三十一、电子商务分析与服务推荐
1. 数据预处理
1.2 数据预处理的流程
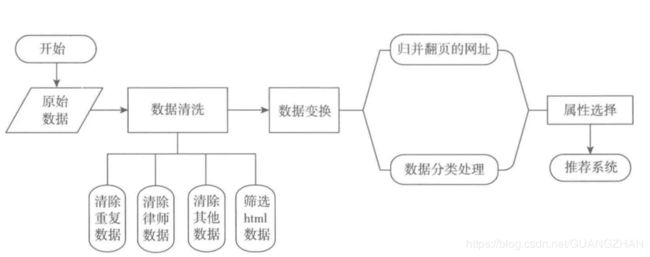
本案例在原始数据的探索分析的基础上,发现与分析目标无关或模型需要处理的数据,针对此类数据进行处理。其中涉及的数据处理方式有:
- 数据清洗
- 数据变换
- 属性归约
2. 数据清洗
2.1 数据清洗规则
-
从探索分析的过程中发现与分析目标无关的数据,归纳总结其数据满足如下规则:中间页面的网址、咨询发布成功页面、律师登录助手的页面等。将其整理成删除数据规则,下表给出了信息的结果。律师用户占了所有记录的22%左右,其他数据占比很小,大概5%左右。

-
经过上述清洗后的记录中仍然存在大量的目录网页(可理解为用户浏览信息的路径),在进入推荐系统时,这些信息的作用不大,反而会影响推荐的结果。因此需要进一步筛选以html为后缀的网页。
-
根据分析目标以及探索结果可知,咨询与知识是其主要业务来源,故筛选咨询与知识相关的记录,将此部分数据作为模型分析需要的数据。
数据清洗操作的实现
import pandas as pd
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://root:[email protected]:3306/7law?charset=utf8')
sql = pd.read_sql('all_gzdata', engine, chunksize = 10000)
for i in sql:
d = i[['realIP', 'fullURL']] #只要网址列
d = d[d['fullURL'].str.contains('\.html')].copy() #只要含有.html的网址
#保存到数据库的cleaned_gzdata表中(如果表不存在则自动创建)
d.to_sql('cleaned_gzdata', engine, index = False, if_exists = 'append')
3 数据变换
3.1 用户翻页处理
- 因此,针对这些网页需要还原其原始数据类型,处理方式为首先是被翻页的网址,然后对翻页的网址进行还原,最后针对每个用户访问的页面进行重操作。

3.2 用户翻页处理的实现
import pandas as pd
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://root:[email protected]:3306/7law?charset=utf8')
sql = pd.read_sql('cleaned_gzdata', engine, chunksize = 10000)
for i in sql: #逐块变换并去重
d = i.copy()
d['fullURL'] = d['fullURL'].str.replace('_\d{0,2}.html', '.html') #将下划线后面部分去掉,规范为标准网址
d = d.drop_duplicates() #删除重复记录
d.to_sql('changed_gzdata', engine, index = False, if_exists = 'append') #保存
3.3 网址分类
- 由于在探索阶段发现有部分网页的所属类别是错误的,需对其数据进行网页分类,且分析目标是分析咨询类别与知识类别,因此需对这些网址进行手动分类,其分类的规则为包含”ask”、”askzt”关键字的记录人为归类至咨询类别,对网址包含“知识”、“faguizt”关键字的网址归类为知识类别。

