数据压缩 Huffman编码
Huffman编码器
实验原理
简介
(1) Huffman Coding (霍夫曼编码)是一种无失真编码的编码方式,Huffman 编码是可 变字长编码(VLC)的一种。
(2) Huffman 编码基于信源的概率统计模型,它的基本思路是,出现概率大的信源符 号编长码,出现概率小的信源符号编短码,从而使平均码长最小。
(3) 在程序实现中常使用一种叫做树的数据结构实现 Huffman 编码,由它编出的码是即时码。
数据结构
(1) Huffman节点

typedef struct huffman_node_tag
{
unsigned char isLeaf;//whether this node is leaf
unsigned long count;/*how many times the symbol
occured in the information source*/
struct huffman_node_tag *parent;/*parent node indicator*/
union
{/*to save storage.If the node is a leaf,the union stands for the Sequencesymbol;
else the union stands for the indicator of the left and right childnode.
*/
struct
{
struct huffman_node_tag *zero, *one;
};
unsigned char symbol;
};
} huffman_node;(2) Huffman码
typedef struct huffman_code_tag
{
//The length of this code in bits.
unsigned long numbits;
//The bits that make up this code.
//The first bit is at position 0 in bits[0].
//The second bit is at position 1 in bits[0].
//The eighth bit is at position 7 in bits[0].
//The ninth bit is at position 0 in bits[1].
unsigned char *bits;
} huffman_code;(3)用于输出码表的结构体
输出至txt文件,用于后续对平均码长及编码效率进行分析。
typedef struct huffman_statistics_result
{
float freq[256];
unsigned long numbits[256];
unsigned char bits[256][100];
}huffman_stat;
(4)使用到编译器函数库自带的快速排序函数qsort
qsort 的函数原型是
void qsort(void*base,size_t num,size_t width,int(__cdecl*compare)(const void*,const void*));其中base是排序的一个集合数组,num是这个数组元素的个数,width是一个元素的大小,compare是一个比较函数(自行设计)。
compare函数原型:
compare( (void *) & elem1, (void *) & elem2 );| Compare 函数的返回值 | 描述 |
|---|---|
| < 0 | elem1将被排在elem2前面 |
| =0 | elem1 等于 elem2 |
| >0 | elem1 将被排在elem2后面 |
实验流程
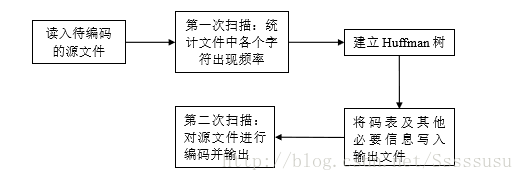
本实验Huffman码字生成的实现方法
(1)将文件以ASCII字符流的形式读入,统计每个符号的发生频率;
(2)将所有文件中出现过的字符按照频率从小到大的顺序排列;
(3)每一次选出最小的两个值,作为二叉树的两个叶子节点,将和作为它们的根节点,
这两个叶子节点不再参与比较,新的根节点参与比较;
(4)重复3,直到最后得到和为1的根节点;
(5)将形成的二叉树的左节点标0,右节点标1,把从最上面的根节点到最下面的叶子节
点途中遇到的0、1序列串起来,得到了各个字符的编码表示。
代码分析
代码分析采用全英文注释
本实验采用静态链接库实现。该程序文件包含两个两个工程(project),其中“Huff_run”为主工程(Win32 Console Application),其中包含程序的主函数,有“Huff_code”为库工程(Win32 Static Library)。
- Huff_code
Huffman.h
包含4个可供外部调用的函数(可以看做该库对外的接口)。
#ifndef HUFFMAN_HUFFMAN_H
#define HUFFMAN_HUFFMAN_H
#include Huffman.c
按照实验流程分析
1.从指定文件中读取数据(本实验以ASCII字符流),统计每个符号发生的概率,并建立相应的树叶节点。
#define MAX_SYMBOLS 256
typedef huffman_node* SymbolFrequencies[MAX_SYMBOLS];static unsigned int
get_symbol_frequencies(SymbolFrequencies *pSF, FILE *in)
{
int c;
//The total number of source symbols is initialized to 0.
