JUC(三)
目录
- 同步队列
- 池化技术和线程池的使用
- 线程池的三大方法
- 线程池的七大参数
- 参数描述
- 手动创建线程池
- 四大拒绝策略
- CPU密集型和IO密集型(调优)
- 四大函数式接口
- `Stream`流式计算
- ForkJoin详解
- `ForkJoin`使用
- 求和计算的任务
- 异步回调
- 无返回值的异步执行
- 有返回值的异步回调
- 调整线程池大小
- JMM
- 内存交互操作
- 复现问题
- volatile可见性和非原子性验证
- 可见性验证
- 不保证原子性验证
- 禁止指令重排序
- 内存屏障
- Java 关键字 volatile 与 synchronized 作用与区别?
同步队列
没有容量,进去一个元素,必须等待取出来之后,才能再往里添加一个元素!
put添加元素,take取出元素
同步队列与其他的BlockingQueue不一样,SynchronousQueue不存储元素,put了一个元素,必须从队里先take取出来,否则不能put进去元素。
实例:
public class Testtb {
public static void main(String[] args) {
BlockingQueue blockingQueue = new SynchronousQueue<>();
new Thread(()->{
try {
System.out.println(Thread.currentThread().getName()+" put 1");
blockingQueue.put("1");
System.out.println(Thread.currentThread().getName()+" put 2");
blockingQueue.put("2");
System.out.println(Thread.currentThread().getName()+" put 3");
blockingQueue.put("3");
} catch (InterruptedException e) {
e.printStackTrace();
}
},"t1").start();
new Thread(()->{
try {
TimeUnit.SECONDS.sleep(3);
System.out.println(Thread.currentThread().getName()+"==>"+blockingQueue.take());
TimeUnit.SECONDS.sleep(3);
System.out.println(Thread.currentThread().getName()+"==>"+blockingQueue.take());
TimeUnit.SECONDS.sleep(3);
System.out.println(Thread.currentThread().getName()+"==>"+blockingQueue.take());
} catch (InterruptedException e) {
e.printStackTrace();
}
},"t2").start();
}
}
池化技术和线程池的使用
程序的运行:本质就是占用系统的资源,优化资源的使用=》池化技术
池化技术的应用:线程池,jdbc连接池,内存池,对象池等等。创建,销毁非常消耗资源。池化技术:事先准备好一些资源,需要用,直接拿,用完,放回池子。
线程池的好处:
1.降低资源的消耗
2.提高响应的速度
3.方便管理 总结:线程复用,可以控制最大并发数,管理线程
线程池的三大方法
Executors工具类 3大方法:
Executors.newSingleThreadExecutor():容量为一的线程池
Executors.newFixedThreadPool(5):创建一个固定容量的线程池的
Executors.newCachedThreadPool():创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
public class PoolTest {
public static void main(String[] args) {
// ExecutorService executorService = Executors.newSingleThreadExecutor();
// ExecutorService executorService = Executors.newFixedThreadPool(5);
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < 10; i++) {
//使用线程池之后,使用线程池来创建线程
executorService.execute(()->{
System.out.println(Thread.currentThread().getName()+" ok");
});
}
//关闭线程池
executorService.shutdown();
}
}
线程池的七大参数
源码分析:
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue()));
}
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue());
}
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue());
}
本质:new ThreadPoolExecutor()
//7大参数
public ThreadPoolExecutor(int corePoolSize,//核心线程池大小
int maximumPoolSize, //最大核心线程池大小
long keepAliveTime,//超时了,没调用就会释放
TimeUnit unit,//超时单位
BlockingQueue workQueue,//阻塞队列
ThreadFactory threadFactory,//线程工厂:创建线程的,一般不用动
RejectedExecutionHandler handler //拒绝策略
) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}

参数描述
1,2窗口是一直开放的,345平时是关的,人多的时候,345窗口开放,如果人多到候客区也满了,就拒绝客人进入。

超时释放:

