一、Beautiful Soup简介
简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据。官方解释如下:
-
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
-
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
-
Beautiful Soup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度。
废话不多说,直接开始动手吧!
二、实战
1.背景介绍
小说网站-笔趣看:
URL:http://www.biqukan.com/
笔趣看是一个盗版小说网站,这里有很多起点中文网的小说,该网站小说的更新速度稍滞后于起点中文网正版小说的更新速度。并且该网站只支持在线浏览,不支持小说打包下载。因此,本次实战就是从该网站爬取并保存一本名为《一念永恒》的小说,该小说是耳根正在连载中的一部玄幻小说。PS:本实例仅为交流学习,支持耳根大大,请上起点中文网订阅。
2.Beautiful Soup安装
我们我可以使用pip3或者easy_install来安装,在cmd命令窗口中的安装命令分别如下:
a)pip3安装
pip3 install beautifulsoup4- 1
b)easy_install安装
easy_install beautifulsoup4- 1
3.预备知识
更为详细内容,可参考官方文档:
URL:http://beautifulsoup.readthedocs.io/zh_CN/latest/
a)创建Beautiful Soup对象
from bs4 import BeautifulSoup
#html为解析的页面获得html信息,为方便讲解,自己定义了一个html文件
html = """
<html>
<head>
<title>Jack_Cuititle> head> <body> <p class="title" name="blog"><b>My Blogb>p> <li>li> <a href="http://blog.csdn.net/c406495762/article/details/58716886" class="sister" id="link1">Python3网络爬虫(一):利用urllib进行简单的网页抓取a><br/> <a href="http://blog.csdn.net/c406495762/article/details/59095864" class="sister" id="link2">Python3网络爬虫(二):利用urllib.urlopen发送数据a><br/> <a href="http://blog.csdn.net/c406495762/article/details/59488464" class="sister" id="link3">Python3网络爬虫(三):urllib.error异常a><br/> body> html> """ #创建Beautiful Soup对象 soup = BeautifulSoup(html,'lxml')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
如果将上述的html的信息写入一个html文件,打开效果是这样的(为注释内容,不会显示):
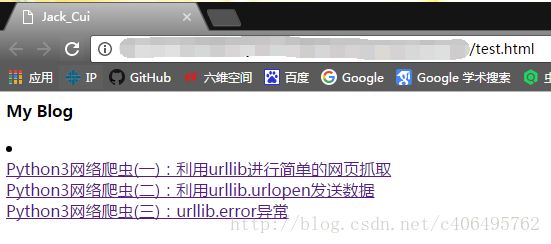
同样,我们还可以使用本地HTML文件来创建对象,代码如下:
soup = BeautifulSoup(open(test.html),'lxml')- 1
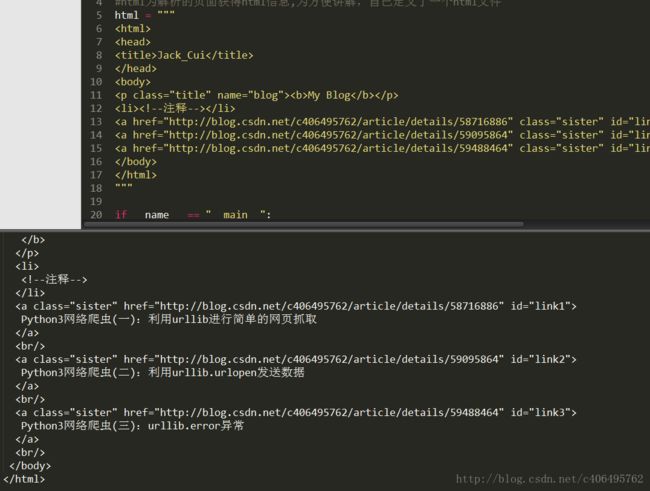
使用如下代码格式化输出:
print(soup.prettify())- 1
b)Beautiful Soup四大对象
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:
- Tag
- NavigableString
- BeautifulSoup
- Comment
(1)Tag
Tag通俗点讲就是HTML中的一个个标签,例如
<title>Jack_Cuititle>- 1
上面的title就是HTML标签,标签加入里面包括的内容就是Tag,下面我们来感受一下怎样用 Beautiful Soup 来方便地获取 Tags。
下面每一段代码中注释部分即为运行结果:
print(soup.title)
#<title>Jack_Cuititle>
print(soup.head)
#<head> <title>Jack_Cuititle>head> print(soup.a) #<a class="sister" href="http://blog.csdn.net/c406495762/article/details/58716886" id="link1">Python3网络爬虫(一):利用urllib进行简单的网页抓取a> print(soup.p) #<p class="title" name="blog"><b>My Blogb>p>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
