python编程练习:10000位的圆周率飞花令
一、目标
利用爬虫收集足够多的古诗词,筛选诗词中含有数字的句子后,再按照圆周率中的数字顺序对这些诗词进行排序。最后形成下图所示的统计结果:
二、步骤及代码
2.1 爬虫获取古诗词
import urllib.request
import urllib.parse
from lxml import etree
import random
import time
"""
爬取古诗词网
"""
# 可用的代理地址
proxy_lists = ["163.204.240.213:9999",
"117.69.200.74:9999",
"47.112.218.30:8000",
"121.226.188.148:9999",
"121.40.108.76:80",
"223.241.78.159:8010",
"219.147.157.98:443",
"117.69.200.167:9999"]
def url_open(url):
proxy_support = urllib.request.ProxyHandler({"http": random.choice(proxy_lists)})
opener_1 = urllib.request.build_opener(proxy_support)
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"}
req = urllib.request.Request(url, headers=headers)
response = opener_1.open(req)
page = response.read()
html = etree.HTML(page)
return html
def create_text(url, save_path):
current_html = url_open(url)
name = current_html.xpath('/html/body//div[@class="son1"]/h1') # 作品名
data_main = current_html.xpath('/html/body//div[@class="son2"]')[1].xpath('string(.)').strip()
data_main = data_main.replace(" ", "").replace("\t", "").replace("'", "").replace("\n", "").replace("\r", "")
p_dynasty = data_main.find("朝代:")
p_author = data_main.find("作者:")
dynasty = data_main[p_dynasty+3:p_author]
author = data_main[p_author+3:p_author+6].replace("\xa0", "")
p_start = data_main.find(author) + len(author)
p_end = data_main.find("精彩推荐")
with open(save_path, 'a+') as f_obj:
f_obj.writelines("{0}\n".format(name[0].text))
f_obj.writelines("{0}]\n".format(dynasty))
f_obj.writelines("{0}\n".format(author))
f_obj.writelines("{0}\n".format(data_main[p_start:p_end].replace("\xa0", "").replace("\ue78e", "")))
f_obj.writelines("\n")
if __name__ == "__main__":
page_start = 1
page_end = 77000
file_name = 'test.txt'
for i in range(page_start, page_end):
try:
url_1 = "http://www.haoshiwen.org/view.php?id=" + str(i)
create_text(url_1, file_name)
except Exception as e:
print("Error")
finally:
print("{0}/{1}".format(i, page_end))
time.sleep(0.15)
初学爬虫,异常处理和xpath用的很粗糙,见谅!运行程序后,爬取的古诗词保存在test.txt文件中,信息包括诗词名、朝代、作者、正文,板式如下所示:

删除部分元杂剧的部分,最终得到大约70000首古诗,其中少数由于爬取网页的html结构改变,造成了板式的异常,在此先不考虑,之后再剔除。
2.2 统计古诗词中含有数字的情况
import re
from itertools import compress
import pandas as pd
from collections import Counter
# 待寻找的汉字
search_char = ["零", "一", "二", "三", "四", "五", "六", "七", "八", "九"]
