MySql学习笔记——DQL进阶(二)
多表查询
合并结果集、连接查询、子查询、自连接
1 合并结果集
把两个select语句的查询结果合并到一起
- 两种方式
UNION——合并时去除重复记录
UNION ALL——合并时不去除重复记录
select * from 表1 union select * from 表2;
select * from 表1 union all select * from 表2;
-- 先建个表
create table A(name varchar(10), score int);
create table B(name varchar(10), score int);
-- 插入数据
insert into A values('a',10),('b',20),('c',30);
insert into B values('a',10),('b',20),('d',40);
-- union查询
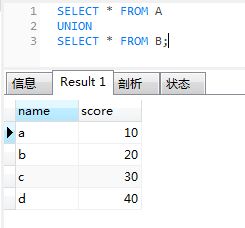
select * from A
union
select * from B;
-- union all查询
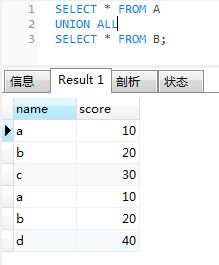
select * from A
union all
select * from B;
【注意】被合并的两个结果,列数、列类型必须相同。
2 连接查询
跨表查询,需要关联多个表进行查询;同时查询两个表,出现的就是笛卡尔集结果。
- 笛卡尔集
假设集合A={a,b},集合B={0,1,2},则两个集合的笛卡尔积为
{(a,0), (a,1), (a,2), (b,0), (b,1), (b,2)},可以扩展到多个集合的情况。
select * from stu, score;

- 查询时给表起别名
select * from stu st,score sc;
-- st表示stu表,sc表示score表
3 多表联查,如何保证数据正确
1. 在查询时要把主键和外键保持一致;
2. 主表当中的数据参照子表当中的数据;
3. 原理逐行判断,选择对应数据。
select * from stu st,score sc where st.sid = sc.sid;
-- 查看对应学号的学生信息和成绩

