rocketmq-事务消息
更多请移步我的博客
前言
之前有转载过一篇关于分布式事务最终一致的MQ实现的文章,当时也是碰到了分布式事务的情形,最后按照文章的思路利用rmq实现了数据的最终一致。不太清楚分布式事务的,可以先看下这边文章了解下。
PS:本篇默认你已经了解rmq的一些基础并看过部分源代码,建议在看该篇时,先看下官方的文档RocketMQ事务消息。
牵涉到的分布式的话题一般都会提到CAP,从知乎上打捞来一份比较好解释。
P 意指分区容忍性。 所谓分区指的是网络分区的意思。详细一点解释,比如你有A B两台服务器,它们之间是有通信的,突然,不知道为什么,它们之间的网络链接断掉了。
好了,那么现在本来AB在同一个网络现在发生了网络分区,变成了A所在的A网络和B所在的B网络。所谓的分区容忍性,就是说一个数据服务的多台服务器在发生了上述情况的时候,
依然能继续提供服务。所以显而易见的,P是大前提,如果P发生了,咱们的数据服务直接不服务了,还谈个毛的可用性和一致性呢。因此CAP要解释成,当P发生的时候,A和C只能而选一。
举个简单的例子,A服务器B服务器同步数据,现在A B之间网络断掉了,那么现在发来A一个写入请求,但是B却没有相关的请求,显然,如果A不写,保持一致性,那么我们就失去了A的服务,
但是如果A写了,跟B的数据就不一致了,我们自然就丧失了一致性。这里设计就涉及到架构师的选择了。注意这里的一致性是强一致性,意思是AB的数据时刻都是同步的,
如果我们放弃了强一致性,不代表我们的数据就是一定是不一致的了,我们可以让A先写入本地,等到通信恢复了再同步给B,这就是所谓的最终一致性,长远的看我们的数据还是一致的,
我们只是在某一个时间窗口里数据不一致罢了。如果这个时间窗口小过了用户逻辑处理的时间。那么其实对于用户来说根本毛都感觉不到。
最终一致性有个很有意思的协议叫gossip就跟传八卦一个意思,我就把我收到里信息里我本地没有的部分加到我本地,再把这个信息发出去,那么长远的看,网络时好时坏,
但是最终所有人都会有所有的信息。因此我们还是能够保证数据的最终一致性的。综上,CAP应该描述成,当发生网络分区的时候,如果我们要继续服务,那么强一致性和可用性只能2选1。
事务消息之前的实现
rmq不提供事务消息之前,通过“本地事务存根+rmq消息语义”来实现事务的最终一致性。
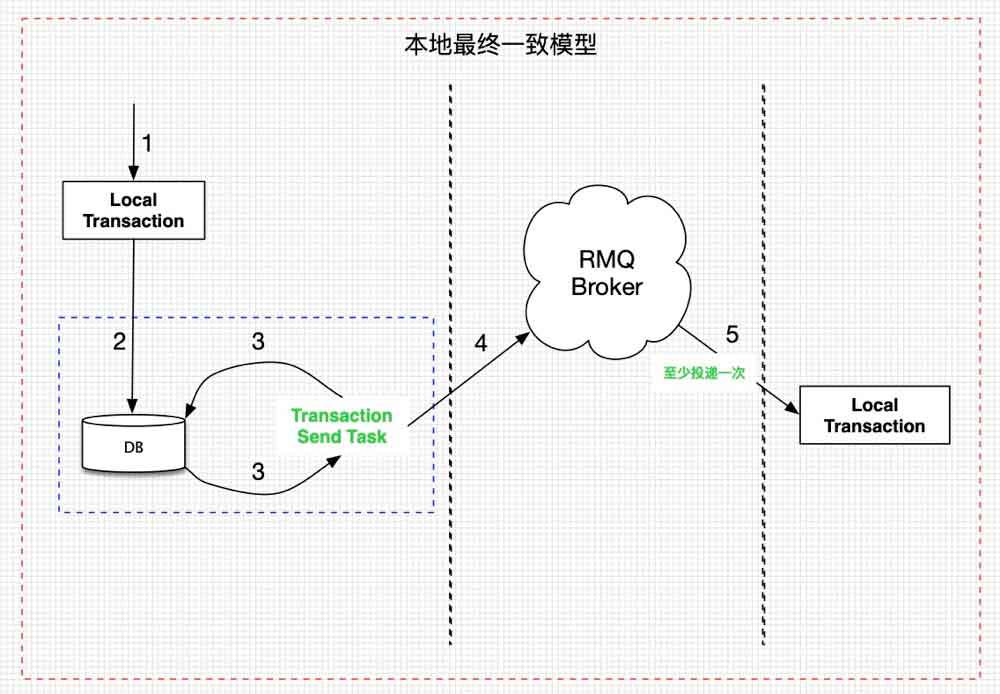
如上图,其实就是每个涉及到分布式事务的应用自己要有一张表来存储需要发送的消息,保证消息一定可以在本地事务完成后可以被发送到broker端。然后依赖“至少消费一次”的rmq语义来确保消息的投递,当然,消费端需要做幂等设计。
这么做除了各个业务段冗余一张表和一个兜底任务外,也无不妥。
rmq实现
事务消息的主要目标:确保本地事务执行完成后,一定会有通知到broker端。要达成这个目标,broker就需要知道每个在执行的事务,并且能在事务超时未发送结束消息时主动去问询事务执行的情况,核对完事务执行情况后再决定是否将事务完成消息推送给consumer。那rmq怎么收集执行的本地事务呢?这个当然需要事务本身在开启前进行上报。简单来讲事务消息就是要实现预约-履约-回查的场景。
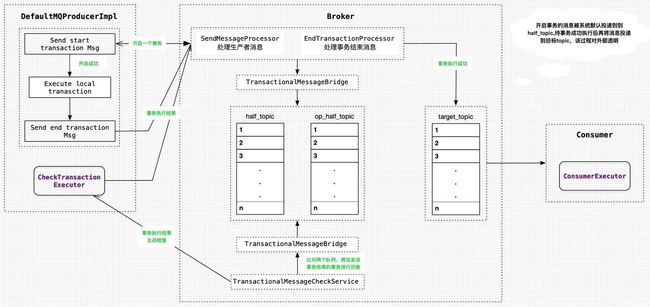
rmq事务消息围绕着两个topic展开RMQ_SYS_TRANS_HALF_TOPIC(half_topic)和RMQ_SYS_TRANS_OP_HALF_TOPIC(op_half_topic)。
`RMQ_SYS_TRANS_HALF_TOPIC`用来记录一个事务;
`RMQ_SYS_TRANS_OP_HALF_TOPIC`用来记录事务的执行状态。
这两个topic均为rmq的系统topic。
结合上图,描述下事务消息的一般流程:
-
发送开启事务消息(half消息)。
-
服务端响应消息响应写入结果。该步骤中会默认将目标topic和queueId进行替换,源topic和queueId当作属性值记到消息体中,half消息对生产和消费方均不可见。
-
根据发送结果执行本地事务,并发送(异步发送)本地事务执行的状态。
-
根据本地事务状态执行Commit或者Rollback。如果是Commit,就取出half消息,新建消息,并拷贝half消息的内容,同时把topic和queueId设置为half消息属性值中的topic和queueId,即:还原源消息,然后将新建的消息进行存储并在
op_half_topic创建操作记录,此时,消费方可以看到并消费事务消息。
PS:改变消息topic是rmq的常用方法,延时消息也是靠这种方式实现。
Producer
