LCA-Tarjan,RMQ,倍增算法超详细原理讲解+python实践(Lowest Common Ancestor of a Binary Tree)
最近公共祖先算法:
通常解决这类问题有两种方法:在线算法和离线算法
在线算法:每次读入一个查询,处理这个查询,给出答案
离线算法:一次性读入所有查询,统一进行处理,给出所有答案
我们接下来介绍一种离线算法:Tarjan,两种在线算法:RMQ,倍增算法
Tarjan的时间复杂度是 O(n+q)
RMQ是一种先进行 O(nlogn) 预处理,然后O(1)在线查询的算法。
倍增算法是一种时间复杂度 O((n+q)logn)的算法
----------------------------------------------------------------------------------------------------------------
本文采用的例子是leetcode的236题,当然本题不是非要采用这三种方法,其实有代码更简洁的方法,可以在讨论区看到,但是本文重在说明这三种方法,其意义在于如在线算法,我们在进行了看似时间复杂度很高的预处理后,以后查询就很快了,即一次预处理换来了以后都很快的查询。
本文采用的结构是三个大模块即Tarjan,RMQ,倍增算法(以%%%%%%%号为分界线)。每个模块下先结合具体的例子讲原理,然后给出算法的伪代码,接着给出使用该算法解决本题的具体实践代码(python实现),最后给出在具体实践中代码方面需要注意的问题
废话不多说啦!先看一下本题:

%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
Tarjan:
它的过程是:
一:首先从根节点u开始进行遍历
二:遍历u的所有子节点v
三:如果v有孩子节点,则返回二直接往下遍历
四:查看与当前节点v有访问关系的节点e
五:如果e有已访问过的标记,则可以确认v和e的最近公共祖先为e被合并到的父亲节点m。 否则什么都不做
六:将v的祖先合并为u,将v设置为已访问
七:回溯
其实上面整个就是一个深度遍历
我们以上面题目为例说明Tarjan原理:
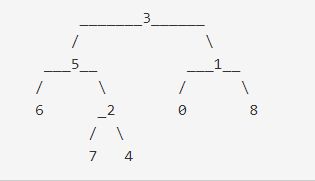
假设我们要找LCA(6,7)和LCA(4,0)
我们首先定义两个数组f和vis
f[i]表示i的祖先,初始化为自身,vis[i]表示节点i是否被访问过的标记,初始化为False ,对应到本题就是:
f[3] = 3 , f[5] = 5 , f[6] = 6 , f[2] = 2 , f[7] = 7 , f[4] = 4 , f[1] = 1 , f[0] = 0 , f[8] = 8
vis[3] = False, vis[5] = False, vis[6] = False, vis[2] = False, vis[7] = False, vis[4] = False, vis[1] = False, vis[0] = False, vis[8] = False
--------------------------------------------------------------------------------------------------------------------------------------------------------
过程:
首先遍历根节点3
发现其孩子有5和1
接着遍历5,发现其还有孩子6和2接着遍历6,发现其是叶子节点即没有子节点
现在查看和6有访问关系的元素,发现是7(注意这里可以是多个,比如我们要找的是LCA(6,7),LCA(6,,0)等等),此时vis[7] = False即7没有被访问过,所以什么都不做
接下来将其祖先设为5 标志为已访问所以此时:
f[3] = 3 , f[5] = 5 , f[6] = 5 , f[2] = 2 , f[7] = 7 , f[4] = 4 , f[1] = 1 , f[0] = 0 , f[8] = 8
vis[3] = False, vis[5] = False, vis[6] = True, vis[2] = False, vis[7] = False, vis[4] = False, vis[1] = False, vis[0] = False, vis[8] = False
最后直接回溯

##############回溯到元素2,发现2还有孩子节点7和4,那么遍历7,发现其是叶子节点,那么就查看和7有访问关系的元素,发现是6,此时vis[6] = True,是已访问状态,所以它们的最近公共祖先就是find(6) = 5
接下来将其祖先设为2,标志为已访问,即:
f[3] = 3 , f[5] = 5 , f[6] = 5 , f[2] = 2 , f[7] = 2 , f[4] = 4 , f[1] = 1 , f[0] = 0 , f[8] = 8