手动创建线程池
线程池最大承载:阻塞队列容量+最大线程数
常用api:
1) void execute(Runnable command) :执行任务/命令,没有返回值,一般用来执行Runnable
2) Callable
3)shutdown():不会立即终止线程池,而是要等所有任务缓存队列中的任务都执行完后才终止,但再也不会接受新的任务
4)shutdownNow():立即终止线程池,并尝试打断正在执行的任务,并且清空任务缓存队列,返回尚未执行的任务
线程初始化:默认情况下,创建线程池之后,线程池中是没有线程的,需要提交任务之后才会创建线程。在实际中如果需要线程池创建之后立即创建线程,可以通过以下两个方法办到:
prestartCoreThread():初始化一个核心线程;prestartAllCoreThreads():初始化所有核心线程
具体的原理:
简单说就是执行execute()方法的时候(submit底层也是用的execute)
- 如果当前线程池中的线程数目小于
corePoolSize,则每来一个任务,就会创建一个线程去执行这个任务同时将这个线程放到一个工作集HashSet中保存起来;(HashSet可以自动消除重复的数据,确保不会出现单个线程有多个entry,并且保持高效率。) - 如果当前线程池中的线程数目
>=corePoolSize,则每来一个任务,会先尝试将其添加到任务缓存队列当中,若添加成功,则该任务会等待空闲线程将其取出去执行;若添加失败,意味着阻塞队列已经满了,则会尝试创建新的线程去执行这个任务; - 如果当前线程池中的线程数目达到
maximumPoolSize,则会采取任务拒绝策略进行处理; - 如果线程池中的线程数量大于
corePoolSize时,如果某线程空闲时间超过keepAliveTime,线程将被终止,直至线程池中的线程数目不大于corePoolSize;如果允许为核心池中的线程设置存活时间,那么核心池中的线程空闲时间超过keepAliveTime,线程也会被终止。
https://blog.csdn.net/weixin_28760063/article/details/81266152
https://www.cnblogs.com/a8457013/p/7819044.html;
public class PoolTest {
public static void main(String[] args) {
//自定义线程池(工作中用这种方式)
ExecutorService executorService = new ThreadPoolExecutor(
2,
5,
3,
TimeUnit.SECONDS,
new LinkedBlockingQueue(3),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy()//线程用完了,阻塞队列也满了,就不处理新的请求并抛出异常
);
//最大承载:队列+最大线程数
for (int i = 1; i <=9; i++) {
//使用线程池之后,使用线程池来创建线程
executorService.execute(()->{
System.out.println(Thread.currentThread().getName()+" ok");
});
}
//关闭线程池
executorService.shutdown();
}
}
i=5时,只有两条线程处理,因为core能处理两个请求,阻塞队列能装下3个请求,并没有触发最大并发 pool-1-thread-2 ok pool-1-thread-2 ok pool-1-thread-2 ok pool-1-thread-1 ok pool-1-thread-2 ok i=6时,两条核心线程处理两请求,阻塞队列装3请求,但是还多一条,触发最大并发,加多一条线程thread-3 同理i=7时,多加两条线程thread-3,thread-4 i=8时,多加了三条线程thread-3,thread-4,thread-5 pool-1-thread-1 ok pool-1-thread-3 ok pool-1-thread-2 ok pool-1-thread-1 ok pool-1-thread-3 ok pool-1-thread-2 ok i=9时,超出了当前线程池的最大承载量,抛出异常:RejectedExecutionException
四大拒绝策略
new ThreadPoolExecutor.AbortPolicy():线程用完了,阻塞队列也满了,就不处理新的请求并抛出异常。默认策略
new ThreadPoolExecutor.CallerRunsPolicy():“调用者运行”一种调节机制,该策略既不会抛弃任务,也不会抛出异常,而是将任务回馈至发起方。比如main线程,让main线程去执行任务。
new ThreadPoolExecutor.DiscardPolicy():队列满了,丢掉任务,不会抛出异常
new ThreadPoolExecutor.DiscardOldestPolicy():队列满了,尝试去和最早的竞争,竞争失败就抛弃任务,也不会抛出异常
CPU密集型和IO密集型(调优)
大量网络,文件操作就是 io 密集型
大量纯计算就是 CPU 密集型
最大线程到底如何定义?
1.CPU密集型:cpu的核数作为最大线程数,可以保持cpu的效率最高。
获取用户的cpu核数:Runtime.getRuntime().availableProcessors()
2.IO密集型:判断程序中十分耗IO的线程数,大于这个线程数即可,一般是这个线程数的两倍。
四大函数式接口
泛型,枚举,反射
新时代程序员要掌握:lamdba表达式,函数式编程,函数式接口,Stream流式计算。
函数式接口:只有一个方法的接口
@FunctionalInterface
public interface Runnable {
public abstract void run();
}
//超级多FunctionalInterface
//简化编程模型,在新版本的框架底层大量应用
//foreach(消费者类的函数式接口)