file_name = "test.txt"
def judge(in_article):
r = ':'
for i in in_article:
if i.find(search_char[0]) != -1:
r += '0'
if i.find(search_char[1]) != -1:
r += '1'
if i.find(search_char[2]) != -1:
r += '2'
if i.find(search_char[3]) != -1:
r += '3'
if i.find(search_char[4]) != -1:
r += '4'
if i.find(search_char[5]) != -1:
r += '5'
if i.find(search_char[6]) != -1:
r += '6'
if i.find(search_char[7]) != -1:
r += '7'
if i.find(search_char[8]) != -1:
r += '8'
if i.find(search_char[9]) != -1:
r += '9'
return r
# 读取文件
with open(file_name) as obj:
all = [i for i in obj.readlines()]
# 作品名
title = [all[i] for i in range(len(all)) if i % 5 == 0]
# 朝代
dynasty = [all[i] for i in range(len(all)) if i % 5 == 1]
# 作者
author = [all[i] for i in range(len(all)) if i % 5 == 2]
# 正文,去除正文中的英文字符等,并划分成句
article = [re.sub("[A-Za-z0-9\<\\n\>]", "", all[i]).split("。") for i in range(len(all)) if i % 5 == 3]
# 结果,含有数字则赋值为0~9,若无则赋值为-1
result = [judge(art) for art in article]
# 判断,是否包含汉字,true代表包含,false代表不包含
judge = [i != ':' for i in result]
# 筛选序列中的元素
filter_result = list(compress(result, judge))
filter_title = list(compress(title, judge))
filter_dynasty = list(compress(dynasty, judge))
filter_author = list(compress(author, judge))
filter_article = list(compress(article, judge))
# 存储到excel文件
out_xls = {"结果": filter_result,
"作品名": filter_title,
"朝代": filter_dynasty,
"作者": filter_author,
"正文": filter_article}
data = pd.DataFrame(out_xls)
data.to_excel("带有数字的古诗v2.xlsx", index=False)
# 统计各数字出现的次数
filter_result = [i[1:] for i in filter_result]
str_result = ''.join(filter_result)
word_counts = Counter(str_result[:])
top_10 = word_counts.most_common()
print(top_10)
将统计结果保存到带有数字的古诗v2.xlsx文件中,输出如下:
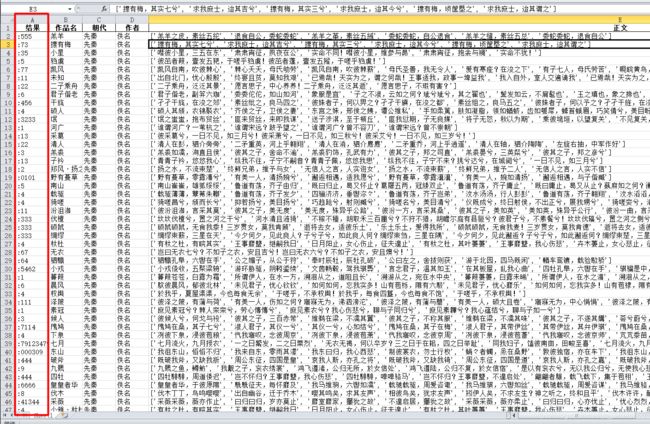
图中红框内为结果一栏,例如,:555表示诗句中汉字"五"出现的次数为3,:73表示诗句中含有汉字"七"和"三"各一次。
各汉字统计结果如下:
[(‘1’, 25621), (‘3’, 9228), (‘5’, 4770), (‘4’, 4195), (‘2’, 3688), (‘9’, 3575), (‘6’, 2226), (‘8’, 1761), (‘7’, 1383), (‘0’, 1072)]
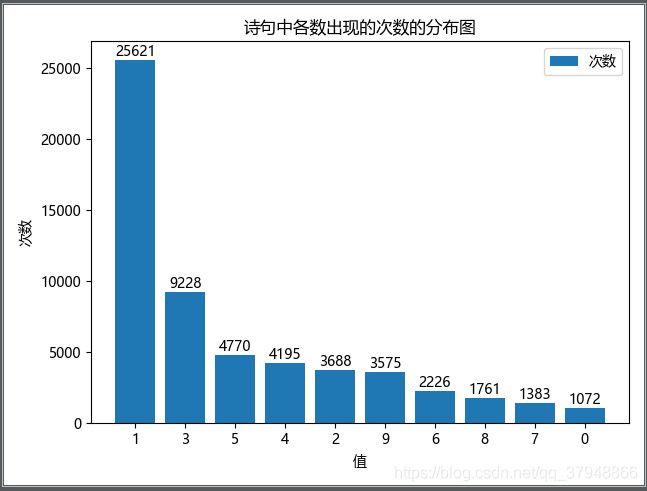
可以看出,各汉字出现次数按从小到大排序为:零<七<八<六<九<二<四<五<三<一
2.3 统计圆周率中各个数字出现的次数
from collections import Counter
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# 设置标签为负号可显示,坐标轴可显示中文
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# 读取存储圆周率位数的文本
file_name = "pi.txt"
with open(file_name) as obj:
pi_value = obj.read()
num_limit = 10000 # 待统计的圆周率位数限制