vis[3] = False, vis[5] = False, vis[6] = True, vis[2] = False, vis[7] = True, vis[4] = False, vis[1] = False, vis[0] = False, vis[8] = False
最后回溯
注意:find是这样实现的:
find(n)
{
if n!=f[n]
{
return find(n);
}
else
return n;
}对应到这里就是![]()
接着回溯到4,发现其是叶子节点,那么就查看和4有访问关系的元素,发现是0,此时vis[0] = False,所以什么都不做
合并其祖先是2,标记为已访问,即:
f[3] = 3 , f[5] = 5 , f[6] = 5 , f[2] = 2 , f[7] = 2 , f[4] = 2 , f[1] = 1 , f[0] = 0 , f[8] = 8
vis[3] = False, vis[5] = False, vis[6] = True, vis[2] = False, vis[7] = True, vis[4] = True, vis[1] = False, vis[0] = False, vis[8] = False
最后回溯:
回溯到2,发现其没有与之有访问关系的元素,这直接合并祖先,标记访问
f[3] = 3 , f[5] = 5 , f[6] = 5 , f[2] = 5 , f[7] = 2 , f[4] = 2 , f[1] = 1 , f[0] = 0 , f[8] = 8
vis[3] = False, vis[5] = False, vis[6] = True, vis[2] = True, vis[7] = True, vis[4] = True, vis[1] = False, vis[0] = False, vis[8] = False
回溯到5,发现其没有与之有访问关系的元素,这直接合并祖先,标记访问
f[3] = 3 , f[5] = 3 , f[6] = 5 , f[2] = 5 , f[7] = 2 , f[4] = 2 , f[1] = 1 , f[0] = 0 , f[8] = 8
vis[3] = False, vis[5] = True, vis[6] = True, vis[2] = True, vis[7] = True, vis[4] = True, vis[1] = False, vis[0] = False, vis[8] = False
回溯到1,发现其有孩子节点0和8,接着遍历0
发现0是叶子节点,查看与其有访问关系的元素,发现是4,而此时vis[4] = True,所以find(4)=3
![]()
接下来将其祖先设为1,标记为已访问
f[3] = 3 , f[5] = 3 , f[6] = 5 , f[2] = 5 , f[7] = 2 , f[4] = 2 , f[1] = 1 , f[0] = 1 , f[8] = 8
vis[3] = False, vis[5] = True, vis[6] = True, vis[2] = True, vis[7] = True, vis[4] = True, vis[1] = False, vis[0] = True, vis[8] = False
最后回溯到8
发现8是叶子节点,发现其没有与之有访问关系的元素,这直接合并祖先,标记访问
f[3] = 3 , f[5] = 3 , f[6] = 5 , f[2] = 5 , f[7] = 2 , f[4] = 2 , f[1] = 1 , f[0] = 1 , f[8] = 1
vis[3] = False, vis[5] = True, vis[6] = True, vis[2] = True, vis[7] = True, vis[4] = True, vis[1] = False, vis[0] = True, vis[8] = True,
最后回溯
回溯到3即根节点结束
--------------------------------------------------------------------------------------------------------------------------------------------------------------
注意:在实际过程中假如我们是找一个LCA,比如我们的任务是LCA(6,7),那么其实我们可以在上面过程中##############处结束,即找到了LCA是5后就完成了任务,直接返回就好了,不变再遍历其他元素啦
Tarjan伪代码:
f[i] = i //存储i的父节点,初始化为自身即i
vis[i] = 0 //节点i的访问标志,初始化为0
Tarjan(u) //根节点u
{
for each(u,v) //遍历与U相邻的所有节点v
{
Tarjan(v); //递归v
join(u,v); //把v合并到u上,即将v的父节点设为u
vis[v]=1; //访问标记
}
