XGBOOST_航班延误预测
最近,想尝试一下利用机器学习进行航班的延误预测,一开始的倾向是使用GBDT算法,使用了在scikit-learn上的肿瘤数据作为初步模型测试,使用网格搜索后发现,其预测结果仅仅只有50%不到,还不如KNN——《机器学习之Knn算法》。
后来在网上看到了XGBOOST算法,于是常识了一波,准确率可以达到90%,比knn要强出5%以上,所以在模型的选择上,博主决定使用XGBOOST。
对于GBDT和XGBOOST的原理,以及各超参的控制机理,博主这边还只是初步尝试,后面会较深入的去琢磨一番,然后完善博客,但是工具的使用还是简单的,问题在于数据集。
一、航班数据集
1.1 搜集数据
国内的航班数据几乎没有,也没有免费的公开网站,而公司的数据几乎不可用,因为只有航线、航司、出发、到达、计划时间等,没有博主需要的实际时间、天气状况、航班号等。
为此博主花了一整天时间搜罗各大网站,终于发现了这个国外网站——stat-computing.org,貌似需要。可以查询到美国的航空公司航班准点率数据,博主选取的是2016年的。
此外,还有这位博主,提供的数据也被博主参考了进来——《通过使用 Python 创建机器学习模型来预测航班晚点情况》。
但是唯一遗憾就是缺少天气数据,经过不断的搜索,博主发现了一个美国气象局,可以查到2016年的历史天气数据——ATL亚特兰大国际机场天气状况
| 亚特兰大国际机场2016年1月部分数据 |
|---|
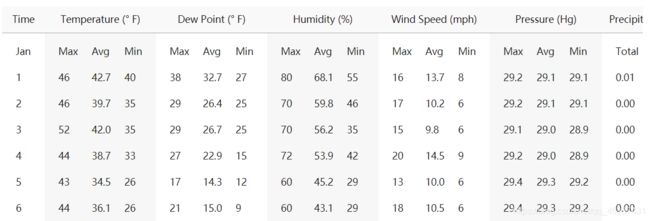 |
本想通过爬虫进行爬取数据,但实际情况不允许。不过博主也是讲table标签数据copy下来,然后利用python进行数据的整理与合并。
经过分析,博主个人认为风速和降水量,由于变化幅度大,可以作为影响航班的主要因素,隐藏只提取这两个因素作为天气指数。
1.2 天气数据处理和合并
由于是调研,选取的是美国大型航空公司——DL达美,并选取了五个机场:ATL(佐治亚州亚特兰大:哈茨菲尔德-杰克逊亚特兰大国际机场)、DTW(底特律韦恩县国际机场)、JFK(纽约:约翰·F·肯尼迪国际机场)、MSP(明尼苏达州明尼阿波利斯:明尼阿波利斯圣保罗国际机场)、SEA(华盛顿州:西雅图/塔科马国际机场)
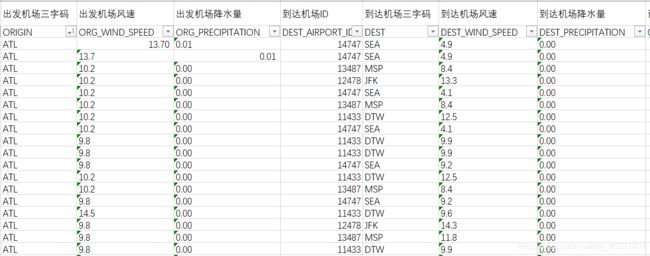
由两个文件,一个是USA_fightDataSet.xlsx,这个Excel文件记录的是起飞时间、机场、计划飞行时间、实际飞行实际、航班号等数据;另一个是由机场和月份组成的60个txt文件,里面是html的table标签数据。
博主要做的就是将table标签里的当天的天气情况,即风速和降水量,插入到表格相应的位置,代码如下:
## 获取天气数据的类方法
import pandas as pd
import numpy as np
np.set_printoptions(threshold=np.inf)
# 获取数据
def getData(url, airport, mon):
# 读取配置文件
table = pd.read_html(url);
# 数据行数
dayOfMonth = np.array(table[1])[1:, 0]
size = dayOfMonth.size
# 选取最后一个元素进行判断,因为爬取的数据有时候最后一个又从1号开始,这里进行判断排除处理
ele = dayOfMonth[size-1]
if ele == '1':
dayOfMonth = np.array(table[1])[1:size, 0]
wsp_data = np.array(table[5])[1:size, 1]
precipitation_data = table[7].values[1:size, 0]
else :
# 读取数据,这里将header删掉,取数据
# 日
dayOfMonth = np.array(table[1])[1:, 0]
# windSpeed的平均值
wsp_data = np.array(table[5])[1:, 1]
# 降水量
precipitation_data = table[7].values[1:, 0]
# 填充月份
size = dayOfMonth.size
month = np.array([mon for i in range(size)])
# 填充机场
airport = np.array([airport for i in range(size)])
# 输出结果
return np.vstack([month, dayOfMonth, airport, wsp_data, precipitation_data]).T
# 迭代合并数组,从2开始
def fibonacci(n, airport):
if n==2 :
url1 = "D:\\File\\航班预测\\天气数据\\"+airport+"\\table" + str(1) + ".txt"
