(DCN)可变形卷积Deformable Convolutional Networks论文阅读笔记
文章目录
- (DCN)Deformable Convolutional Networks论文阅读笔记2017
- Abstract
- 1. Introduction
- 2. Deformable Convolutional Networks
- 2.1 Deformable Convolution
- 2.2 Deformable RoI Pooling
- 2.3 Deformable ConvNets
- 3. Understanding Deformable ConvNets
- 3.1 In Context of Related Works
- 4. Experiments
(DCN)Deformable Convolutional Networks论文阅读笔记2017
Abstract
CNN因为他们的结构,一直受限于模型的几何变换。本文中,我们引入了两种模块来增强CNN的变换建模能力,氛围是可变性卷积和可变性RoI池化。**两者都是基于以下思想:使用额外的偏移量来增强模块中空间采样位置,不使用额外的监督,来从目标任务中学习这个偏移量。**新的模块可以很容易取代现存CNN中的counterparts,很容易使用反向传播端到端训练,形成新的可变形卷积网络。后续实验验证了我们方法的表现。我们第一次发现在CNN中学习密集空间变换对于复杂的视觉任务,比如目标检测和语义分割是有效的。
1. Introduction
视觉任务中的关键挑战在于如何适应目标尺度、姿势、视点和变形中的几何变换和模型几何变换。通常来说有两种方法。第一种是建立有尽可能多变化数据的训练数据集,这通常通过增强现有数据来实现,比如仿射变换。这样可以学习到鲁棒的表示,但是通常训练很耗时,且模型复杂参数多。第二种方法是使用有变换不变性的特征和算法。这包括许多有名的技术,比如SIFT和基于滑窗的目标检测算法。
上面的方法两个缺点。第一,假设了几何变换是固定的且已知,作为先验知识来增强数据和设计特征和算法。这种假设阻止了对具有未知几何变换的新任务的泛化,因为这些几何变换没有正确建模。第二,人工设计的不变性的特征和算法可能比较难,且对于复杂的变换是不可行的,特别是变换未知的时候。
近年来,CNN在视觉任务中取得了极大的成功。然而,它仍然存在上面两个问题,它们对模型几何变换的适应能力大部分来自额外的数据增强,更复杂更大的模型的能力以及一些小的人工设计的模块(比如最大池化)。
简言之,CNN仍受到模型的大的、未知的变换的限制。**这种限制源自CNN模块的固定几何结构:卷几单元在输入特征图的固定位置进行采样;池化层以固定的比例降低空间分辨率;RoI池化层将每个RoI生成固定维度的空间向量。**缺乏处理几何变换的内部机制,会引发一些问题。例如,在同一个CNN层中所有的激活单元的感受野都是一样的。**高等级的CNN,希望将语义信息编码到空间位置中,这是不希望看到的。因为不同的位置可能会与不同尺度、形状的目标相关联,需要使用不同的尺度或感受野大小。**另外一个例子是,尽管目标检测取得了很大的进步,最近所有的方法都依赖于基于特征提取的原始的bbox,这对于不规则的目标尤其不好。
本文中,我们引入了两种新的模块,可以极大增强CNN应用几何变换的能力。第一个是可变形卷积,它对标准的卷积中的感受野中,增加了2D的offsets,使得采样的grid变形,如图1所示。这个offset通过增加额外的卷积层,从之前的特征图中学习到。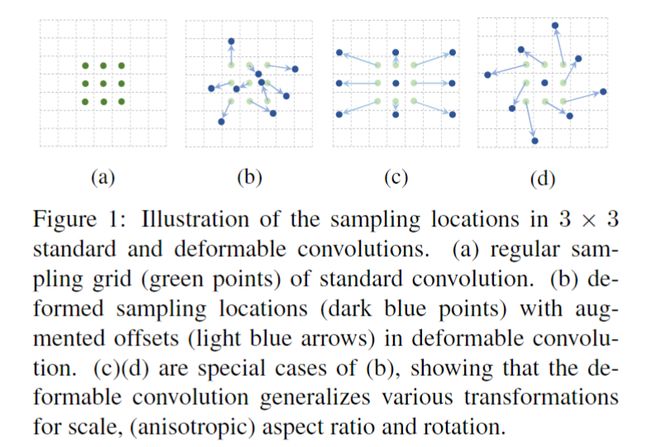
第二个是可变形RoI池化。它对于之前的RoI池化中每个bin位置增加了一个offset。相似地,offset同样由前面的特征图学习得到。