for each(u,e) //遍历与u有询问关系的节点v
{
if(vis[e])
{
ans=find(e);
}
}
}
find(n)
{
if n!=f[n]
{
return find(n);
}
else
return n;
}最后实践一下最开始给出的题目吧,这里使用的是python
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution:
def lowestCommonAncestor(self, root, p, q):
"""
:type root: TreeNode
:type p: TreeNode
:type q: TreeNode
:rtype: TreeNode
"""
self.f = {}
self.vis = {}
#下面的dfs遍历主要是为了初始化 self.f和self.vis
self.dfs(root)
return self.Tarjan(root,p.val,q.val)
def Tarjan(self,root,p,q):
self.vis[root.val] = True
if root.left!=None:
c=self.Tarjan(root.left,p,q)
if c!=None:
return c
self.f[root.left.val] = root.val
if root.right!=None:
c=self.Tarjan(root.right,p,q)
if c!=None:
return c
self.f[root.right.val] = root.val
if root.val==p and self.vis[q] :
return self.find(q)
if root.val==q and self.vis[p] :
return self.find(p)
def dfs(self,root):
if root!=None:
self.f[root.val] = root.val
self.vis[root.val] = False
self.dfs(root.left)
self.dfs(root.right)
def find(self,x):
if x!=self.f[x]:
return self.find(self.f[x])
else:
return TreeNode(x)注意这里开始运行了一个dfs,它的目的只是为了初始化 self.f = {},self.vis = {}
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
RMQ:
我们还是以题目给出的例子来说明RMQ的原理:
注意:下面我们说“位置”的时候是从1开始的,因为数组的第一个元素是从0开始,这里有点区别,事先说明一下,以免误会。
首先我们使用深度遍历得到欧拉序列ves:
ves = [3, 5, 6, 5, 2, 7, 2, 4, 2, 5, 3, 1, 0, 1, 8, 1, 3]
其在树上对应的深度分别为:
R = [1, 2, 3, 2, 3, 4, 3, 4, 3, 2, 1, 2, 3, 2, 3, 2, 1]
我们要找两个节点的最近祖先LCA,其实就是找深度最浅的点,怎么说呢?我们来几个例子:
比如我们要找5和8的LCA,对应到ves中就是区间[3, 5, 6, 5, 2, 7, 2, 4, 2, 5, 3, 1, 0, 1, 8, 1, 3]
注意:我们在找区间的时候是从元素第一次出现的地方开始,所以上面的区间是对的,而不是[5, 3, 1, 0, 1, 8]
而这一段区间元素对应的深度是:[1, 2, 3, 2, 3, 4, 3, 4, 3, 2, 1, 2, 3, 2, 3, 2, 1]
这一段区间深度最小的就是1啦,那它对应的位置就是11,对应的元素就是3
所以LCA(5,8) = 3
再比如我们要找6和4的LCA,对应到ves中就是区间[3, 5, 6, 5, 2, 7, 2, 4, 2, 5, 3, 1, 0, 1, 8, 1, 3]
而这一段区间元素对应的深度是: [1, 2, 3, 2, 3, 4, 3, 4, 3, 2, 1, 2, 3, 2, 3, 2, 1]
这一段区间深度最小的就是2啦,那它对应的位置就是4,对应的元素就是5
所以LCA(6,4) = 5
原理呢就是这么简单,概括说就是先找到区间,然后找这一区间深度最浅的元素,该元素就是我们要找的LCA
ves和R的获得比较容易,就想上面说的可以直接使用DFS遍历得到
下面我们再来说一下怎么找某一段区间最小的问题,通常这里使用ST表解决
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
ST表:
ST表是用来解决给定区间求最值问题的,这里就以求最小值为例来说明原理吧:
假如给定区间为:[3,10,4,8,2,11,7]
dp[i,j]表示以i为起点,区间长度为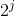 的区间最小值