我们可以利用 soup加标签名轻松地获取这些标签的内容,是不是感觉比正则表达式方便多了?不过有一点是,它查找的是在所有内容中的第一个符合要求的标签,如果要查询所有的标签,我们在后面进行介绍。
我们也可验证一下这些对象的类型:
print(type(soup.title)) #- 1
- 2
对于Tag,有两个重要的属性:name和attrs
name:
print(soup.name)
print(soup.title.name)
#[document]
#title- 1
- 2
- 3
- 4
soup 对象本身比较特殊,它的 name 即为 [document],对于其他内部标签,输出的值便为标签本身的名称。
attrs:
print(soup.a.attrs)
#{'class': ['sister'], 'href': 'http://blog.csdn.net/c406495762/article/details/58716886', 'id': 'link1'}- 1
- 2
在这里,我们把 a 标签的所有属性打印输出了出来,得到的类型是一个字典。
如果我们想要单独获取某个属性,可以这样,例如我们获取a标签的class叫什么,两个等价的方法如下:
print(soup.a['class'])
print(soup.a.get('class'))
#['sister']
#['sister']- 1
- 2
- 3
- 4
(2)NavigableString
既然我们已经得到了标签的内容,那么问题来了,我们要想获取标签内部的文字怎么办呢?很简单,用 .string 即可,例如
print(soup.title.string)
#Jack_Cui- 1
- 2
(3)BeautifulSoup
BeautifulSoup 对象表示的是一个文档的全部内容.大部分时候,可以把它当作 Tag 对象,是一个特殊的 Tag,我们可以分别获取它的类型,名称,以及属性:
print(type(soup.name))
print(soup.name)
print(soup.attrs)
#
#[document] #{} - 1
- 2
- 3
- 4
- 5
- 6
(4)Comment
Comment对象是一个特殊类型的NavigableString对象,其实输出的内容仍然不包括注释符号,但是如果不好好处理它,可能会对我们的文本处理造成意想不到的麻烦。
print(soup.li)
print(soup.li.string)
print(type(soup.li.string))
#<li>li> #注释 #<class 'bs4.element.Comment'>- 1
- 2
- 3
- 4
- 5
- 6
li标签里的内容实际上是注释,但是如果我们利用 .string 来输出它的内容,我们发现它已经把注释符号去掉了,所以这可能会给我们带来不必要的麻烦。
我们打印输出下它的类型,发现它是一个 Comment 类型,所以,我们在使用前最好做一下判断,判断代码如下:
from bs4 import element
if type(soup.li.string) == element.Comment: print(soup.li.string)- 1
- 2
- 3
- 4
上面的代码中,我们首先判断了它的类型,是否为 Comment 类型,然后再进行其他操作,如打印输出。
c)遍历文档数
(1)直接子节点(不包含孙节点)
contents:
tag的content属性可以将tag的子节点以列表的方式输出:
print(soup.body.contents)
#['\n', <p class="title" name="blog"><b>My Blogb>p>, '\n', <li>li>, '\n', <a class="sister" href="http://blog.csdn.net/c406495762/article/details/58716886" id="link1">Python3网络爬虫(一):利用urllib进行简单的网页抓取a>, <br/>, '\n', <a class="sister" href="http://blog.csdn.net/c406495762/article/details/59095864" id="link2">Python3网络爬虫(二):利#用urllib.urlopen发送数据a>, <br/>, '\n', <a class="sister" href="http://blog.csdn.net/c406495762/article/details/59488464" id="link3">Python3网络爬虫(三):urllib.error异常a>, <br/>, '\n']- 1
- 2
- 3
输出方式为列表,我们可以用列表索引来获取它的某一个元素:
print(soup.body.contents[1])
<p class="title" name="blog"><b>My Blogb>p>- 1
- 2
children:
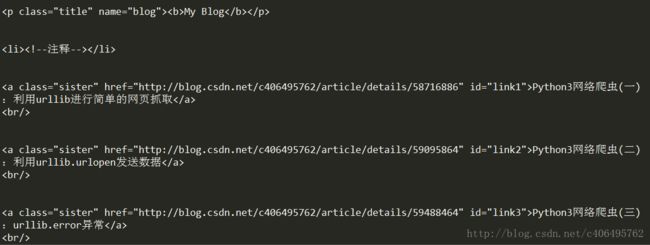
它返回的不是一个 list,不过我们可以通过遍历获取所有子节点,它是一个 list 生成器对象:
for child in soup.body.children:
print(child)- 1
- 2