unsigned int total_count = 0;
/* Set all frequencies to 0. */
init_frequencies(pSF);
/*Count the frequency of each symbol in the input file.Scan the whole file for the first time.*/
while((c = fgetc(in)) != EOF)
{
unsigned char uc = c;
/* If c(that is, uc) is new symbol,
a new leaf node for that character is generated*/
if(!(*pSF)[uc])
(*pSF)[uc] = new_leaf_node(uc);
/*the frequency(Unit:times) of the current symbol +1 */
++(*pSF)[uc]->count;
/*the total number of source Ssymbol +1 */
++total_count;
}
return total_count;
}/*New a leaf node and initialize it.*/
static huffman_node*
new_leaf_node(unsigned char symbol)
{
huffman_node *p = (huffman_node*)malloc(sizeof(huffman_node));
p->isLeaf = 1;
p->symbol = symbol;
p->count = 0;
p->parent = 0;
return p;
}2.构建霍夫曼树及生成霍夫曼码 。
(1) 按字符概率由小到大将对应结点排序
(2) 得到文件出现的字符种类数。
(3)构建霍夫曼树
#define DEBUG true
/* calculate_huffman_codes turns pSF into an array */
/* with a single entry that is the root of the */
/* huffman tree. The return value is a SymbolEncoder, */
/* which is an array of huffman codes index by symbol value. */
static SymbolEncoder*
calculate_huffman_codes(SymbolFrequencies * pSF)
{
unsigned int i = 0;
unsigned int n = 0;
huffman_node *m1 = NULL, *m2 = NULL;
SymbolEncoder *pSE = NULL;
#if DEBUG
printf("BEFORE SORT\n");
print_freqs(pSF); //to present the use of stack
#endif
/* Sort the symbol frequency array by ascending frequency. */
qsort((*pSF), MAX_SYMBOLS, sizeof((*pSF)[0]), SFComp);
/*Function SFComp is called by function qsort to
compare two element of array by the frequency of source symbol
and return some certain value to indicate qsort how to rank.*/
#if DEBUG
printf("AFTER SORT\n");
print_freqs(pSF);
#endif
/* Get the number of symbols. */
for(n = 0; n < MAX_SYMBOLS && (*pSF)[n]; ++n)
;
/* Construct a Huffman tree. This code is based*/
/* on the algorithm given in Managing Gigabytes*/
/* by Ian Witten et al, 2nd edition, page 34. */
/* Note that this implementation uses a simple */
/* count instead of probability. */
/*Build huffman tree.*/
/*It needs to merge n-1 times, so cycle n-1 times.*/
for(i = 0; i < n - 1; ++i)
{
/* Set m1 and m2 to the two subsets of least probability. */
m1 = (*pSF)[0];
m2 = (*pSF)[1];
/* Replace m1 and m2 with a set {m1, m2} whose probability
* is the sum of that of m1 and m2. */
(*pSF)[0] = m1->parent = m2->parent =
new_nonleaf_node(m1->count + m2->count, m1, m2);
(*pSF)[1] = NULL;
/* Put newSet into the correct count position in pSF. */
qsort((*pSF), n, sizeof((*pSF)[0]), SFComp);
}
/* Build the SymbolEncoder array from the tree. */
pSE = (SymbolEncoder*)malloc(sizeof(SymbolEncoder));
memset(pSE, 0, sizeof(SymbolEncoder));
build_symbol_encoder((*pSF)[0], pSE);
return pSE;
}其中qsort函数使用到的比较函数SFComp代码如下:
/*
// * When used by qsort, SFComp sorts the array so that
* the symbol with the lowest frequency is first. Any
* NULL entries will be sorted to the end of the list.
*/
static int
SFComp(const void *p1, const void *p2)
{
const huffman_node *hn1 = *(const huffman_node**)p1;
const huffman_node *hn2 = *(const huffman_node**)p2;
/* Sort all NULLs to the end. */
if(hn1 == NULL && hn2 == NULL)
return 0;
if(hn1 == NULL)
return 1;
if(hn2 == NULL)
return -1;
if(hn1->count > hn2->count)
return 1;
else if(hn1->count < hn2->count)
return -1;
return 0;
}(4)对霍夫曼树编码
// build_symbol_encoder builds a SymbolEncoder by walking
// from root down to the leaves of the Huffman tree and then,
// for each leaf, determines its code.