的区间最小值
比如:dp[1,0]对应的区间就是[3,10,4,8,2,11,7] 所以dp[1,0]=3
dp[1,1]对应的区间就是[3,10,4,8,2,11,7] 所以dp[1,1]=3
dp[1,2]对应的区间就是[3,10,4,8,2,11,7] 所以dp[1,2]=3
dp[2,2]对应的区间就是[3,10,4,8,2,11,7] 所以dp[2,2]=2
在求解dp[i,j]时,使用动态规划,其过程是先对长度为的区间分成两等份,每份长度均为![]() 。之后在分别求解这两个区间的最小值dp[i,j-1]和dp[i+
。之后在分别求解这两个区间的最小值dp[i,j-1]和dp[i+![]() ,j-1]。,最后结合这两个区间的最值,求出整个区间的最值。特殊情况,当j = 0时,即区间长度等于1,就是是说区间只有一个元素即本身,此时dp[i,0]就应该等于自身。
,j-1]。,最后结合这两个区间的最值,求出整个区间的最值。特殊情况,当j = 0时,即区间长度等于1,就是是说区间只有一个元素即本身,此时dp[i,0]就应该等于自身。
假如我们现在需要求dp[3,2]时,对应的区间是[3,10,4,8,2,11,7] 那么我们可以分成两段即[3,10,4,8,2,11,7]和[3,10,4,8,2,11,7]
即求dp[3,1]和dp[5,1] 所以dp[3,2] = min (dp[3,1] , dp[5,1])
于是动态方程就是:
![]()
初始化为:
![]()
在进行递推的时候,是对每一元素,先求所有元素区间长度为1的区间最值,接着求所有元素区间长度为2的区间最值,之后再求区间长度为4的区间最值….,最后求解区间长度为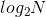 的区间最值,其中N表示元素个数。
的区间最值,其中N表示元素个数。
即:先初始化dp[1,0],dp[2,0],dp[3,0],,,,dp[N,1]
接着求 dp[1,1] dp[2,1],dp[3,1],, dp[N,1],再求.dp[1,2],dp[2,2],dp[3,2],,,dp[N,2],… 。
---------------------------------------------------------------------------------------------------------------------------------------------------------
注意现在我们希望得到的是某一段区间最小值对应的位置即:

所以关于ST的伪代码可以写成:
#dp里面存储的是某一段区间里面拥有最小深度元素的位置
void ST(int len){
int k = int(log(len,2));#以2为低的log函数
#初始化
for (int i=1;i<=len;i++){
dp[i,0] = i;
}
#区间长度分别是1,2,4,8,,,,,,,,,,
for (int j=1;j<=k;j++){
#遍历每一个元素
for(int i=1;i+pow(2,j)-1<=len;i++){
int a = dp[i,j-1];
int b = dp[i+pow((j-1),2),j-1];
#这里是用树的深度来选择最小值
if (R[a]现在我们有了dp就好办啦:
所以RMQ的伪代码就是:
int RMQ(int m,int n){
int k = int(log((n-m+1,2)));
int a = dp[m,k];
int b = dp[n-pow(k,2)+1,k];
if a我们要找两个节点的LCA时,这里的m,n就是这两个节点的位置说白了就是其在数组ves中对应的下标比如我们要找LCA(5,8)
那么m=2,n=15
好啦最后就是我们LCA啦:
int LCA(int u ,int v) //返回点u和点v的LCA
{
int x = first[u] , y = first[v];
if(x > y) swap(x,y);
int res = RMQ(x,y);
return ver[res];
}综上所述我们大概需要四个功能的函数:
DFS,ST,RMQ,LCA
最后总体写一下RMQ全部代码的模板:
void dfs(int u ,int depth){
tot++;
ves[tot] = u;
R[tot] = depth;
if (u not in first){
first[u] = tot;
}
for(k=u.next){
dfs(k,depth+1);
ves[tot] = u;
R[tot] = dep;
}
}
int RMQ(int x ,int y)
{
int K = (int)(log((double)(y-x+1)) / log(2.0));
int a = dp[x][K] , b = dp[y-_pow[K]+1][K];
if(R[a] < R[b]) return a;
else return b;
}
