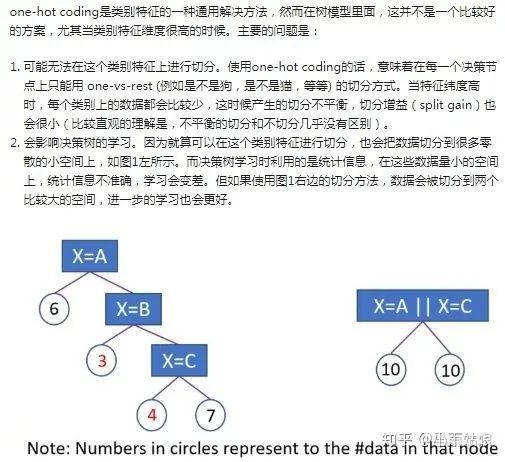
但是在实战中,我发现使用Xgboost处理高维稀疏的问题效果并不会很差。例如在IJCAI-18商铺中用户定位比赛中,一个很好的baseline就是把高维稀疏的wifi信号向量直接当做特征放到Xgboost里面,也可以获得很好的预测结果。不知道是不是因为Xgboost对于稀疏特征的优化导致。
对于有序离散特征,尝试 Ordinal (Integer), Binary, OneHot, LeaveOneOut, and Target. Helmert, Sum, BackwardDifference and Polynomial 基本没啥用,但是当你有确切的原因或者对于业务的理解的话,可以进行尝试。
对于回归问题而言,Target 与 LeaveOneOut 方法可能不会有比较好的效果。
LeaveOneOut、WeightOfEvidence、James-Stein、M-estimator 适合用来处理高基数特征。Helmert、Sum、Backward Difference、Polynomial 在机器学习问题里的效果往往不是很好(过拟合的原因)。
原文链接:https://zhuanlan.zhihu.com/p/87203369
AI学习路线和优质资源,在后台回复"AI"获取