// Recursive operation based on depth
static void
build_symbol_encoder(huffman_node *subtree, SymbolEncoder *pSF)
{
if(subtree == NULL)
return;
/*If subtree is a leaf, a huffman_code is generated.*/
if(subtree->isLeaf)
(*pSF)[subtree->symbol] = new_code(subtree);//
else
{
/*Depth traversal*/
build_symbol_encoder(subtree->zero, pSF);
build_symbol_encoder(subtree->one, pSF);
}
}对每个树叶节点进行编码:
//new_code builds a huffman_code from a leaf in a Huffman tree.
static huffman_code*
new_code(const huffman_node* leaf)
{
// Build the huffman code by walking up to
* the root node and then reversing the bits,
* since the Huffman code is calculated by
* walking down the tree. */
unsigned long numbits = 0;/*code length*/
unsigned char* bits = NULL;/*the first address of the code*/
huffman_code *p;
/*
*leaf!=NULL:
The current huffman_node exists,which needs to be encoded.
*leaf->parent!=NULL:
The current huffman_node has parent,indicating that
the encoding process of the current node
(backtracking from leaf to root)
has not yet completed.
*/
while(leaf && leaf->parent)
{
huffman_node *parent = leaf->parent;
unsigned char cur_bit = (unsigned char)(numbits % 8);
/*cur_bit:position of the encoding bit in the current byte,
ranging from 0 to 7.*/
unsigned long cur_byte = numbits / 8;
/*cur_byte:
Currently,how many complete bytes has been encoded.*/
/* cur_bit==0:The encoding bit is the first bit of a byte,
and the last byte has completely encoded,
so it needs to build a new coding byte.
If we need another byte to hold the code,
then allocate it. ==> newSize=cur_byte+1
*/
if(cur_bit == 0)
{
size_t newSize = cur_byte + 1;
bits = (char*)realloc(bits, newSize);
bits[newSize - 1] = 0; /* Initialize the new byte. */
/*
Function"realloc" is different from function "malloc".
"Realloc" can reallocate new space in the case of
keeping the original data unchanged.
The original data lies in the front of new space.
(The space's address may be changed.)
*/
}
/* If a "one" must be added then or it in. If a zero
* must be added then do nothing, since the byte
* was initialized to zero. */
if(leaf == parent->one)
bits[cur_byte] |= 1 << cur_bit;
/*Shift 1 left to the encoding bit.*/
++numbits;
leaf = parent;/*backtracking*/
}
if(bits)
reverse_bits(bits, numbits);
/*From the above it can be seen that the encoding process
is from leaf backtracking to root.(Leaf lies in the low bit,and root in the high.)
So the bit order of code is inverted.
Function "reverse_bits" is used to reverse the bit order of the whole code.*/
p = (huffman_code*)malloc(sizeof(huffman_code));
p->numbits = numbits;
p->bits = bits;
/*The bytes number is integer.
Coresponding with numbits,the real codeword can be obtained*/
return p;
}码字逆序:
//In order to reverse the bit order of the whole code.
static void
reverse_bits(unsigned char* bits, unsigned long numbits)
{
unsigned long numbytes = numbytes_from_numbits(numbits);
unsigned char *tmp =
(unsigned char*)alloca(numbytes);
/*The funciton "alloca" applies for space on the stack
and is released automatically.*/
unsigned long curbit;
long curbyte = 0;
memset(tmp, 0, numbytes);
for(curbit = 0; curbit < numbits; ++curbit)
{
unsigned int bitpos = curbit % 8;
/*bitpos:the position,where curbit
is located in the current byte.*/
if(curbit > 0 && curbit % 8 == 0)
++curbyte;
/*Get inverted bit and put in the 0th bit,
then shift left to the positive bit position. */
tmp[curbyte] |= (get_bit(bits, numbits - curbit - 1) << bitpos);
}
memcpy(bits, tmp, numbytes);
/*Copy "numbytes" bytes from the begining of tmp to "bits"*/
}3.将码表及其他必要信息写入输出文件(txt文件)
/*In order to calculate frequencies by appearence times(count).*/
int huffST_getSymFrequencies(SymbolFrequencies *SF, huffman_stat *st,int total_count)
{
int i,count =0;
for(i = 0; i < MAX_SYMBOLS; ++i)
{
if((*SF)[i])
{
st->freq[i]=(float)(*SF)[i]->count/total_count;
count+=(*SF)[i]->count;
}
else
{
st->freq[i]= 0;
}
}
if(count==total_count)
return 1;
else
return 0;
}
/*Get codeword and its other information and save them
to structure huffman_stat in order to output codeword table
to txt file.*/
int huffST_getcodeword(SymbolEncoder *se, huffman_stat *st)
{
unsigned long i,j;
for(i = 0; i < MAX_SYMBOLS; ++i)
{
huffman_code *p = (*se)[i];
if(p)
{
unsigned int numbytes;
st->numbits[i] = p->numbits;
numbytes = numbytes_from_numbits(p->numbits);
for (j=0;jbits[i][j] = p->bits[j];
}
else
st->numbits[i] =0;
}
return 0;
}
/*Output the statistic results and huffman code table to file.*/
void output_huffman_statistics(huffman_stat *st,FILE *out_Table)
{
int i,j;
unsigned char c;
fprintf(out_Table,"symbol\t freq\t codelength\t code\n");
for(i = 0; i < MAX_SYMBOLS; ++i)
{
/*Use the key "Tab" to seperate each element of huffman_stat,
so that the file can be read by other software, such as Excel.
