Solr完整个性化搜索排序方案
Solr个性化搜索排序
有不少同学想要代码,把仓库放在这里:
https://bitbucket.org/verycute/niuniusolrcore4.2/src/master/
首先需要改动solr-core模块,这里没有用maven,而是直接导出的方式
https://bitbucket.org/verycute/niuniu-search/src/master/
在改造完solr-core模块后,就支持多段式的搜索框架了,在这里涉及各种排序、queryparser、同义词改造、索引插件等逻辑
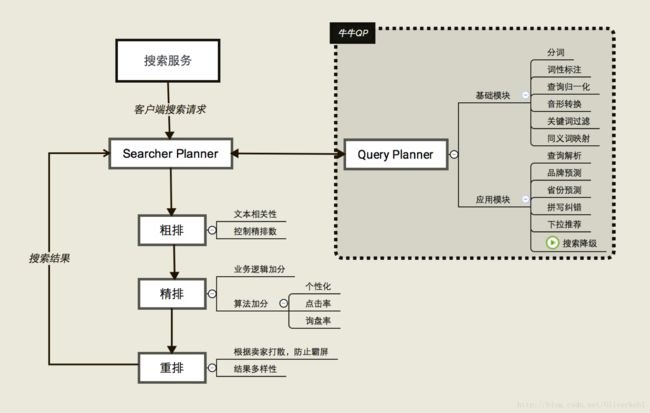
A厂的排序方案是添加各种各样的排序链,用于支持各个业务场景下的搜索排序功能,之前我们主搜排序以及筛选页的逻辑非常简单,就是文本相关性+业务分(业务加分+业务扣分),搜索结果干预功能也很直接,这些模块都直接添加在SolrIndexSearcher中,为的是最快的支持搜索排序业务,然后就这么撑了6个月。。。我们发现,用到排序的场景越来越多,比如首页很关键的两个入口:推荐资源和推荐寻车,推荐问题其实完全可以通过搜索召回+排序来进行,这就引入了相应的困难:并没有个性化的搜索排序功能来支持我们做相应的工作,导致我们的推荐和搜索排序策略都非常naive,搜索仅仅是个及格分,而推荐则远不及格,具体原因不分析,我们来看方案的改动
4.2及之前的版本
- 定义Component
- 定义requestHandler,其中的模块由各个Component组成,例如solr默认的requestHandler select就由query、facet、mlt、highlight、debug以及spellcheck这几个component组成,分别对应各自的功能
- QueryComponent调用SolrIndexSearcher的search方法来进行搜索生成结果,所以一开始的思路就是:哪里拿到搜索结果,就在哪里进行我们想要的额外处理:业务加分+搜索结果干预,即resort以及chaos
- 正因为搜索无关个性化,所以可以把搜索结果扔到cache中,在新的searcher生成前,下一次搜索过来就会从cache中拿到结果直接返回,而这种缓存机制是完全不适合个性化排序的
如上所述,这种模式不支持从请求中接收额外的参数用户辅助搜索排序,所以也就无法支持推荐相关的逻辑,所以需要改。
*新方案!! *
目前想到的排序特征虽然不算很多,但是也不少了,例如,订单量,用户偏好,用户对资源感冒不感冒,以及资源虽然是今天更新的,但是这个资源的价格是不是不靠谱,以及资源是不是很早很早之前就创建好了,那么现在的价格、颜色等信息其实也已经有了潜在的变动,或者说资源的信息已经不靠谱了。
综上,我们需要参考很多特征来做精排,而这个事情是循序渐进的过程,在优化过程中还需要进行AB实验看看这个特征到底怎么样,用于试探用户的实际业务习惯。所以这里对精排的灵活性提出了非常高的要求,灵活性的含义包括:已有特征的权重调整和新特征的引入,不能引入太多的发布。
所以,参考某宝的排序链,结果solr本身的特性,我开发了我们自己的排序体系:

-
新的搜索引入新的QueryComponent,即MyQueryComponent,用于第一步:粗排,即传统意义的布尔检索+filter+sort,用于召回候选集合
a. 沿用solr自带的缓存机制
b. 设置粗排截断数量 -
引入全新的Component,即MyCustomComponent,顾名思义,用于个性化排序的Component,用于第二步,精排
a. 排序特征
开发自己的排序特征,然后在solrconfig.xml中注册特征,该特征才能被排序链使用b. 排序链
定义排序链,排序链由不同的已注册特征以及对应的权重构成,精排分对这些的特征进行加权求和c. 搜索结果干预
chaos参数,引入新的solr url参数chaos_field,同时去除chaos为负数的情况(根据user_id或者hashkey来剔除某些搜索结果),因为该情况需要我们对搜索进行妥协,而且这个功能并不是很关键,或者说并不是很合理
缓存