https://blog.csdn.net/weixin_42412601/article/details/100943585
Stream流式计算
集合只管存储,计算交给流。
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User implements Comparable{
private int id;
private String name;
private int age;
@Override
public int compareTo(User user) {
// 1、比较者大于被比较者(也就是compareTo方法里面的对象),那么返回正整数
// 2、比较者等于被比较者,那么返回0
// 3、比较者小于被比较者,那么返回负整数
System.out.println(this.name.compareTo(user.name));
return this.name.compareTo(user.name)==0? 0:this.name.compareTo(user.name);
}
}
/**
* 筛选:
* 1.id是偶数的
* 2.年龄大于23的
* 3.用户名转为大写字母
* 4.用户名字母倒叙排序
* 5.只输出一个用户
*/
public class TestStream {
public static void main(String[] args) {
User u1=new User(1, "a",21 );
User u2=new User(2, "b",22 );
User u3=new User(3, "c",23 );
User u4=new User(4, "d",24 );
User u5=new User(6, "e",25 );
List users = Arrays.asList(u1, u2, u3, u4, u5);
//用到了lamdba表达式,链式编程,函数式接口,Stream流计算
users.stream()
.filter(user->user.getId()%2==0)
.filter(user -> user.getAge()>23)
.map(user->{
String s = user.getName().toUpperCase();
user.setName(s);
return user;
}).sorted((uu1,uu2)->{return uu2.compareTo(uu1);})
.limit(1)
.forEach( System.out::println);
}
}
结果:
-1
User(id=6, name=E, age=25)
ForkJoin详解
ForkJoin:并行执行任务,提高效率。把大任务拆分成子任务
ForkJoin是由JDK1.7后提供多线并发处理框架。ForkJoin的框架的基本思想是分而治之。什么是分而治之?分而治之就是将一个复杂的计算(大任务),按照设定的阈值进行分解成多个计算(子任务),然后将各个计算结果进行汇总。相应的ForkJoin将复杂的计算当做一个任务。而分解的多个计算则是当做一个子任务。

ForkJoin特点:工作窃取
ForkJoin里面维护的都是双端队列

Fork/Join采用“工作窃取模式”,当执行新的任务时他可以将其拆分成更小的任务执行,并将小任务加到线程队列中,然后再从一个随即线程中偷一个并把它加入自己的队列中。
就比如两个CPU上有不同的任务,这时候A已经执行完,B还有任务等待执行,这时候A就会将B队尾的任务偷过来,加入自己的队列中,对于传统的线程,ForkJoin更有效的利用的CPU资源!
ForkJoin使用
三大核心组件:
ForkJoinPool(线程池实现了接口ExecutorService)、
ForkJoinTask(任务)
ForkJoinWorkerThread(工作线程),
外加WorkQueue(任务队列)
ForkJoinPool:ExecutorService的实现类,负责工作线程的管理、任务队列的维护,以及控制整个任务调度流程。- 主要工作:
- 接受外部任务的提交(外部调用
ForkJoinPool的invoke/execute/submit方法提交任务);- 通过
invoke方法提交的任务,调用线程直到任务执行完成才会返回,也就是说这是一个同步方法,且有返回结果; - 通过
execute方法提交的任务,调用线程会立即返回,也就是说这是一个异步方法,且没有返回结果; - 通过
submit方法提交的任务,调用线程会立即返回,也就是说这是一个异步方法,且有返回结果(返回Future实现类,可以 通过get获取结果)
- 通过
- 接受
ForkJoinTask自身fork出的子任务的提交; - 任务队列数组
(WorkQueue[])的初始化和管理; - 工作线程(
Worker)的创建/管理。
- 接受外部任务的提交(外部调用
- 创建方式:
- 通过3种构造器的任意一种进行构造(new)
- 主要工作:
/**
* @param parallelism 并行级别, 默认为CPU核心数
* @param factory 工作线程工厂
* @param handler 异常处理器
* @param mode 调度模式: true表示FIFO_QUEUE; false表示LIFO_QUEUE
* @param workerNamePrefix 工作线程的名称前缀
*/
private ForkJoinPool(int parallelism, ForkJoinWorkerThreadFactory factory, UncaughtExceptionHandler handler,
int mode, String workerNamePrefix) {
this.workerNamePrefix = workerNamePrefix;
this.factory = factory;
this.ueh = handler;
this.config = (parallelism & SMASK) | mode;
long np = (long) (-parallelism); // offset ctl counts
this.ctl = ((np << AC_SHIFT) & AC_MASK) | ((np << TC_SHIFT) & TC_MASK);
}
- 通过
ForkJoinPool.commonPool()静态方法构造。
JDK8以后,ForkJoinPool又提供了一个静态方法commonPool(),这个方法返回一个ForkJoinPool内部声明的静态ForkJoinPool实例,
主要是为了简化线程池的构建,这个ForkJoinPool实例可以满足大多数的使用场景
public static ForkJoinPool commonPool() {
// assert common != null : "static init error";
return common;
}
ForkJoinTask:Future接口的实现类,fork是其核心方法,用于分解任务并异步执行;而join方法在任务结果计算完毕之后才会运行,用来合并或返回计算结果;