*/
fprintf(out_Table,"%d\t ",i);
fprintf(out_Table,"%f\t ",st->freq[i]);
fprintf(out_Table,"%d\t ",st->numbits[i]);
if(st->numbits[i])
{
for(j = 0; j < st->numbits[i]; ++j)
{
c =get_bit(st->bits[i], j);
fprintf(out_Table,"%d",c);
}
}
fprintf(out_Table,"\n");
}
} 4.第二次扫描: 对源文件进行编码并输出
(1)将码表输出到输出文件
/*
* Write the huffman code table. The format is:
* 4 byte code count in network byte order.
* 4 byte number of bytes encoded
* (if you decode the data, you should get this number of bytes)
* code1
* ...
* codeN, where N is the count read at the begginning of the file.
* Each codeI has the following format:
* 1 byte symbol, 1 byte code bit length, code bytes.
* Each entry has numbytes_from_numbits code bytes.
* The last byte of each code may have extra bits, if the number of
* bits in the code is not a multiple of 8.
*/
static int
write_code_table(FILE* out, SymbolEncoder *se, unsigned int symbol_count)
{
unsigned long i, count = 0;
//Determine the number of entries in se.
for(i = 0; i < MAX_SYMBOLS; ++i)
{
if((*se)[i])
++count;
}
//htonl():This function converts a 32-bit number
//from the host byte order to the network byte order of an unsigned long integer.
//In the network transmission, big-endian order is used,
//for 0x0A0B0C0D, the order of transmission is 0A 0B 0C 0D,
//so we take big-endian as network byte order,
//little-endian as host byte order.
//The advantage of little-endian order is
//that unsigned char / short / int/ long type conversion
//can be accomplished without the storage location change.
/* Write the number of entries in network byte order. */
i = htonl(count);
if(fwrite(&i, sizeof(i), 1, out) != 1)
return 1;
/* Write the number of bytes that will be encoded. */
symbol_count = htonl(symbol_count);
if(fwrite(&symbol_count, sizeof(symbol_count), 1, out) != 1)
return 1;
/* Write the entries. */
for(i = 0; i < MAX_SYMBOLS; ++i)
{
huffman_code *p = (*se)[i];
if(p)
{
unsigned int numbytes;
/* Write the 1 byte symbol. */
fputc((unsigned char)i, out);
/* Write the 1 byte code bit length. */
fputc(p->numbits, out);
/* Write the code bytes. */
numbytes = numbytes_from_numbits(p->numbits);
if(fwrite(p->bits, 1, numbytes, out) != numbytes)
return 1;
}
}
return 0;
}(2)遍历输入文件,对信源符号按已生成的码表编码,并输出码字
//This function is used in the second file scan
//in order to encode the whole input file by looking up the code table.
static int
do_file_encode(FILE* in, FILE* out, SymbolEncoder *se)
{
unsigned char curbyte = 0;
unsigned char curbit = 0;
int c;
/*Traverse each symbol(/bytes) of the file.*/
while((c = fgetc(in)) != EOF)
{
unsigned char uc = (unsigned char)c;
huffman_code *code = (*se)[uc];/*Look up the code table.*/
unsigned long i;
for(i = 0; i < code->numbits; ++i)
{
/* Add the current bit to curbyte. */
curbyte |= get_bit(code->bits, i) << curbit;
/* If this byte is filled up then write it
* out and reset the curbit and curbyte. */
if(++curbit == 8)
{
fputc(curbyte, out);
curbyte = 0;
curbit = 0;
}
}
}
/*
* If there is data in curbyte that has not been
* output yet, which means that the last encoded
* character did not fall on a byte boundary,
* then output it.
*/
if(curbit > 0)
fputc(curbyte, out);
return 0;
}5.编码器对外部的接口
/*
* huffman_encode_file huffman encodes in to out.