url2 = "D:\\File\\航班预测\\天气数据\\"+airport+"\\table" + str(2) + ".txt"
return np.concatenate([getData(url1, airport, 1), getData(url2, airport, 2)])
else :
url = "D:\\File\\航班预测\\天气数据\\"+airport+"\\table" + str(n) + ".txt"
return np.concatenate([fibonacci(n-1, airport), getData(url, airport, n)])
# 将各机场数据拼接
def getWeatherData():
result1 = fibonacci(12, 'ATL')
result2 = fibonacci(12, 'DTW')
result3 = fibonacci(12, 'JFK')
result4 = fibonacci(12, 'MSP')
result5 = fibonacci(12, 'SEA')
return np.concatenate([result1, result2, result3, result4, result5])
##
## 调用上面的天气数据包,然后与USA_fightDataSet.xlsx表格数据进行合并
import weatherData.getWeatherData as gd
import numpy as np
import openpyxl
np.set_printoptions(threshold=np.inf)
# 获取天气数据结果
result = gd.getWeatherData()
# 获取FlightData表格数据
wb = openpyxl.load_workbook('D:\\File\\航班预测\\天气数据\\USA_fightDataSet.xlsx')
sheet = wb['FlightData_DL']
# 获取fightData的行数,必须+1,因为后面的for循环判断是<判断
rows = sheet.max_row+1
# 获取天气数据的行数
rows_weather = result.shape[0]
# 外层fightData数据
for i in range(3, rows):
# 获取月份/日期/出发和到达机场名字
# 注意,openpyxl读取的数据是从1开始计数的
month = sheet.cell(row=i, column=3).value
# 表格读取的数据莫名其妙不是字符串,导致后面判断总是false,需要转一下
dayOfMonth = str(sheet.cell(row=i, column=4).value)
ori_airport = sheet.cell(row=i, column=9).value # 出发机场
dest_airport = sheet.cell(row=i, column=13).value # 到达机场
# 内层循环天气数据
for j in range(0, rows_weather):
# 获取天气行数据
weather_row = result[j]
# 获取天气的各数据
w_month = weather_row[0]
w_dayOfMonth = weather_row[1]
w_airport = weather_row[2]
w_wsp = weather_row[3] # 风速
w_precipitation = weather_row[4] # 降水量
# 循环对比,如果月份/日期/机场名字都对应,则将风速和降水量插入表格
if month == w_month and dayOfMonth == w_dayOfMonth and ori_airport == w_airport:
sheet.cell(row=i, column=10).value = w_wsp
sheet.cell(row=i, column=11).value = w_precipitation
if month == w_month and dayOfMonth == w_dayOfMonth and dest_airport == w_airport:
sheet.cell(row=i, column=14).value = w_wsp
sheet.cell(row=i, column=15).value = w_precipitation
# 保存操作
wb.save('D:\\jdFile\\航班预测\\天气数据\\USA_fightDataSet.xlsx')
| 表格部分数据 |
|---|
 |
1.3 数据集处理
我们可以看看是否有缺省值,即空值null,进行数据一次处理,补充空值,抽出label,删除无效feature
# 读取路径的xlsx文件
dataFrame = pd.read_excel(url, sheet_name = sheetname)