重写compute方法一般需要遵循这个规则来写:
if(任务足够小){
直接执行任务;
如果有结果,return结果;
}else{
拆分为2个子任务;
分别执行子任务的fork方法;
执行子任务的join方法;
如果有结果,return合并结果;
}
ForkJoinWorkerThread:Thread的子类,作为线程池中的工作线程(Worker)执行任务;WorkQueue:任务队列,用于保存任务;
求和计算的任务
1.如何使用forkjoinPool 通过它执行
2.计算任务forkjoinPool.execute(ForkJoinTask task)
3.计算类要继承 ForkJoinTask
任务:
public class FkTest extends RecursiveTask {
private Long start;
private Long end;
//临界值
private Long temp=10000L;
public FkTest(Long start, Long end) {
this.start = start;
this.end = end;
}
//计算方法,递归执行
@Override
protected Long compute() {
if ((end-start) 测试:
public class FTest {
static final int MAX_CAP = 0x7fff; // max #workers - 1
public static void main(String[] args) throws ExecutionException, InterruptedException {
// sum=500000000500000000 时间:490
test1();
// sum=500000000500000000 时间:314
test2();
// sum=500000000500000000 时间:256
test3();
}
//普通加法计算
public static void test1(){
long sum=0l;
long start = System.currentTimeMillis();
for (long i = 1l; i <=10_0000_0000; i++) {
sum+=i;
}
long end = System.currentTimeMillis();
System.out.println("sum="+sum+" 时间:"+(end-start));
}
//使用ForkJoin
public static void test2() throws ExecutionException, InterruptedException {
long start = System.currentTimeMillis();
ForkJoinPool forkJoinPool=new ForkJoinPool();
ForkJoinTask task = new FkTest(0L, 10_0000_0000L);
ForkJoinTask submit = forkJoinPool.submit(task);//提交任务
Long aLong = submit.get();//获取返回值 forkJoinPool.invoke(task )也可以
Long end = System.currentTimeMillis();
System.out.println("sum="+aLong+" 时间:"+(end-start));
}
//Stream并行流 Stream API可以声明性的通过parallel()与sequential()在并行流与串行流中随意切换
public static void test3() throws ExecutionException, InterruptedException {
long start = System.currentTimeMillis();
long sum = LongStream.rangeClosed(0L, 10_0000_0000L).parallel().reduce(0, Long::sum);
long end = System.currentTimeMillis();
System.out.println("sum="+sum+" 时间:"+(end-start));
}
}
https://blog.csdn.net/codingtu/article/details/88729498
https://www.cnblogs.com/coloz/p/11167883.html
异步回调
https://cloud.tencent.com/developer/article/1453048
https://javadoop.com/post/completable-future
https://www.cnblogs.com/xinde123/p/10928091.html
https://segmentfault.com/a/1190000019571918
在java8以前,我们使用java的多线程编程,一般是通过Runnable中的run方法来完成,这种方式,有个很明显的缺点,就是,没有返回值,这时候,大家可能会去尝试使用Callable中的call方法,然后用Future返回结果,如下:
public static void main(String[] args) throws Exception {
ExecutorService executor = Executors.newSingleThreadExecutor();
