171217 逆向-HomuraVM
1625-5 王子昂 总结《2017年12月17日》 【连续第443天总结】
A. CG-CTF(HomuraVM)
B.
南邮的Re师傅们真是热爱VM啊……OTZ
这一题比WxyVM的两个要难一点,却又比asm汇编级别的解释器简单许多,感谢南邮师傅们(吼姆拉酱?ww)恰到好处的难度控制
拖入IDA,结构很清晰
将输入拷贝到一个数组中,然后初始化机器码
变换后进行check
很明显解释器就是sub_8DC,而sub_8AA则是反调试
对sub_8DC进行反编译,发现不完整

这里的JUMPOUT就是用来跳转至对应解释函数的语句
不过对机器码进行解析的部分都反编译出来了,就是每个字符-67后去dword_1048中寻找偏移值,然后以dword_1048为基准进行跳转
jmp base[a[i]-67] + base回到汇编状态进行分析各个解释函数
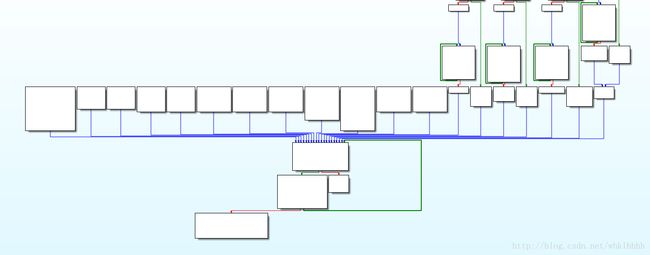
可以看到有这么多,不过还好它们的核心语句基本上就只有一两行汇编,逐个记录即可
主要变量有两个计数器a和i,分别表示读取input和机器码的下标
两个寄存器qword_202080和qword_202088,下将其称为n1和n2
简单的函数如下
93c: a += 1
962: a -= 1
988: input[a] += 1
9aa: input[a] -= 1
9cc: n1 += 1
9ee: n1 -= 1
a10: n2 = n1
a36: n2 = n1 + input[a]
a67: n2 -= (n1&input[a])*2
aa6: n2 -= 1
ac8: n2 += 1比较复杂的4个函数:
aea: if(input[a]!=0){b1d}else{af8}
af8: i++;if(k[i]==0x5d){c23}else{af8}
b1d: i++;
b31: if(input[a]!=0){b79}else{b3f}
b3f: i--;if(k[i]==0x5b){i++;c23}:else{b3f}
b79: i++;
b8d: if(n2!=0){bbd}else{b9b}
b9b: i++;if(k[i]==0x7d){c23}else{b9b}
bbd: i++;
bce: if(n2!=0){c13}else{bdc}
bdc: i--;if(k[i]==0x7b){i++;c23}else{bdc}
c13: i++;这4个函数是循环结构,通过input[a]和n2来进行判断,通过i来控制执行的语句
其中0x5d 0x5b 0x7d 0x7b这4个终止值让人比较在意,char分别是”[]{}”
看起来可能有点复杂,没关系,等会儿再继续解析
表示出现的机器码和解释函数对应关系:
# dword_1048处dump出来的偏移数组
n = [0xa67, 0xc23, 0xc23, 0xc23, 0xaa6, 0xc23, 0xc23, 0xc23, 0xc23, 0xc23, 0xa36, 0xc23, 0xc23, 0xc23, 0xc23, 0xc23, 0xc23, 0xac8, 0xc23, 0xc23, 0xc23, 0xc23, 0xc23, 0xc23, 0xaea, 0xc23, 0xb31, 0xc23, 0xc23, 0xc23, 0x9ee, 0xc23, 0xc23, 0xc23, 0xc23, 0xc23, 0xc23, 0x93c, 0xc23, 0xc23, 0xc23, 0xc23, 0x988, 0xc23, 0x962, 0xc23, 0xc23, 0x9cc, 0xc23, 0xc23, 0x9aa, 0xa10, 0xc23, 0xc23, 0xc23, 0xc23, 0xb8d, 0xc23, 0xbce]
s = "ahmoruvCMG[]{}"
for i in s:
print(i, hex(n[ord(i)-67])[2:])
可以生成一份表(第三列代码部分是另加的对应字典)

