使用遗传算法解决中国TSP问题
遗传算法基本流程:
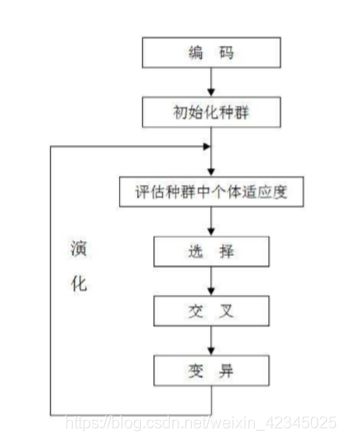
编码:即不同的城市 0-33(34个城市)
初始化种群:要产生较好的初始化结果,所以我采用的是先随机选择开始点,再选择与这个点最近的点作为下一个点(为保证初始化的多样性,最近的点由十余次搜索以内产生,进行十步以上搜索时有概率中止搜索操作)
python代码:
for i in range(INDINUM):
init=[]
allcity=list(allcities)
add=allcity[int(citynum*random())]
init.append(add)
allcity.remove(add)
for i in range(citynum-1):
mindist=10000
add=-1
findtime=0
for city in allcity:
dist=dist2(x[city],x[init[-1]],y[city],y[init[-1]])
if dist(citynum//3) and random()<0.1:
break
init.append(add)
allcity.remove(add)
m.append(init) 评估适应度:对距离取倒数,为了增加优秀个体的优势,又减去了一个常数
python代码:
def dist2(x1,x2,y1,y2):
return ((x1-x2)**2)+((y1-y2)**2)
def evaluate(m,x,y):
sums=sqrt(dist2(x[m[0]],x[m[-1]],y[m[0]],y[m[-1]]))
size=len(m)-1
for ii in range(size):
sums+=sqrt(dist2(x[m[ii]],x[m[ii+1]],y[m[ii]],y[m[ii+1]]))
score=(10000/sums)-40#increase weight of good ones
if score<0:
score=0.1
return score选择:根据适应度加权平均选择
PYTHON代码:
preserve=[(evas/sum(eva)) for evas in eva]
#preserve
new=[]
new.append(list(m[eva.index(max(eva))]))
for i in range(INDINUM-2):
point=random()
for ii in range(INDINUM):
point-=preserve[ii]
if point<0:
new.append(list(m[ii]))
break
new.append(best)
m=deepcopy(new) 交叉:A与B交叉:以A片段插入B为例:先从B中去除掉片段(除第一个)的元素,再从片段首的位置插入B
#cross
for i in range(INDINUM//2):
crosspart=[]
if random()变异:交换操作,迭代达到一定次数后增加变异的概率
#mutation(exchange)
for i in range(INDINUM):
if random()rank0:
m[i][a],m[i][b]=m[i][b],m[i][a] 经个人实验,个体数量选择500-2000为宜,相应迭代次数约为800-400,交叉概率设为0.6后期0.3,变异概率设为0.1后期0.6
实验数据为中国34个城市的经纬度数据
with open('data.txt','r') as fp:
for line in fp.readlines():
name.append(line.split(',')[0])
x.append(float(line.split(',')[1]))
y.append(float(line.split(',')[2].strip()))较好的一次实验结果:
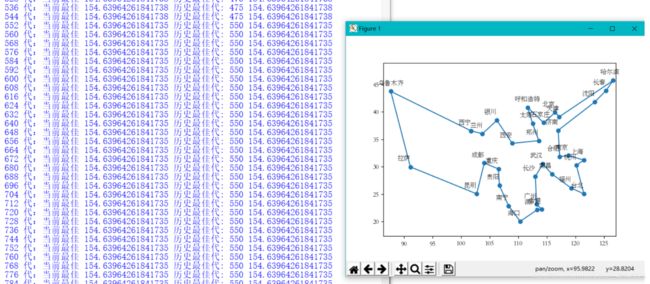
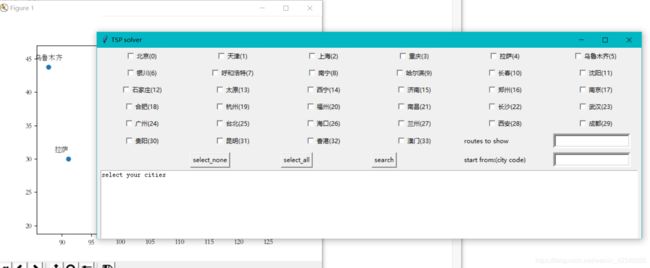
实验二为程序的城市选择以及可视化操作,个人使用tkinter进行gui编写,matplotlib进行可视化输出