关联规则挖掘
关联规则挖掘是推荐技术的基础。
数据表示:
全项集:I={i1,i2,…im} (商品库)
交易t:记录一次交易中顾客购买的所有元素(t∈I)
交易数据集 T ={t1,t2,…,tn}
如:超市交易数据集:
t1:{面包,牛奶,果酱}
t2:{苹果,香蕉,鸡蛋,牛肉}
…
tn:{鸡蛋,牛肉,牛奶}
k 项集:有 k 个元素组成的集合。
关联规则:X→Y (这便是我们要挖掘出来的)
X,Y 是项集,X,Y∈I 且 X∩Y=ø
规则强度指标
支持度(Support):交易数据集中同时包含X和Y的交易占所有交易的比例。
对关联规则普遍性的衡量。
support=(XUY).countn
置信度(Confidence):交易数据集中同时包含X和Y的交易占所有包含 X 的交易的比例。
对关联规则准确性的衡量。
confidence=(XUY).countX.count
支持数(Support count):项集 X 的支持数(X.count)指交易数据集中所有包含 X 的交易的数量。
如果 A→B 的confidence 为100%,说明买A的用户一定会买B。那么 B→A的confidence 也可能很小,因为分子相同,分母不同。B可能是一个流行度非常高的商品。推荐系统需要新颖度,如果B是每个用户都必买的(比如矿泉水),那么就没有必要给用户推荐。推荐系统要挖掘用户不知道但感兴趣的东西。给用户惊喜。可以对商品做一个流行度的惩罚。
关联规则挖掘
找出满足给定的最小支持度(minimum support,minsup)和最小置信度(minimum confidence,minconf)的关联规则。
给定交易数据集,minsup and minconf ,结果规则集合是唯一的。
算法通常分两步:
1. 挖掘满足minsup 的所有项集(频繁项集,frequent itemset)
2. 利用frequent itemset 生成minconf 的关联规则。
Apriori 算法
input:交易数据集T;minsup
output: frequent itemset L
算法:
1. 找出频繁 1 项集L1。
2. 利用频繁 k 项集生成候选频繁 k+1 项集Ck+1。
3. 过滤Ck+1 中不满足的 minsup 要求的项集,等到Lk+1。
4. 循环步骤2-3,知道Lk+1 为空。
Apriori 算法过程实例
要求:最小支持数为 2
交易数据集T
| transaction | itemts |
|---|---|
| T1 | I1 , I2 , I5 |
| T2 | I2 , I4 |
| T3 | I2 , I3 |
| T4 | I1 , I2 , I4 |
| T5 | I1 , I3 |
| T6 | I2 , I3 |
| T7 | I1 , I3 |
| T8 | I1 , I2 , I3 , I5 |
| T9 | I1 , I2 , I3 |
扫描T,对每个候选集计数
C1
| 项集 | 支持数 |
|---|---|
| {I1} | 6 |
| {I2} | 7 |
| {I3} | 6 |
| {I4} | 2 |
| {I5} | 2 |
过滤不满足minsup 要求的候选集得到L1
L1
| 项集 | 支持数 |
|---|---|
| {I1} | 6 |
| {I2} | 7 |
| {I3} | 6 |
| {I4} | 2 |
| {I5} | 2 |
有L1 产生候选集C2
C2
| 候选项集 |
|---|
| {I1,I2} |
| {I1,I3} |
| {I1,I4} |
| {I1,I5} |
| {I2,I3} |
| {I2,I4} |
| {I2,I5} |
| {I3,I4} |
| {I3,I5} |
| {I4,I5} |
注意对项集进行排序,尽量让左边项相同。
扫描T,对每个候选集计数(注意:每次在计数时需要在原始交易数据集中扫描,很耗性能)
C2
| 项集 | 数 |
|---|---|
| {I1,I2} | 4 |
| {I1,I3} | 4 |
| {I1,I4} | 1 |
| {I1,I5} | 2 |
| {I2,I3} | 4 |
| {I2,I4} | 2 |
| {I2,I5} | 2 |
| {I3,I4} | 0 |
| {I3,I5} | 1 |
| {I4,I5} | 0 |
过滤不满足minsup 的候选集
L2
| 项 | 数 |
|---|---|
| {I1,I2} | 4 |
| {I1,I3} | 4 |
| {I1,I5} | 2 |
| {I2,I3} | 4 |
| {I2,I4} | 2 |
| {I2,I5} | 2 |
由L2产生候选集C3
| 候选项集 |
|---|
| I1,I2,I3 |
| I1,I3,I5 |
注意:
1. 在链接时,我们只需链接那些只有最后一项不同的项(理由和剪枝一样)。
2. 这里用了剪枝。
在C3 中每一项的所有两两组合都应该在L2中存在,如果不在那么他可定不满足最小支持度,所在在这里做剪枝。减少后边在统计支持数时,对交易数据集扫描次数。
扫描T,对每个候选集计数
C3
| 项集 | 支持数 |
|---|---|
| I1,I2,I3 | 2 |
| I1,I3,I5 | 2 |
过滤不满足minsup要求的候选集
L3
| 项集 | 支持数 |
|---|---|
| I1,I2,I3 | 2 |
| I1,I3,I5 | 2 |
由于L3,生成C4
剪枝后C4为null,得到最终 frequest itemset 是 L1+L2+L3
算法代码