结果如下图所示:
(2)搜索文档树
find_all(name, attrs, recursive, text, limit, **kwargs):
find_all() 方法搜索当前tag的所有tag子节点,并判断是否符合过滤器的条件。
1) name参数:
name 参数可以查找所有名字为 name 的tag,字符串对象会被自动忽略掉。
传递字符:
最简单的过滤器是字符串,在搜索方法中传入一个字符串参数,Beautiful Soup会查找与字符串完整匹配的内容,下面的例子用于查找文档中所有的标签:
print(soup.find_all('a'))
#['\n', <p class="title" name="blog"><b>My Blogb>p>, '\n', <li>li>, '\n', <a class="sister" href="http://blog.csdn.net/c406495762/article/details/58716886" id="link1">Python3网络爬虫(一):利用urllib进行简单的网页抓取a>, <br/>, '\n', <a class="sister" href="http://blog.csdn.net/c406495762/article/details/59095864" id="link2">Python3网络爬虫(二):利用urllib.urlopen发送数据a>, <br/>, '\n', <a class="sister" href="http://blog.csdn.net/c406495762/article/details/59488464" id="link3">Python3网络爬虫(三):urllib.error异常a>, <br/>, '\n']- 1
- 2
- 3
传递正则表达式:
如果传入正则表达式作为参数,Beautiful Soup会通过正则表达式的 match() 来匹配内容.下面例子中找出所有以b开头的标签,这表示和标签都应该被找到
import re
for tag in soup.find_all(re.compile("^b")):
print(tag.name)
#body
#b
#br #br #br- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
传递列表:
如果传入列表参数,Beautiful Soup会将与列表中任一元素匹配的内容返回,下面代码找到文档中所有
- 1
- 2
传递True:
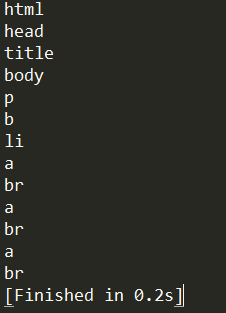
True 可以匹配任何值,下面代码查找到所有的tag,但是不会返回字符串节点:
for tag in soup.find_all(True):
print(tag.name)- 1
- 2
运行结果:
2)attrs参数
我们可以通过 find_all() 方法的 attrs 参数定义一个字典参数来搜索包含特殊属性的tag。
print(soup.find_all(attrs={"class":"title"}))
#[<p class="title" name="blog"><b>My Blogb>p>]- 1
- 2
3)recursive参数
调用tag的 find_all() 方法时,Beautiful Soup会检索当前tag的所有子孙节点,如果只想搜索tag的直接子节点,可以使用参数 recursive=False。
4)text参数
通过 text 参数可以搜搜文档中的字符串内容,与 name 参数的可选值一样, text 参数接受字符串 , 正则表达式 , 列表, True。
print(soup.find_all(text="Python3网络爬虫(三):urllib.error异常"))
#['Python3网络爬虫(三):urllib.error异常']- 1
- 2
5)limit参数
find_all() 方法返回全部的搜索结构,如果文档树很大那么搜索会很慢.如果我们不需要全部结果,可以使用 limit 参数限制返回结果的数量.效果与SQL中的limit关键字类似,当搜索到的结果数量达到 limit 的限制时,就停止搜索返回结果。
文档树中有3个tag符合搜索条件,但结果只返回了2个,因为我们限制了返回数量:
print(soup.find_all("a", limit=2))
#[<a class="sister" href="http://blog.csdn.net/c406495762/article/details/58716886" id="link1">Python3网络爬虫(一):利用urllib进行简单的网页抓取a>, <a class="sister" href="http://blog.csdn.net/c406495762/article/details/59095864" id="link2">Python3网络爬虫(二):利用urllib.urlopen发送数据a>]- 1
- 2
- 3
6)kwargs参数
如果传入 class 参数,Beautiful Soup 会搜索每个 class 属性为 title 的 tag 。kwargs 接收字符串,正则表达式
print(soup.find_all(class_="title"))
#[<p class="title" name="blog"><b>My Blogb>p>]- 1