rmq在生产Client中使用模版消息封装了事务开启消息及实务完结消息的发送,开发者只需要实现自己本地事务和定义事务消息数据结构即可(DefaultMQProducerImpl#sendMessageInTransaction)。
事务消息存在三种状态:
public enum LocalTransactionState {
/**
* 本地事务执行成功
*/
COMMIT_MESSAGE,
/**
* 本地事务回滚
*/
ROLLBACK_MESSAGE,
/**
* 本地事务状态未知
* 该种状态下,broker会按照配置来检查事务的执行状态
*/
UNKNOW,
}
至于状态对应的场景,自己撸下代码吧,比较简单。
Broker
Broker端对Producer事务响应的处理代码在EndTransactionProcessor中,逻辑也比较简单。
OperationResult result = new OperationResult();
if (MessageSysFlag.TRANSACTION_COMMIT_TYPE == requestHeader.getCommitOrRollback()) {
// 查询half消息
result = this.brokerController.getTransactionalMessageService().commitMessage(requestHeader);
if (result.getResponseCode() == ResponseCode.SUCCESS) {
// 检查消息与生产方提交的消息信息是否一致
RemotingCommand res = checkPrepareMessage(result.getPrepareMessage(), requestHeader);
if (res.getCode() == ResponseCode.SUCCESS) {
// 制作新的事务消息,将half消息拷贝到新建的消息(topic等信息写成源信息)
MessageExtBrokerInner msgInner = endMessageTransaction(result.getPrepareMessage());
// 消息投递到源目标topic
RemotingCommand sendResult = sendFinalMessage(msgInner);
if (sendResult.getCode() == ResponseCode.SUCCESS) {
// 创建删除half消息的操作消息
this.brokerController.getTransactionalMessageService().deletePrepareMessage(result.getPrepareMessage());
}
return sendResult;
}
return res;
}
} else if (MessageSysFlag.TRANSACTION_ROLLBACK_TYPE == requestHeader.getCommitOrRollback()) {
// 查询half消息
result = this.brokerController.getTransactionalMessageService().rollbackMessage(requestHeader);
if (result.getResponseCode() == ResponseCode.SUCCESS) {
RemotingCommand res = checkPrepareMessage(result.getPrepareMessage(), requestHeader);
if (res.getCode() == ResponseCode.SUCCESS) {
// 创建删除half消息的操作消息
this.brokerController.getTransactionalMessageService().deletePrepareMessage(result.getPrepareMessage());
}
return res;
}
}
不管事务结束消息成功与否,总会记录一条操作消息(RMQ_SYS_TRANS_OP_HALF_TOPIC(op_half_topic)),这个topic究竟有什么用呢?
我们知道rmq对文件是连续写随机读的,这样就意味着我们不可能想操作数据库那样可以update/delete一条记录,所以rmq在处理事务消息的消息补偿-回查逻辑时就利用RMQ_SYS_TRANS_HALF_TOPIC(half_topic)和RMQ_SYS_TRANS_OP_HALF_TOPIC(op_half_topic)这两个topic来判断哪些消息处理完成了,哪些消息需要发起回查。
