clickhouse简介及应用
一、Clickhouse的特点
- Clickhouse采用列式存储:
列式储存的好处:
1 对于列的聚合,计数,求和等统计操作原因优于行式存储。
2 由于某一列的数据类型都是相同的,针对于数据存储更容易进行数据压缩,每一列选择更优的数据压缩算法,大大提高了数据的压缩比重。
3 由于数据压缩比更好,一方面节省了磁盘空间,另一方面对于cache也有了更大的发挥空间。
- 多样化引擎
clickhouse和mysql类似,把表级的存储引擎插件化,根据表的不同需求可以设定不同的存储引擎。
- 写数据
ClickHouse采用类LSM Tree的结构,数据写入后定期在后台合并。通过类LSM tree的结构,但是没有内存表,没有预写日志,ClickHouse在数据导入时全部是顺序append写入磁盘,在后台周期性合并数据到主数据段。
不支持常规意义的修改行和删除行数据。
不支持事务。
- 读数据
语句级多线程:在这种设计下,单条Query就能利用整机所有CPU。
稀疏索引:索引之间的颗粒度(默认8192行)。
二、数据类型
1 整型
整型范围(-2n-1~2n-1-1):
Int8 - [-128 : 127]
Int16 - [-32768 : 32767]
Int32 - [-2147483648 : 2147483647]
Int64 - [-9223372036854775808 : 9223372036854775807]
无符号整型范围(0~2n-1):
UInt8 - [0 : 255]
UInt16 - [0 : 65535]
UInt32 - [0 : 4294967295]
UInt64 - [0 : 18446744073709551615]
2 浮点型
Float32 - float
Float64 – double
3 布尔型
没有单独的类型来存储布尔值。可以使用 UInt8 类型,取值限制为 0 或 1。
4 Decimal 型
Decimal32(s),相当于Decimal(9-s,s)
Decimal64(s),相当于Decimal(18-s,s)
Decimal128(s),相当于Decimal(38-s,s)
s标识小数位
5 字符串
1)String
字符串可以任意长度的。它可以包含任意的字节集,包含空字节。
2)FixedString(N)
固定长度 N 的字符串,N 必须是严格的正自然数。
6 枚举类型
Enum8 用 ‘String’= Int8 对描述。
Enum16 用 ‘String’= Int16 对描述。
7 时间类型
Date 接受 年-月-日 的字符串比如 ‘2019-12-16’
Datetime 接受 年-月-日 时:分:秒 的字符串比如 ‘2019-12-16 20:50:10’
Datetime64 接受 年-月-日 时:分:秒.亚秒 的字符串比如 ‘2019-12-16 20:50:10.66’
8 数组
Array(T):由 T 类型元素组成的数组。
三 、表引擎
1、MergeTree
Clickhouse中最强大的表引擎当属 MergeTree (合并树)引擎及该系列(*MergeTree)中的其他引擎。
建表语句
create table t_order_mt(
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine =MergeTree
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id)
-
partition by 分区 (可选项)
如果不填: 只会使用一个分区。
分区目录: MergeTree 是以列文件+索引文件+表定义文件组成的,但是如果设定了分区那么这些文件就会保存到不同的分区目录中。
**并行:**分区后,面对涉及跨分区的查询统计,clickhouse会以分区为单位并行处理。
数据写入与分区合并:
任何一个批次的数据写入都会产生一个临时分区,不会纳入任何一个已有的分区。写入后的某个时刻(大概10-15分钟后),clickhouse会自动执行合并操作(等不及也可以手动通过optimize执行),把临时分区的数据,合并到已有分区中。
optimize table xxxx [final]
手动触发合并,除了合并分区还有很多别的事件会触发。
加入final选项,保证即使数据已经合并完成,也会强行合并(主要是可以保证触发其他事件)。否则的话,如果数据已经合并完成,则不会合并,也不会触发其他事件。
- primary key主键(可选)
clickhouse中的主键,和其他数据库不太一样,它只提供了数据的一级索引,但是却不是唯一约束。
- order by (必选)
order by 设定了分区内的数据按照哪些字段顺序进行有序保存。
order by是MergeTree中唯一一个必填项,甚至比primary key 还重要,因为当用户不设置主键的情况,很多处理会依照order by的字段进行处理(比如后面会讲的去重和汇总)。
要求:主键必须是order by字段的前缀字段。
- 数据TTL
TTL即Time To Live,MergeTree提供了可以管理数据或者列的生命周期的功能。
-- 列级别TTL
create table t_order_mt3(
id UInt32,
sku_id String,