两种模块的权值都很少,它们增加了很少的参数以及计算。它们可以很容易地取代原来CNN中的对应模块,新的网络成为可变形卷积网络(DCN)。
2. Deformable Convolutional Networks
特征图和卷积是3D的,可变形卷积和可变形RoI池化都是在2D上进行操作,在每个通道上,操作一致。
2.1 Deformable Convolution
2D的卷积包含两个步骤:
- 在输入特征图x上使用规则的网格R进行采样
- 然后将采样的值使用权重w相乘,然后求和。网格R即为感受野的尺寸,比如3 * 3:
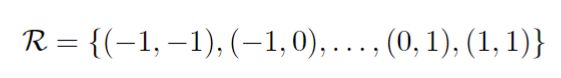
对于每个位置p0,输入的y为:
pn为R中所有的像素。
在可变形卷积中,规则的网格R使用偏移 进行增强,这样式子1就变成了:
进行增强,这样式子1就变成了:

采样的位置是不规则的pn+offset位置,因为偏置通常是一个小数,式2中的x§通常使用双线性插值:
这里p表示任意位置(即式2中的p0+pn+偏置),q枚举了特征图x中的所有整数位置,G是双线性插值核,它是二维的,可分解为两个维度的核:
这里面![]() ,式子3计算很快,因为G中只有几项不为0。(对于p点,找到距离最近的几个整数点,即包围p的格子的四个坐标,求和,再乘卷积对应的参数)
,式子3计算很快,因为G中只有几项不为0。(对于p点,找到距离最近的几个整数点,即包围p的格子的四个坐标,求和,再乘卷积对应的参数)
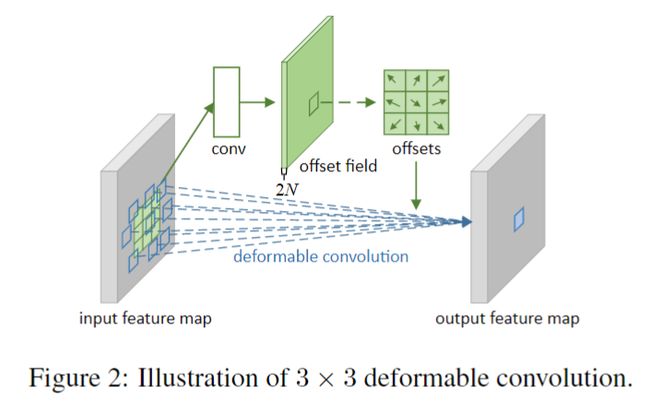
如图2中所示,==offsets是通过在特征图上增加一个卷积层来得到的。这个卷积核的尺寸与可变形卷积的尺寸一致。输出的offset fields有着与输入特征图一样的尺寸,通道维度2N与N个2D的offsets相关联。==训练中,生成offset的卷积和可变形卷积是同时学习的,学习offset的时候,是通过式子3和4进行梯度回传的。
2.2 Deformable RoI Pooling
RoI池化将任意尺寸的输入矩形转换成固定尺寸k * k的特征。
RoI Pooling
对于输入特征图x和尺寸为w * h的RoI,左上角为p0,那么对于k * k的每个bin,计算公式为:
与式子2类似,可变形的RoI池化中,对空间中每个bin的位置加了offset。这样式子5变成了:
图3展示了如何学习offsets。首先使用RoI池化对每个RoI生成k * k。然后使用一个fc层在上面生成一个归一化的offsets,然后这个offsets乘上RoI的宽和高,得到式子6中的offset, 。这里γ是一个提前定义好的尺度参量,通常设为0.1,使用归一化的offset是必需的,这样可以使得offset对RoI尺寸具有不变性。
。这里γ是一个提前定义好的尺度参量,通常设为0.1,使用归一化的offset是必需的,这样可以使得offset对RoI尺寸具有不变性。

Position-Sensitive (PS) RoI Pooling
PS-RoI pooling具体解释可见R-FCN的论文,它是全卷积的,如图4下所示。
在可变形的PS RoI池化中,式子6中唯一的改变就是x变为 x i , j x_{i,j} xi,j,即变成了位置敏感的的特征图。然而学习offset的过程是不同的,它遵循了全卷积的思想,如图4。通过卷积层生成了整个尺寸的offset fields,对每个RoI(以及每个class),与上面一样,获得归一化的offsets,然后变换成真正的offsets。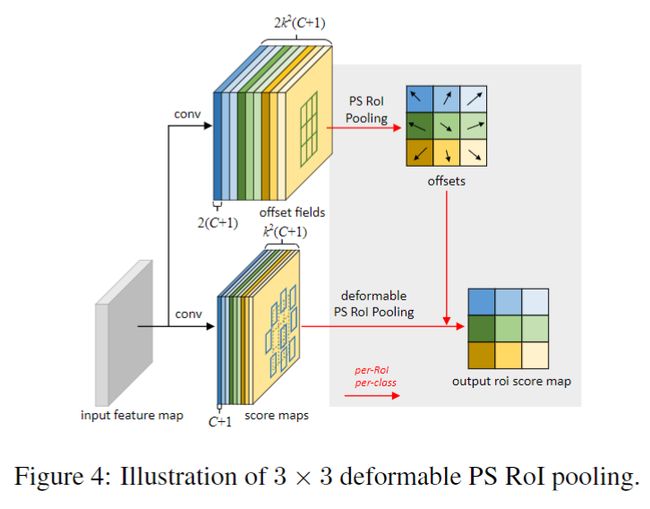
2.3 Deformable ConvNets