solr本身有着较为完善的缓存机制,但是当我们把整个体系设计成个性化模式时,通用的缓存模式已经不再适用了,即A君搜索X5和B君搜索X5完全是奔着宝马和东南这两个不同的品牌去的,你缓存宝马的搜索结果给B君那就是灾难,所以我们这里只能缓存粗排结果。即只有精排阶段会涉及到个性化的信息,而粗排阶段的统一召回完全是根据通用信息和属性来的,所以缓存粗排结果是一个比较合理的选择。
于是由于4.2版本引入的chaos、resort等用户计算缓存key的模块就可以移除了。
样例
solrconfig.xml配置:
注册自定义的SearchComponent
- niuniu_query类似常规solr的QueryComponent,我们进行了一定的改动,让该模块成为粗排模块,为下层的niuniu_custom个性化精排模块提供粗排截断后的结果;
- niuniu_custom对应的是精排模块,这一阶段的工作就是拿到粗排阶段的结果,使用字段(从DocValue中获取)以及http请求带过来的个性化参数,通过排序链为各个进入这一阶段的结果进行重打分,然后根据最终分数做稳定的排序,然后再做重排序;
- 为了我们debug方便查看各个特征和模块的分数情况,我们引入了niuniu_debug模块,是参照A厂的哆啦A梦平台搞的。。

定义requestHandler
niuniu_query
niuniu_custom
niuniu_debug
注册排序时要用的特征
search_score_1
1
created_at_ms
根据不同的特征,定义不同的排序链
其中各个权重用于不同特征的加权求和,分数最终会作用于精排阶段的排序依据
search_feature
1
new_search_feature, new_resource_feature
1,2
对于一个工程师来说,如果想开发排序模块,只要开发排序特征代码,然后在solrconfig.xml中注册该特征并且加入到排序链中就可以生效了,外部代码模块对他来说就当黑盒子使用即可。
solr最终搜索串如下:
http://xxx/solr/production/select?q=c200&wt=json&defType=niuniuparser&chaos=4&sort_chain=wlsort1&chaos_field=user_id&
fl=id,score&start=0&sort=updated_at+desc,+created_at+desc&resort=true&rows=20&
fq=(post_type_i:0+OR+post_type_i:2)+AND+post_status_i:1&userinfo=xxx10.8|xxx0.64|xxx^0.15
可以看到我们沿用了solr本身的参数体系,然后多加了其他参数的解析:
-
chaos用于搜索最终结果的处理(即重排序),例如相同卖家的资源不能连续出现等
-
chaos_field告知MyCustomComponent哪个字段用于做重排序
-
sort_chain即使用哪个排序链进行此次搜索,不同的排序链对应着不同的排序方案或者排序加权方案,这种设置一是为了灵活性二是为了做AB实验
-
resort告知MyCustomComponent这次搜索需要走精排逻辑,这样如果不带resort=true的话默认就是粗排方案,但是可以进行重排序,不带该参数时sort_chain也失效
-
userinfo用于传递用户的信息,一般这些信息都是从redis中获取,传到MyCustomComponent中,不同的特征在parseUserInfo阶段专门读取自己需要的信息
-
defType=niuniuparser参考之前的文章
总结
这里只是把基本的构造一个类似某哦宝的粗排+精排+重排序的大方案介绍了一下,至于具体的细节还有很多的值得思考的地方,在很多所谓的细枝末节上其实花的功夫非常多,例如在精排阶段读取doc的字段,怎么读?之前是使用SolrDocument来读取,也没有在意schema.xml中的DocValue属性,发现效率很低,后来又去从fieldCache读取,效率提高很多但是内存占用较高,最后使用DocValue,即所谓的正排字段,效率高且内存占用率低,才能搭起来一个平均搜索时长在6ms左右的个性化搜索框架,当然这和我们用的精排特征有关,如果你有海量特征或者使用树模型来在精排阶段打分,就会较为耗时了
后续还会在新写一些文章代码细节上进行补充,并且给出一些代码的sample这样让看客们尽量少走弯路。
有问题可以私信或者发我邮件