候选集生成代码

关联规则生成
得到频繁项集后,再生成关联规则
方法:对一个频繁项集X,设A为X的一个非空子集,B=X-A,则A→B就是一条关联规则,如果其满足最小置信度条件。
support(A→B)=support(A∪B)=support(X)
confidenct(A→B)=support(A∪B)/support(A)
Apriori 算法缺点:
1. 需要生成大量的候选 ( 耗内存 )
2. 需要频繁扫描交易数据集 (耗性能)
FP-Growth 算法
频繁模式增长(Frequent-Pattern Growth)
是对Priori 算法的一种优化。优化了Apriori 的两个缺点。
步骤:
1. 从交易数据集构造FP树 (精简表示了交易数据集的信息)
2. 从FP树挖掘频繁模式
1. 生成条件模式库
2. 产生条件 FP 树
FP-Tree 生成
最小支持数为 3

扫描交易数据集,得到频繁1项集(包含了过滤不满minsup 项)红框中的数据(注意已经排序降序)。
安装L1 中顺序对所有交易中项排序(降序),同时去掉非频繁项(L1不包括的项)就是(ordered)frequent items 列。
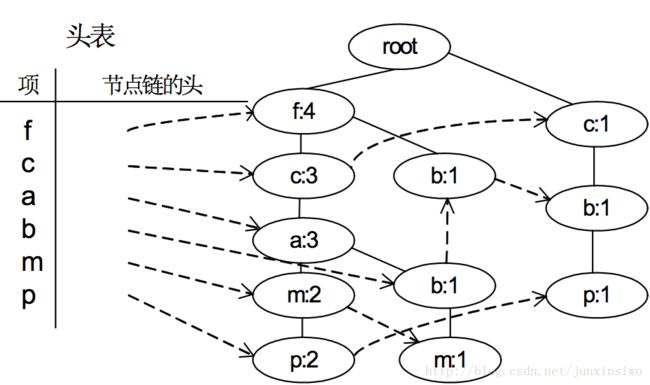
构造FP-Tree

注意:根节点为null
将(ordered)frequent items,从根节点依次插入树中,如果按照frequant Items 项的顺序插入时,树中以后此节点,那么加 1.
我们经常需要统计FP-Tree中 p 一共多少个节点。我们需要将树遍历一边才知道。这样是很大浪费。于是我们要建立一个索引(头表)
如图:头表将 L1 所有项在PF-Tree中串起来。便于查找。