Python爬虫之设置代理IP(六)
一、准备
1.1、需求
- 代理IP的使用常常出现在网页爬虫的常见中,现在的网站都有自己的反爬机制,当我们一次性过多的请求并爬取网站数据时会被目标网站识别为恶意攻击并封ip;这个时候代理ip就可以很好的解决这个问题,所以我们主要的目的是获取符合我们实际需求的代理ip
- 国内高匿代理ip网站:https://www.xicidaili.com/nn/
- 步骤:
1、爬取上述的高匿代理ip网站的信息:
2、明确我们要获取的数据内容:主要包括下列图片中的蓝色方框内的值,即ip地址、端口、类型、存活时间;在这里我们只选取存活时间大于等于5天的ip
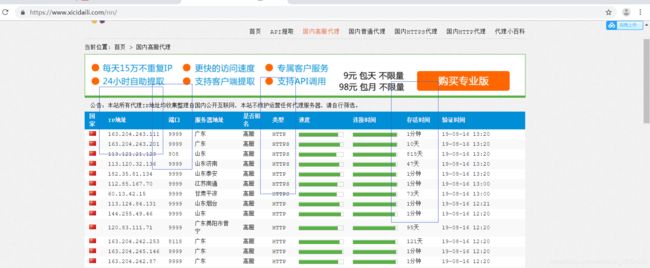
3、将获取到的数据封装成一个代理ip字典,字典key值就是上述步骤中的类型对应的值,value是ip地址:端口的格式组成;最后将单个的代理ip字典放入代理ip数组即代理池中
4、从ip代理池随机选择目标数量的代理ip
1.2、环境搭建
- 我们主要使用Python内置的requests和 BeautifulSoup模块解析并爬取https://www.xicidaili.com/nn/这个高匿代理ip网站的数据,所以本次我们环境搭建主要是安装requests和 BeautifulSoup模块
1、requests模块的安装
- 具体步骤:打开本机的Python安装目录,进入Scripts文件夹,复制此路径bin打开此路径 的cmd窗口运行命令:pip install requests
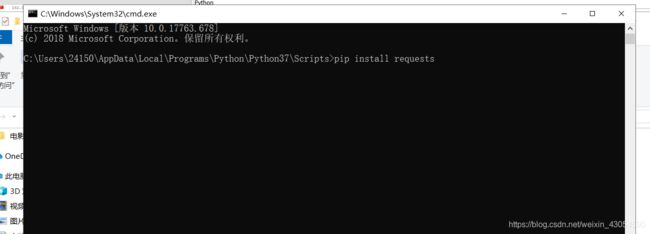
- 注意:在执行此命令之前必须先配置好Scripts文件夹的系统环境变量,否则上述命令将会报错,环境变量如何配置请自行百度。
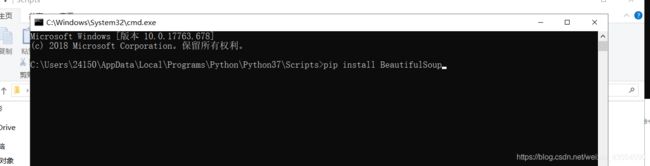
2、BeautifulSoup模块的安装
- 与requests的安装步骤一样,只不过执行的命令是:pip install BeautifulSoup
- 提高pip的下载速度请点这里
二、项目代码编写
2.1、高匿网站的代理ip字典的获取
from urllib import request
from urllib import error
from bs4 import BeautifulSoup
import requests
import re
import random
class IpProxyUtils():
# 高匿名ip网站url
ip_proxy_url = 'https://www.xicidaili.com/nn/'
traget_headers ={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"
}
page = 2 # 页数
def get_free_proxy(self):
"""
获取number数量的ip代理数组:数组元素必须为字典
"""
ip_list = []
html = requests.get(url = self.ip_proxy_url + str(self.page),headers = self.traget_headers).text
soup = BeautifulSoup(html,'lxml')
ips = soup.find_all('tr')
for i in range(1,len(ips)):
ip_info = ips[i]
tds = ip_info.find_all('td')
ip_value = tds[1].text + ':' + tds[2].text
ip_mapping = {str(tds[5].text):ip_value}
ip_list.append(ip_mapping)
return ip_list
ip_proxy_utils = IpProxyUtils()
print(ip_proxy_utils.get_free_proxy())
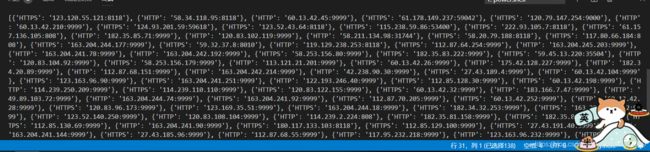
- 如上所示:我们获取了ip字典的值,字典格式为:{类型值:ip地址 + 端口},然后将其添加到ip_list中,ip_list就是前面所说的ip代理池。
- 测试结果:page就是爬取第几页的高匿ip,这里是爬取第二页
2.2、添加有效期校验条件
- 这里我们采用正则表达式来校验ip的有效期,比如有效期大于等于五天的就爬取下来
from urllib import request
from urllib import error
from bs4 import BeautifulSoup
import requests
import re
import random
class IpProxyUtils():
# 高匿名ip网站url
ip_proxy_url = 'https://www.xicidaili.com/nn/'
traget_headers ={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"
}
page = 2 # 页数
def get_free_proxy(self):
"""
获取number数量的ip代理数组:数组元素必须为字典
"""
ip_list = []
html = requests.get(url = self.ip_proxy_url + str(self.page),headers = self.traget_headers).text
soup = BeautifulSoup(html,'lxml')
ips = soup.find_all('tr')
for i in range(1,len(ips)):
ip_info = ips[i]
tds = ip_info.find_all('td')
if(self.__validate_ip(tds[8])):
ip_value = tds[1].text + ':' + tds[2].text
ip_mapping = {str(tds[5].text):ip_value}
ip_list.append(ip_mapping)
return ip_list
