Deep Learning with Pytorch 中文简明笔记 第五章 The mechanics of learning
Deep Learning with Pytorch 中文简明笔记 第五章 The mechanics of learning
Pytorch作为深度学习框架的后起之秀,凭借其简单的API和简洁的文档,收到了越来越多人的关注和喜爱。本文主要总结了 Deep Learning with Pytorch 一书第五章[The mechanics of learning]的主要内容,并加以简单明了的解释,作为自己的学习记录,也供大家学习和参考。
文章目录
- Deep Learning with Pytorch 中文简明笔记 第五章 The mechanics of learning
- 主要内容
- 1. 一个永恒的建模课程
- 2. 学习就是参数估计
- 3. 我们所需要的是更小的误差
- 4. 沿着梯度下降
- 5. Pytorch的自动求导和反向传播
- 5.1 自动计算梯度
- 5.2 优化器
- 5.3 训练和验证
- 5.4 梯度更新的开关
主要内容
- 理解算法如何从数据中学习
- 理解使用微分和梯度下降来做参数估计
- 走通简单学习算法的过程
- 了解Pytorch如何自动求导
1. 一个永恒的建模课程
主要讲开普勒第一第二定律,略。
2. 学习就是参数估计
以温度转换为例,生成一些数据
# In[2]:
t_c = [0.5, 14.0, 15.0, 28.0, 11.0, 8.0, 3.0, -4.0, 6.0, 13.0, 21.0]
t_u = [35.7, 55.9, 58.2, 81.9, 56.3, 48.9, 33.9, 21.8, 48.4, 60.4, 68.4]
t_c = torch.tensor(t_c)
t_u = torch.tensor(t_u)
将数据可视化

直接尝试线性模型 t c = w ∗ t u + b t_c=w* t_u+b tc=w∗tu+b
此时已经有了模型、=和数据,我们需要估计模型的参数使得模型的输出和真实值之间的误差越小越好,但是还需要设定衡量误差的指标,这个指标称作loss function.
3. 我们所需要的是更小的误差
刚才说到,损失函数就是用来衡量预测值和真实值之间的差距,越小越好。常见的有均方误差和绝对误差,分别为 ( t p – t c ) 2 (t_p – t_c)^2 (tp–tc)2和 ∣ t p – t c ∣ |t_p – t_c| ∣tp–tc∣。
首先设计模型函数
# In[3]:
def model(t_u, w, b):
return w*t_u+b
定义损失函数
# In[4]:
def loss_fn(t_p, t_c):
squared_diffs = (t_p - t_c)**2
return squared_diffs.mean()
传入数据
# In[5]:
w = torch.ones(())
b = torch.zeros(())
t_p = model(t_u, w, b)
t_p
# Out[5]:
tensor([35.7000, 55.9000, 58.2000, 81.9000, 56.3000, 48.9000, 33.9000, 21.8000, 48.4000, 60.4000, 68.4000])
计算损失
# In[6]:
loss = loss_fn(t_p, t_c)
loss
# Out[6]:
tensor(1763.8846)
4. 沿着梯度下降
这里书中为了引入,先说了使用delta近似微分的思想,这里略过,直接用求偏导的做法。
手动计算损失函数微分
# In[11]:
def dloss_fn(t_p, t_c):
dsq_diffs=2* (t_p - t_c) / t_p.size(0)
return dsq_diffs
# In[3]:
def model(t_u, w, b):
return w*t_u+b
# In[12]:
def dmodel_dw(t_u, w, b):
return t_u
# In[13]:
def dmodel_db(t_u, w, b):
return 1.0
# In[14]:
def grad_fn(t_u, t_c, t_p, w, b):
dloss_dtp = dloss_fn(t_p, t_c)
dloss_dw = dloss_dtp * dmodel_dw(t_u, w, b)
dloss_db = dloss_dtp * dmodel_db(t_u, w, b)
return torch.stack([dloss_dw.sum(), dloss_db.sum()])
定义训练的循环函数
# In[15]:
def training_loop(n_epochs, learning_rate, params, t_u, t_c):
for epoch in range(1, n_epochs + 1):
w, b = params
t_p = model(t_u, w, b)
loss = loss_fn(t_p, t_c)
grad = grad_fn(t_u, t_c, t_p, w, b)
params = params - learning_rate * grad
print('Epoch %d, Loss %f' % (epoch, float(loss)))
return params
训练