total_amount Decimal(16,2) TTL create_time+interval 10 SECOND,-- 当前系统时间+10s
create_time Datetime
) engine =MergeTree
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id, sku_id)
-- 表级TTL
alter table t_order_mt3 MODIFY TTL create_time + INTERVAL 10 SECOND;2、ReplacingMergeTree
ReplacingMergeTree是MergeTree的一个变种,它存储特性完全继承MergeTree,只是多了一个去重的功能。
去重时机:数据的去重只会在合并的过程中出现。合并会在未知的时间在后台进行,所以你无法预先作出计划。有一些数据可能仍未被处理。
去重范围:如果表经过了分区,去重只会在分区内部进行去重,不能执行跨分区的去重。
认为order by相同的为相同的数据,并且在同一个分区
create table t_order_rmt(
id UInt32,
sku_id String,
total_amount Decimal(16,2) ,
create_time Datetime
) engine =ReplacingMergeTree(create_time)
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id, sku_id)
-- ReplacingMergeTree() 填入的参数为版本字段,重复数据保留版本字段值最大的。
-- 如果不填版本字段,默认保留最后一条。 通过测试得到结论:
Ø 实际上是使用order by 字段作为唯一键。
Ø 去重不能跨分区。
Ø 只有合并分区才会进行去重。
Ø 认定重复的数据保留,版本字段值最大的。
Ø 如果版本字段相同则保留最后一笔。
3、SummingMergeTree
create table t_order_smt(
id UInt32,
sku_id String,
total_amount Decimal(16,2) ,
create_time Datetime
) engine = SummingMergeTree(total_amount)
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id )
以SummingMergeTree()中指定的列作为汇总数据列。可以填写多列必须数字列,如果不填,以所有非维度列且为数字列的字段为汇总数据列。
以order by 的列为准,作为维度列。
其他的列保留第一行。
不在一个分区的数据不会被聚合。
在求和时,还是要用sum,因为可能会包含一些还没来得及聚合的临时明细。
四、SQL操作
1、Insert
包括标准 insert into [table_name] values(…),(….)
以及 从表到表的插入
insert into [table_name] select a,b,c from [table_name_2]
2、Update 和 Delete
虽然可以实现修改和删除,但是和一般的OLTP数据库不一样,Mutation语句是一种很“重”的操作,而且不支持事务。
“重”的原因主要是每次修改或者删除都会导致放弃目标数据的原有分区,重建新分区。所以尽量做批量的变更,不要进行频繁小数据的操作。
其他的基本和MySQL一样。
五、副本
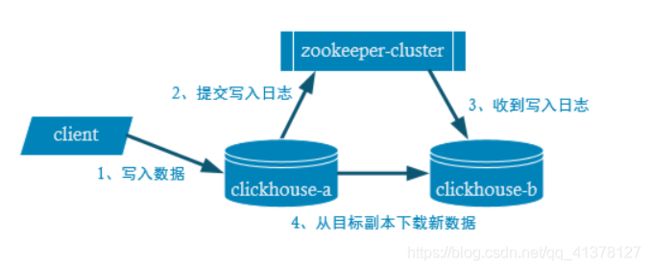
配置:
/etc/clickhouse-server/config.d目录下创建一个名为metrika.xml的配置文件:
hdp1
2181
hdp2
2181
hdp3
2181
在 /etc/clickhouse-server/config.xml中增加
/etc/clickhouse-server/config.d/metrika.xml
建表:
create table rep_t_order_mt_0105 (
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine =ReplicatedMergeTree('/clickhouse/tables/01/rep_t_order_mt_0105','rep_hdp1')
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id);ReplicatedMergeTree 中,
第一参数是分片的zk_path,一般按照:
/clickhouse/table/{shard}/{table_name} 的格式写,如果只有一个分片就写01即可。
reate_time Datetime
) engine =ReplicatedMergeTree(’/clickhouse/tables/01/rep_t_order_mt_0105’,‘rep_hdp1’)
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id);
ReplicatedMergeTree 中,
第一参数是分片的zk_path,一般按照:
/clickhouse/table/{shard}/{table_name} 的格式写,如果只有一个分片就写01即可。
第二个参数是副本名称,相同的分片副本名称不能相同。