4 连接方式
- 分类
内连接、外连接、自然连接 - 内连接分类
等值连接、多表查询,非等值连接、自连接 - 等值连接
两个表同时出现的id号(值)才显示(连接两个表,同时查询多张表)
-- 将学号相同的学生数据连接在一起
--内连接
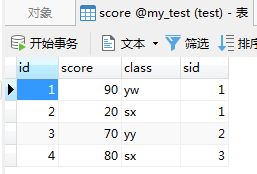
SELECT * FROM stu st INNER JOIN score sc ON st.sid = sc.sid;
-- 查询结果同(多表联查)
select * from stu st, score sc where st.sid = sc.sid;
内连接与多表联查约束主外键相同,只是写法改变;
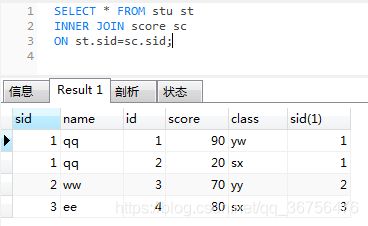
-- 补充条件连接查询,查询对应学号,成绩大于60分的男生
SELECT st.sno,st.`sname`,st.sex,sc.score FROM students st
JOIN score sc
ON st.sno = sc.sid
WHERE sc.score > 60
AND st.sex ='nan';
INNER JOIN等价于 JOIN;
ON后只写主外键;
有条件写WHERE;
还有条件加AND。
- 外连接分类
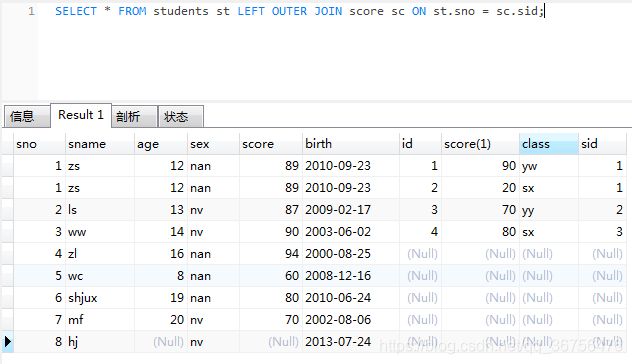
左连接,右连接,多表连接 - 左连接
把左表当中的数据全部查出,右表当中只查出满足条件的数据;
可以省略outer不写;
查询时,两个表可以不需要建立主外键约束。
查询students表中所有数据,score表中只查询满足条件的数据。
SELECT * FROM students st LEFT OUTER JOIN score sc ON st.sno = sc.sid;
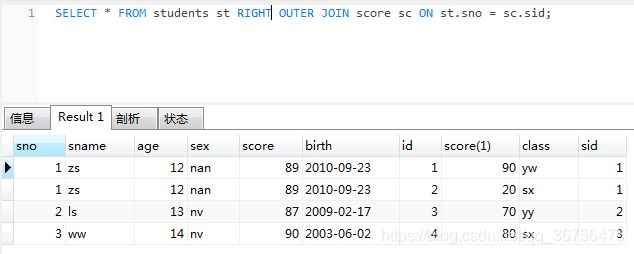
- 右连接
同理:把右表当中的数据全部查出,左表当中只查出满足条件的数据
SELECT * FROM students st RIGHT OUTER JOIN score sc ON st.sno = sc.sid;
- 多表连接
99连接法:多一个条件多一个and
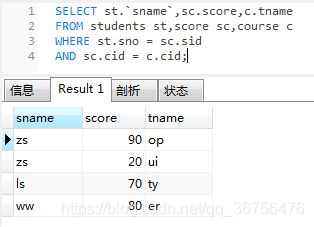
SELECT st.`sname`,sc.score,c.tname
FROM students st,score sc,course c
WHERE st.sno = sc.sid
AND sc.cid = c.cid;
内联查询法
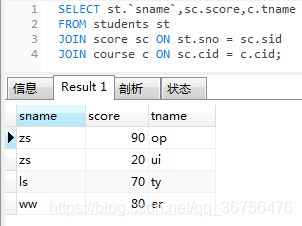
SELECT st.`sname`,sc.score,c.tname
FROM students st
JOIN score sc ON st.sno = sc.sid
JOIN course c ON sc.cid = c.cid;
- 非等值连接
-- 建表emp
create table `emp`(
`empno` int(11) not null,
`ename` varchar(255) default null,
`job` varchar(255) default null,
`mgr` varchar(255) default null,
`hiredate` date default null,
`salary` decimal(10,0) default null,
`comm` double default null,
`deptno` int(11) default null,
primary key (`empno`)
) engine = innoDB default charset = utf8;
-- 建表dept,使用comment可以在语句里加注释
create table `dept`(
`deptno` bigint(2) not null auto_increment comment '表示部门编号,有两位数字所组成',
`dname` varchar(14) default null comment '部门名称,最多由14个字符所组成',
`local` varchar(13) default null comment '部门所在的位置',
primary key (`deptno`)
) engine = innoDB auto_increment = 41 default charset = utf8;
-- 建表salgrade
create table `salgrade`(
`grade` bigint(11) not null auto_increment comment '工资等级',
`lowSalary` int(11) default null comment '此等级的最低工资',
`highSalary` int(11) default null comment '此等级的最高工资',
primary key (`grade`)
) engine = innoDB auto_increment = 6 default charset = utf8;
-- 给这三个表填上数据
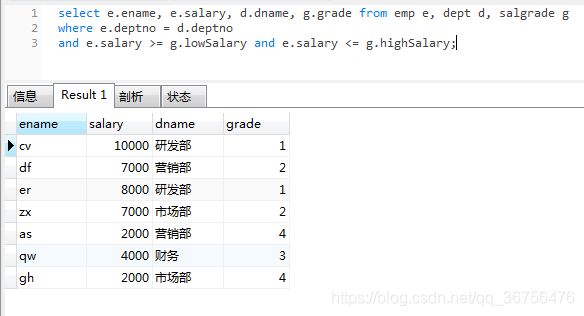
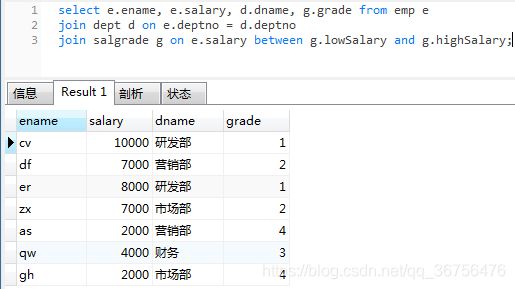
查询所有员工的姓名,工资,所在部门的名称以及工资的等级
-- 99法
select e.ename, e.salary, d.dname, g.grade
from emp e, dept d, salgrade g
where e.deptno = d.deptno
and e.salary >= g.lowSalary and e.salary <= g.highSalary;
-- 内连接法
select e.ename, e.salary, d.dname, g.grade from emp e
join dept d on e.deptno = d.deptno
join salgrade g on e.salary between g.lowSalary and g.highSalary;
- 自然连接
连接查询会产生无用笛卡尔集,使用主外键关系等式来去除它;
自然连接无需给出主外键等式,会自动找到这一等式,即不用写条件;
要求:两张连接的表中列名称和类型完全一致的列作为条件;
会去除相同的列。
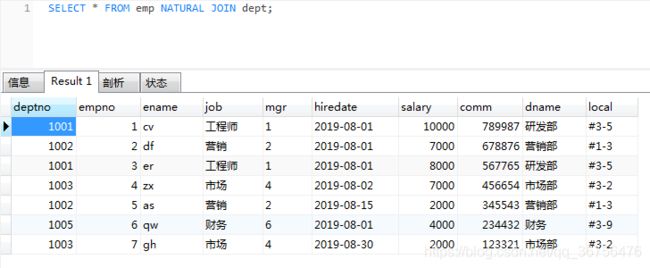
select * from emp NATURAL JOIN dept;
以共有的deptno进行连接
navicat中query builder(查询创建工具):查看约束关系
5 子查询
一个select语句中包含另一个完整的select语句,即一个查询中出现了两个或两个以上的select。
- 子查询出现的位置
where后,把select查询出的结果当做另一个select的条件值;
from后,把查询出的结果当做一个新表。
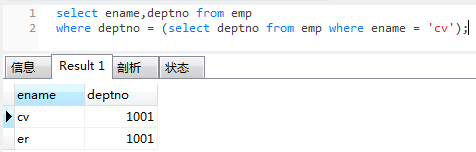
查询与cv同一个部门的员工
select ename,deptno from emp
where deptno = (select deptno from emp where ename = 'cv');
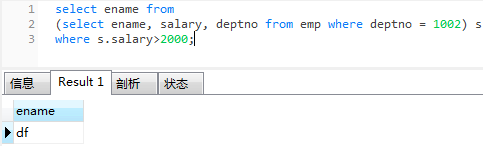
查寻部门号为1002的员工中薪资大于2000的人
select ename from
(select ename, salary, deptno from emp where deptno = 1002) s
where s.salary>2000;
-- s代指查出来的中间表
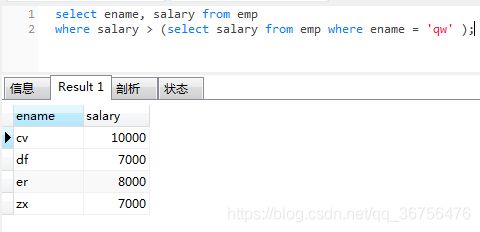
查询工资高于qw的员工
select ename, salary from emp
where salary > (select salary from emp where ename = 'qw' );
工资高于1002号部门所有人的员工信息
select ename, salary from emp
where salary > (select max(salary) from emp where deptno = 1002);