- 2
4.小说内容爬取
掌握以上内容就可以进行本次实战练习了
a)单章小说内容爬取
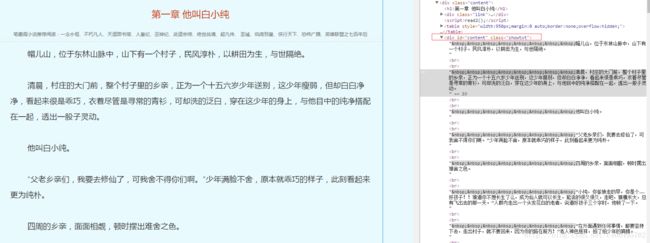
打开《一念永恒》小说的第一章,进行审查元素分析。
URL:http://www.biqukan.com/1_1094/5403177.html
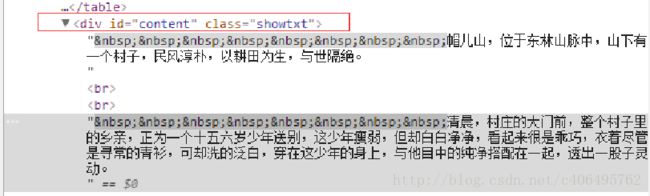
由审查结果可知,文章的内容存放在id为content,class为showtxt的div标签中:
局部放大:
因此我们,可以使用如下方法将本章小说内容爬取下来:
# -*- coding:UTF-8 -*-
from urllib import request
from bs4 import BeautifulSoup
if __name__ == "__main__": download_url = 'http://www.biqukan.com/1_1094/5403177.html' head = {} head['User-Agent'] = 'Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19' download_req = request.Request(url = download_url, headers = head) download_response = request.urlopen(download_req) download_html = download_response.read().decode('gbk','ignore') soup_texts = BeautifulSoup(download_html, 'lxml') texts = soup_texts.find_all(id = 'content', class_ = 'showtxt') soup_text = BeautifulSoup(str(texts), 'lxml') #将\xa0无法解码的字符删除 print(soup_text.div.text.replace('\xa0',''))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
运行结果:

可以看到,我们已经顺利爬取第一章内容,接下来就是如何爬取所有章的内容,爬取之前需要知道每个章节的地址。因此,我们需要审查《一念永恒》小说目录页的内容。
b)各章小说链接爬取
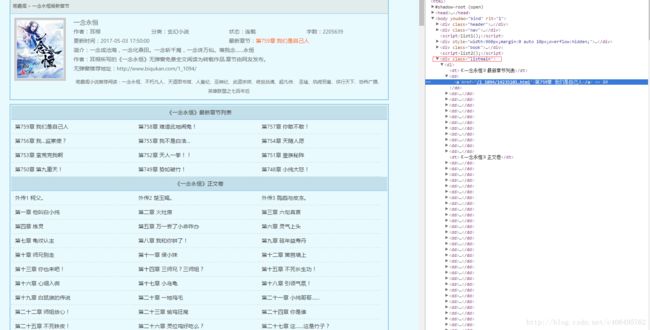
URL:http://www.biqukan.com/1_1094/
由审查结果可知,小说每章的链接放在了class为listmain的div标签中。链接具体位置放在html->body->div->dd->dl->a的href属性中,例如下图的第759章的href属性为/1_1094/14235101.html,那么该章节的地址为:http://www.biqukan.com/1_1094/14235101.html
局部放大:

因此,我们可以使用如下方法获取正文所有章节的地址:
# -*- coding:UTF-8 -*-
from urllib import request
from bs4 import BeautifulSoup if __name__ == "__main__": target_url = 'http://www.biqukan.com/1_1094/' head = {} head['User-Agent'] = 'Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19' target_req = request.Request(url = target_url, headers = head) target_response = request.urlopen(target_req) target_html = target_response.read().decode('gbk','ignore') #创建BeautifulSoup对象 listmain_soup = BeautifulSoup(target_html,'lxml') #搜索文档树,找出div标签中class为listmain的所有子标签 chapters = listmain_soup.find_all('div',class_ = 'listmain') #使用查询结果再创建一个BeautifulSoup对象,对其继续进行解析 download_soup = BeautifulSoup(str(chapters), 'lxml') #开始记录内容标志位,只要正文卷下面的链接,最新章节列表链接剔除 begin_flag = False #遍历dl标签下所有子节点 for child in download_soup.dl.children: #滤除回车 if child != '\n': #找到《一念永恒》正文卷,使能标志位 if child.string == u"《一念永恒》正文卷": begin_flag = True #爬取链接 if begin_flag == True and child.a != None: download_url = "http://www.biqukan.com" + child.a.get('href') download_name = child.string print(download_name + " : " + download_url)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