# 用collection类中的Counter类统计序列中各元素出现的次数,结果保存到top_10中
word_counts = Counter(pi_value[:num_limit])
top_10 = word_counts.most_common()
def draw_tar(turple_list, title="圆周率前{0}位各数出现的次数分布图"):
"""
:param turple_list: 由元组(数字,数字出现的次数)构成的列表
:param title: 柱状图的标题
:return:
"""
# x为值,y为值对应的次数
x = np.array([i[0] for i in turple_list])
y = np.array([i[1] for i in turple_list])
# 绘图
plt.bar(x, y, label="次数")
# 设置数据标签
for a, b in zip(x, y):
plt.text(a, b, b, ha="center", va="bottom", fontsize=10)
# 坐标轴、标题设置
plt.title(str.format(title, num_limit))
plt.xlabel("值")
plt.ylabel("次数")
plt.legend()
plt.show()
if __name__ == "__main__":
draw_tar(top_10)
结果如下图:
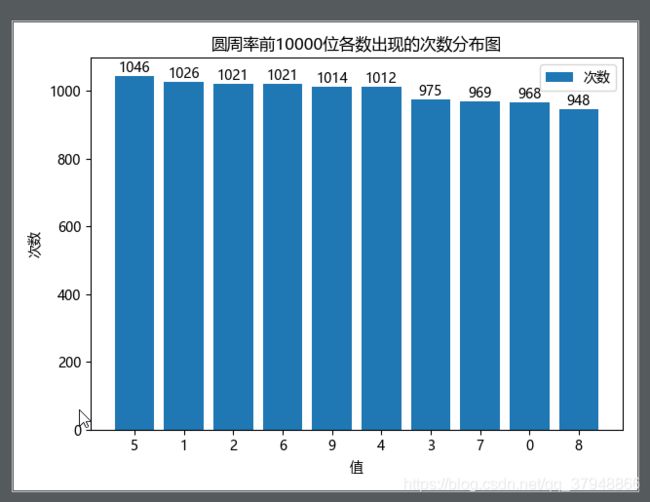
对应代码中top_10的值:
[(‘5’, 1046), (‘1’, 1026), (‘2’, 1021), (‘6’, 1021), (‘9’, 1014), (‘4’, 1012), (‘3’, 975), (‘7’, 969), (‘0’, 968), (‘8’, 948)]
2.4 分析可能性
由于飞花令规则中一首古诗只能出现一次,所以为了生成更长的飞花令需要确定一个优先级问题,例如《小明》含有数字的情况为:20,正文中有两句含有数字的古诗—— ‘二月初吉,载离寒暑’ 和 ‘念彼共人,涕零如雨’。由于全体诗句集中含有"零"的诗句最少,故将这首诗作为圆周率中的某一位零来使用。用程序解释如下:
def func(in_str):
# 按照数字的优先级,修改结果
if in_str.find('0') != -1:
return '0'
elif in_str.find('7') != -1:
return '7'
elif in_str.find('8') != -1:
return '8'
elif in_str.find('6') != -1:
return '6'
elif in_str.find('9') != -1:
return '9'
elif in_str.find('2') != -1:
return '2'
elif in_str.find('4') != -1:
return '4'
elif in_str.find('5') != -1:
return '5'
elif in_str.find('3') != -1:
return '3'
elif in_str.find('1') != -1:
return '1'
据上文中,圆周率10000位与数据集中各数字的统计结果对比,由于圆周率中8出现的次数最少为948,因此只要满足“数据集中每一个数字出现次数大于948”这一条件就可以初步认为具备实现10000位圆周率飞花令的条件。
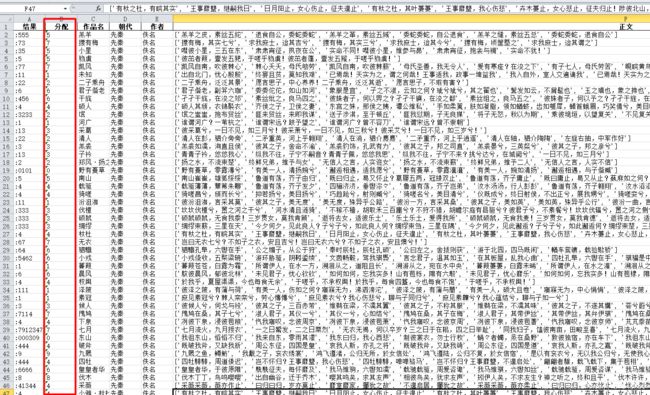
2.5 按数字使用优先级修改结果
按优先级对之前得到的带有数字的古诗v2.xlsx进行处理得到带有数字的古诗v3.xlsx,结果如下:
2.6 生成按照圆周率排序的数据集
import pandas as pd
# 读取存储圆周率位数的文本
file_name = "pi.txt"
with open(file_name) as obj:
pi_value = obj.read()
# 确定每一行对应的位置
file_3 = r"带有数字的古诗v3.xlsx"
pd_1 = pd.read_excel(file_3)
pd_2 = pd.DataFrame({'pi': list(pi_value)})
temp_1 = [str(i) for i in list(pd_1["分配"].values)] # 提取表格中"分配"一列作为一个列表
temp_2 = ['' for i in range(len(temp_1))]
for i, v in enumerate(pi_value):
for j, r in enumerate(temp_1): # 遍历“分配”列
if r == v and temp_2[j] == '':
temp_2[j] = i
break
xls_3 = pd.read_excel(file_3)
xls_3.insert(1, "位置", temp_2)
xls_3.to_excel("带有数字的古诗v4.xlsx", index=False)
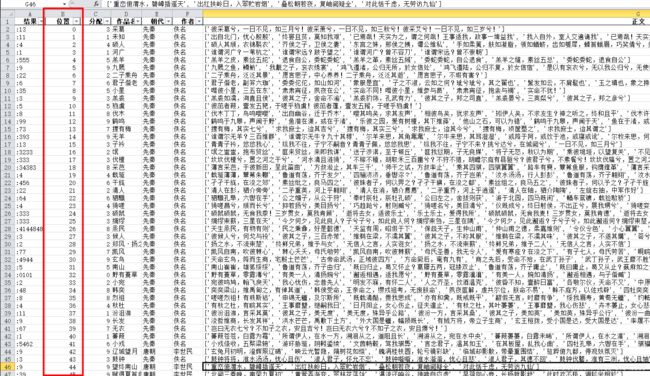
得到带有数字的古诗v4.xlsx
三、结果展示
视频展示见1~1000位圆周率飞花令