*/
//step1:changed by yzhang for huffman statistics from (FILE *in, FILE *out) to (FILE *in, FILE *out, FILE *out_Table)
int
huffman_encode_file(FILE *in, FILE *out, FILE *out_Table)
{
SymbolFrequencies sf;
SymbolEncoder *se;
huffman_node *root = NULL;
int rc;
unsigned int symbol_count;
//step2:add by yzhang for huffman statistics
huffman_stat hs;
//end by yzhang
/* Get the frequency of each symbol in the input file. */
symbol_count = get_symbol_frequencies(&sf, in);
//step3:add by yzhang for huffman statistics,... get the frequency of each symbol
huffST_getSymFrequencies(&sf,&hs,symbol_count);
//end by yzhang
/* Build an optimal table from the symbolCount. */
se = calculate_huffman_codes(&sf);
root = sf[0];
//step3:add by yzhang for huffman statistics... output the statistics to file
huffST_getcodeword(se, &hs);
output_huffman_statistics(&hs,out_Table);
//end by yzhang
/* Scan the file again and, using the table
previously built, encode it into the output file. */
//Reset the file incator to the beginning of the file.
rewind(in);
//First,write huffman code table to the output file.
rc = write_code_table(out, se, symbol_count);
/*"rc==0" stands for the fact that writing code table is successful.
And then encode the whole input file by huffman code table
into output file.
*/
if(rc == 0)
rc = do_file_encode(in, out, se);
/* Free the Huffman tree. */
free_huffman_tree(root);
free_encoder(se);
return rc;
}
- Huff_run
Huffcode.c
#include "huffman.h"
#include 实验结果
选择十种不同格式类型的文件,使用Huffman编码器进行压缩得到输出的压缩比特流文件。根据输出的码字及其必要信息的文件,对各种不同格式的文件进行压缩效率的分析。将存有码字信息的txt文件导入到excel中,进行统计分析。


(1)以表格形式表示的实验结果
| file type | avi | doc | excel | jpg | mp4 |
|---|---|---|---|---|---|
| average_codelength | 7.970551 | 2.604187 | 7.81014 | 7.991087 | 8.000016 |
| entropy | 7.952410383 | 2.47715948 | 7.778867823 | 7.972575064 | 7.999820052 |
| original file size(KB) | 7531.64 | 11 | 35.7 | 293 | 58188.58 |
| compressed file size(KB) | 7504.74 | 4.44 | 35.7 | 294 | 58189.34 |
| Compression ratio | 1.003584401 | 2.477477477 | 1 | 0.996598639 | 0.999986939 |
| file type | png | ppt | psd | rar | |
|---|---|---|---|---|---|
| average_codelength | 7.966299 | 7.998246 | 5.810035 | 6.067207 | 7.999944 |
| entropy | 7.949396899 | 7.980677645 | 5.763231865 | 6.040932735 | 7.998544022 |
| original file size(KB) | 212 | 249 | 396 | 693 | 313 |
| compressed file size(KB) | 212 | 250 | 288 | 526 | 314 |
| Compression ratio | 1 | 0.996 | 1.375 | 1.317490494 | 0.996815287 |
(2)各样本文件的概率分布图
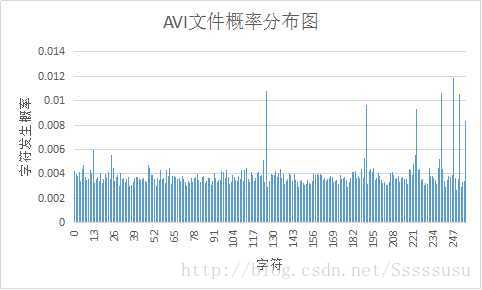
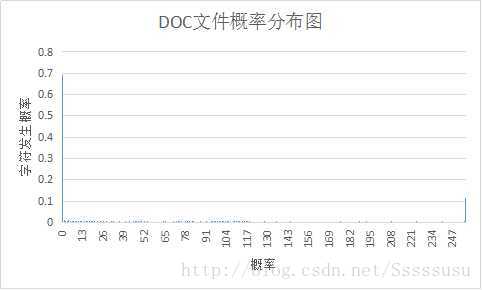







(3)实验结果的分析
根据香农第一定理(无失真信源编码定理),对于二进制码信源符号,平均码长的下界为信源熵。当信源符号接近等概分布时,信源熵最大,而平均码长也没有可降低的空间了。故当文件的概率分布越不均匀,通过霍夫曼编码得到的编码效率越高。