# In[17]:
training_loop( n_epochs = 100, learning_rate = 1e-2, params = torch.tensor([1.0, 0.0]), t_u = t_u, t_c = t_c)
可以根据需要调整训练的参数
5. Pytorch的自动求导和反向传播
5.1 自动计算梯度
Pytorch包含一个非常重要的组件,自动求导autograd
下面是我们之前定义的模型和损失函数
# In[3]:
def model(t_u, w, b):
return w*t_u+b
# In[4]:
def loss_fn(t_p, t_c):
squared_diffs = (t_p - t_c)**2
return squared_diffs.mean()
使用Pytorch的Tensor来定义参数
# In[5]:
params = torch.tensor([1.0, 0.0], requires_grad=True)
注意函数中的requires_grad = True,这告诉Pytorch将追踪整个参数参与的操作,方便求导
通常,所有的Pytorch中的Tensor均有一个属性grad,一般情况下为None
# In[6]:
params.grad is None
# Out[6]:
True
由于我们已经设置了requires_grad为True,所以可以调用backward()方法来计算导数
# In[7]:
loss = loss_fn(model(t_u, *params), t_c)
loss.backward()
params.grad
# Out[7]:
tensor([4517.2969, 82.6000])
当将参数传入损失函数计算的函数中时,Pytorch创建了自动求导图(计算图),当调用backward()方法时,Pytorch自动求导器会沿着计算图的边反向计算导数(梯度)
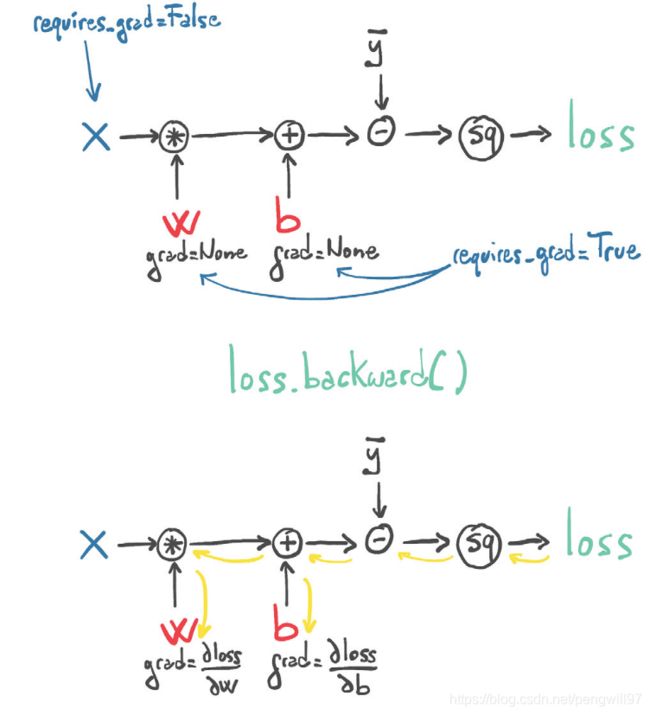
值得注意的是,若反复调用backward()方法,会将梯度累加,所以在执行新的一次backward()时,应该将现有的梯度清零。清零可以使用梯度的zero_()方法。
# In[8]:
if params.grad is not None:
params.grad.zero_()
提供这样手动清除梯度的方式,让Pytorch有了更多的灵活性。
下面将Pytorch的自动求导融合进训练过程。
# In[9]:
def training_loop(n_epochs, learning_rate, params, t_u, t_c):
for epoch in range(1, n_epochs + 1):
if params.grad is not None:
params.grad.zero_()
t_p = model(t_u, *params)
loss = loss_fn(t_p, t_c)
loss.backward()
with torch.no_grad():
params -= learning_rate * params.grad
if epoch % 500 == 0:
print('Epoch %d, Loss %f' % (epoch, float(loss)))
return params
注意到with torch.no_grad(),其含义为在代码块中的所有操作均不计算梯度,一方面可以加速,另一方面可以防止在更新的参数的时候也计算梯度。
5.2 优化器
之前的模型中,使用的是朴素的梯度下降,下面将介绍Pytroch的优化器。
# In[5]:
import torch.optim as optim
dir(optim)
# Out[5]:
['ASGD',
'Adadelta',
'Adagrad',
'Adam',
'Adamax',
'LBFGS',
'Optimizer',
'RMSprop',
'Rprop',
'SGD',
'SparseAdam',
... ]
优化器的构造函数需要传入待优化的参数(即Tensor,通常将requires_grad设为True),所有的参数在训练的过程中传入优化器,并且访问他们的grad属性同时更新参数。

每一个优化器都会用到两个方法,一个是zero_grad(),另一个是step()。zero_grad()用于将参数的grad清零,而step()则根据优化器的策略更新参数值。
下面创建一个SGD优化器
# In[6]:
params = torch.tensor([1.0, 0.0], requires_grad=True)
learning_rate = 1e-5
optimizer = optim.SGD([params], lr=learning_rate)
在使用step()之前,同样应该使用zero_grad()对参数的梯度进行清零。
# In[8]:
params = torch.tensor([1.0, 0.0], requires_grad=True)
learning_rate = 1e-2
optimizer = optim.SGD([params], lr=learning_rate)
t_p = model(t_un, *params)
loss = loss_fn(t_p, t_c)
optimizer.zero_grad() l
oss.backward()
optimizer.step()
params
完整的代码为
# In[9]:
def training_loop(n_epochs, optimizer, params, t_u, t_c):