# 判断是否有缺省值,即空值,true表示有空值
result = dataFrame.isnull().values.any()
# 有空值,找到空值所在位置
if result :
position = dataFrame.isnull().sum()
print(position)
print(result)
根据网上说法,xgboost在进行预测的时候,只对数字敏感,而不需要考虑量纲问题,所以对数据清洗的时候,我们可以最大限度保留可能的影响因素。另外,既然是分类树的形式,那么我们为了准确率和速度,必须对数据进行合理的分类,保证离散值足够小,数据处理原则:
1、去掉年份维度,保留季度、月、日、周日期
2、航班号,如果涉及到了历史准点率,则考虑航班号,否则取消航班号维度,因为我们有起飞的时刻,不需要航班号
3、出发到达机场ID或者说起飞城市ID,重要,因为这个维度从宏观上控制了地理位置、地形、海拔等不变因素
4、机场规模要考虑,一般小机场延误情况严重一些(1-小机场,2-中机场,3-大机场)
5、机场的风速,根据表格中的风速(单位是迈,我们转为km/h),对应风力等级,分为12个级别,减少数据散列程度
| 风力等级 | 风速(km/h) |
|---|---|
| 0 | <1 |
| 1 | 1-5 |
| 2 | 6-11 |
| 3 | 12-19 |
| 4 | 20-28 |
| 5 | 29-38 |
| 6 | 39-49 |
| 7 | 50-61 |
| 8 | 62-74 |
| 9 | 75-88 |
| 10 | 89-102 |
| 11 | 103-117 |
| 12 | >117 |
6、降水量分为6个等级,减少散列程度
| 降雨等级 | 雨量(mm) |
|---|---|
| 1 | <10 |
| 2 | 10~24.9 |
| 3 | 25~49.9 |
| 4 | 50~99.9 |
| 5 | 100~250 |
| 6 | >250 |
7、起飞时刻,这个维度散列值太多,我们可以÷100,将结果向下取整,其实就是小时,24个散列程度
8、飞行时长,对于国内航班,按照小时统计,÷60取整,缩小散列值
9、保留飞行距离
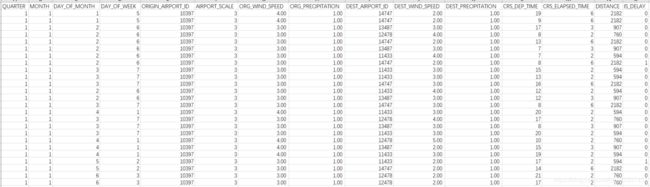
根据以上分析,将相应的数据补充进去
最终处理结果USA_fightDataSet
| USA_fightDataSet |
|---|
 |
二、使用xgboost进行处理
我们根据《机器学习之Knn算法》文章,对数据集进行处理,分出feature、label、向量数据和特征矩阵值,并分解为训练集和测试集
2.1 读取文件数据得到train And test
import pandas as pd
import numpy as np
# np.set_printoptions(threshold=np.inf)
# 创建航班延误数据集对象
class FlightDelay:
def __init__(self, feature_names, data, target_names, target):
self.feature_names = feature_names
self.data = data
self.target_names = target_names
self.target = target
# 读取excel文件(**强烈建议转为csv去处理,否则数据太容易被误改)
def getDataSet(url, sheetname):
# 读取路径的xlsx文件
dataFrame = pd.read_excel(url, sheet_name = sheetname)
# 可以打印查看数据的类型是否有str
# dataInfo = dataFrame.info()
# 转为数据矩阵
data_matrix = dataFrame.values
# 获取feature_names,取第一行为feature,使用columns获取列名,然后使用values获取结果,去除掉最后的label列名
feature_names = dataFrame.head(n=0).columns.values[:-1]
# 获取label标签
target_names = dataFrame.head(n=0).columns.values[-1]
# feature特征矩阵data,全部取整,保证离散值足够小
data = data_matrix[:, :-1].astype(int)
# label标签向量,将小数转为整型
target = data_matrix[:, -1].astype(int)
return FlightDelay(feature_names, data, target_names, target)
2.2 xgboost训练数据
import xgboost as xgb
from sklearn.metrics import roc_auc_score