在broker启动时,会创建一个任务(消费者)来定时消费这两个topic,具体消费代码在TransactionalMessageServiceImpl#check()中。
String topic = MixAll.RMQ_SYS_TRANS_HALF_TOPIC;
// 获取半消息队列,只有1个
Set<MessageQueue> msgQueues = transactionalMessageBridge.fetchMessageQueues(topic);
for (MessageQueue messageQueue : msgQueues) {
long startTime = System.currentTimeMillis();
// 获取半消息队列对应的操作记录队列
MessageQueue opQueue = getOpQueue(messageQueue);
// 获取两个队列的消费进度
long halfOffset = transactionalMessageBridge.fetchConsumeOffset(messageQueue);
long opOffset = transactionalMessageBridge.fetchConsumeOffset(opQueue);
List<Long> doneOpOffset = new ArrayList<>();
HashMap<Long, Long> removeMap = new HashMap<>();
// 从操作队列中取出32个
// 如果操作操作记录中的halfoffset比消费进度还小,表示该消息已经处理(removeMap),否则表示该消息需要在本次处理完成(doneOpOffset)
PullResult pullResult = fillOpRemoveMap(removeMap, opQueue, opOffset, halfOffset, doneOpOffset);
// single thread
int getMessageNullCount = 1;
long newOffset = halfOffset;
long i = halfOffset;
while (true) {
// 超过一次检查的耗时,结束本次检查,等待下次调度
if (System.currentTimeMillis() - startTime > MAX_PROCESS_TIME_LIMIT) {
break;
}
if (removeMap.containsKey(i)) {
// 如果消息已经被处理过,跳过进行下一个
removeMap.remove(i);
} else {
// 获取半消息
GetResult getResult = getHalfMsg(messageQueue, i);
MessageExt msgExt = getResult.getMsg();
if (msgExt == null) {
// 如果半消息获取为null次数超过 MAX_RETRY_COUNT_WHEN_HALF_NULL=1,终止本次检查
if (getMessageNullCount++ > MAX_RETRY_COUNT_WHEN_HALF_NULL) {
break;
}
// 如果没有拉到新消息,终止本次检查
if (getResult.getPullResult().getPullStatus() == PullStatus.NO_NEW_MSG) {
break;
} else {
// 没有明确的失败原因,重试该偏移量的消息
i = getResult.getPullResult().getNextBeginOffset();
newOffset = i;
continue;
}
}
// 消息是否已经超过最大检查次数 || 消息所在的文件已经超过系统配置的保留时间(默认72小时)
if (needDiscard(msgExt, transactionCheckMax) || needSkip(msgExt)) {
listener.resolveDiscardMsg(msgExt);
newOffset = i + 1;
i++;
continue;
}
// 如果检查任务开始的时间小于消息存储的时间,不必再继续本次检查任务
// 可能事务尚未完成,不必多余检查
if (msgExt.getStoreTimestamp() >= startTime) {
log.debug("Fresh stored. the miss offset={}, check it later, store={}", i,
new Date(msgExt.getStoreTimestamp()));