for epoch in range(1, n_epochs + 1):
t_p = model(t_u, *params)
loss = loss_fn(t_p, t_c)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 500 == 0: print('Epoch %d, Loss %f' % (epoch, float(loss)))
return params
# In[10]:
params = torch.tensor([1.0, 0.0], requires_grad=True)
learning_rate = 1e-2
optimizer = optim.SGD([params], lr=learning_rate)
training_loop( n_epochs = 5000, optimizer = optimizer, params = params, t_u = t_un, t_c = t_c)
5.3 训练和验证
数据集的分割,使用torch.randperm来产生随机的全排列
# In[12]:
n_samples = t_u.shape[0]
n_val = int(0.2 * n_samples)
shuffled_indices = torch.randperm(n_samples)
train_indices = shuffled_indices[:-n_val]
val_indices = shuffled_indices[-n_val:]
train_indices, val_indices
# Out[12]:
(tensor([9, 6, 5, 8, 4, 7, 0, 1, 3]), tensor([ 2, 10]))
分别创建训练数据集和验证数据集
# In[13]:
train_t_u = t_u[train_indices]
train_t_c = t_c[train_indices]
val_t_u = t_u[val_indices]
val_t_c = t_c[val_indices]
train_t_un = 0.1 * train_t_u
val_t_un = 0.1 * val_t_u
分别在两个数据集上训练和验证
# In[14]:
def training_loop(n_epochs, optimizer, params, train_t_u, val_t_u, train_t_c, val_t_c):
for epoch in range(1, n_epochs + 1):
train_t_p = model(train_t_u, *params)
train_loss = loss_fn(train_t_p, train_t_c)
val_t_p = model(val_t_u, *params)
val_loss = loss_fn(val_t_p, val_t_c)
optimizer.zero_grad()
train_loss.backward()
optimizer.step()
if epoch <= 3 or epoch % 500 == 0:
print(f"Epoch {epoch}, Training loss {train_loss.item():.4f}," f" Validation loss {val_loss.item():.4f}"
return params
注意的是,我们仅仅在train_loss上使用backward(),没有在val_loss上使用backward(),所以在验证的时候的梯度并没有更新到参数上。更准确的说,train_loss和val_loss使用的同一套参数,但是却生成了两部分计算图。所以train的梯度不会更新到val上。
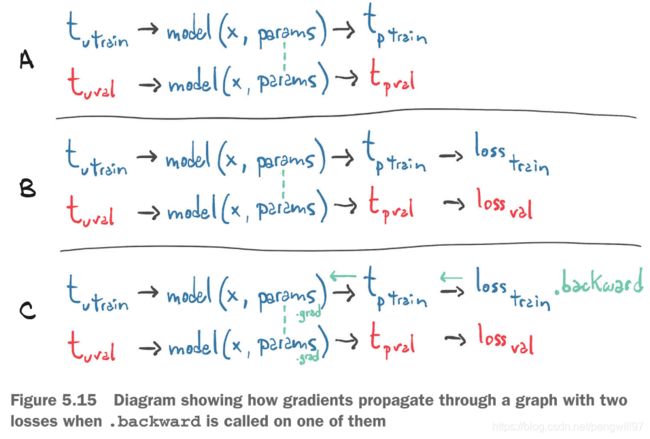
5.4 梯度更新的开关
之前说过使用torch.no_grad()可以控制代码块中的语句不更新梯度
# In[16]:
def training_loop(n_epochs, optimizer, params, train_t_u, val_t_u, train_t_c, val_t_c):
for epoch in range(1, n_epochs + 1):
train_t_p = model(train_t_u, *params)
train_loss = loss_fn(train_t_p, train_t_c)
with torch.no_grad():
val_t_p = model(val_t_u, *params)
val_loss = loss_fn(val_t_p, val_t_c)
assert val_loss.requires_grad == False
optimizer.zero_grad()
train_loss.backward()
optimizer.step()
或者使用torch.set_grad_enable()来控制是否更新梯度,传入一个bool变量作为控制变量即可。
In[17]:
def calc_forward(t_u, t_c, is_train):
with torch.set_grad_enabled(is_train):
t_p = model(t_u, *params)
loss = loss_fn(t_p, t_c)
return loss
这样就不用分别写train和validation了。