Future stringFuture = executor.submit(new Callable() {
@Override
public String call() throws Exception {
Thread.sleep(2000);
return "async thread";
}
});
Thread.sleep(1000);
System.out.println("main thread");
System.out.println(stringFuture.get());
}
通过观察控制台,我们发现先打印 main thread ,一秒后打印 async thread,似乎能满足我们的需求,但仔细想我们发现一个问题,当调用future的get()方法时,当前主线程是堵塞的,这好像并不是我们想看到的
Future:设计的初衷,对将来的某个事件的结果进行建模.
异步调用CompletableFuture.
异步执行
成功回调
失败回调
无返回值的异步执行
join()和get()方法都是用来获取CompletableFuture异步之后的返回值
1.join()方法抛出的是uncheck异常(即未经检查的异常),不会强制开发者抛出,
会将异常包装成CompletionException异常,CancellationException异常,
但是本质原因还是代码内存在的真正的异常。
2.get()方法抛出的是经过检查的异常,ExecutionException, InterruptedException
需要用户手动处理(抛出或者 try catch)
public class FutureDemo01 {
public static void main(String[] args) throws ExecutionException, InterruptedException {
CompletableFuture.runAsync(()->{
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+"异步执行!!");
});
System.out.println("1111111");
//异步执行要执行至少一秒,主线程不能提前结束
//不然看不到异步执行的结果
Thread.sleep(2000);
System.out.println("结束!!");
}
}
有返回值的异步回调
任务执行完,会执行会自动执行回调函数,比如:thenApply,whenComplete
//有返回值的异步回调
CompletableFuture.supplyAsync(() -> {
System.out.println(Thread.currentThread().getName() + "异步执行!!");
int i=10/0;
return 1024;
//t 正常的返回结果 u 异常时的返回结果
}).whenComplete((t, u) -> {
System.out.println("t: " + t);
System.out.println("u: " + u);
}).exceptionally(e -> {
System.out.println(e.getMessage());
return 233;
});
或者
// .thenApply((t) -> {
// System.out.println("t: " + t);
// return t;
// }).exceptionally(e -> {
// System.out.println(e.getMessage());
// return "error";
// });
调整线程池大小
https://blog.csdn.net/u011381576/article/details/80013146
设置线程池的大小规则是
如果服务是cpu密集型的,设置为电脑的核数
如果服务是io密集型的,设置为电脑的核数*2
public class FutureDemo01 {
static Executor executor = Executors.newFixedThreadPool(8, new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
Thread thread = new Thread(r);
thread.setDaemon(true);
return thread;
}
});
public static void main(String[] args) throws ExecutionException, InterruptedException {
CompletableFuture.runAsync(()->{
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+"异步执行!!");
},executor);
System.out.println("1111111");
//异步执行要执行至少一秒,主线程不能提前结束
//不然看不到异步执行的结果
Thread.sleep(2000);
System.out.println("结束!!");
}
}
JMM
Volatile是虚拟机提供的轻量级的同步机制
1.保证可见性
2.不保证原子性
3.禁止指令重排序
Volatile是怎样保证可见性的?
JMM:java内存模型。不存在的东西,概念,约定,规定了内存主要划分为主内存和工作内存两种。主内存对应的是Java堆中的对象实例部分,工作内存对应的是栈中的部分区域,从更底层的来说,主内存对应的是硬件的物理内存,工作内存对应的是寄存器和高速缓存。
关于JMM的一些同步约定:
1.线程解锁前,必须把共享变量立刻刷回去