3.4 网址分类的实现
import pandas as pd
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://root:[email protected]:3306/7law?charset=utf8')
sql = pd.read_sql('changed_gzdata', engine, chunksize=10000)
for i in sql:
d = i.copy()
d['type_l'] = d['fullURL']
d['type_l_1'] = None
d['type_l_2'] = None
d['type_l'][d['fullURL'].str.contains('(ask)|(askzt)')] = 'zixun'
d['type_l'][d['fullURL'].str.contains('(info)|(zhishiku)')] = 'zhishi'
d['type_l'][d['fullURL'].str.contains('(faguizt)|(lifadongtai)')] = 'fagui'
d['type_l'][d['fullURL'].str.contains('(fayuan)|(gongan)|(jianyu)|(gongzhengchu)')] = 'jigou'
d['type_l'][d['fullURL'].str.contains('interview')] = 'fangtan'
d['type_l'][d['fullURL'].str.contains('d\d+(_\d)?(_p\d+)?\.html')] = 'zhengce'
d['type_l'][d['fullURL'].str.contains('baike')] = 'baike'
d['type_l'][d['type_l'].str.len() > 15] = 'etc'
d[['type_l_1', 'type_l_2']] = d['fullURL'].str.extract(
'http://www.lawtime.cn/(info|zhishiku)/(?P[A-Za-z]+)/(?P[A-Za-z]+)/\d+\.html',
expand=False).iloc[:, 1:]
d.to_sql('splited_gzdata', engine, index=False, if_exists='append')
属性归约
6 完整代码
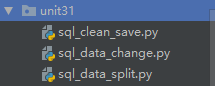
6.1 代码目录结构
6.2 完整代码
1. sql_clean_save.py
import pandas as pd
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://root:[email protected]:3306/7law?charset=utf8')
sql = pd.read_sql('all_gzdata', engine, chunksize = 10000)
for i in sql:
d = i[['realIP', 'fullURL']] #只要网址列
d = d[d['fullURL'].str.contains('\.html')].copy() #只要含有.html的网址
#保存到数据库的cleaned_gzdata表中(如果表不存在则自动创建)
d.to_sql('cleaned_gzdata', engine, index = False, if_exists = 'append')
2. sql_data_change.py
import pandas as pd
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://root:[email protected]:3306/7law?charset=utf8')
sql = pd.read_sql('cleaned_gzdata', engine, chunksize = 10000)
for i in sql: #逐块变换并去重
d = i.copy()
d['fullURL'] = d['fullURL'].str.replace('_\d{0,2}.html', '.html') #将下划线后面部分去掉,规范为标准网址
d = d.drop_duplicates() #删除重复记录
d.to_sql('changed_gzdata', engine, index = False, if_exists = 'append') #保存
3. sql_data_split.py
import pandas as pd
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://root:[email protected]:3306/7law?charset=utf8')
sql = pd.read_sql('changed_gzdata', engine, chunksize=10000)
for i in sql:
d = i.copy()
d['type_l'] = d['fullURL']
d['type_l_1'] = None
d['type_l_2'] = None
d['type_l'][d['fullURL'].str.contains('(ask)|(askzt)')] = 'zixun'
d['type_l'][d['fullURL'].str.contains('(info)|(zhishiku)')] = 'zhishi'
d['type_l'][d['fullURL'].str.contains('(faguizt)|(lifadongtai)')] = 'fagui'
d['type_l'][d['fullURL'].str.contains('(fayuan)|(gongan)|(jianyu)|(gongzhengchu)')] = 'jigou'
d['type_l'][d['fullURL'].str.contains('interview')] = 'fangtan'
d['type_l'][d['fullURL'].str.contains('d\d+(_\d)?(_p\d+)?\.html')] = 'zhengce'
d['type_l'][d['fullURL'].str.contains('baike')] = 'baike'
d['type_l'][d['type_l'].str.len() > 15] = 'etc'
d[['type_l_1', 'type_l_2']] = d['fullURL'].str.extract(
'http://www.lawtime.cn/(info|zhishiku)/(?P[A-Za-z]+)/(?P[A-Za-z]+)/\d+\.html',
expand=False).iloc[:, 1:]
d.to_sql('splited_gzdata', engine, index=False, if_exists='append')
1>[A-Za-z]+)/(?P[A-Za-z]+)/\d+\.html',
expand=False).iloc[:, 1:]
d.to_sql('splited_gzdata', engine, index=False, if_exists='append')