from sklearn.metrics import roc_curve
import matplotlib.pyplot as plt
from sklearn.model_selection import GridSearchCV
import numpy as np
np.set_printoptions(threshold=np.inf)
# XGBOOST进行预测
# 通用参数:#
# booster:我们有两种参数选择,gbtree和gblinear。gbtree是采用树的结构来运行数据,而gblinear是基于线性模型
# silent:静默模式,为1时模型运行不输出
# nthread: 使用线程数,一般我们设置成-1,使用所有线程。如果有需要,我们设置成多少就是用多少线程
# Booster参数:#
# n_estimator:num_boosting_rounds 最大的迭代次数
# learning_rate: 有时也叫作eta,系统默认值为0.3,每一步迭代的步长,很重要。太大了运行准确率不高,太小了运行速度慢。我们一般使用比默认值小一点,0.1左右就很好
# gamma:系统默认为0,在节点分裂时,只有分裂后损失函数的值下降了,才会分裂这个节点。gamma指定了节点分裂所需的最小损失函数下降值。 这个参数的值越大,算法越保守。因为gamma值越大的时候,损失函数下降更多才可以分裂节点。所以树生成的时候更不容易分裂节点
# subsample:系统默认为1,这个参数控制对于每棵树,随机采样的比例。减小这个参数的值,算法会更加保守,避免过拟合。但是,如果这个值设置得过小,它可能会导致欠拟合。 典型值:0.5-1,0.5代表平均采样,防止过拟合
# colsample_bytree:系统默认值为1。我们一般设置成0.8左右,用来控制每棵随机采样的列数的占比(每一列是一个特征)。 典型值:0.5-1
# colsample_bylevel:默认为1,我们也设置为1;这个就相比于前一个更加细致了,它指的是每棵树每次节点分裂的时候列采样的比例
# max_depth: 系统默认值为6,我们常用3-10之间的数字。这个值为树的最大深度。这个值是用来控制过拟合的。max_depth越大,模型学习的更加具体。设置为0代表没有限制
# max_delta_step:默认0,我们常用0.,这个参数限制了每棵树权重改变的最大步长,如果这个参数的值为0,则意味着没有约束。如果他被赋予了某一个正值,则是这个算法更加保守。通常,这个参数我们不需要设置,但是当个类别的样本极不平衡的时候,这个参数对逻辑回归优化器是很有帮助的。
# lambda:也称reg_lambda,默认值为0就,权重的L2正则化项。(和Ridge regression类似)。这个参数是用来控制XGBoost的正则化部分的。这个参数在减少过拟合上很有帮助。
# alpha:也称reg_alpha默认为0,权重的L1正则化项。(和Lasso regression类似)。 可以应用在很高维度的情况下,使得算法的速度更快
# scale_pos_weight:默认为1,在各类别样本十分不平衡时,把这个参数设定为一个正值,可以使算法更快收敛。通常可以将其设置为负样本的数目与正样本数目的比值
# 学习目标参数 #
# objective [缺省值=reg:linear]
# reg:linear– 线性回归
# reg:logistic – 逻辑回归
# binary:logistic – 二分类逻辑回归,输出为概率
# binary:logitraw – 二分类逻辑回归,输出的结果为wTx
# count:poisson – 计数问题的poisson回归,输出结果为poisson分布。在poisson回归中,max_delta_step的缺省值为0.7
# multi:softmax – 设置 XGBoost 使用softmax目标函数做多分类,需要设置参数num_class(类别个数),输出为概率最大的分类
# multi:softprob – 如同softmax,但是输出结果为ndata*nclass的向量,其中的值是每个数据分为每个类的概率
# eval_metric [缺省值=通过目标函数选择]
# rmse: 均方根误差(回归问题默认)
# mae: 平均绝对值误差
# logloss: negative log-likelihood数似然损失,对数损失函数,一般用于分类问题
# error: 二分类错误率。其值通过错误分类数目与全部分类数目比值得到。对于预测,预测值大于0.5被认为是正类,其它归为负类(分类问题默认)
# merror: 多分类错误率,计算公式为(wrong cases)/(all cases)
# mlogloss: 多分类log损失
# auc: 曲线下的面积
# ndcg: Normalized Discounted Cumulative Gain
# map: 平均正确率
def inputDataSet(X_train, X_test, y_train, y_test):