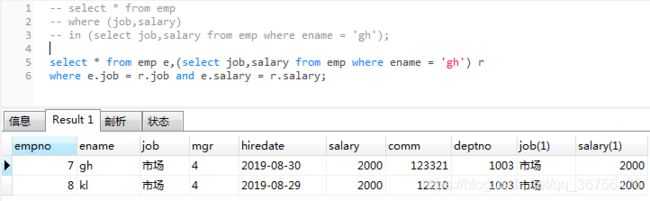
查询工作和工资与gh完全相同的员工的信息
select * from emp
where (job,salary)
in (select job,salary from emp where ename = 'gh');
-- 等同于
select * from emp e,(select job,salary from emp where ename = 'gh') r
where e.job = r.job and e.salary = r.salary;
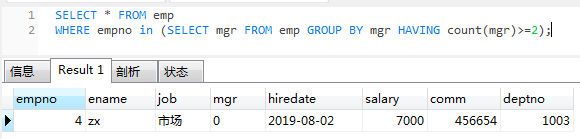
有两个及以上直接下属的员工信息
思路:以管理者编号mgr分组并显示分组信息,组内数量
-- 第一步,每个管理者管理人数
select mgr,group_concat(mgr),count(mgr) from emp group by mgr;

-- 第二步,查询(管理者编号mgr,员工编号empno)
SELECT * FROM emp
WHERE empno in (SELECT mgr FROM emp GROUP BY mgr HAVING count(mgr)>=2);
- (多表查询)查询员工编号为5的员工的名称、工资、部门名称、部门地址
SELECT e.ename,e.salary,d.dname,d.`local`
FROM emp e,dept d
WHERE e.empno = 5 and e.deptno=d.deptno;

- 自连接
自己连接自己,起别名
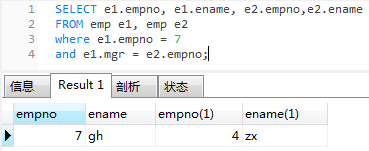
求7号员工编号、姓名、经理编号和经理姓名
SELECT e1.empno, e1.ename, e2.empno,e2.ename
FROM emp e1, emp e2
where e1.empno = 7
and e1.mgr = e2.empno;