int LCA(int u ,int v)
{
int x = first[u] , y = first[v];
if(x > y) swap(x,y);
int res = RMQ(x,y);
return ver[res];
}
void ST(int len){
int k = int(log(len,2));
for (int i=1;i<=len;i++){
dp[i,0] = i;
}
for (int j=1;j<=k;j++){
for(int i=1;i+pow(2,j)-1<=len;i++){
int a = dp[i,j-1];
int b = dp[i+pow((j-1),2),j-1];
if (R[a]最后还是实践一下开始给出的题目,笔者这里使用的是python,代码如下:
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution:
import math
def lowestCommonAncestor(self, root, p, q):
"""
:type root: TreeNode
:type p: TreeNode
:type q: TreeNode
:rtype: TreeNode
"""
#记录每一个元素对应的深度
self.R = []
#记录遍历过的元素对应
self.ves = []
#记录每一个区段的最值,它的结构是这样{1: [1, 1, 1, 1, 1], 2: [2, 2, 2, 2, 11],.........}
#2: [2, 2, 2, 2, 11]比如代表的意义就是从第二个位置开始,长度为1的区间中(本身)深度最浅元素的位置是2,长度为2的区间中深度最浅元素的位置是2
#长度为4的区间中(本身)深度最浅元素的位置是2,长度为8的区间中(本身)深度最浅元素的位置是2,长度为16的区间中(本身)深度最浅元素的位置是11
self.dp = {}
#记录每一个元素在欧拉序中出现的第一个位置
self.first = {}
self.dfs(root,1)
self.ST(len(self.R))
m = self.LCA(p.val,q.val)
return TreeNode(m)
def LCA(self,f,g):
if self.first[f]直观看一下各个变量:
self.ves:
[3, 5, 6, 5, 2, 7, 2, 4, 2, 5, 3, 1, 0, 1, 8, 1, 3]self.R:
[1, 2, 3, 2, 3, 4, 3, 4, 3, 2, 1, 2, 3, 2, 3, 2, 1]self.dp:
{1: [1, 1, 1, 1, 1], 2: [2, 2, 2, 2, 11], 3: [3, 4, 4, 4], 4: [4, 4, 4, 11], 5: [5, 5, 5, 11], 6: [6, 7, 7, 11], 7: [7, 7, 10, 11], 8: [8, 9, 11, 11], 9: [9, 10, 11, 11], 10: [10, 11, 11, 11], 11: [11, 11, 11], 12: [12, 12, 12], 13: [13, 14, 14], 14: [14, 14, 17], 15: [15, 16], 16: [16, 17], 17: [17]}注意这里采用字典的形式代表dp[i,j],如3: [3, 4, 4, 4]代表的含义就是从位置3开始(注意我们这里所说的位置不是从0开始的,即第一个元素的位置就是1,而不是0,不要和数组的下标混了,因为数组下标是从0开始的)长度分别为1,2,4,8的区间内对应的深度最浅的元素的位置是3,4,4,4结合self.ves:可以知道3和4的位置是6和5
self.first:
{0: 13, 1: 12, 2: 5, 3: 1, 4: 8, 5: 2, 6: 3, 7: 6, 8: 15}它的含义就是元素第一次出现的位置,比如0: 13就是说0这个元素在ves中第一次出现的位置是13
[3, 5, 6, 5, 2, 7, 2, 4, 2, 5, 3, 1, 0, 1, 8, 1, 3]
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
倍增算法:
为了更加形象说明其工作原理,我们还是用上面题目给出的例子来讲解:
假如我们求LCA(1,8),LCA(7,8)过程如下:
先将深度大的那个节点上移,使两者处于同一深度,具体就是我们要找LCA(7,8)转化为LCA(2,8),要找LCA(1,8)转化为LCA(1,1)
当转化为两者处于同一深度时,先判断新的两个元素是否相同,如果相同则其就是结果返回即可,例如LCA(1,1)返回1,如果不相同,那么两者一同上移,知道转化后的两个新元素相同返回,例如LCA(2,8)继续转化为LCA(5,1),LCA(5,1)继续转化为LCA(3,3),此时相同返回3即可。
