Python爬虫:皮皮虾短视频无水印下载
引入:

皮皮虾,是一个主打轻幽默神评论的社区。我们暂且先不论他的前世今生,单凭现在的状况,在我看来,确实比某音更深得我心。
当我刷的视频太多时,我已有把视频保存下来的想法,虽然良心的官方给我们提供了保存的方式,但是下载的视频都被加上了水印和片尾,这可不是我想要的,鉴于身边同为皮友的发小问我能不能写一个程序,下载没有水印的视频,我这才想起以前学 Fiddler 抓包时,小小的研究过这是怎么回事,于是,这才有了这段代码。
这里的所有链接我都给和谐了,因为我不和谐就要和谐我的咩~
不过!这也挡不住大家 ” 求学 “ 的热情吧! /滑稽
分析及代码:
鉴于皮皮虾是手机端的app,而写出的程序可以任何人都能使用,所以入口就肯定不能放到软件上,除了直接抓包获取视频链接,还能怎么样呢?
我们随便选取一个视频点击分享后发现,我们可以直接复制视频的链接,说不定,我们可以从这里下手:
随机选取了一个链接: https://*****/s/JRjEVyT/
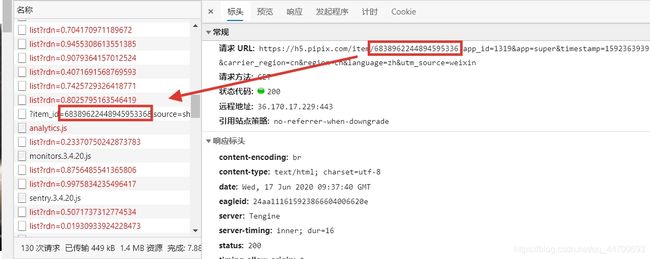
拿到链接在电脑上打开后,发现,链接变成了一个含有多个参数的长链接:
https://*****/item/6838962244894595336?app_id=1319&app=super×tamp=1592363939&carrier_region=cn®ion=cn&language=zh&utm_source=weixin
通过查看浏览器抓包我们可以获取到此次的请求信息,然后开始写出代码的前期准备:
鉴于需要 多次请求不同的链接, 所以将请求代码写成函数,方便使用。
import random
import os
import requests
proxies = ['HTTP://182.46.113.88:9999', 'HTTP://175.42.122.197:9999', 'HTTP://118.212.106.160:9999',
'HTTP://175.43.32.33:9999', 'HTTP://163.204.247.122:9999', 'HTTP://115.218.0.69:9000',
'HTTP://115.221.246.189:9999', 'HTTP://182.34.35.2:9999', 'HTTP://182.92.113.148:8118']
proxy = {'HTTP': random.choice(proxies)}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/81.0.4044.138 Safari/537.36 Edg/81.0.416.72 '
}
path = './Spider/'
if os.path.exists(path):
pass
else:
os.mkdir(path)
def request(url):
try:
r = requests.get(url, proxies=proxy, headers=headers)
r.raise_for_status()
r.encoding = 'utf-8'
return r
except:
print("链接错误,请求失败!")
我们发现在某一次请求的链接中含有与刚请求的链接相同的字段,查看预览发现返回的是 json 格式的文件。在该文件里一阵寻找,发现了一个关键的信息:origin_video_download
(这就暗示的很明显了吧,这个字段里面肯定就是用户上传的原视频了啊。)
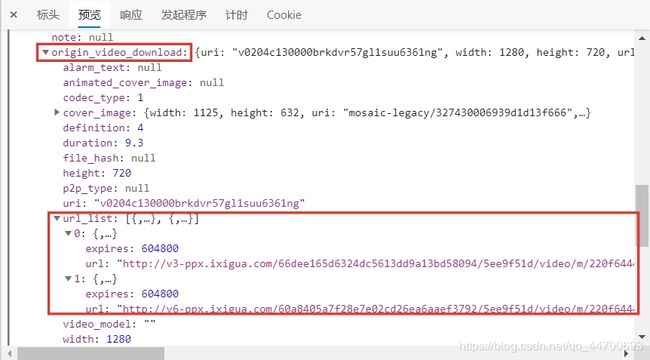
在两个链接中随便选一个打开:
是我们想要的没错了。偶不,是我们想要的视频没错了!
既然已经分析到了我们所需要的地步,那么就开始码最主要的代码:
根据两次请求的链接来获取,生成第二次的链接。
def video_info(url):
video_num = str(request(url).url).split('/')[-1].split('?')[0]
URL = 'https://****/bds/webapi/item/detail/?item_id=' + video_num + '&source=share'
r1 = request(URL)
video_name = r1.json()['data']['item']['content']
video_url = r1.json()['data']['item']['origin_video_download']['url_list'][1]['url']
video = request(video_url).content
with open(path + str(video_name) + '.mp4', 'wb') as f:
f.write(video)
既然你选择来看这篇文章,那对于 json 数据的操作,该不用我多说了吧!!
由于我选择用每个视频的配文来作为视频的保存名字,所以对于某些没有配文的视频,保存时是没有名字的,所以我有加了两行代码,用产生的随机数来作为视频的保存名字:
***略****
if video_name=='':
video_name=int(random.random()*2*1000)
***略***
最后写上主函数调用:
if __name__ == '__main__':
share_url = input('请输入分享链接:')
video_info(share_url)
print('下载完成!')
源码及运行结果:
import random
import os
import requests
proxies = ['HTTP://182.46.113.88:9999', 'HTTP://175.42.122.197:9999', 'HTTP://118.212.106.160:9999',
'HTTP://175.43.32.33:9999', 'HTTP://163.204.247.122:9999', 'HTTP://115.218.0.69:9000',
'HTTP://115.221.246.189:9999', 'HTTP://182.34.35.2:9999', 'HTTP://182.92.113.148:8118']
proxy = {'HTTP': random.choice(proxies)}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/81.0.4044.138 Safari/537.36 Edg/81.0.416.72 '
}
path = './Spider/'
if os.path.exists(path):
pass
else:
os.mkdir(path)
def request(url):
try:
r = requests.get(url, proxies=proxy, headers=headers)
r.raise_for_status()
r.encoding = 'utf-8'
return r
except:
print("链接错误,请求失败!")
def video_info(url):
video_num = str(request(url).url).split('/')[-1].split('?')[0]
URL = 'https://*****/bds/webapi/item/detail/?item_id=' + video_num + '&source=share'
r1 = request(URL)
video_name = r1.json()['data']['item']['content']
if video_name=='':
video_name=int(random.random()*2*1000)
video_url = r1.json()['data']['item']['origin_video_download']['url_list'][1]['url']
video = request(video_url).content
with open(path + str(video_name) + '.mp4', 'wb') as f:
f.write(video)
if __name__ == '__main__':
share_url = input('请输入分享链接:')
video_info(share_url)
print('下载完成!')
运行结果:
请输入分享链接:https://*****/s/JRjEVyT/
下载完成!
进程已结束,退出代码 0