我们的两种可变形结构与plain版本的输入和输出尺寸一样,因此可以直接被移植到现存的CNN中来取代之前的结构。**训练时,这些添加的用于学习offset的conv和fc初始化为0。学习率设置为其它层的β倍(默认的β=1,对于Faster R-CNN,fc层β设为0.01)。**通过式子3,4的双线性插值进行反向传播。训练的结果叫做可变形卷积网络。
为了将可变形卷积整合到SOTA的CNN结构中,我们注意到这些结构由两阶段组成。首先使用FCN网络生成整张图像的特征图。然后使用较浅的针对任务的网络从特征图上生成结果。
Deformable Convolution for Feature Extraction
我们对两种backbone进行了实验,一个是ResNet-101,另一个是修正版本的Inception-ResNet,都在ImageNet上预训练过。
原来的Inception-ResNet是用来图像识别的,它有特征不对齐的问题,对dense预测可能有问题,我们修正来解决这个问题,记为“Aligned-Inception-ResNet”。
两个模型都由几个卷积块,一个平均池化,和一个针对ImageNet的1000类fc层进行分类。我们将平均池化和fc移除,增加随机初始化的1 * 1卷积来降维到1024。根据之前的经验,将到最后一层的有效步长从32像素减小到16像素来增加特征图的分辨率,在最后一个block的开始,将步长从2改为1即可。
可以有选择的对最后几个卷积层使用可变形卷积,我们实验了不同的数量,发现对最后三层使用是一个较平衡的选择,如表1所示。
Segmentation and Detection Networks
在上面生成的特征图基础上,构建针对特定任务的网络,在下面的介绍中,C表示目标的类别数。
DeepLab是SOTA的语义分割方法。它在特征图上增加1 * 1的卷积层来生成(C+1)个图名代表每个像素的分类分数,然后使用softmax来输出每个像素的概率。
Category-Aware RPN与Faster R-CNN中的RPN基本一致,只不过其中的二分类器(目标/背景)变为C+1类分类器。
Faster R-CNN是SOTA的检测方法,我们应用中,将RPN加到conv4之后。之前的实践中,将RoI池化层插入到conv4和conv5之间,对每个RoI留下了10层,这取得了很好的准确率但是计算量很大(这10层不共享计算)。我们使用了FPN中的简化设计,将RoI放在最后。然后使用两个2个1024维度的fc层,之后接bbox回归和分类。尽管这样的简化(从10层降为2fc)导致准确率下降一些,但是影响不大。
这之中的RoI池化可以更换为可变形的RoI池化。
R-FCN是另一个SOTA检测方法,同样可以将PS-RoI池化改为可变形的位置敏感的RoI池化。
3. Understanding Deformable ConvNets
本文的想法是在卷积和RoI池化中使用特定任务学习到的额外的offset,来对这些位置进行采样。
当可变形卷积堆叠的时候,这种复合变形的影响是深远的,如图5所示。
标准卷积中感受野和采样位置是固定的,在可变形卷积中,它们可以根据目标的尺度和形状进行改变。图6展示了更多的例子,表2提供了更多的证据。

可变形RoI池化的效果是类似的,如图7所示。网格结构的规则性不再存在,相反,RoI中每个bin移动到最近的目标区域。这使得定位能力增强,尤其是对不规则的目标。
3.1 In Context of Related Works
我们的工作参考了很多之前的工作,我们在这部分讲述联系与不同。
Spatial Transform Networks (STN)
STN是第一个在深度学习框架中学习空间变换的方法。它通过一个全局参数变换,比如仿射变换将特征图来扭曲变形。这样的变形花费很大且学习变换参数很难,在inverseSTN中,通过有效的变换参数回传来取代了花费代价大的特征变形。
可变形卷积那个的offset学习可以当做是STN中的一种非常轻参数的空间变换器。然而,我们没有使用卷积参数变换和特征图变形。且很容易整合到现存的CNN中,