原理呢就是这么简单,但是每次上移都是一步的话,这样太慢啦,而这里的倍增算法,关键之处就是体现在上移过程中不是一步一步移,而是以2的倍数进行上移
现在定义两个数组,f[i,j]和depth[i]
f[i,j]代表的意思是从节点i开始上移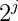 所到达的节点,例如f[7,0]=2,f[0,1]=3
所到达的节点,例如f[7,0]=2,f[0,1]=3
所以可以得到递推式:
![\begin{matrix} f[i,0]=father_{i}\\ f[i,j]=f[f[i,j-1],j-1] \end{matrix}](http://img.e-com-net.com/image/info8/c5c576c7df7f49fca49143e2e6921ff7.gif)
depth[i]代表的是节点i在树中的深度,例如depth[6]=3 , depth[4]=4
写一下其模板:
void dfs(int prev,int rt){
depth[rt]=depth[prev]+1;
fa[rt][0]=prev;
for (int i=1;i<100;i++)
fa[rt][i]=fa[fa[rt][i-1]][i-1];
for (int i=0;i注意这里的100是指最多可以上跳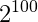
有了这些信息,我们来讲一下怎么使用倍增的思想来跳
首先解决怎么将两者移位同一深度:
假如LCA(m,n),假设n的深度大于m
设两者的高度差是H,我们的i从100开始即从迈最大的步数开始(这里所说的i其实就是一个for循环),看H是否大于等于![]() ,如果大于等于的话我们就将深度深的那个节点上移
,如果大于等于的话我们就将深度深的那个节点上移![]() 即n=f[n,i],如果不大于的话就什么也不做,接着我们减少i为99,用新的n和m重复上面的过程,直到两者处于同一深度,好像有点复杂,来举个例子吧
即n=f[n,i],如果不大于的话就什么也不做,接着我们减少i为99,用新的n和m重复上面的过程,直到两者处于同一深度,好像有点复杂,来举个例子吧

对于这个树结构来说,上面的100在这里只需要3即最大上移8
假设现在求LCA(D,P)
已知f[P,0] = M,f[p,1] = I,f[P,2] = B
depth[P]=6
f[D,0]=B,f[D,1]=A
depth[D]=3
f[I,0]=E , f[I,1]=A
对应到上面的话
那么这里高度差为H=6-3=3,我们首先从P开始迈最大的步i=2,即迈![]() ,此时H<
,此时H<![]() ,那么我们什么也不做,于是i--,此时i=1,于是我们这次迈
,那么我们什么也不做,于是i--,此时i=1,于是我们这次迈![]() ,此时H>
,此时H>![]() ,于是上移到I(f[p,1] = I),此时i--,即i=0,于是我们这次迈
,于是上移到I(f[p,1] = I),此时i--,即i=0,于是我们这次迈![]() 步,H>
步,H>![]() ,于是上移到E(f[I,0]=E)
,于是上移到E(f[I,0]=E)
i--,此时i=-1小于0结束,可以看到由P移动到E,移动到同一深度啦,于是问题就转化为求LCA(D,E)
注意:其实一旦H大于等于![]() ,以后i不断的减小,这一条件都是满足的,所以从此时的i开始,以后都要上移,只不过上移的步伐都是上次的一半,总结来说就是先找出可以迈的最大步伐,迈出去,更新当前元素,然后从当前元素开始,向上迈,迈的步伐是上次的一半,然后不断重复上面的过程,直到深度相同
,以后i不断的减小,这一条件都是满足的,所以从此时的i开始,以后都要上移,只不过上移的步伐都是上次的一半,总结来说就是先找出可以迈的最大步伐,迈出去,更新当前元素,然后从当前元素开始,向上迈,迈的步伐是上次的一半,然后不断重复上面的过程,直到深度相同
接下来我们解决怎么利用倍增思想将两者怎么同时上移,找到共同祖先:
假设我们找LCA(P,O),此时我们利用上面的过程已将问题转化为求LCA(M,O)
已知 f[M,0]=I , f[M,1]=E , f[M,2]=A
f[O,0]=K, f[O,1]=F, f[O,2]=A
f[E,0]=B, f[E,1]=A
f[F,0]=C, f[F,1]=A
f[B][0]=A
f[C][0]=A
我们还是从i最大开始,即从迈最大的步伐开始,两者同时迈即同时上移,上移后,如果两者元素不同就更新,否则不更新。
对应到这里就是我们将从i=2开始,两者同时上移,发现上移后元素相同都是A(f[M,2]=A=f[O,2]),那么什么不做,i--,此时i=1,即同时上移![]() ,发现元素不相同即E和F(f[M,1]=E, f[O,1]=F),更新,此时两个元素各自更新为E和F即
,发现元素不相同即E和F(f[M,1]=E, f[O,1]=F),更新,此时两个元素各自更新为E和F即![]()
i--,此时i=0,将E和F同时上移![]() 发现元素不相同即B和C(f[E,0]=B,f[F,0]=C),此时两个元素各自更新为B和C即