def __validate_ip(self,validity):
"""
校验IP有效期:筛选出有效时间大于5的ip
"""
result = re.findall('(\d*?)天',str(validity))
if len(result) == 0 or int(result[0]) < 5:
return False
else:
return True
ip_proxy_utils = IpProxyUtils()
print(ip_proxy_utils.get_free_proxy())
- 测试结果:明显相对于第一段代码爬取的数据就少了很多

2.3、添加从代理ip池里面随机获取代理ip功能
-
首先我们需要导入random模块,使用random将ip代理池随机导出指定数量的ip,会用到random的sample方法;其次我们要考虑number数量大于代理池ip数量的情况,当number大于代理池数量ip时,我们可以重复随机获取代理池里面的ip,完整代码如下:
from urllib import request from urllib import error from bs4 import BeautifulSoup import re import requests import random class IpProxyUtils(): # 高匿名ip网站url ip_proxy_url = 'https://www.xicidaili.com/nn/' ip_proxy_max_page = 1 # 最好不要大于这个数,小心ip被封,还有请求的次数不要过于频繁 traget_headers ={ "User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36" } def get_free_proxy(self,number): """ 获取number数量的ip代理数组:数组元素必须为字典 """ proxy_url_list = [] for a in range(1,self.ip_proxy_max_page+1): proxy_url = self.ip_proxy_url + str(a) proxy_url_list.append(proxy_url) ip_list = [] for proxy_url in proxy_url_list: html = requests.get(url =proxy_url,headers = self.traget_headers).text soup = BeautifulSoup(html,'lxml') ips = soup.find_all('tr') for i in range(1,len(ips)): ip_info = ips[i] tds = ip_info.find_all('td') if(self.__validate_ip(tds[8])): id_value = tds[1].text + ':' + tds[2].text ip_mapping = {str(tds[5].text):id_value} ip_list.append(ip_mapping) if number % len(ip_list) == 0: count = number // len(ip_list) else: count = number // len(ip_list) + 1 return self.__get_random_ip_list(ip_list,number,count) def __validate_ip(self,validity): """ 校验IP有效期:筛选出有效时间大于5天的ip """ result = re.findall('(\d*?)天',str(validity)) if len(result) == 0 or int(result[0]) < 5: return False else: return True def __get_random_ip_list(self,ip_list,number,count): """ 获取随机的ip数组 """ target_list = [] if count <= 1: ip_proxy_list = random.sample(ip_list,number) target_list = target_list + ip_proxy_list else: for i in range(0,count-1): # 随机获取number数量的代理ip ip_proxy_list = random.sample(ip_list,len(ip_list)) target_list = target_list + ip_proxy_list ip_proxy_list = random.sample(ip_list,number - len(ip_list) * (count - 1)) target_list = target_list + ip_proxy_list return target_list ip_proxy_utils = IpProxyUtils() print(ip_proxy_utils.get_free_proxy(5))注意:这里的ip_proxy_max_page与前面的page不一样,当ip_proxy_max_page为4时代表爬取从第一页到第三页的数据,前面的demo是page为3就只爬取第三页的数据;切记切记不要一次性爬取太多页面,否则一定会被封ip的,当爬取总页数超过5页时就会被封、亲测有效感兴趣的也可以试试。
-
测试结果:

-
当number = 1000 时:
ip_proxy_utils = IpProxyUtils() print(ip_proxy_utils.get_free_proxy(1000)) -
测试结果:一共得到了1000个ip结果
-
忠告:大家最好不要向上述这样一直请求这个高匿网站爬取ip,当你频繁请求这个网站时,哪怕你每次请求的网页数很少,它也会把你封掉的,所以个人建议先利用上面的程序把我们想要的ip都给爬取下来,然后在我们的工程代码中将爬取的结果放在一个代理池中,这是最稳妥的一种方法,比如直接这样放:
ip_list = [ {'HTTP': '120.83.108.85:9999'}, {'HTTP': '123.163.97.189:9999'}, {'HTTP': '163.204.241.162:9999'}, {'HTTP': '60.13.42.182:9999'}, {'HTTP': '163.204.242.122:9999'}, {'HTTPS': '163.204.245.191:9999'}, {'HTTPS': '163.204.242.146:9999'}, {'HTTPS': '112.80.158.105:8118'}, {'HTTPS': '120.83.103.126:808'}, {'HTTP': '163.204.245.128:9999'}, {'HTTP': '60.13.42.83:9999'}, {'HTTP': '163.204.245.168:9999'}, {'HTTPS': '163.204.240.146:9999'}, {'HTTP': '122.193.246.136:9999'}, {'HTTPS': '27.43.185.96:9999'}, {'HTTPS': '60.13.42.190:9999'}, {'HTTP': '113.121.20.215:9999'}, {'HTTPS': '182.34.33.15:9999'}, {'HTTPS': '60.13.42.61:9999'}, {'HTTPS': '120.83.99.199:9999'}, {'HTTP': '113.121.23.170:9999'}, {'HTTPS': '120.83.109.170:9999'}, {'HTTPS': '163.204.245.95:9999'}, {'HTTP': '112.87.69.110:9999'}, {'HTTP': '60.13.42.229:9999'}, {'HTTP': '61.135.155.82:443'}, {'HTTP': '163.204.241.97:9999'}, {'HTTPS': '112.85.174.44:9999'}, {'HTTP': '113.57.34.214:18118'}, {'HTTPS': '60.13.42.52:9999'}, {'HTTP': '223.241.78.55:18118'},{'HTTP': '113.121.21.236:9999'}, {'HTTP': '112.85.169.154:9999'}, {'HTTPS': '163.204.244.68:9999'}, {'HTTP': '60.13.42.40:9999'}, {'HTTPS': '222.94.146.241:808'}, {'HTTPS': '123.169.35.162:9999'}, {'HTTP': '112.85.130.199:9999'}, {'HTTP': '163.204.247.18:9999'}, {'socks4/5': '120.83.104.222:6675'}, {'HTTP': '112.85.129.187:8090'}, {'HTTP': '120.83.120.174:9999'}, {'HTTPS': '27.43.190.15:9999'}, {'HTTPS': '163.204.246.231:9999'}, {'HTTP': '163.204.245.29:9999'}, {'HTTP': '163.204.245.140:9999'}, {'HTTP': '163.204.243.169:9999'}, {'HTTP': '163.204.246.215:9999'}, {'HTTPS': '163.204.245.17:9999'}, {'HTTPS': '112.85.129.106:9999'}, {'HTTP': '163.204.246.57:9999'}, {'HTTP': '112.87.68.55:9999'}, {'HTTP': '171.12.112.222:9999'}, {'HTTPS': '163.204.244.215:9999'}, {'HTTPS': '163.204.242.240:9999'}, {'HTTPS': '115.223.92.230:8010'}, {'HTTPS': '58.253.159.71:9999'}, {'HTTP': '113.121.21.118:808'}, {'HTTPS': '113.124.86.167:9999'}, {'HTTPS': '112.87.68.188:9999'}, {'HTTP': '163.204.245.207:9999'}, {'HTTP': '1.198.73.44:9999'}, {'HTTPS': '163.204.242.97:9999'}, {'HTTP': '163.204.242.190:9999'}, {'HTTPS': '60.13.42.207:9999'}, {'HTTPS': '163.204.242.74:9999'}, {'HTTP': '112.85.128.143:9999'}, {'HTTPS': '120.79.147.254:9000'}, {'HTTP': '120.83.107.53:9999'}, {'HTTP': '163.204.240.55:9999'}, {'HTTPS': '163.204.243.75:9999'}, {'HTTP': '60.13.42.211:9999'}, {'HTTPS': '60.13.42.232:9999'}, {'HTTP': '1.197.16.177:9999'}, {'HTTPS': '60.13.42.140:9999'}, {'HTTPS': '163.204.241.184:9999'}, {'HTTP': '60.13.42.214:9999'} ] if number % len(ip_list) == 0: count = number // len(ip_list) else: count = number // len(ip_list) + 1 return self.__get_random_ip_list(LawUtils,ip_list,number,count)