Active Convolution
这个工作同样增强卷积中的采样位置,通过反向传播学习offsets,在图像分类任务中取得很好的效果。但是与可变形卷积相比有两个缺点。
- 一是它对所有不同的空间位置共享offset。
- 二是,偏移量offset是静态模型参数,可以按任务或按训练学习。
相反,我们的offset是动态的模型输出,在每个图像的位置是不同的,效果更好。
Effective Receptive Field
它发现卷积的感受野中,每个像素对于输出响应的贡献不是相同的。**接近中央的像素有着更大的影响。有效的感受野仅仅占理论上的感受野的一小部分,服从高斯分布。**尽管理论的感受野尺寸随着卷积层增加也线性增加,但是有效的感受野尺寸是随着卷积层数的平方差线性增加的。
这个发现表明在深度CNN的深层,感受野的尺寸不够大,这也解释了为什么空洞卷积被广泛应用。
可变形卷积可以自适应地学习感受野尺寸。
Atrous convolution
它将卷积核的步长大于1,保持原有的参数,这样采样的位置就更加稀疏。这增加了感受野的尺寸,保持了相同的计算复杂度,广泛应用于语义分割,目标检测和图像分类。
可变形卷积是空洞卷积的一种概括(generalization),在图1c中很容易看出,后续地其他对比见表3。
Deformable Part Models (DPM)
可变形RoI池化与DPN类似,因为它们都是学习目标part的空间变形,来最大化分类分数。可变形RoI池化更简单因为不需要考虑parts之间的空间关系。
DPN是一个浅模型,能力有限,然而他的相关算法可以移植到CNN上,把距离变换当作特殊的池化操作。但是它的训练不是端到端的,包括了许多启发式选择,比如成分的选择和part size的选择。相反,可变形卷积网络很深,且是端到端训练的。当多个可变形模块堆叠,网络的能力更强。
DeepID-Net
它引入了一个变形受约束的池化层,同样考虑了part变形,与我们的可变形池化想法相似,但是更复杂。它更加工程化,基于RCNN,不清楚如何应用到SOTA方法中。
Spatial manipulation in RoI pooling
空间金字塔池化使用了不同尺度上的人工池化区域,在cv领域是一种主要方法,也用在了基于深度学习的目标检测中(SPPnet)。
可变形RoI池化是第一个学习CNN池化区域的网络。尽管目前的区域有着相同的尺寸,将其扩展到多尺寸也是很容易的。
Transformation invariant features and their learning
在设计变换不变性特征上,人们又大量的研究,最著名的有SIFT和ORB。在CNN的背景下,此类研究更多。一些网络学习针对于不同变换的不变性表示,比如scattering network、 convolutional jungles和TI-pooling。一些网络只针对特定的变换。在第一部分我们分析过,这些工作针对的是已知的变换,无法处理新任务中的位置变换。相反,我们的可变形模块可从目标任务中学习。
4. Experiments
Semantic Segmentation
我们用PASCAL VOC和CityScapes,前者有20类,训练集包括10582张图像,在验证集1449张图像上评估;后者训练和验证集有2975+500张,有19类加上一个背景类。
我们使用mIoU进行评估。
训练和测试阶段,将图像resize到短边360(PASCAL)和1024(CityScapes),分别训练30k和45k迭代,前三分之二学习率0.001,后面学习率0.0001。
Object Detection
使用PASCAL VOC和COCO数据集,对于前者,在VOC2007trainval和2012trainval联合数据集上训练,在VOC2007 test进行测试。对于COCO,在120k的trainval进行训练和验证,在20k的test-dev进行测试。