发现元素不相同即B和C(f[E,0]=B,f[F,0]=C),此时两个元素各自更新为B和C即![]()
i--,此时i=-1,i<0结束。
返回f[B][0]或f[C][0]即是结果:A
其实就是说先找出可以迈的最大步伐,迈出去,分别更新两者当前元素,然后从当前元素开始,向上迈,迈的步伐是上次的一半,然后不断重复上面的过程,直到元素相同
说了这么多还是给出代码模板吧,这样逻辑看起来会更加清晰:(这里还是假设i最大为100)
int LCA(int x,int y){
if (depth[x]=0;i--)
if (depth[x]-(1<=depth[y])
x=fa[x][i];
if (x==y)
return x;
for (int i=100;i>=0;i--)
if (fa[x][i]!=fa[y][i])
x=fa[x][i],y=fa[y][i];
return fa[x][0];
} 所以总体来说就是先用dfs遍历得到f[i,j]和depth[i]
接着使用LCA函数得到结果
伪代码总结一下就是:
void dfs(int prev,int rt){
depth[rt]=depth[prev]+1;
fa[rt][0]=prev;
for (int i=1;i<100;i++)
fa[rt][i]=fa[fa[rt][i-1]][i-1];
for (int i=0;i=0;i--)
if (depth[x]-(1<=depth[y])
x=fa[x][i];
if (x==y)
return x;
for (int i=100;i>=0;i--)
if (fa[x][i]!=fa[y][i])
x=fa[x][i],y=fa[y][i];
return fa[x][0];
}
int main(){
#假如我们要求LCA(p,q)
#depth,fa数组的申请
depth[m]
fa[m][n]
#depth[root]的初始化
depth[root] = 1
if root.left!=None{
dfs(root,root.left);
}
if root.right!=None{
dfs(root,root.right);
}
return LCA(p,q)
} 最后还是实践一下开始给出的题目,笔者这里使用的是python,代码如下:
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution:
import math
def lowestCommonAncestor(self, root, p, q):
"""
:type root: TreeNode
:type p: TreeNode
:type q: TreeNode
:rtype: TreeNode
"""
self.depth = {}
self.f = {}
self.maxstep = 100
self.depth[root.val] = 1
if root.left!=None:
self.dfs(root,root.left)
if root.right!=None:
self.dfs(root,root.right)
c = self.LCA(root.val,p.val,q.val)
return TreeNode(c)
def LCA(self,root,m,n):
#因为 self.f中没有根节点,所以这里判断一下,如果其中一个是根节点,那么其LCA必是根节点,直接返回即可
if m==root or n==root:
return root
if self.depth[n]=2**(len(self.f[n])-i-1):
n = self.f[n][len(self.f[n])-i-1]
if n==m:
return n
#两者一同向上跳,注意这里的length的重要性
length = len(self.f[n])
for i in range(length):
if self.f[n][length-i-1]!=self.f[m][length-i-1]:
n = self.f[n][length-i-1]
m = self.f[m][length-i-1]
return self.f[m][0]
def dfs(self,prev,rt):
self.f[rt.val] = [prev.val]
self.depth[rt.val] = self.depth[prev.val]+1
for i in range(1,self.maxstep):
if self.f[rt.val][i-1] in self.f.keys() and len(self.f[self.f[rt.val][i-1]])>=i :
self.f[rt.val].append(self.f[self.f[rt.val][i-1]][i-1])
else:
break
if rt.left!=None:
self.dfs(rt,rt.left)