2.线程加锁前,必须读取主存中的最新值到工作内存中

3.加锁和解锁是同一把锁
内存交互操作
内存交互操作有8种,虚拟机实现必须保证每一个操作都是原子的,不可在分的(对于double和long类型的变量来说,load、store、read和write操作在某些平台上允许例外)
- lock (锁定):作用于主内存的变量,把一个变量标识为线程独占状态
- unlock (解锁):作用于主内存的变量,它把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定
- read (读取):作用于主内存变量,它把一个变量的值从主内存传输到线程的工作内存中,以便随后的load动作使用
- load (载入):作用于工作内存的变量,它把read操作从主存中变量放入工作内存中
- use (使用):作用于工作内存中的变量,它把工作内存中的变量传输给执行引擎,每当虚拟机遇到一个需要使用到变量的值,就会使用到这个指令
- assign (赋值):作用于工作内存中的变量,它把一个从执行引擎中接受到的值放入工作内存的变量副本中
- store (存储):作用于主内存中的变量,它把一个从工作内存中一个变量的值传送到主内存中,以便后续的write使用
- write (写入):作用于主内存中的变量,它把store操作从工作内存中得到的变量的值放入主内存的变量中
JMM对这八种指令的使用,制定了如下规则:
- 不允许read和load、store和write操作之一单独出现。即使用了read必须load,使用了store必须write
- 不允许线程丢弃他最近的assign操作,即工作变量的数据改变了之后,必须告知主存
- 不允许一个线程将没有assign的数据从工作内存同步回主内存
- 一个新的变量必须在主内存中诞生,不允许工作内存直接使用一个未被初始化的变量。就是怼变量实施use、store操作之前,必须经过assign和load操作
- 一个变量同一时间只有一个线程能对其进行lock。多次lock后,必须执行相同次数的unlock才能解锁
- 如果对一个变量进行lock操作,会清空所有工作内存中此变量的值,在执行引擎使用这个变量前,必须重新load或assign操作初始化变量的值
- 如果一个变量没有被lock,就不能对其进行unlock操作。也不能unlock一个被其他线程锁住的变量
- 对一个变量进行unlock操作之前,必须把此变量同步回主内存
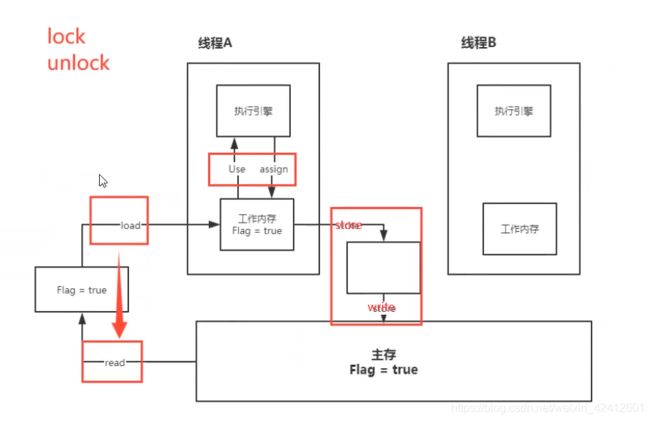

其实这个就是多线程出现线程不安全的原因。
复现问题
public class VolatileDemo01 {
//共享资源
private static int num=0;
//main线程
public static void main(String[] args) {
new Thread(()->{
while (num==0){
}
},"A").start();
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
num=1;
System.out.println(num);
}
}
结果:1
打印出1后,程序一直在运行,共享变量已经改成了1,但是A线程里的num还是0 ,线程A对主内存的变化是不知道的
解决:可以使用Synchronized上锁
volatile可见性和非原子性验证
可见性验证
在上面的复现问题中,给共享资源就加上volatile关键字,线程A即可对主存中的共享资源num可见
private volatile static int num=0;
不保证原子性验证
原子性:不可分割。线程A在执行任务的时候,不能被打扰的,也不能被分割,要么同时成功,要么同时失败。
实例:理论上num为20000,实际上不会等于20000
//volatile不保证原子性
public class VolatileDemo02 {
private volatile static int num=0;
//加synchronized,肯定保证原子性
public static void add(){
num++;
}
public static void main(String[] args) {
//理论上num为20000
for (int i = 0; i <20; i++) {
new Thread(()->{
for (int i1 = 0; i1 < 1000; i1++) {
add();
}
},"A").start();
}
//默认有两个线程在执行main,gc
while(Thread.activeCount()>2){
Thread.yield();
}
//到这线20个线程一定都执行完了
System.out.println(Thread.currentThread().getName()+" "+num);
}
}
如果不使用lock和synchronized,怎么保证原子性?
num++不是一个原子性的操作。

为什么num++不是一个原子操作就会出现问题呢?
当前线程才能从主存中获取值,然后加+1,但是在写回去之前,可能已经有多个线程进行了+1操作并且已经写回到了主存,然后当前线程又把自己的值写回主存中,很明显,自己的这个值是有问题的!
使用原子类,解决原子性问题。 非常高效,这些类的底层直接和操作系统挂钩,在内存中修改值,Unsafe是一个很特殊的类。