这里可以看到,[和]对应构成一个循环,{和}对应构成一个循环
以’[‘和’]’为例
当遇到’[‘时,判断input[a]是否==0,为0则直接跳到’]’后,否则运行[]内的代码
当遇到’]’时,判断input[a]是否==0,为0则继续运行后面的内容,否则返回到’[‘前
实际上就是一个while循环
这个思想挺像以前看到的BrainF@ck语言来着
观察机器码,发现只有三种循环:{aG}{mG}[ur]
这样可以针对性地翻译出它们的对应代码来降低理解难度:
(为了书写方便将input[a]简写为s[a],下同)
{mG}: s[a] += n2; n2=0
{aG}: n1 -= n2; n2=0
[ur]: n1 += s[a]; s[a]=0(其实上一步可以省略)
分析机器码,发现大量的重复部分,区别只是中间的a和r

这样翻译起来就简单很多了
(感谢出题师傅手下留情)
尝试解析重复的部分,发现n2可以被消去
解析完以后发现h代表input下标+1,因此以它作为分界线更为合适
也就是说,将不同的a和r放在代码块的中间
通过正则表达式分组出如下代码:
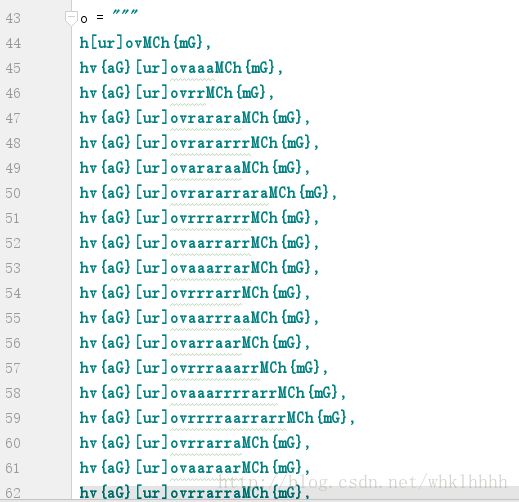
虽然第一句长的不太一样,但是解析以后发现效果其实相同
每一行翻译出的伪代码为:
a += 1
n1 = 0
n2 = 0
n1 = s[a]
# n1根据a和r改变
...
# 计算
s[a] = n1+s[a-1] - (n1&s[a-1])*2注意这里的s[a-1]是计算后的内容了
也就是说正向算法是
# x为不同行中的改变内容
f(计算前的s[a] + x,计算后的s[a-1]) = 计算后的s[a]这样就得到了递推公式
虽然计算方法有点点复杂,无法逆运算
不过数据范围都在一个比特内,因此只有256种可能,穷举即可
# 有可能会出现多解情况,已验证皆为一解,因此可以直接return
def find(x, y):
for z in range(256):
if(y == x + z - (x & z) * 2):
return z于是根据递推公式可以逆求出所有的计算前的input
for i in range(1, 34):
# 逆求值
p = find(n[i-1], n[i])
# 修正对n1的改变
offset = (o[i].count('a')-1) - (o[i].count('r')-1)
print(chr(p + offset), end='')得到flag
开头少了一位,是因为在赋值的时候
*(_DWORD *)input_q = input[strlen(input) - 1];将最后一位赋给了第一位(之后的操作全部都是从第二位开始的)
通过最后一位和第一位的值同样可以逆推出原值,直接根据格式猜也行233
另外check的地方有一个bug:
for ( j = 0; j <= 33; ++j )
{
if ( *(&v5 + j) != v42[j + 1LL] )
{
puts("GG!");
exit(0);
}
}
puts("correct!");意味着只要满足前34位值相同即可
而解释器的结束条件是机器码读取完毕,也就是说仅会对前34位进行变换
开始输入的地方也没有对长度进行校验
因此满足check的条件就是
正确flag + 任意位字符 (最后一位为’}’)
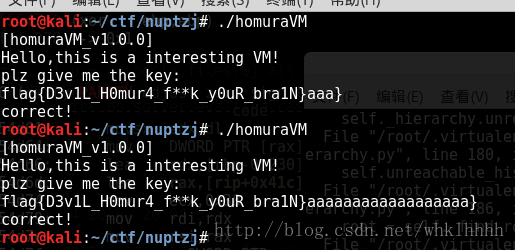
不过flag显而易见所以无伤大雅啦~
PS:
静态分析被指针、内存等等搞乱了的时候,需要动态调试来观察内存中的变化
因此动态调试还是挺有必要滴:
这个反调试函数是通过比较是否Sessionid和ppid来判断的:
v1 = getsid(v0);
result = getppid();
if ( v1 != result )
exit(0);
return result;如果是调试器开启的程序则会导致ppid和sid不等,进而退出程序
最简单的方法就是直接patch,将0x8AA的首字节改为0x3c(retn)
不清楚gdb有没有附加调试功能,以及附加能不能过这个反调方法呢~
下次挑战hctf的level2的解释器=A=
C. 明日计划
加密与解密