评估使用标准的mAP,前者使用IoU阈值0.5和0.7,后者使用标准的 mAP@[0.5:0.95]以及[email protected]。
训练和测试阶段,将图像resize到短边600像素。对于class-aware RPN,图像采样256个RoI,对于Faster R-CNN和R-FCN,区域建议采样256和128RoI。RoI池化中为7 * 7bins。为了在VOC上进行剥离实验,我们利用预训练、固定的RPN来训练Faster R-NN和R-FCN,区域建议网络和后边不共享特征。对于COCO,使用联合训练,共享特征。在两个数据集上分别训练30k和240k,学习率变化与语义分割时一样。
Evaluation of Deformable Convolution
表1评估了使用ResNet-101作为backbone的可变形卷积的效果。当更多层使用可变形卷积,准确率持续提升,尤其对于DeepLab和class-aware RPN。当使用3层,前者的提升饱和了,对于其他,使用6层饱和了,因此其他的实验中,我们使用3层。
我们观察到在可变形卷积中学习到的offsets适配于图像的内容,为了跟好的理解可变形卷积的机理,我们对可变形卷积定义了一个尺度,叫做effective dilation,它是滤波器中所有相邻采样位置对之间距离的平均值。
我们将三个可变形层应用到R-FCN上,在VOC2007测试集。**我们将可变形卷积核分为4类,小、中、大和背景,根据GT box的标签,以及卷积核中心的位置。**表2展示了有效dilation的数据:
可以清晰地看到:
- 可变形卷积的感受野尺寸与目标尺寸相关,这表示这个变形学习到了图像中的内容。
- 背景区域的卷积核的尺寸在中等和大之间,表示对于背景区域的识别来说,需要一个相对大的感受野。
这些现象在其他的层也可以看到。
我们的默认ResNet-101在最后三个3 * 3卷积层上使用了空洞卷积(dilation2),我们继续讲dilation扩大到4、6、8,结果如表3所示:
结果表明:
- 当使用更大的dilation,准确率都上升了,这表明默认网络的感受野太小了。
- 对于不同任务,最佳的dilation不一样。
Evaluation of Deformable RoI Pooling
可变形RoI池化可以应用到Faster R-CNN和R-FCN中,如表3所示,只使用可变形池化就可以取得效果提升,尤其是在更严格的mAP0.7尺度上。当同时使用可变形卷积和可变形RoI池化的时候,效果更好。
Object Detection on COCO
表4中展示了可变形卷积网络和普通网络在COCO上的对比。我们首先使用ResNet-101进行实验,可变形的版本class-aware RPN, Faster R-CNN and R-FCN 取得了25.8%、33.1%、34.5%的mAP,比它们的plain版本相对提升了11%、13%、12%。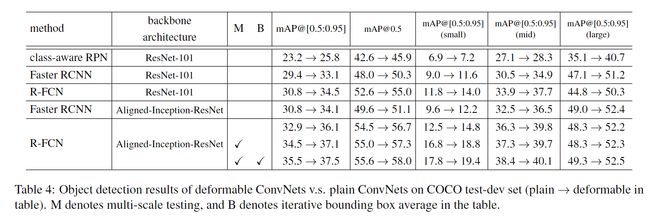
更改backbone为Aligned-Inception-ResNet之后,网络更加提升。进一步在多尺度测试下(短边尺寸为480、576、688、864、1200、1400),且使用了迭代bbox平均,R-FCN的mAP更加提升到37.5%,且可变形卷积的提升相对于这些bells and whistles来说是正交的(互补的)。
Model Complexity and Runtime
表5展示了可变形卷积网络与对应的plain版本的复杂度和运行时间对比。可变形卷积网络值增加了很少的参数和计算,这表明效果的提升是来自模型能力的增加,而不是来自参数量的提升。