break;
}
// 从时间差来看事务是否需要发起检查
long valueOfCurrentMinusBorn = System.currentTimeMillis() - msgExt.getBornTimestamp();
long checkImmunityTime = transactionTimeout;
// 消息本身是否设置了事务超时回查时间
String checkImmunityTimeStr = msgExt.getUserProperty(MessageConst.PROPERTY_CHECK_IMMUNITY_TIME_IN_SECONDS);
if (null != checkImmunityTimeStr) {
// 如果消息自己设置有固定的检查时间
checkImmunityTime = getImmunityTime(checkImmunityTimeStr, transactionTimeout);
if (valueOfCurrentMinusBorn < checkImmunityTime) {
// 如果事务消息尚未到检查时间,先检查该条消息的源消息是否被删除(removeMap)
// 如果没有被删除,就将消息重新投递到半队列,等待下次检查,并将消费进度向前推进
if (checkPrepareQueueOffset(removeMap, doneOpOffset, msgExt)) {
newOffset = i + 1;
i++;
continue;
}
}
} else {
// 说明消息为新消息,不必再继续本次检查任务
if ((0 <= valueOfCurrentMinusBorn) && (valueOfCurrentMinusBorn < checkImmunityTime)) {
break;
}
}
List<MessageExt> opMsg = pullResult.getMsgFoundList();
// valueOfCurrentMinusBorn <= -1 是什么场景时出现???
boolean isNeedCheck = (opMsg == null && valueOfCurrentMinusBorn > checkImmunityTime)
|| (opMsg != null && (opMsg.get(opMsg.size() - 1).getBornTimestamp() - startTime > transactionTimeout))
|| (valueOfCurrentMinusBorn <= -1);
if (isNeedCheck) {
// 将消息重新投递到half队列
if (!putBackHalfMsgQueue(msgExt, i)) {
continue;
}
// 异步向客户端发起检查命令
listener.resolveHalfMsg(msgExt);
} else {
// 取出操作队列数据,继续检查
pullResult = fillOpRemoveMap(removeMap, opQueue, pullResult.getNextBeginOffset(), halfOffset, doneOpOffset);
continue;
}
}
newOffset = i + 1;
// 将消费进度向前推进
i++;
}
// 计算并更新队列的消费进度
if (newOffset != halfOffset) {
transactionalMessageBridge.updateConsumeOffset(messageQueue, newOffset);
}
long newOpOffset = calculateOpOffset(doneOpOffset, opOffset);
if (newOpOffset != opOffset) {
transactionalMessageBridge.updateConsumeOffset(opQueue, newOpOffset);
}
}
上面这段代码便是补偿逻辑的核心了,看懂这块代码,整个事务消息的处理也就基本明白的差不多了。
总结
在看这段代码时我有一个疑问:
- 为什么消息回查时,要重新提交一条消息到half队列呢?
自己思考的答案:
- 因为rmq顺序写,同时消费进度需要向前推进,不能够因为某个消息有问题影响消息的处理(单线程处理),基于rmq的底层实现和特性,提交一条新的消息除了占用一些存储空间外,处理问题的复杂度和时间消耗均能得到保证。
小生不才,以上如有描述有误的地方还望各位不吝赐教 !_!
源代码版本:release-4.5.0 贴出的源代码会有所删减
参考
CAP
seata
消息事务样例