使用原子类AtomicInteger 解决问题:
//volatile不保证原子性
public class VolatileDemo02 {
//原子类的Integer
private volatile static AtomicInteger num=new AtomicInteger();
//加synchronized,肯定保证原子性
public static void add(){
//AtomicInteger+1方法,cas
num.getAndIncrement();
}
public static void main(String[] args) {
//理论上num为20000
for (int i = 0; i <20; i++) {
new Thread(()->{
for (int i1 = 0; i1 < 1000; i1++) {
add();
}
},"A").start();
}
//默认有两个线程在执行main,gc
while(Thread.activeCount()>2){
Thread.yield();
}
//到这线20个线程一定都执行完了
System.out.println(Thread.currentThread().getName()+" "+num);
}
}
结果:
20000
原子类为什么这么高级?
synchronized可以使得多线程下,变得线程安全,但是共享资源也变得同一时刻,只能有一个线程拥有,那么我又想要并发性,我还想要线程安全,怎么办呢?使用原子类!
要实现一个网站访问量的计数器,可以通过一个Long类型的对象,并加上synchronized内置锁的方式。但是这种方式使得多线程的访问变成了串行的,同一时刻只能有一个线程可以更改long的值,那么为了能够使多线程并发的更新long的值,我们可以使用J.U.C包中的Atomic原子类。这些类的更新是原子的,不需要加锁即可实现并发的更新,并且是线程安全的。
原子类详解:https://segmentfault.com/a/1190000018363034?utm_source=tag-newest
禁止指令重排序
什么是指令重排:你写的程序,计算机并不是按照你写的顺序执行的。
源代码->编译器优化的重排->指令并行也可能会重排->内存系统也会重排->执行
处理器在进行重排的时候,会考虑数据之间的依赖性。
int x=1;//1
int y=2;//2
x=x+5;//3
y=x*x;//4
我们期望的是1234的顺序 但是执行的时候可能会变成2134或者1324
但肯定不是4123,因为4依赖于第一行代码
可能造成的结果:假设a,b,x,y为0
| 线程A | 线程B |
|---|---|
| x=a | y=b |
| b=1 | a=2 |
正常的结果:x=0,y=0;但是可能由于指令重排序
| 线程A | 线程B |
|---|---|
| b=1 | a=2 |
| x=a | y=b |
指令重排序导致的诡异结果:x=2,y=1
volatile可避免指令重排序。
内存屏障
https://blog.csdn.net/weixin_34384681/article/details/88840660
内存屏障(memory barrier) 是一个CPU指令。
作用:
1.保证特定的操作的执行顺序,禁止了指令的重排序。
2.可以保证某些变量的内存可见性(利用这些特性volatile实现的可见性)
内存屏障是怎么保证volatile的可见性和禁止了指令的重排序的?
下面是基于保守策略的JMM内存屏障插入策略:
在每个volatile写操作的前面插入一个StoreStore屏障。
在每个volatile写操作的后面插入一个StoreLoad屏障。
在每个volatile读操作的后面插入一个LoadLoad屏障。
在每个volatile读操作的后面插入一个LoadStore屏障。
volatile写插入内存屏障后生成的指令序列示意图:

volatile读插入内存屏障后生成的指令序列示意图:

例:
class VolatileBarrierExample {
int a;
volatile int v1 = 1;
volatile int v2 = 2;
void readAndWrite() {
int i = v1; //第一个volatile读
int j = v2; // 第二个volatile读
a = i + j; //普通写
v1 = i + 1; // 第一个volatile写
v2 = j * 2; //第二个 volatile写
}
… //其他方法
}
针对readAndWrite()方法,编译器在生成字节码时可以做如下的优化:有些内存屏障给省略了,优化。