运行结果:
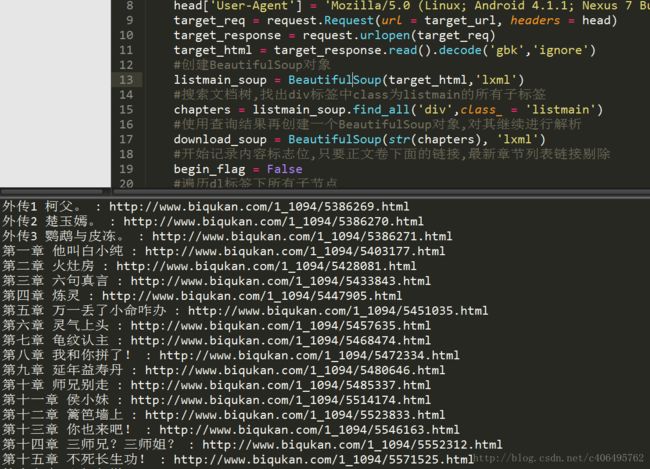
c)爬取所有章节内容,并保存到文件中
整合以上代码,并进行相应处理,编写如下代码:
# -*- coding:UTF-8 -*-
from urllib import request
from bs4 import BeautifulSoup
import re
import sys
if __name__ == "__main__": #创建txt文件 file = open('一念永恒.txt', 'w', encoding='utf-8') #一念永恒小说目录地址 target_url = 'http://www.biqukan.com/1_1094/' #User-Agent head = {} head['User-Agent'] = 'Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19' target_req = request.Request(url = target_url, headers = head) target_response = request.urlopen(target_req) target_html = target_response.read().decode('gbk','ignore') #创建BeautifulSoup对象 listmain_soup = BeautifulSoup(target_html,'lxml') #搜索文档树,找出div标签中class为listmain的所有子标签 chapters = listmain_soup.find_all('div',class_ = 'listmain') #使用查询结果再创建一个BeautifulSoup对象,对其继续进行解析 download_soup = BeautifulSoup(str(chapters), 'lxml') #计算章节个数 numbers = (len(download_soup.dl.contents) - 1) / 2 - 8 index = 1 #开始记录内容标志位,只要正文卷下面的链接,最新章节列表链接剔除 begin_flag = False #遍历dl标签下所有子节点 for child in download_soup.dl.children: #滤除回车 if child != '\n': #找到《一念永恒》正文卷,使能标志位 if child.string == u"《一念永恒》正文卷": begin_flag = True #爬取链接并下载链接内容 if begin_flag == True and child.a != None: download_url = "http://www.biqukan.com" + child.a.get('href') download_req = request.Request(url = download_url, headers = head) download_response = request.urlopen(download_req) download_html = download_response.read().decode('gbk','ignore') download_name = child.string soup_texts = BeautifulSoup(download_html, 'lxml') texts = soup_texts.find_all(id = 'content', class_ = 'showtxt') soup_text = BeautifulSoup(str(texts), 'lxml') write_flag = True file.write(download_name + '\n\n') #将爬取内容写入文件 for each in soup_text.div.text.replace('\xa0',''): if each == 'h': write_flag = False if write_flag == True and each != ' ': file.write(each) if write_flag == True and each == '\r': file.write('\n') file.write('\n\n') #打印爬取进度 sys.stdout.write("已下载:%.3f%%" % float(index/numbers) + '\r') sys.stdout.flush() index += 1 file.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
代码略显粗糙,运行效率不高,还有很多可以改进的地方,运行效果如下图所示:
最终生成的txt文件,如下图所示:

生成的txt文件,可以直接拷贝到手机中进行阅读,手机阅读软件可以解析这样排版的txt文件。