# 设置xgboost分类器
xlf = xgb.XGBClassifier(max_depth=6, learning_rate=0.1, n_estimators=1000, objective='binary:logistic',
nthread=-1, subsample=0.5, colsample_bytree=0.8)
# 训练,verbose标识每迭代一次进行输出,可以指定迭代几次输出
xlf.fit(X_train, y_train, eval_metric='error', verbose=True)
# 预测准确率得分
score = xlf.score(X_test, y_test)
print("预测准确率得分 = {:.2f}".format(score),)
# AUC模型评分
y_pred = xlf.predict_proba(X_test)
auc_score = roc_auc_score(y_test, y_pred[:, 1])
print("AUC模型评价 = {:.2f}".format(auc_score))
# roc曲线可视化输出
roc_function_image(y_test, y_pred)
# 可视化的roc评价函数图像
def roc_function_image(y_test, y_pred):
# fpr是假阳性率,tpr是真阳性率
fpr, tpr, _ = roc_curve(y_test, y_pred[:, 1])
plt.plot(fpr, tpr, color='darkred')
plt.plot([0, 1], [0, 1], color='grey', lw=1, linestyle='--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.show()
方法的调用
import getdata.FlightDelay as fd
import getdata.XgboostModel as xm
from sklearn.model_selection import train_test_split
# 导入xlsx文件路径和工作簿名称
url = "D:\\python\\Projects\\USA_flightDelayInfo_dataSet\\USA_fightDataSet.xlsx"
sheet_name = 'DL'
# 调用方法获取数据集
flightDataSet = fd.getDataSet(url, sheet_name)
target_names = flightDataSet.target_names
target = flightDataSet.target
feature_names = flightDataSet.feature_names
data = flightDataSet.data
# 使用train_test_split方法获取训练集和测试集,这里二八分,随机种子为1
X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=0.2, random_state=1)
# 使用xgboost进行模型预测
xm.inputDataSet(X_train, X_test, y_train, y_test)
输出结果:
预测准确率得分 = 0.85
AUC模型评价 = 0.70
| roc模型评价曲线 |
|---|
 |
2.3 结果说明
我们的模型预测准确率达到了85%,但事实并非如此,会有一种情况,博主称之为“机器欺骗”:
为1(true)的情况太少,而0(false)的情况太多,导致,模型无论给定结果如何全部输出0,从而凭运气导致预测结果准确率很高,即模型的
欺骗行为
为了避免这种情况,我们需要引入ROC(Receiver Operating Characteristic Curve) 受试者工作特征曲线。用来评价二分类问题的模型好坏。
ROC曲线主要是对二分类预测模型的预测概率情况进行描述,真实的结果分为了【0-false,1-true】,那么预测结果是否与真实结果一致,这边产生了四种情况:
| 预测概率情况矩阵 |
|---|
 |
通俗来讲就是,我实际值是1,你预测为1的概率是多少,预测为0的概率是多少,即TPR+FNR=100%,我们的考察是TPR(True Positive Rate)和FPR(False Positive Rate),前面输出的函数图像就是这个函数的结果。
AUC(Area Under Curve)这个得分指标其实就是ROC曲线与x轴的面积。
如果图像在y=x这个直线上,说明,auc得分是0.5,则这个模型就跟抛硬币一样,随机预测,根本没有“自己动脑”,这是不理想的,也是auc的底线。如果小于0.5,说明模型的预测与实际总是相反的,这时候我们要考虑对结果进行取反操作,保证预测准确。
所以最理想的就是在0.5以上,切越靠近y轴越精确,即每次的预测都是“有效思考”后的结果。