Volatile的汇编码:
环境配置:https://blog.csdn.net/J080624/article/details/85318895
生成汇编码:java -XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly -Xcomp VolatileBarrierExample.java > VolatileBarrierExample.asm
得出汇编码如下:
0x000000011214bb49: mov %rdi,%rax
0x000000011214bb4c: dec %eax
0x000000011214bb4e: mov %eax,0x10(%rsi)
0x000000011214bb51: lock addl $0x0,(%rsp) ;*putfield v1
; - com.earnfish.VolatileBarrierExample::readAndWrite@21 (line 35)
0x000000011214bb56: imul %edi,%ebx
0x000000011214bb59: mov %ebx,0x14(%rsi)
0x000000011214bb5c: lock addl $0x0,(%rsp) ;*putfield v2
; - com.earnfish.VolatileBarrierExample::readAndWrite@28 (line 36)
其对应的Java代码如下:
v1 = i - 1; // 第一个volatile写
v2 = j * i; // 第二个volatile写
可见其本质是通过一个lock指令来实现的。那么lock是什么意思呢?
查询IA32手册,它的作用是使得本CPU的Cache写入了内存,该写入动作也会引起别的CPU invalidate其Cache。所以通过这样一个空操作,可让前面volatile变量的修改对其他CPU立即可见。(将当前线程的工作内存中的值写入内存,并将其他线程工作内存中的值失效)
所以,它的作用是
- 锁住主存
- 任何读必须在写完成之后再执行
- 使其它线程这个值的栈缓存失效
总结:
volatile是可以保持可见性,不能保持原子性,由于内存屏障,可以保证避免指令重排序的现象产生。
volatile内存屏障在单例模式里面使用的最多
Java 关键字 volatile 与 synchronized 作用与区别?
voliatile 保证了可见性和有序性(不保证原子性),如果一个共享变量被 volatile 关键字修饰,那么假设一个线程修改了这个共享变量后,其他线程是立马可知的。而 synchronized 提供了同步锁的概念,被 synchronized 修饰的代码段可以防止被多个线程同时执行,一个线程只有拿到 synchronized 修饰的代码段的内置锁才能执行,其他的线程只有等该线程执行完,释放该锁后才能继续竞争该锁,并在获得之后执行代码;区别就是 volatile 相比于属于 synchronized 轻量级。
volatile 保证可见性的原理是:当程序对 volatile 修饰的变量进行写操作时,即对该变量值进行修改时,JIT 编译器生成对应汇编指令时,除了会包含写的动作,还会在最后加上一行:0x01a3de24: lock addl $0X0,(%esp);
该句代码的意思是对原值加零,其中相加指令 addl 前有 lock 修饰。lock 前缀的指令在多核处理器下会引发两件事情:
- 将当前处理器缓存行的数据写回到系统内存;
- 这个写回内存的操作会使在其他
CPU里缓存了该内存地址的数据无效。
而根据缓存的一致性协议,当其他线程操作该变量值,发现内存地址无效了,就会去访问系统内存读取数据;
有序性的原理:内存屏障。它确保指令重排序时不会把其后面的指令排到内存屏障之前的位置,也不会把前面的指令排到内存屏障的后面;即在执行到内存屏障这句指令时,在它前面的操作已经全部完成;它会强制将对缓存的修改操作立即写入主存;如果是写操作,它会导致其他 CPU 中对应的缓存行无效。在使用 volatile 修饰的变量会产生内存屏障,即在执行到内存屏障这句指令时,在它前面的操作已经全部完成;它会强制将对缓存的修改操作立即写入主存。
sychronized 的实现原理:
在 JVM 中,每个对象在内存中的布局分为三块区域:对象头、实例数据和对齐填充。

- 实例变量:存放类的属性数据信息,包括父类的属性信息,如果是数组的实例部分还包括数组的长度,这部分内存按 4 字节对齐。
- 填充数据:由于虚拟机要求对象起始地址必须是 8 字节的整数倍。填充数据不是必须存在的,仅仅是为了字节对齐,这点了解即可。
对于对象头,一般而言,synchronized 使用的锁对象是存储在 Java 对象头里的,而每个对象都存在着一个 monitor 与之关联,下面为对应程序获取锁,释放锁的字节码指令:
monitorenter //进入同步方法
..........获得对象锁的程序执行代码
monitorexit //退出同步方法
monitorenter 指令指向同步代码块的开始位置,monitorexit 指令则指明同步代码块的结束位置。。当执行 monitorenter 指令时,当前线程将试图获取对象锁所对应的 monitor 的持有权,当该对象的monitor 的进入计数器为 0,那线程可以成功取得monitor,并将计数器值设置为1,取锁成功。
如果当前线程已经拥有 monitor 的持有权,那它可以重入(重入锁的概念这里不过多介绍啦)这个 monitor,重入时计数器的值也会加 1。倘若其他线程已经拥有该对象的 monitor 的所有权,那当前线程将被阻塞,直到正在执行线程执行完毕,即 monitorexit 指令被执行,执行线程将释放 monitor(锁)并设置计数器值为 0 ,其他线程将有机会持有 monitor。