if rt.right!=None:
self.dfs(rt,rt.right) 对应着
来直观看一下各个变量:
self.f:
{0: [1, 3], 1: [3], 2: [5, 3], 4: [2, 5], 5: [3], 6: [5, 3], 7: [2, 5], 8: [1, 3]}self.depth:
{0: 3, 1: 2, 2: 3, 3: 1, 4: 4, 5: 2, 6: 3, 7: 4, 8: 3}注意:
一:f中并没有根节点,对应到上面的例子中即f字典中没有关键3
二:因为python的字典不需要事先申请大小,所以我们在深度遍历f时,事先判断一下是否能继续继续上跳,能的话就append
不能的话就break
其实就是看![]() 是否存在并且
是否存在并且![]() 所对应的列表长度得大于j,否则怎么可能会有
所对应的列表长度得大于j,否则怎么可能会有![]() 对吧,所以这里准确来说有两个条件
对吧,所以这里准确来说有两个条件
举个例子
我们在求self.f[5][1]=self.f[self.f[5][0]][0]=self.f[3][0],而正如上面给出的self.f中并没有关键字3所以就break好啦,结果就是self.f[5]中的列表就只是一个元素即self.f[5][0],而没有self.f[5][1] self.f[5][2] self.f[5][3],,,,,,,正如上面
{0: [1, 3], 1: [3], 2: [5, 3], 4: [2, 5], 5: [3], 6: [5, 3], 7: [2, 5], 8: [1, 3]}
再比如我们求self.f[7][2]=self.f[self.f[7][1]][1]=self.f[5][1],此时满足第一条件即5是f的关键字,但len(self.f[5])=1,只有一个元素即5: [3],
只有self.f[5][0],而我们要求self.f[5][1]显然不存在,所以self.f[7][2]不存在,直接break,最后self.f[7]只有self.f[7][0] , self.f[7][1] 而self.f[7][2] , self.f[7][3] , ,,,,,,都没有
对应的代码就是:
if self.f[rt.val][i-1] in self.f.keys() and len(self.f[self.f[rt.val][i-1]])>=i :
self.f[rt.val].append(self.f[self.f[rt.val][i-1]][i-1])
else:
break三:这里说一下length的重要性,笔者之前是这样写的:
#两者一同向上跳,注意这里的length的重要性
for i in range(len(self.f[n])):
if self.f[n][len(self.f[n])-i-1]!=self.f[m][len(self.f[n])-i-1]:
n = self.f[n][len(self.f[n])-i-1]
m = self.f[m][len(self.f[n])-i-1]
return self.f[m][0]结果一直不通过,显示错误,我们来看一下原因:
对比:
#两者一同向上跳,注意这里的length的重要性
length = len(self.f[n])
for i in range(length):
if self.f[n][length-i-1]!=self.f[m][length-i-1]:
n = self.f[n][length-i-1]
m = self.f[m][length-i-1]
return self.f[m][0]可以看到这里的length在每一次循环下其实是个定值,而错误的那个len(self.f[n])其实是个变量,随着n的更新变化而变化
我们拿过来一开始分析的那段话:其实就是说先找出可以迈的最大步伐,迈出去,分别更新两者当前元素,然后从当前元素开始,向上迈,迈的步伐是上次的一半,然后不断重复上面的过程,直到元素相同
这里的“迈的步伐是上次的一半”就是说self.f[n][length-i-1]中length-i-1体现的正是如此,而错误的中self.f[n][len(self.f[n])-i-1]的不仅i在变化,len(self.f[n])也在不断变化,也就是说不能保证“迈的步伐是上次的一半”。
这可能不是什么大错误,大家也不会犯这种错误,可是这个错误花了笔者好长时间才找到,心痛,,,,,,,,,
四:同时因为self.f中没有根节点的信息,即没有self.f[3],所以当我要求LCA(3,8)等的时候在用f的时候就会出错,所以针对这一特殊情况我们直接判断一下要求的的两个节点中是否有根节点,如果有的话直接返回根节点就可以来(因为这种情况的LCA就是根节点),对应的代码部分就是:
#因为 self.f中没有根节点,所以这里判断一下,如果其中一个是根节点,那么其LCA必是根节点,直接返回即可
if m==root or n==root:
return root